【XGBoost】第 4 章:从梯度提升到 XGBoost
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
从装袋到提升
介绍 AdaBoost
区分梯度提升
梯度提升的工作原理
残差
学习如何从头开始构建梯度提升模型
处理自行车租赁数据集
从头开始构建梯度提升模型
在 scikit-learn 中构建梯度提升模型
修改梯度提升超参数
学习率
基础学习器
subsample
RandomizedSearchCV
XGBoost
接近大数据——梯度提升与 XGBoost
介绍系外行星数据集
预处理系外行星数据集
构建梯度提升分类器
时序模型
比较速度
概括
XGBoost 是一种独特的梯度提升形式,具有几个明显的优势,将在第 5 章XGBoost揭幕中进行解释。要了解 XGBoost 相对于传统梯度提升的优势,您必须首先了解传统梯度提升的工作原理。XGBoost 融合了传统梯度提升的一般结构和超参数。在本章中,您将发现梯度提升背后的力量,它是 XGBoost 的核心。
在本章中,您将从头开始构建梯度提升模型,然后将梯度提升模型和误差与之前的结果进行比较。特别是,您将专注于学习率超参数,以构建包括 XGBoost 在内的强大梯度提升模型。最后,您将预览一个关于系外行星的案例研究,强调需要更快的算法,这是 XGBoost 满足的大数据领域的一项关键需求。
在本章中,我们将讨论以下主要主题:
-
从装袋到提升
-
梯度提升的工作原理
-
修改梯度提升超参数
-
接近大数据——梯度提升与 XGBoost
从装袋到提升
在第 3 章,使用随机森林进行装袋时,您了解了为什么要使用集成机器学习算法,例如随机森林通过将许多机器学习模型合二为一来做出更好的预测。随机森林被归类为装袋算法,因为它们采用自举样本(决策树)的聚合。
相比之下,Boosting 从单个树的错误中学习。总体思路是根据之前树的误差来调整新树。
在 boosting 中,为每棵新树纠正错误是一种与 bagging 不同的方法。在 bagging 模型中,新树不关注以前的树。此外,新树是从头开始建造的使用自举,最终模型聚合所有单独的树。然而,在 boosting 中,每棵新树都是从前一棵树构建的。树木不是孤立运作的;相反,它们是建立在彼此之上的。
介绍 AdaBoost
AdaBoost是最早和最流行的 boosting 模型之一。在 AdaBoost 中,每棵新树都会调整它的基于先前树的误差的权重。通过调整以更高百分比影响这些样本的权重,会更加关注预测出错的预测。通过从错误中学习,AdaBoost 可以将弱学习者转变为强学习者。弱学习器是一种机器学习算法,其性能几乎不比机会好。相比之下,更强的学习者从数据中学到了相当多的东西并且表现得很好。
提升算法背后的总体思路是将弱学习者转化为强学习者。弱学习器几乎不比随机猜测好。但起步较弱的背后是有目的的。在这个总体思路的基础上,通过专注于迭代纠错而不是通过建立强大的基线模型来促进工作。如果基础模型太强,学习过程必然会受到限制,从而破坏提升模型背后的一般策略。
弱学习者通过数百次迭代转化为强学习者。从这个意义上说,一个小的优势会走很长的路。事实上,在过去的几十年中,就产生最佳结果而言,boosting 一直是最好的通用机器学习策略之一。
对 AdaBoost 的详细研究超出了本书的范围。像许多 scikit-learn 模型一样,在实践中实现 AdaBoost 很简单。AdaBoostRegressor和AdaBoostClassifier算法可以从 sklearn.ensemble 库下载并适合任何训练集。最重要的 AdaBoost 超参数是n_estimators,即创建强学习器所需的树(迭代)数。
笔记
