【语音识别】自动语音识别(ASR)研究综述
自动语音识别(ASR)研究综述
Note:
- 正文内容绝大部分取自 语音识别研究综述
- WeNet的部署参考该Blog WeNet平台搭建
文章目录
- 自动语音识别(ASR)研究综述
-
- 零、参考资料
-
- 1、参考文档
- 2、参考论文
- 3、参考代码
- 一、语音识别基础知识
-
- 1、特征提取(MFCC声学特征)
- 2、声学模型(建立关于语音特征和音素的映射关系(条件概率),语音识别中最重要部分)
- 3、语言模型(n-gram 或 使用RNN进行语言模型建模,计算音素的先验概率)
- 4、端到端语音识别(2020 ContextNet)
- 二、语音识别到难点与热点
-
- 1、鲁棒性语音识别
- 2、低资源语音识别
- 3、语音的模糊性
- 4、低计算资源
- 三、语音识别落地方案探讨
-
- 1、Kaldi系统
- 2、端到端系统
零、参考资料
1、参考文档
- 基于PaddlePaddle实现的DeepSpeech2端到端中文语音识模型
- ASR-工业级中文语音识别系统
- THCHS-30数据集下载(EU镜像)
- 几个最新免费开源的中文语音数据集
- ASRT语音识别文档
- Wenet - 面向工业落地的E2E语音识别工具
- Tensorflow教程之语音识别(MFCC,CTC decoder等)
2、参考论文
- 语音识别研究综述
- 语音识别专利技术综述
- 语音识别中声学模型研究综述
- WeNet Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
3、参考代码
- PaddlePaddle-DeepSpeech
- DeepSpeech
- DeepSpeech官方文档
- Welcome to Wenet’s documentation!
一、语音识别基础知识
参考 语音识别研究综述
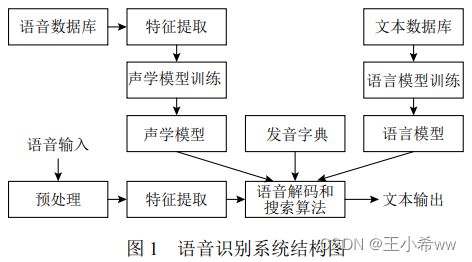
从语音识别系统的构成来讲, 一套完整的语音识别系统包括预处理、特征提取、声学模型、语言模型以及搜索算法等模块, 其结构示意图如图所示:
1、特征提取(MFCC声学特征)
通常, 在进行语音识别之前, 需要根据语音信号波形提取有效的声学特征. 特征提取的性能对后续语音识别系统的准确性极其关键, 因此需要具有一定的鲁棒性和区分性. 目前语音识别系统常用的声学特征有梅尔频率倒谱系数 (Mel-frequency cepstrum coefficient,
MFCC)、感知线性预测系数 (perceptual linear predictive cepstrum coefficient, PLP)、线性预测倒谱系数 (linear prediction cepstral coefficient, LPCC)、梅尔滤波器组系数 (Mel filter bank, Fbank) 等。
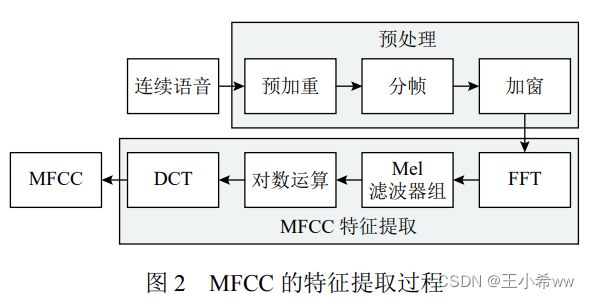
MFCC 是最为经典的语音特征, 其提取过程如图 2 所示. MFCC 的提取模仿了人耳的听觉系统, 计算简单,低频部分也有良好的频率分辨能力, 在噪声环境下具有一定的鲁棒性. 因此, 现阶段语音识别系统大多仍采用 MFCC 作为特征参数, 并取得了不错的识别效果。
2、声学模型(建立关于语音特征和音素的映射关系(条件概率),语音识别中最重要部分)
