美赛 6:相关性模型、回归模型(十大模型篇)
目录
三、相关性模型(SPSS)
1.皮尔逊相关系数
2.皮尔逊相关系数假设检验
3.数据正态分布检验
4.斯皮尔曼相关系数
四、回归模型(Stata)
1.多元线性回归分析
2.逐步回归分析
3.岭回归和Lasso回归
三、相关性模型(SPSS)
相关性模型涉及到两种最为常用的相关系数:皮尔逊person相关系数和斯皮尔曼spearman等级相关系数。
它们可用来衡量两个变量之间的相关性大小,根据数值满足的不同条件,我们要选择不同的相关系数进行计算。
1.皮尔逊相关系数





这里的相关系数只是用来衡量两个变量线性相关程度的指标;
也就是说,你必须先确认这两个变量是线性相关的,然后这个相关系数才能告诉你这两个变量的相关程度如何。
总结:
1.如果两个变量本身就是线性的关系,那么皮尔逊相关系数绝对值大的就是相关性强,小的就是相关性弱;
2.在不确定两个变量是什么关系的情况下,即使算出皮尔逊相关系数,发现很大,也不能说明那两个变量线性相关,甚至不能说他们相关,一定要先画出散点图来看才行。

Matlab代码:
%文件名如果有空格隔开,那么需要加引号
load 'physical fitness test.mat'
% 每一列的最小值
MIN = min(Test);
% 每一列的最大值
MAX = max(Test);
% 每一列的均值
MEAN = mean(Test);
% 每一列的中位数
MEDIAN = median(Test);
% 每一列的偏度
SKEWNESS = skewness(Test);
% 每一列的峰度
KURTOSIS = kurtosis(Test);
% 每一列的标准差
STD = std(Test);
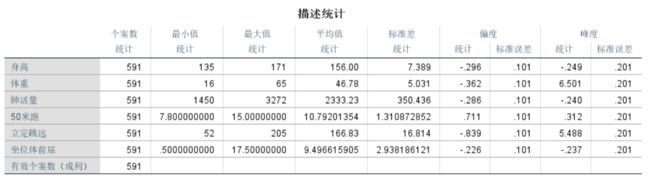
RESULT = [MIN;MAX;MEAN;MEDIAN;SKEWNESS;KURTOSIS;STD] 描述性统计(SPSS)
矩阵散点图(SPSS)


Matlab代码:
R = corrcoef(Test)将得到的结果复制到Excel中进行作图。

2.皮尔逊相关系数假设检验


Python代码:
import numpy as np
import matplotlib.pyplot as plt
n=30
r=np.linspace(-0.999999,0.999999,10000)
t=r*np.sqrt((n-2)/(1-np.square(r)))
x=np.linspace(-50,50,10000)
y=np.array([len(np.where(t
皮尔逊双变量相关性(SPSS)

3.数据正态分布检验


Matlab代码:
% 检验第一列数据是否为正态分布
[h,p] = jbtest(Test(:,1),0.05)
[h,p] = jbtest(Test(:,1),0.01)
% 用循环检验所有列的数据
n_c = size(Test,2);
H = zeros(1,6);
P = zeros(1,6);
for i = 1:n_c
[h,p] = jbtest(Test(:,i),0.05);
H(i)=h;
P(i)=p;
end
disp(H)
disp(P) 