有关 AdaBoost 的更多信息,请查看sklearn.ensemble.AdaBoostClassifier — scikit-learn 1.1.2 documentation的官方文档以获取分类器和https://scikit-learn.org/stable/ modules/generated/sklearn.ensemble.AdaBoostRegressor.html用于回归器。
我们现在将继续梯度提升,AdaBoost 的强大替代品,性能略有优势。
区分梯度提升
梯度提升使用与 AdaBoost 不同的方法。而梯度提升也会根据不正确的预测,它将这个想法更进一步:梯度提升完全基于前一棵树的预测错误来拟合每棵新树。也就是说,对于每棵新树,梯度提升都会查看错误,然后完全围绕这些错误构建一棵新树。新树不关心已经正确的预测。
构建一个只关注错误的机器学习算法需要一种综合方法来总结错误以做出准确的最终预测。此方法利用残差,即模型的预测值与实际值之间的差异。这是一般的想法:
梯度提升计算每棵树预测的残差,并将所有残差相加以对模型进行评分。
了解计算和求和残差至关重要,因为这个想法是 XGBoost 的核心,它是梯度提升的高级版本。当您构建自己的梯度提升版本时,计算和求和残差的过程将变得清晰。在下一节中,您将构建自己版本的梯度提升模型。首先,让我们详细了解梯度提升的工作原理。
梯度提升的工作原理
在本节中,我们将深入了解梯度提升,并通过在先前树的错误上训练新树,从头开始构建梯度提升模型。这里的关键数学思想是残差。接下来,我们将使用 scikit-learn 的梯度提升算法获得相同的结果。
残差
残差是错误和预测之间的差异给定模型的。在统计学中,通常分析残差以确定给定的线性回归模型与数据的拟合程度。
考虑以下示例:
-
自行车租赁
a)预测:759
b)结果:799
c)残差:799 - 759 = 40
-
收入
a)预测:100,000
b)结果:88,000
c)剩余:88,000 –100,000 = -12,000
如您所见,残差告诉您模型的预测与现实的差距有多大,它们可能是正面的或负面的。
这是一个显示线性回归线残差的可视化示例: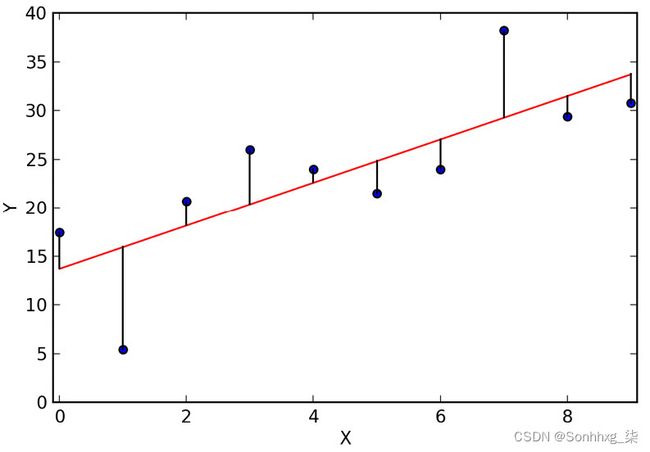
图 4.1 – 线性回归线的残差
线性回归的目标是最小化残差的平方。如图所示,可视化残差表示该线与数据的拟合程度。在统计,线性回归分析通常通过绘制残差来更深入地了解数据。
为了从头开始构建梯度提升算法,我们将计算每棵树的残差,并为残差拟合一个新模型。现在让我们这样做。
学习如何从头开始构建梯度提升模型
构建渐变从头开始提升模型将使您更深入地了解梯度提升在代码中的工作原理。在构建模型之前,我们需要访问数据并为机器学习做好准备。
处理自行车租赁数据集
我们继续骑自行车Rentals 数据集,用于将新模型与以前的模型进行比较:
-
我们将从导入pandas和numpy开始。我们还将添加一行来消除任何警告:
import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') -
现在,加载bike_rentals_cleaned数据集并查看前五行:
df_bikes = pd.read_csv('bike_rentals_cleaned.csv') df_bikes.head()您的输出应如下所示:
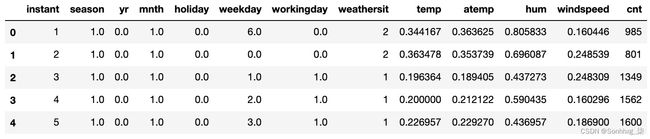
图 4.2 – 自行车租赁数据集的前五行
-
现在,将数据拆分为X和y。然后,将X和y拆分为训练集和测试集:
from sklearn.model_selection import train_test_split X_bikes = df_bikes.iloc[:,:-1] y_bikes = df_bikes.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X_bikes, y_bikes, random_state=2)
是时候从头开始构建梯度提升模型了!
