行人重识别之Intra-Inter Camera Similarity for Unsupervised Person Re-Identification
CVPR2021
Shiyu Xuan Shiliang Zhang
Department of Computer Science, School of EECS, Peking University
0.摘要
这也是一篇利用聚类产生伪标签的论文。
问题:跨相机的标签计算精度低,这是由于之前的工作不考虑相机间分布的差异,在不同的摄像头下同一个人会呈现出不同的特征。
解决方法:样本相似度计算分解为两个阶段,分别为相机内计算和相机间计算。同一相机内的直接使用特征图进行相似性度量,不同相机间则主要使用伪标签,然后在不同相机上获得的分类得分作为新的特征向量。
基于伪标签的方法首先根据样本相似度制定一定的规则生成伪标签,然后用这些伪标签训练ReID模型。计算出的伪标签的质量决定了这些方法的性能。无监督聚类方法是生成伪标签最常用的方法之一。
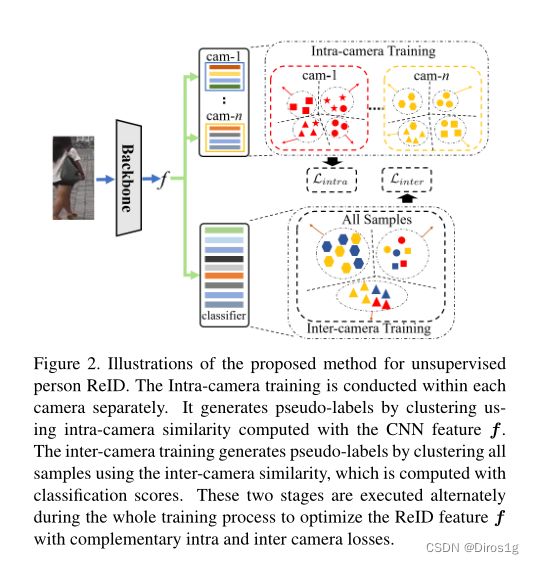
1.实现方法
1.1目标函数

转换为如下问题:
t代表的是聚类结果(伪标签),卡方p代表的是p个行人在相机中的特征信息增大每个{Xp}的类间距离,减小{Xi}和{Xj}之间的类内距离
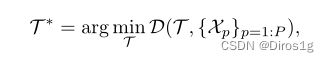
1.2采集的信息
作者认为一张行人的图片应该是由三部分信息构成:
![]()
其中I代表第c个摄像头的第n个图片,这个行人为行人p。这张图片由三个部分:A代表p的外观信息;S代表了摄像头c的参数、视角、周围环境等信息;E代表其他信息,包括姿势、遮挡、光照。
S和E代表的是外界的信息,作者想要提高A影响力,来减轻外界环境的干扰。具体措施就是使用伪标签。
1.3环境干扰Ec
首先对于特征f,我们进行聚类,得到这张图片的标签m。为了保证不同摄像头下E都是相同的,要固定S和A,对每个不同摄像头的分类器F都分别进行学习,用伪标签进行监督学习。
w是权重,f是特征,F是分类器,m是伪标签,用softmax计算。

一个摄像头的分类器的损失,是要考虑所有伪标签情况

总的训练损失
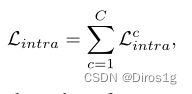
1.4相机间的相互增强Sc
对于同一张罩袍,所有摄像头的分类器应该得到相同的结果
不同的相机间,可以使用分类得分对同一个人进行识别,也可以使用相机间的相似度来扩大同一个人不同相机间的相似度得分。
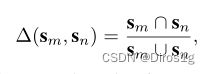
第一项是特征之间的相似度,第二项是分类器之间的相似度:
![]()
属于同一身份的样本,每个分类器产生的分类概率分布应该相似,利用Jaccard相似度分类概率计算,越大越相似
 第一种情况两个分类器对于这个人类别的概率为 【0.1,0.9】【0.8,0.2】
第一种情况两个分类器对于这个人类别的概率为 【0.1,0.9】【0.8,0.2】
第二种情况两个分类器对于这个人类别的概率为【0.4,0.6】【0.4,0.6】
经过运算,第一种情况最终结果为【1/8,2/9】,第二种情况为【1,1】,第二种情况,两种分类器的结果更相近,作者想要达到这种效果。
这样对于同一个人,其特征是相近的,就不会受摄像头参数等因素的影响,而对分类结果产生偏差。

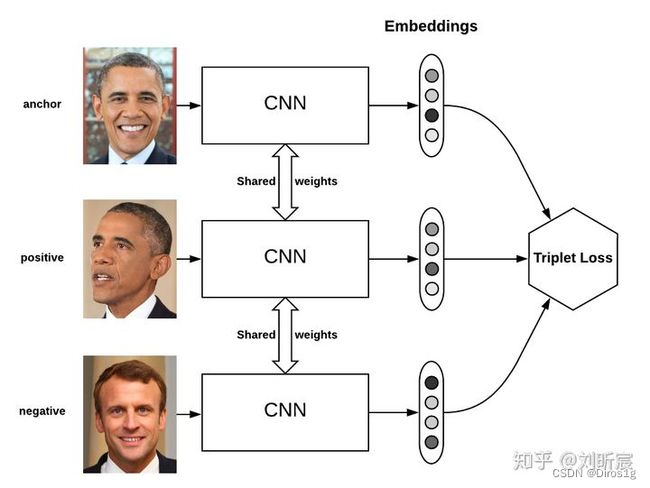
三元组损失函数,是无监督中比较常用的损失函数:
![]()
1.6AIBN

图中C代表通道,N一竖列代表一张图片
这个图是6个通道,也就是6个feature map
BN:6张图片的相同通道进行Normalization
LN:一张图片6个通道进行Normalization
IN:一张图片的一个通道进行Normalization
GN:一张图片的几个通道进行Normalization
BN适用于判别模型中,比如图片分类模型。因为BN注重对每个batch进行归一化,从而保证数据分布的一致性,而判别模型的结果正是取决于数据整体分布。但是BN对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布。
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,在风格迁移中使用Instance Normalization不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立
BN有助于挖掘出内容,而IN有助于消除风格, 但是会消除内容。所以很多工作都会结合BN和IN来消除风格,挖掘内容。
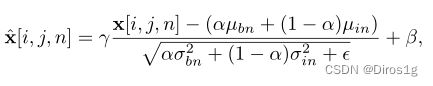
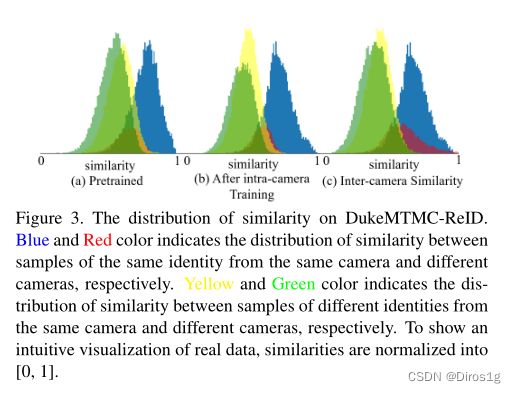
2.结果
红色是同一个人在不同摄像头下的相似度,蓝色是同一个人在同一个摄像头下的相似度。黄色和黄色是分别指一台相机和不同相机不同人的相似度。