设一段语音信号经过特征提取得到特征向量序列为 X = [ x 1 , x 2 , … , x N ] X=[x_1, x_2, …, x_N] X=[x1,x2,…,xN], 其中 x i x_i xi 是一帧的特征向量, i = 1 , 2 , … , N i=1, 2, …,N i=1,2,…,N 为特征向量的数目。该段语音对应的文本序列设为 W = [ w 1 , w 2 , … , w M ] W=[w_1 , w_2, …, w_M] W=[w1,w2,…,wM], 其中 w i w_i wi 为基本组成单元,如音素、单词、字符, i = 1 , 2 , … , M i=1, 2, …, M i=1,2,…,M, M 为文本序列的维度。从贝叶斯角度, 语音识别的目标就是从所有可能产生特征向量 X X X 的文本序列中找到概率最大的 W ∗ W^* W∗, 可以用公式表示为式 (1) 优化问题:
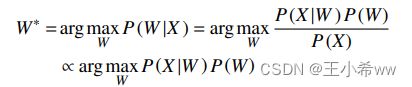
由式 (1) 可知, 要找到最可能的文本序列必须使两个概率 P ( X ∣ W ) P(X|W) P(X∣W) 和 P ( W ) P(W) P(W) 的乘积最大, 其中 P ( X ∣ W ) P(X|W) P(X∣W) 为条件概率, 由声学模型决定; P ( W ) P(W) P(W) 为先验概率, 由语言模型决定. 声学模型和语言模型对语音信号的表示越精准, 得到的语音系统效果越准确。
声学模型是对下式 (1) 中的 P ( X ∣ W ) P(X|W) P(X∣W) 进行建模,在语音特征与音素之间建立映射关系, 即给定模型后产生语音波形的概率, 其输入是语音信号经过特征提取后得到的特征向量序列。
声学模型是整个语音识别系统中最重要的部分, 只有学好了发音, 才能顺利和发音词典、语言模型相结合得到较好的识别性能。
常见的声学模型有GMM-HMM,该模型利用 HMM 对时间序列的建模能力, 描述语音如何从
一个短时平稳段过渡到下一个短时平稳段; 此外, HMM的隐藏状态和观测状态的数目互不相干, 可以解决语音识别中输入输出不等长的问题. 该声学模型中的每个 HMM 都涉及到 3 个参数: 初始状态概率、状态转移概率和观测概率, 其中观测概率依赖于特征向量的概率分布, 采用高斯混合模型 GMM 进行建模。
深度学习的兴起为声学建模提供了新途径, 学者们用深度神经网络 (deep neural network, DNN) 代替GMM 估计 HMM 的观测概率, 得到了 DNN-HMM 语音识别系统。基于 DNN-HMM 的语音识别系统框架如下:
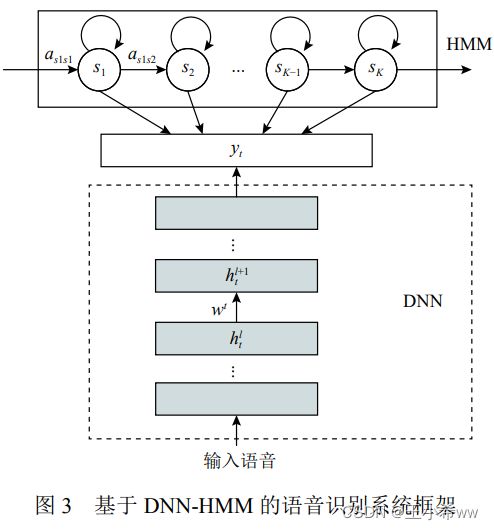
然而, DNN 对于时序信息的上下文建模能力以及灵活性等方面仍有欠缺. 针对这一问题, 对上下文信息利用能力更强的循环神经网络RNN和卷积神经网络 CNN 被引入声学建模中。
总体而言, 近年来语音识别中对声学模型的研究仍集中在神经网络, 针对不同的应用场景和需求对上述经典网络结构进行综合和改进, 以期训练更复杂、更强大的声学模型。
3、语言模型(n-gram 或 使用RNN进行语言模型建模,计算音素的先验概率)
语言模型是用来预测字符 (词) 序列产生的概率, 判断一个语言序列是否为正常语句, 也就是解决如何计算等式 (1) 中的 P ( W ) P(W) P(W)。传统的语言模型 n-gram 是一种具有强马尔科夫独立性假设的模型, 它认为任意一个词出现的概率仅与前面有限的 n–1 个字出现的概率有关, 其公式表达如下:
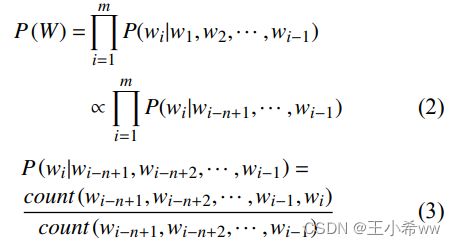