从头开始构建梯度提升模型
以下是构建一个从零开始梯度提升机器学习模型:
-
将数据拟合到决策树:您可以使用max_depth值为1的决策树桩,或max_depth值为2或3的决策树。最初的决策树,称为基础学习器,不应该为准确性进行微调。我们想要一个专注于从错误中学习的模型,而不是一个严重依赖基础学习器的模型。
使用max_depth=2初始化决策树,并将其作为tree_1拟合到训练集上,因为它是我们集成中的第一棵树:
from sklearn.tree import DecisionTreeRegressor tree_1 = DecisionTreeRegressor(max_depth=2, random_state=2) tree_1.fit(X_train, y_train) -
使用训练集进行预测:梯度提升中的预测最初是使用训练集进行的,而不是使用测试集进行预测。为什么?为了计算残差,我们需要在训练阶段比较预测。在构建完所有树之后,模型构建的测试阶段就结束了。第一轮训练集的预测是通过将predict方法添加到tree_1中获得的,其中X_train作为输入:
y_train_pred = tree_1.predict(X_train) -
计算残差:残差是预测与目标列之间的差异。X_train的预测(此处定义为y_train_pred )从目标列y_train中减去,以计算残差:
y2_train = y_train - y_train_pred笔记
残差定义为y2_train,因为它们是下一棵树的新目标列。
-
在残差上拟合新树:在残差上拟合新树与在训练集上拟合模型不同。主要区别在于预测。在自行车租赁数据集中,当在残差上拟合一棵新树时,我们应该逐渐得到更小的数字。
初始化一棵新树并将其拟合到X_train和残差y2_train 上:
tree_2 = DecisionTreeRegressor(max_depth=2, random_state=2) tree_2.fit(X_train, y2_train) -
重复步骤 2-4:作为过程继续下去,残差应该从正负方向逐渐接近0 。迭代继续估计器的数量n_estimators。
让我们对第三棵树重复该过程,如下所示:
y2_train_pred = tree_2.predict(X_train) y3_train = y2_train - y2_train_pred tree_3 = DecisionTreeRegressor(max_depth=2, random_state=2) tree_3.fit(X_train, y3_train)这个过程可能会持续数十、数百或数千棵树。在正常情况下,你肯定会继续前进。将弱学习器转变为强学习器需要不止几棵树。然而,由于我们的目标是了解梯度提升在幕后的工作原理,所以现在我们将继续讨论总体思路。
-
对结果求和:对结果求和需要使用测试集对每棵树进行预测,如下所示:
y1_pred = tree_1.predict(X_test) y2_pred = tree_2.predict(X_test) y3_pred = tree_3.predict(X_test)由于预测是正差和负差,因此对预测求和应该会产生更接近目标列的预测,如下所示:
y_pred = y1_pred + y2_pred + y3_pred -
最后,让我们计算均方误差( MSE ) 以获得如下结果:
from sklearn.metrics import mean_squared_error as MSE MSE(y_test, y_pred)**0.5这是预期的输出:
911.0479538776444
对弱者来说还不错还不强的学习者!现在让我们尝试使用 scikit-learn 获得相同的结果。
在 scikit-learn 中构建梯度提升模型
让我们看看是否我们可以使用 scikit-learn 的GradientBoostingRegressor获得与上一节相同的结果。这个可以通过一些超参数调整来完成。使用GradientBoostingRegressor的优点是构建速度更快,实现更容易:
-
首先,从sklearn.ensemble库中导入回归器:
from sklearn.ensemble import GradientBoostingRegressor -
在初始化GradientBoostingRegressor时,有几个重要的超参数。要获得相同的结果,必须匹配max_depth=2和random_state=2。此外,由于只有三棵树,我们必须有n_estimators=3。最后,我们必须设置learning_rate=1.0超参数。我们很快就会对learning_rate有很多话要说:
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=3, random_state=2, learning_rate=1.0) -
现在,模型已初始化,可以拟合训练数据并进行评分针对测试数据:
gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) MSE(y_test, y_pred)**0.5结果如下:
911.0479538776439
结果与小数点后 11 位相同!
