论文解读-SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
本文是上海交通大学张伟楠教授发表的一篇关于使用基于策略梯度的GAN来生成轨迹的文章,文章称作为一种训练产生式模型的新方法,产生式对抗性网络(GAN)利用判别模型指导产生式模型的训练,在生成实值数据方面取得了相当大的成功。然而,GAN在生成实值数据方面也存在不少的问题,例如1)产生式模型的离散输出使得从判别模型到产生式模型的梯度更新很难通过。2)判别模型只能评估完整的序列,而对于部分生成的序列,一旦整个序列生成后,平衡其当前分数和未来分数是非常困难的。
本文提出了一个序列生成框架SeqGAN来解决问题,将数据生成器建模为强化学习(RL)中的随机策略,SeqGAN通过直接执行梯度策略更新绕过了生成器差异化问题。RL奖励信号来自按完整序列判断的GAN鉴别器,并且使用蒙特卡罗搜索被传递回中间状态-动作步骤。
Introduction
古德费罗等人于2014年提出的生成对抗性网络(GAN)。在GAN中,判别网D学习区分给定数据实例是否真实,而生成网G通过生成高质量数据来学习混淆D。
不幸的是,应用GaN生成序列有两个问题。首先,GAN设计用于生成实值的、连续的数据,但在直接生成离散符号序列(如文本)方面存在困难。
本文将将序列生成过程视为顺序决策过程。产生式模型被视为强化学习(RL)的Agent;状态是到目前为止生成的令牌,动作是下一个要生成的令牌。为了给出奖励,我们使用一个鉴别器来评估序列,并反馈评估来指导生成模型的学习。
为了解决当输出是离散的情况下梯度不能返回生成模型的问题,我们将生成模型看作一个随机的参数化策略。在我们的政策梯度中,我们使用蒙特卡罗(MC)搜索来近似状态作用值。我们通过策略梯度直接训练策略(生成模型)。
Related Work
深度生成模型包括,DBN,DAE,VAE等。
所有这些产生式模型都是通过最大化训练数据似然(下限)来训练的,但是这存在逼近难以处理的概率计算的困难。
2014年提出了一种替代生成性模型的训练方法,即GAN,其中训练过程是生成性模型和歧视性模型之间的极小极大博弈。该框架绕过了最大似然学习的困难,并在自然图像生成方面取得了惊人的成功。但是GAN在生成连续数据方面效果不好,这是因为GAN中的生成器被设计为能够连续调整输出,这不适用于离散数据生成。
Bengio等人指出,训练和生成之间的差异使得最大似然估计不是最优的,并提出了预定抽样策略(SS)。后来(Husz‘ar 2015)理论上认为SS下的目标函数是不正确的,并从理论上解释了Gans倾向于生成看起来自然的样本的原因。因此,GAN算法对离散概率模型具有很大的潜力,但目前在实际应用中并不可行。
其实,有研究人员指出,序列数据的生成可以表示为一个序列决策过程,这可能可以通过强化学习技术来解决。将序列生成器建模为选择下一个token的策略,策略梯度方法可以用来优化生成器。
综上所述,我们提出的SeqGAN使用基于强化学习的生成器来扩展GANS,以解决序列生成问题,其中鉴别器在每集结束时通过蒙特卡洛方法提供奖励信号,生成器选择动作并使用估计的总体奖励来学习策略。
序列生成对抗网络
序列的生成问题描述如下,使用 G θ G_{\theta} Gθ生成序列 Y 1 : T = ( y 1 , . . . , y t , . . . y T ) Y_{1:T}=(y_1,...,y_t,...y_{T}) Y1:T=(y1,...,yt,...yT)。使用强化学习来解释这个问题,状态是当前的序列 ( y 1 , . . . y t − 1 ) (y_1,...y_{t-1}) (y1,...yt−1),动作a是要选择的下一个位置 y t y_t yt,因此策略 G θ ( y t ∣ Y 1 : t − 1 ) G_{\theta}(y_t|Y_{1:t-1}) Gθ(yt∣Y1:t−1)是随机的,在选择了动作之后是确定的。
同时,基于从判别模型D-θ得到的期望末端报酬,采用策略梯度和MC搜索对生成模型G-φ进行更新。奖励是根据它欺骗判别模型Dφ的可能性来估计的。
通过策略梯度实现的SeqGAN
没有中间奖励时,生成器模型(策略)Gθ(yt|y1:t−1)的目标是从开始状态S0生成序列以最大化其预期的结束奖励:
 Q是序列的动作值函数,即从状态s开始,采取行动a,然后遵循策略Gθ的期望累积报酬。
Q是序列的动作值函数,即从状态s开始,采取行动a,然后遵循策略Gθ的期望累积报酬。
如何估计动作值函数?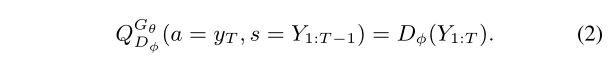 然而,鉴别器仅为完成的序列提供奖励值。因为我们真正关心的是长期回报,因此,为了评估中间状态的动作值,我们应用蒙特卡罗搜索和推出策略Gβ对未知的最后T−t个令牌进行采样。我们将N次蒙特卡罗搜索表示为,
然而,鉴别器仅为完成的序列提供奖励值。因为我们真正关心的是长期回报,因此,为了评估中间状态的动作值,我们应用蒙特卡罗搜索和推出策略Gβ对未知的最后T−t个令牌进行采样。我们将N次蒙特卡罗搜索表示为,
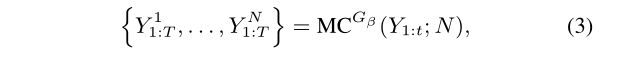
我们从当前状态到序列结束运行转出策略N次,得到
 训练鉴别器模型:
训练鉴别器模型:
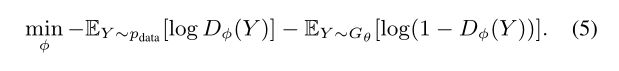
更新生成器,