然而, 由于训练语料数据不足或者词组使用频率过低等常见因素, 测试集中可能会出现训练集中未出现过的词或某个子序列未在训练集中出现, 这将导致n-gram 语言模型计算出的概率为零, 这种情况被称为未登录词 (out-of-vocabulary, OOV) 问题. 为缓解这个问题, 通常采用一些平滑技术, 常见的平滑处理有Discounting、Interpolation 和 Backing-off 等. n-gram 模型的优势在于其参数易训练, 可解释性极强, 且完全包含了前 n–1 个词的全部信息, 能够节省解码时间; 但难以避免维数灾难的问题, 此外 n-gram 模型泛化能力弱, 容易出现 OOV 问题, 缺乏长期依赖。
为进一步解决问题, RNN 被用于语言模型建模。RNNLM 中隐含层的循环能够获得更多上下文信息, 通过在整个训练集上优化交叉熵来训练模型, 使得网络能够尽可能建模出自然语言序列与后续词之间的内在联系. 其优势在于相同的网络结构和超参数可以处理任意长度的历史信息, 能够利用神经网络的表征学习能力, 极大程度避免了未登录问题; 但无法任意修改神经网络中的参数, 不利于新词的添加和修改, 且实时性不高。
语言模型的性能通常采用困惑度 (perplexity ,PPL) 进行评价. PPL 定义为序列的概率几何平均数的倒数, 其公式定义如下:
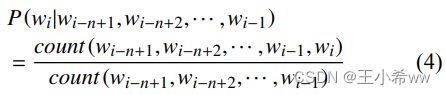
PPL 越小表示在给定历史上出现下一个预测词的概率越高, 该模型的效果越好。
4、端到端语音识别(2020 ContextNet)
传统的语音识别由多个模块组成, 彼此独立训练,但各个子模块的训练目标不一致, 容易产生误差累积, 使得子模块的最优解并不一定是全局最优解。 针对这个问题, 学者们提出了端到端的语音识别系统, 直接对等式 (1) 中的概率 P ( W ∣ X ) P(W|X) P(W∣X) 进行建模, 将输入的语音波形 (或特征矢量序列) 直接转换成单词、字符序列. 端到端的语音识别将声学模型、语言模型、发音词典等
模块被容纳至一个系统, 通过训练直接优化最终目标,如词错误率 (word error rate, WER)、字错误率 (character error rate, CER), 极大地简化了整个建模过程。
目前端到端的语音识别方法主要有基于连接时序分类(connectionist temporal classification, CTC) 和基于注意力机制 (attention model)两类方法及其改进方法。
CTC 引入空白符号 (blank) 解决输入输出序列不等长的问题, 主要思想是最大化所有可能对应的序列概率之和,无需考虑语音帧和字符的对齐关系, 只需要输入和输出就可以训练. CTC 实质是一种损失函数, 常与 LSTM 联合使用。基于 CTC 的模型结构简单, 可读性较强, 但对发音词典和语言模型的依赖性较强, 且需要做独立性假设. RNN-Transducer 模型是对 CTC 的一种改进, 加入一个语言模型预测网络, 并和 CTC 网络通过一层全连接层得到新的输出, 这样解决了CTC 输出需做条件独立性假设的问题, 能够对历史输出和历史语音特征进行信息累积, 更好地利用语言学信息提高识别准确率。
基于注意力机制的端到端模型最开始被用于机器翻译, 能够自动实现两种语言的不同长度单词序列之间的转换. 该模型主要由编码网络、解码网络和注意力子网络组成。编码网络将语音特征序列经过深层神经网络映射成高维特征序列, 注意力网络分配权重系数, 解码网络负责输出预测的概率分布。该模型不需要先验对齐信息, 也不用音素序列间的独立性假设, 不需要发音词典等人工知识, 可以真正实现端到端的建模。2016 年谷歌提出了一个 Listen-Attend-Spell (LAS) 模型, LAS 模型真正实现了端到端, 所有组件联合训练, 也无独立性假设要求. 但LAS 模型需要对整个输入序列之后进行识别, 因此实时性较差, 之后也有许多学者对该模型不断改进。