回想一下,梯度提升的目的是建立一个具有足够多树的模型,以将弱学习器转变为强学习器。这很容易通过将迭代次数n_estimators更改为更大的数字来完成。
-
让我们用 30 个估计器构建梯度提升回归器并对其进行评分:
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=30, random_state=2, learning_rate=1.0) gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) MSE(y_test, y_pred)**0.5结果如下:
857.1072323426944
分数是一种进步。现在让我们看一下 300 个估算器:
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=300, random_state=2, learning_rate=1.0) gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) MSE(y_test, y_pred)**0.5结果是这样的:
936.3617413678853
这是一个惊喜!成绩越来越差了!我们被误导了吗?梯度提升不就是它被破解的全部吗?
每当你得到一个出人意料的结果,值得仔细检查代码。现在,我们更改了learning_rate并没有多说。那么,如果我们删除learning_rate=1.0并使用 scikit-learn 默认值会发生什么?
让我们来了解一下:
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=300, random_state=2)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
MSE(y_test, y_pred)**0.5
结果是这样的:
653.7456840231495
极好的!通过使用 learning_rate 超参数的 scikit-learn 默认值,分数已从936更改为654。
在下一节中,我们将详细了解不同的梯度提升超参数,重点是learning_rate超参数。
修改梯度提升超参数
在本节中,我们将关注learning_rate,最重要的梯度提升超参数,可能除了n_estimators 之外,模型中的迭代或树的数量。我们还将调查一些树超参数和子样本,这会导致随机梯度提升。此外,我们将使用RandomizedSearchCV并将结果与 XGBoost 进行比较。
学习率
在最后部分,将GradientBoostingRegressor的learning_rate值从1.0更改为 scikit-learn 的默认值0.1,从而获得了巨大的收益。
learning_rate,也称为收缩,收缩的贡献单独的树,以便在构建模型时没有树有太大的影响。如果整个集成是从一个基础学习器的错误中构建的,如果不仔细调整超参数,模型中的早期树可能会对后续开发产生太大影响。learning_rate限制单个树的影响。一般来说,随着n_estimators,树的数量上升,learning_rate应该下降。
确定最佳learning_rate值需要改变n_estimators。首先,让我们保持n_estimators不变,看看learning_rate自己做了什么。learning_rate范围从0到1。learning_rate值为1表示不进行任何调整。默认值0.1表示树的影响权重为 10%。
这是一个合理的范围:
learning_rate_values = [0.001, 0.01, 0.05, 0.1, 0.15, 0.2, 0.3, 0.5, 1.0]
接下来,我们将通过构建和评分一个新的GradientBoostingRegressor来遍历这些值,以查看分数的比较:
for value in learning_rate_values:
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=300, random_state=2, learning_rate=value)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
rmse = MSE(y_test, y_pred)**0.5
print('Learning Rate:', value, ', Score:', rmse)学习率值和分数如下:
Learning Rate: 0.001 , Score: 1633.0261400367258
Learning Rate: 0.01 , Score: 831.5430182728547
Learning Rate: 0.05 , Score: 685.0192988749717
Learning Rate: 0.1 , Score: 653.7456840231495
Learning Rate: 0.15 , Score: 687.666134269379
Learning Rate: 0.2 , Score: 664.312804425697
Learning Rate: 0.3 , Score: 689.4190385930236
Learning Rate: 0.5 , Score: 693.8856905068778