SPSS正态性检验:图中“显著性”即为P值

Matlab代码:
qqplot(Test(:,1))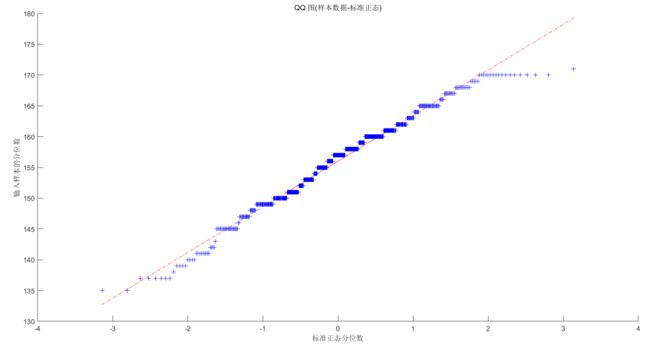
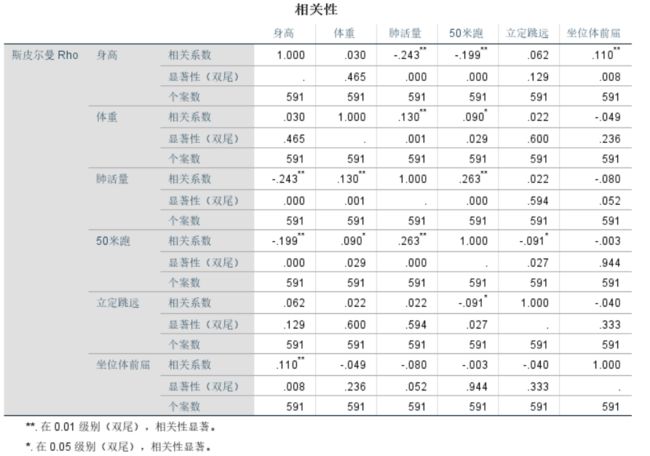
4.斯皮尔曼相关系数

斯皮尔曼相关系数被定义成等级之间的皮尔逊相关系数。

Matlaba代码:
% 必须为列向量,'表示求转置
X = [3 8 4 7 2]'
Y = [5 10 9 10 6]'
coeff = corr(X , Y , 'type' , 'Spearman')


斯皮尔曼双变量相关性(SPSS)

四、回归模型(Stata)
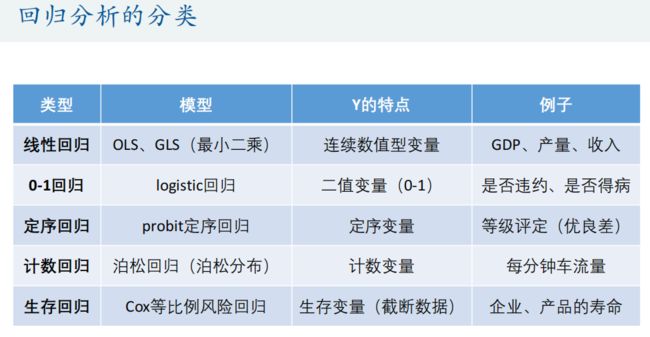
回归分析是数据分析中最基础也是最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的任务就是,通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
常见的回归分析有五类:线性回归、0-1回归、定序回归、计数回归和生存回归,其划分的依据是因变量Y的类型。
1.多元线性回归分析






Matlab代码:
%% 蒙特卡洛模拟:内生性会造成回归系数的巨大误差
% 蒙特卡洛的次数
times = 300;
R = zeros(times,1);
K = zeros(times,1);
for i = 1: times
n = 30;
x1 = -10+rand(n,1)*20;
u1 = normrnd(0,5,n,1) - rand(n,1);
x2 = 0.3*x1 + u1;
u = normrnd(0,1,n,1);
y = 0.5 + 2 * x1 + 5 * x2 + u ;
k = (n*sum(x1.*y)-sum(x1)*sum(y))/(n*sum(x1.*x1)-sum(x1)*sum(x1));
K(i) = k;
u = 5 * x2 + u;
r = corrcoef(x1,u);
R(i) = r(2,1);
end
plot(R,K,'*')
xlabel("x_1和u'的相关系数")
ylabel("k的估计值")











2.逐步回归分析


3.岭回归和Lasso回归
上文介绍了多元线性回归模型,估计回归系数使用的是OLS,并在最后讨论了异方差和多重共线性对于模型的影响。事实上,回归中关于自变量的选择大有门道,变量过多时可能会导致多重共线性问题造成回归系数的不显著,甚至造成OLS估计的失效。
岭回归和lasso回归在OLS回归模型的损失函数上加上了不同的惩罚项,该惩罚项由回归系数的函数构成,一方面,加入的惩罚项能够识别出模型中不重要的变量,对模型起到简化作用,可以看作逐步回归法的升级版;另一方面,加入的惩罚项能够让模型变得可估计,即使之前的数据不满足列满秩。




内容原作者:数学建模清风
学习用途,仅作参考。