目前端到端的语音识别系统仍是语音识别领域的研究热点, 基于 CTC、attention 机制以及两者结合的系统, 都取得了非常不错的成果. 其中Transformer-Transducer 模型将 RNN-T 模型中的RNN 替换为 Transformer 提升了计算效率, 还控制attention 模块上下文时间片的宽度, 满足流式语音识别的需求. 2020 年谷歌提出的 ContextNet 模型[39], 采用Squeeze-and-Excitation 模块获取全局信息, 并通过渐进降采样和模型缩放在减小模型参数和保持识别准确率之间取得平衡。在 Transformer 模型捕捉长距离交互的基础上加入了 CNN 擅长的局部提取特征得到 Conformer模型, 实现以更少的参数达到更好的精度. 实际上端到端的语音识别系统在很多场景的识别效果已经超出传统结构下的识别系统, 但距其落地得到广泛商业应用仍有一段路要走。
二、语音识别到难点与热点
语音识别作为人机交互的关键技术一直是科技应用领域的研究热点. 目前, 语音识别技术从理论研究到产品的开发都已取得了很多的成果, 然而, 相关研究及应用落地仍然面临很大挑战, 具体可归纳为以下几方面:
1、鲁棒性语音识别
目前, 理想条件下 (低噪声加近场) 的语音识别准确率已经达到一定程度. 然而, 在实际一些复杂语音环境下, 如声源远场等情景, 低信噪比、房间混响、回声干扰以及多声源信号干扰等因素,使得语音识别任务面临很大挑战。因此, 针对复杂环境研究鲁棒语音识别是目前语音识别领域的研究难点和热点. 当前, 针对复杂环境下的语音识别研究大致可以分为 4 个方向:
- (1) 在语音识别前端, 利用信号处理技术提高信号质量: 采用麦克风阵列技术采集远场声源信号, 然后通过声源定位、回声消除、声源分离或语音增强等提高语音信号质量. 例如, 文献在基于深度学习的自适应声学回声消除 (acoustic echo cancellation, AEC) 中加入了背景关注模块以适应部署环境的变化, 以提高语音信号质量; 文献 [45] 以深度聚类为框架提出了结合频谱和空间信息的盲源分离方法;文献 [46] 利用以基于生成式对抗网络 (generative adversial networks, GAN) 为基础框架的增强网络进行
噪声抑制, 从而提高目标语音信号质量; - (2) 寻找新的鲁棒性特征, 尽可能消除非目标语音信号的影响: 例如, 伽马通滤波器倒谱系数 (Gammatone frequency cepstrumcoefficient, GFCC) 等听觉特征参数更适合拟合人耳基底膜的选择性, 符合人耳听觉特征; 或者, 采用自动编码器[48]、迁移学习[49] 等多种方式提取更鲁棒的特征;
- (3) 模型的改进与自适应: 上海交通大学提出的VDCNN[6] 以及 VDCRN[7] 通过加深卷积层提升算法的鲁棒性, 文献利用 GAN 中生成器与判别器的相互博弈和瓶颈特征构建声学模型, 文献采用teacher-student learning 的方式以干净语音训练的声学模型作为教师模型训练噪声环境下的学生模型;