Learning Rate: 1.0 , Score: 936.3617413678853尽你所能从输出看,默认learning_rate值0.1给出了 300 棵树的最佳分数。
现在让我们改变n_estimators。使用上述代码,我们可以生成n_estimators为 30、300 和 3,000 棵树的learning_rate图,如下图所示:
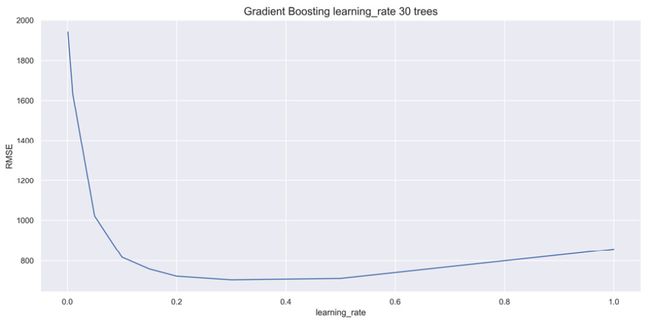
图 4.3 – 30 棵树的 learning_rate 图
正如你可以看到 30 棵树的learning_rate值峰值在0.3左右。
现在,让我们看一下3,000 棵树的learning_rate图:

图 4.4——3000 棵树的 learning_rate 图
对于 3,000 棵树,learning_rate值在第二个值处达到峰值,即0.05。
这些图表突出了同时调整learning_rate和n_estimators的重要性。
基础学习器
最初的决定梯度提升回归器中的树被称为基础学习器,因为它位于集成的基础上。这是第一个过程中的学习者。这里的学习者一词表示弱学习者转变为强学习者。
尽管不需要对基础学习器进行微调以提高准确性,如第 2 章“深度决策树”中所述,但当然可以调整基础学习器以提高准确性。
例如,我们可以选择max_depth值为1、2、3或4并按如下方式比较结果:
depths = [None, 1, 2, 3, 4]
for depth in depths:
gbr = GradientBoostingRegressor(max_depth=depth, n_estimators=300, random_state=2)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
rmse = MSE(y_test, y_pred)**0.5
print('Max Depth:', depth, ', Score:', rmse)结果如下:
Max Depth: None , Score: 867.9366621617327
Max Depth: 1 , Score: 707.8261886858736
Max Depth: 2 , Score: 653.7456840231495
Max Depth: 3 , Score: 646.4045923317708
Max Depth: 4 , Score: 663.048387855927max_depth值为3可获得最佳结果。
其他基础学习器超参数,如第 2 章,深度决策树中所述,可以以类似的方式进行调整。
subsample
subsample是样本的子集。由于样本是行,因此行的子集意味着所有行可能不是在构建每棵树时包括在内。通过将子样本从1.0更改为更小的小数,树只选择构建阶段的样本百分比。例如,subsample=0.8将为每棵树选择 80% 的样本。
继续使用max_depth=3,我们尝试了一系列子样本百分比来改善结果:
samples = [1, 0.9, 0.8, 0.7, 0.6, 0.5]
for sample in samples:
gbr = GradientBoostingRegressor(max_depth=3, n_estimators=300, subsample=sample, random_state=2)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
rmse = MSE(y_test, y_pred)**0.5
print('Subsample:', sample, ', Score:', rmse)结果如下:
Subsample: 1 , Score: 646.4045923317708
Subsample: 0.9 , Score: 620.1819001443569
Subsample: 0.8 , Score: 617.2355650565677
Subsample: 0.7 , Score: 612.9879156983139
Subsample: 0.6 , Score: 622.6385116402317
Subsample: 0.5 , Score: 626.9974073227554子样本值300 棵树的0.7和3的max_depth产生了最好的分数。
当subsample不等于1.0时,模型被归类为随机梯度下降,其中随机表示模型中固有的一些随机性。
RandomizedSearchCV
我们有一个很好的工作模型,但我们还没有执行网格搜索,如第 2 章,深度决策树中所述。我们的初步分析表明,以max_depth=3、subsample=0.7、n_estimators=300和learning_rate = 0.1为中心的网格搜索是一个不错的起点。我们已经表明,随着n_estimators上升,learning_rate应该下降:
-
这是一个可能的起点:
params={'subsample':[0.65, 0.7, 0.75], 'n_estimators':[300, 500, 1000], 'learning_rate':[0.05, 0.075, 0.1]}由于n_estimators从 300 的起始值上升,learning_rate从0.1的起始值下降。让我们保持max_depth=3来限制方差。