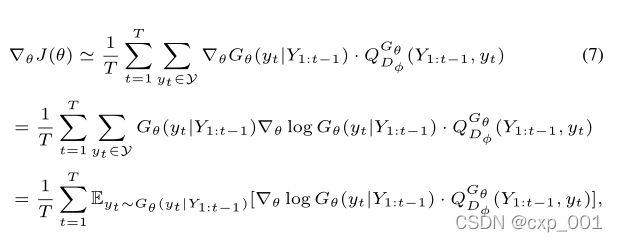
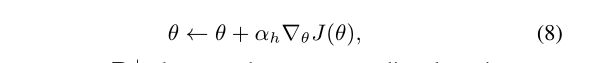
在训练开始时,我们使用最大似然估计在训练集S上对G-θ进行预训练。
在预训练之后,交替训练生成器和鉴别器。当训练鉴别器时,正样本来自给定的数据集S,而负样本来自我们的生成器。为了保持平衡,我们为每个d步生成的反例数与正例数相同。为了减少估计的变异性,我们使用了不同的负样本和正样本组合,这类似于Bootstrapping。
序列的生成模型
作者使用RNN来嵌入轨迹表示,
 其中,g为LSTM模型。最后,使用softmax函数来生成目标token的分布。
其中,g为LSTM模型。最后,使用softmax函数来生成目标token的分布。
序列的判别模型
在本文中,我们选择CNN作为我们的鉴别器,因为最近CNN在文本(令牌序列)分类中显示出了很好的效果,大多数判别模型只能对整个序列进行分类,而不能对未完成的序列进行分类。在本文中,我们还重点研究了鉴别器预测完成序列为真的概率的情况。
首先,将输入序列化成一个矩阵,
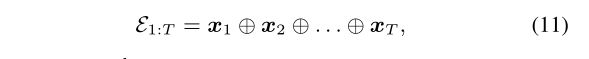
然后,使用卷积网络,
![]()
我们可以使用不同数目、不同窗口大小的核函数来提取不同的特征。最后,进行最大池化操作,
![]()
为了增强性能,我们还添加了基于池功能地图的高速公路架构。最后,使用具有sigmoid激活的全连通层来输出概率。
实验
1.评价指标
我们使用随机初始化的LSTM作为真实模型,也就是Oracle,来生成实际数据分布p(xt|x1,…,XT−1).
拥有这样的预言机的好处是,首先,它提供了训练数据集,其次,它评估了生成模型的准确性能,然后,为了增加通过图灵检验的机会,我们实际上需要最小化确切的操作平均负对数似然,
![]()
在我们的合成数据实验中,我们可以认为oracle是人类对现实世界问题的观察者,因此一个完美的评估指标应该是,
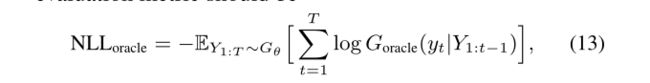 在测试阶段,我们使用Gθ生成100000个序列样本,并通过Goracle计算每个样本的NLLoracle及其平均分数。此外,还进行了显著性检验,以比较基线和SeqGAN之间发电性能的统计特性。(什么意思,愣是没看懂)
在测试阶段,我们使用Gθ生成100000个序列样本,并通过Goracle计算每个样本的NLLoracle及其平均分数。此外,还进行了显著性检验,以比较基线和SeqGAN之间发电性能的统计特性。(什么意思,愣是没看懂)
2.训练
首先,作者将LSTM的参数按照N(0,1)标准正态分布进行初始化。然后我们用它生成10000个长度为20的序列,作为生成模型的训练集。
在SeqGAN算法中,鉴别器的训练集由标签为0的生成示例和标签为1的“真实”实例组成。
然后,一共有四种基准模型用于作比较。第一种是随机生成,第二种是MLE训练的LSTM( G θ G_{\theta} Gθ)。第三种是计划抽样。第四种是PG-BLEU。
3.结果
NLLoracle性能,

图2所示的学习曲线明确说明了SeqGAN的优越性。

Discussion
作者对每次生成器和鉴别器的训练次数进行了分析。
真实世界场景
作者用该模型进行了诗歌和音乐的生成。
结论
在本文中,我们提出了一种序列生成方法SeqGAN,通过策略梯度有效地训练生成性对抗网络生成结构化序列。据我们所知,这是第一个扩展GAN以生成离散令牌序列的工作。在我们的合成数据实验中,我们使用oracle评估机制来明确说明SeqGAN优于强基线。对于三个真实场景,即诗歌、语音和音乐生成,SeqGAN在生成创意序列方面表现出色。我们还进行了一系列实验来研究训练序列的鲁棒性和稳定性。对于未来的工作,我们计划建立蒙特卡罗树搜索和价值网络,以改进大规模数据和长期规划的行动决策。
P.S.
太强了