- (4) 多模态数据融合: 当在高噪声环境或多说话人造成语音重叠的情况下, 目标语音信号容易被噪声或其他非目标声源 (干扰信号)“淹没”, 这时仅凭拾音设备捕捉的“语音”信号往往无法获得良好的识别性能; 这时, 将语音信号和其他信号如声带的振动信号[54]、嘴部的图像信号[55] 等进行融合, 更好地提升识别系统的鲁棒性. 例如, 文献 [56] 以 RNN-T 为框架, 提出多模态注意力机制对音频和视频信息进行融合, 以提高识别性能; 文献 [57]同样基于 RNN-T, 但利用 vision-to-phoneme model(V2P) 提取视觉特征, 连同音频特征以相同的帧频输入至编码器, 取得了良好的识别性能。
2、低资源语音识别
这是对各种小语种语言识别研究的统称. 小语种不同于方言, 有独立完整的发音体系,各异性较强但数据资源匮乏, 难以适应以汉语、英语为主的语音识别系统, 声学建模需要利用不充分的数据资源训练得到尽可能多的声学特征. 解决这一问题的基本思路可以概括为从主流语言的丰富资源中提取共性训练出可以公用的模型, 在此基础上训练小语种模型. 文献 [58] 为解决共享隐藏层中会学到不必要的特定信息这一问题, 提出了一个共享层和特有层平行的模型,它通过对抗性学习确保模型能够学习更多不同语种间的不变特征. 然而, 小语种种类繁多, 为了单独一种建立识别系统耗费过多资源并不划算, 因此现在主要研究多语种融合的语音识别系统。
3、语音的模糊性
各种语言中都存在相似发音的词语, 不同的讲话者存在不同的发音习惯以及口音、方言等问题, 母语者和非母语者说同一种语言也存在不同的口音, 难以针对单独的口音构建模型. 针对多口音建模的问题, 现有的方法一般可以分为与口音无关和与口音相关两大类, 其中与口音无关的模型普遍表现更好一些. 文献尝试通过特定口音模型的集合建立统一的多口音识别模型; 文献通过多任务学习将声学模型和口音识别分类器联合; 文献则基于 GAN 构建了预训练网络从声学特征中区分出不变的口音。
4、低计算资源
精度高效果好的神经网络模型往往需要大量的计算资源且规模巨大, 但移动设备 (如手机、智能家居等) 计算能力和内存有限, 难以支撑, 因此需要对模型进行压缩及加速. 目前针对深度学习模型采用的压缩方法有网络剪枝、参数量化、知识蒸馏等. 文献 [65] 采用网络剪枝的方法构建了动态稀疏神经网络 (dynamic sparsity neural networks, DSNN) , 提供不同稀疏级别的网络模型, 通过动态调整以适应不同资源和能量约束的多种硬件类型的能力. 文献 [66]通过量化网络参数减少内存占用并加快计算速度. 知识蒸馏能够将复杂模型的知识迁入小模型, 已应用于对语音识别系统的语言模型[67]、声学模型[68] 和端到端模型[29,69,70] 等进行压缩. 文献 [71] 利用知识蒸馏将视听两模态的识别系统迁移至单听觉模型, 缩小了模型规模, 加快了训练速度, 却并不影响精度。
三、语音识别落地方案探讨
参考 想了解一下现在语音识别主流的方案是什么?主流的落地方案又是什么呢?
目前开源语音识别的主流的方案有K2、PaddleSpeech、ESPnet 、WeNet。关于主流的落地方案是什么,这个要分开说,如果想搞科研,那么ESPnet就会更适合一些,WeNet也可以;如果要产品落地的话,那么目前来说WeNet是走在最前面的。首先,WeNet针对落地化的一些问题,提出了语言模型、热词等不少解决方案,接下来我们也会继续优化热词,后续可能会出一个热词增强的2.0,大家也可以关注一下。其次,我们基本上能够很简单地把WeNet部署起来,用到一个真实的业务上面去。
参考 想了解一下现在语音识别主流的方案是什么?主流的落地方案又是什么呢?