有了 27 种可能的超参数组合,我们使用RandomizedSearchCV尝试其中的 10 种组合,希望找到一个好的模型。
笔记
虽然GridSearchCV有 27 种组合是可行的,但在某些时候你会遇到太多的可能性,而RandomizedSearchCV将变得必不可少。我们在这里使用RandomizedSearchCV进行练习并加快计算速度。
-
让我们导入RandomizedSearchCV并初始化一个梯度提升模型:
from sklearn.model_selection import RandomizedSearchCV gbr = GradientBoostingRegressor(max_depth=3, random_state=2) -
接下来,使用gbr和params作为输入以及迭代次数、评分和折叠数来初始化RandomizedSearchCV 。回想一下,n_jobs=-1可能会加快计算速度,而random_state=2可以确保结果的一致性:
rand_reg = RandomizedSearchCV(gbr, params, n_iter=10, scoring='neg_mean_squared_error', cv=5, n_jobs=-1, random_state=2) -
现在拟合模型在训练集上并获得最佳参数和分数:
rand_reg.fit(X_train, y_train) best_model = rand_reg.best_estimator_ best_params = rand_reg.best_params_ print("Best params:", best_params) best_score = np.sqrt(-rand_reg.best_score_) print("Training score: {:.3f}".format(best_score)) y_pred = best_model.predict(X_test) rmse_test = MSE(y_test, y_pred)**0.5 print('Test set score: {:.3f}'.format(rmse_test))结果如下:
Best params: {'learning_rate': 0.05, 'n_estimators': 300, 'subsample': 0.65} Training score: 636.200 Test set score: 625.985从这里开始,值得通过单独或成对更改参数来进行试验。尽管目前最好的模型有n_estimators=300 ,但通过仔细调整learning_rate值,提高这个超参数肯定会获得更好的结果。子样本也可以进行试验。
-
之后几轮实验,我们得到以下模型:
gbr = GradientBoostingRegressor(max_depth=3, n_estimators=1600, subsample=0.75, learning_rate=0.02, random_state=2) gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) MSE(y_test, y_pred)**0.5结果如下:
596.9544588974487
n_estimators在1600的值较大,在0.02的learning_rate值较小,a0.75的可比较子样本值和相同的max_depth值3 ,我们在597处获得了最好的均方根误差( RMSE ) 。
或许可以做得更好。我们鼓励您尝试!
现在,让我们看看 XGBoost 与使用迄今为止所涵盖的相同超参数的梯度提升有何不同。
XGBoost
XGBoost 是一个具有相同一般结构的梯度提升的高级版本,这意味着它通过对树的残差求和来将弱学习器转换为强学习器。
与上一节中超参数的唯一区别是 XGBoost 将learning_rate称为eta。
让我们构建一个具有相同超参数的 XGBoost 回归器来比较结果。
从xgboost导入XGBRegressor,然后对模型进行初始化和评分,如下所示:
from xgboost import XGBRegressor
xg_reg = XGBRegressor(max_depth=3, n_estimators=1600, eta=0.02, subsample=0.75, random_state=2)
xg_reg.fit(X_train, y_train)
y_pred = xg_reg.predict(X_test)
MSE(y_test, y_pred)**0.5结果是这样的:
584.339544309016
成绩更好。至于为什么分数更好的原因将在下一章,第 5 章,XGBoost Unveiled中揭晓。
准确性和速度是构建机器学习模型时最重要的两个概念,我们已经多次证明 XGBoost 非常准确。XGBoost 通常比梯度提升更受欢迎,因为它始终提供更好的结果,而且速度更快,如以下案例研究所示。
接近大数据——梯度提升与 XGBoost
在里面现实世界,数据集可能是巨大的,有数万亿个数据点。将工作限制在一台计算机上可能是不利的由于一台机器的资源有限。在处理大数据时,云通常用于利用并行计算机。
当数据集突破计算极限时,它们就很大。到目前为止,在本书中,通过将数据集限制为数万行和一百列或更少的列,应该没有明显的时间延迟,除非你遇到错误(每个人都会发生)。