目前来说主流的方案应该还是有两套:基于Kaldi的系统和基于端到端模型的系统,这两个方案,我认为现阶段仍然是两个主流的方向。虽然很多论文和工作已经宣称自己的端到端模型比Kaldi的TDNN-LFMMI系统好多少好多少,但是要注意,这些对比是不是完全合理的?比如拿一个纯流式的Kaldi模型去 PK 完全非流式的端到端模型,那肯定是端到端模型更好!Kaldi的系统,有自己的一整套完整的框架,从模型训练到解码器,即使现在很多公司已经升级到端到端系统,Kaldi工具包仍然作为一个重要的工具,比如进行GMM模型训练、特征提取、对齐等重要的功能仍在使用。下面针对这两种主流的方案进行介绍,但是针对这个问题,我觉得我的答案应该是:主流落地方案是以CTC或Transducer为主导的端到端语音识别系统了。
1、Kaldi系统
Kaldi系统主打“神经网络声学模型+解码图“对方案;神经网络一般使用TDNN比较多,训练损失函数是LFMMI+CE联合训练。解码图是基于WFST的,HCLG复合而成。可以说大部分公司的解码器都是基于Kaldi的进行的工程优化,即使现在的端到端系统,想要投入正式的使用,仍要使用一个基于WFST的解码器,只不过一般是相对比较简单的构图方式了。虽然现在很多公司的系统还是基于Kaldi的,但是长远来看,Kaldi这套系统应该很快就会被放弃。一方面,这套系统完全C++实现,虽然是一个非常好的开源项目,代码质量非常好,但对使用者来说,门槛也相对比较高,和现在基于pytorch的方案对比,简直是复杂的不行。一个初学者,想要写一个目前最为前沿的神经网络结构,用pytorch结合开源代码,可能几天就能搞定,但是如果用Kaldi,那可就复杂多了。另一方面,端到端系统不断的完善,以谷歌、微软和亚马逊等公司的语音团队,不断的打磨各种流式端到端模型,系统的性能也超过了Kaldi,建模流程又非常简单明了,所以大家肯定会转移到端到端系统。
2、端到端系统
端到端系统是一个比较宽泛的说法,因为目前的端到端方案其实有多种,所谓的端到端,其实都是相对于之前对序列数据建模的“frame-by-frame”的方式而言的。端到端方案都是采用“sequence-to-sequence”的建模方式,比如CTC,RNN-Transducer(RNNT)以及Attention based Enocder-Decoder(AED)。在端到端开始流行的时候,大家希望建模颗粒度越大越好,比如输入语音,直接输出汉字,那么这才是最直观的端到端系统。可是随着大家的re-re-research,发现这种系统根本无法真正使用,不融合任何外部信息的端到端系统根本无法真正投入到商业使用,做到最后,大家还是选择用比较小粒度的建模单元,比如phone来建模,最后还需要外接一个简单的TLG解码图,只不过声学模型的训练,采用了“sequence-to-sequence”的损失函数。如果从这层面来说,我们目前所谓的端到端系统,绝大部分还是一个混合系统,只不过训练过程和建模过程得到了简化。
在实际使用的过程中,基于CTC和Transducer的系统相对较多,因为它们只要采用流式的神经网络,就能够实现流式的实时识别。CTC和Transducer只是两种损失函数而已,声学模型可以采用任何神经网络,只要这种神经网络有一定的记忆能力或者建模上下文的能力。截止到目前(20220623),我相信大家采用的神经网络应该主要都是Conformer了,比如现在国内比较流行的WeNet,其实就是Conformer+CTC的架构,google力推的Cascaded encoder方式,则是采用了Conformer+Transducer(C-T)方式。那么要是对比CTC和Transducer两个损失函数,我更倾向于Transducer损失函数,这种损失函数理论上是比CTC更完美的,而且实际使用的时候,可以玩的花样也是比较多的,比如微软的Meng Zhong博士它们的ILME、我们的Tiny Transducer[1]中的一些小技巧,都非常有效。如果你想迅速部署一个模型,你可以使用WeNet,目前WeNet只是支持Conformer-CTC,Conformer的实现主要是参考了Espnet,如果你想训练一个轻量级的小模型,采用其他结构,那么就还是需要自己编码实现。据我了解,目前各个公司基本上都有一套自己的基于pytorch的端到端系统,因为每个公司自己的业务不一样,需要的模型结构肯定也不同,设备端和云端所用的模型会有很大区别,再有就是pytorch的jit导出模型,C++环境部署做的非常好,极大的简化了模型部署的难度。