在本节中,我们会随着时间的推移检查系外行星。该数据集有 5,087 行和 3,189 列,记录了恒星生命周期不同时间的光通量。将列和行相乘会产生 150 万个数据点。使用 100 棵树的基线,我们需要 1.5 亿个数据点来构建模型。
在本节中,我的 2013 MacBook Air 的等待时间约为 5 分钟。新电脑应该更快。我选择了系外行星数据集,以便等待时间发挥重要作用,而不会长时间占用您的计算机。
介绍系外行星数据集
这exoplanet 数据集取自 Kaggle,日期为 2017 年左右:https ://www.kaggle.com/keplesmachines/kepler-labelled-time-series-data 。数据集包含有关星光的信息。每一行都是一颗单独的星星,而这些列随着时间的推移显示出不同的光模式。除了光模式之外,如果恒星拥有系外行星,则系外行星列标记为2 ;否则,它被标记为1。
数据集记录光通量来自万千星辰。光通量,通常称为光通量,是可感知的星星的亮度。
笔记
感知亮度与实际亮度不同。例如,一颗非常明亮的恒星在很远的地方可能有很小的光通量(看起来很暗),而一颗中等亮度的恒星,比如太阳,可能有很大的光通量(看起来很亮)。
当单个恒星的光通量周期性变化时,这颗恒星可能正在绕轨道运行由系外行星。假设是,当一颗系外行星在恒星前面运行时,它会阻挡一小部分光线,从而减少感知到的亮度非常轻微。
小费
发现系外行星是罕见的。关于一颗恒星是否拥有系外行星的预测列,很少有正面案例,导致数据集不平衡。不平衡的数据集需要额外的预防措施。我们将在第 7 章“使用 XGBoost 发现系外行星”中介绍不平衡数据集,并在其中详细介绍该数据集。
接下来,让我们访问系外行星数据集并为机器学习做好准备。
预处理系外行星数据集
系外行星数据集已上传到我们的 GitHub 页面,网址为Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn/Chapter04 at master · PacktPublishing/Hands-On-Gradient-Boosting-with-XGBoost-and-Scikit-learn · GitHub。
以下是为机器学习加载和预处理系外行星数据集的步骤:
-
将exoplanets.csv下载到与 Jupyter Notebook 相同的文件夹中。然后,打开文件并查看:
df = pd.read_csv('exoplanets.csv') df.head()DataFrame 将如下图所示:
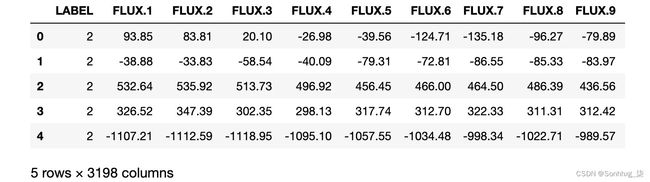
图 4.5 – 系外行星数据帧
由于空间限制,并未显示所有列。通量列是浮点数,而标签列是2表示系外行星恒星,1表示非系外行星恒星。
-
让我们确认所有列是数字的df.info():
df.info()结果如下:
RangeIndex: 5087 entries, 0 to 5086 Columns: 3198 entries, LABEL to FLUX.3197 dtypes: float64(3197), int64(1) memory usage: 124.1 MB 从输出中可以看出,3197列是浮点数,1列是int,所以所有列都是数字的。
-
现在,让我们使用以下代码确认空值的数量:
df.isnull().sum().sum()输出如下:
0
输出显示没有空值。
-
由于所有列都是数字,没有空值,我们可以将数据分为训练和测试套。请注意,第 0 列是目标列y,所有其他列是预测列X:
X = df.iloc[:,1:] y = df.iloc[:,0] X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2)
是时候构建一个梯度增强分类器来预测恒星是否拥有系外行星了。
构建梯度提升分类器
梯度提升分类器的工作方式与梯度提升回归器相同。区别主要在于得分。
让我们首先导入GradientBoostingClassifer和XGBClassifier以及accuracy_score,以便我们可以比较两个模型:
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score接下来,我们需要一种使用计时器来比较模型的方法。
时序模型
Python 带有一个时间库,可以用来标记时间。一般的想法是在计算之前和之后标记时间。这些时间之间的差异告诉我们计算需要多长时间。
时间库导入如下:
import time在time库中,.time()方法以秒为单位标记时间。
例如,通过使用time.time()在计算之前和之后分配开始和结束时间来查看运行df.info()需要多长时间:
start = time.time()
df.info()
end = time.time()
elapsed = end - start
print('\nRun Time: ' + str(elapsed) + ' seconds.')这输出如下:
RangeIndex: 5087 entries, 0 to 5086
Columns: 3198 entries, LABEL to FLUX.3197
dtypes: float64(3197), int64(1)
memory usage: 124.1 MB 运行时如下:
Run Time: 0.0525362491607666 seconds.
您的结果将与我们的不同,但希望它在同一个球场上。
现在让我们使用前面的代码标记时间,将GradientBoostingClassifier和XGBoostClassifier与 exoplanet 数据集的速度进行比较。
小费
Jupyter Notebooks 带有神奇的功能,在命令前用%符号表示。%timeit就是这样一种神奇的功能。%timeit不是计算运行一次代码需要多长时间,而是计算多次运行代码需要多长时间。有关魔术函数的更多信息,请参阅ipython.readthedocs.io/en/stable/interactive/magics.html。
比较速度
是时候与GradientBoostingClassifier和XGBoostClassifier比赛了系外行星数据集。我们设置了 max_depth=2和n_estimators=100来限制模型的大小。让我们从GradientBoostingClassifier开始:
-
首先,我们将标记开始时间。建立模型并评分后,我们将标记结束时间。以下代码可能需要大约 5 分钟才能运行,具体取决于您的计算机速度:
start = time.time() gbr = GradientBoostingClassifier(n_estimators=100, max_depth=2, random_state=2) gbr.fit(X_train, y_train) y_pred = gbr.predict(X_test) score = accuracy_score(y_pred, y_test) print('Score: ' + str(score)) end = time.time() elapsed = end - start print('\nRun Time: ' + str(elapsed) + ' seconds')结果是这样的:
Score: 0.9874213836477987 Run Time: 317.6318619251251 secondsGradientBoostingRegressor在我的 2013 MacBook Air 上运行了 5 分钟。对于旧计算机上的 1.5 亿个数据点来说还不错。
笔记
虽然 98.7% 的分数通常在准确性方面非常出色,但不平衡数据集的情况并非如此,正如您将在第 7 章“使用 XGBoost 发现系外行星”中看到的那样。
-
接下来,我们将构建一个具有相同超参数的XGBClassifier模型并以同样的方式标记时间:
start = time.time() xg_reg = XGBClassifier(n_estimators=100, max_depth=2, random_state=2) xg_reg.fit(X_train, y_train) y_pred = xg_reg.predict(X_test) score = accuracy_score(y_pred, y_test) print('Score: ' + str(score)) end = time.time() elapsed = end - start print('Run Time: ' + str(elapsed) + ' seconds')结果如下:
Score: 0.9913522012578616
Run Time: 118.90568995475769 seconds
在我的 2013 MacBook Air 上,XGBoost 只用了不到 2 分钟,速度是原来的两倍多。它也更准确半个百分点。
在大数据方面,两倍速度的算法可以节省数周或数月的计算时间和资源。这种优势在大数据领域是巨大的。
在提升领域,XGBoost 因其无与伦比的速度和令人印象深刻的准确性而成为首选模型。
至于系外行星数据集,将在第 7 章“使用 XGBoost 发现系外行星”中重新讨论,这是一个重要的案例研究,揭示了使用不平衡数据集的挑战以及应对这些挑战的各种潜在解决方案。
笔记
我最近购买了 2020 款 MacBook Pro 并更新了所有软件。使用相同代码的时间差异是惊人的:
梯度提升运行时间:197.38 秒
XGBoost 运行时间:8.66 秒
相差10倍以上!
概括
在本章中,您了解了 bagging 和 boosting 之间的区别。您通过从头开始构建梯度提升回归器了解了梯度提升的工作原理。您实现了各种梯度提升超参数,包括learning_rate、n_estimators、max_depth和subsample,这会导致随机梯度提升。最后,您使用大数据通过比较GradientBoostingClassifier和XGBoostClassifier的时间来预测恒星是否有系外行星,其中XGBoostClassifier的出现速度是两倍到十倍以上,而且更准确。
学习这些技能的好处是您现在了解何时应用 XGBoost 而不是类似的机器学习算法,如梯度提升。您现在可以通过正确利用核心超参数(包括n_estimators和learning_rate )来构建更强大的 XGBoost 和梯度提升模型。此外,您已经开发出对所有计算进行计时的能力,而不是依赖直觉。
恭喜!您已完成所有 XGBoost 预备章节。到目前为止,目的一直是在更大的 XGBoost 叙述中向您介绍机器学习和数据分析。目的是展示对 XGBoost 的需求是如何从集成方法、提升、梯度提升和大数据中产生的。
下一章将通过对 XGBoost 的高级介绍开始我们旅程的新旅程,除了 XGBoost 为提高速度而进行的硬件修改外,您还将了解 XGBoost 算法背后的数学细节。您还将在有关发现希格斯玻色子的历史相关案例研究中使用原始 Python API 构建 XGBoost 模型。接下来的章节重点介绍了令人兴奋的细节、优势、细微差别以及技巧和技巧,以构建您可以在未来几年使用的快速、高效、强大和行业就绪的 XGBoost 模型。