TernausNet论文笔记及结构代码
原文地址:U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
Abstract
基于像素的图像分割是计算机视觉领域的一项重要任务。由编码器和解码器组成的经典U-Net结构在医学图像、卫星图像等的分割中非常流行。通常,在ImageNet等大数据集上预先训练的网络中,使用权值初始化的神经网络比在小数据集上从头开始训练的神经网络表现出更好的性能。在一些实际应用中,尤其是在医疗和交通安全方面,模型的准确性至关重要。在本文中,我们演示了如何通过使用预训练编码器来改进U-Net类型的体系结构。我们的代码和相应的预训练权重可在https://github.com/ternaus/TernausNet.我们比较了三种权值初始化方案:LeCun uniform、使用VGG11权值的编码器和在Carvana数据集上训练的全网络。这种网络架构是Kaggle:Carvana图像掩蔽挑战赛获奖方案(735名中排名第一)的一部分。
Keywords—Computer Vision, Image Segmentation, Image Recognition, Deep learning, Medical Image Processing, Satellite Imagery.
**关键词:**计算机视觉,图像分割,图像识别,深度学习,医学图像处理,卫星图像。
1、INTRODUCTION
随着计算机硬件的民主化,进行密集计算的最新进展使研究人员能够使用具有数百万自由参数的模型。卷积神经网络(CNN)已经在图像分类、目标检测、场景理解等方面取得了成功。对于几乎所有的计算机视觉问题,基于CNN的方法都优于其他技术,在许多情况下甚至超过了相应领域的人类专家。现在几乎所有的计算机视觉应用都试图利用深度学习技术来改进传统方法。它们影响着我们的日常生活,这些技术的潜在用途看起来确实令人印象深刻。
可靠的图像分割是计算机视觉的重要任务之一。这个问题对于医学成像尤其重要,因为医学成像可以潜在地提高我们的诊断能力和现场理解能力,从而制造安全的智能医疗设备。密集图像分割实质上是将图像分割成有意义的区域,这可以看作是一项像素级的分类任务。解决这类问题最直接(也是最慢)的方法是手动分割图像。然而,这是一个耗时的过程,当涉及人工数据管理人员时,容易出现不可避免的错误和不一致。自动处理提供了一种系统化的方法,可以在获取图像后立即对图像进行分割。该过程需要提供必要的精度,以便在生产环境中发挥作用。
在过去几年中,人们提出了不同的方法来解决创建CNN的问题,该CNN可以在一次向前传递中生成整个输入图像的分割图。最成功的最先进的深度学习方法之一是基于完全卷积网络(FCN)[2]。该方法的主要思想是使用CNN作为一个强大的特征提取工具,通过卷积一个取代完全连接的层来输出空间特征图,而不是分类分数。这些地图进一步上采样,以产生密集的像素级输出。该方法允许以端到端的方式训练CNN,以便对任意大小的输入图像进行分割。此外,与标准数据集(如PASCAL VOC[3])上的常用方法相比,该方法在分割精度方面取得了改进。该方法已得到进一步改进,现称为U-Net神经网络[4]。U-Net体系结构使用跳过连接将低级特征映射与高级特征映射相结合,从而实现精确的像素级定位。上采样部分的大量特征通道允许将上下文信息传播到更高分辨率的层。这种网络结构在卫星图像分析[5]和医学图像分析[6]、[7]等二值图像分割竞赛中得到了证明。
在本文中,我们展示了如何通过使用预先训练好的权重轻松提高U-Net的性能。作为一个例子,我们展示了这种方法在航空图像标记数据集[8]中的应用,该数据集包含几个高分辨率城市的航空图像。图像的每个像素都被标记为属于“building”或“not building”类。成功应用这种体系结构和初始化方案的另一个例子是Kaggle Carvana图像分割比赛[9],其中一位作者将其作为获胜(735支队伍中排名第一)解决方案的一部分。
2、NETWORK ARCHITECTURE
一般来说,U-Net体系结构包括捕捉上下文的收缩路径和实现精确定位的对称扩展路径(例如,参见图1)。收缩路径遵循卷积网络的典型结构,交替进行卷积和池运算,并逐步减少特征图的采样,同时增加每层特征图的数量。扩展路径中的每一步都由特征映射的上采样和卷积组成。
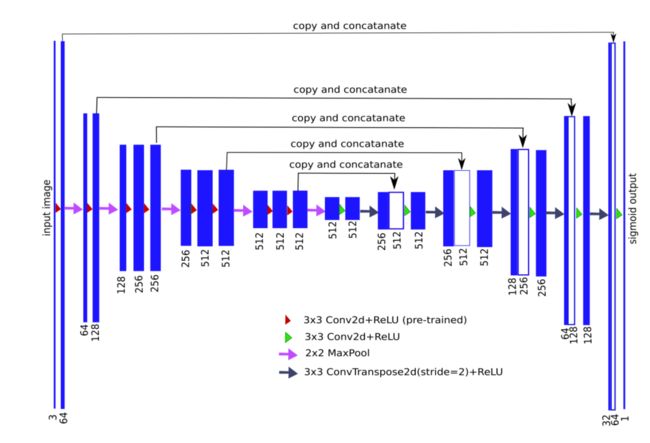
注释:编码器-解码器神经网络结构也称为U-Net,其中VGG11神经网络没有完全连接的层作为其编码器。每个蓝色矩形块表示经过一系列变换的multi-channel features map。棒的高度显示相对贴图大小(以像素为单位),而它们的宽度与通道数成正比(通道数显式对应到相应的棒)。在左侧编码部分,信道数逐级增加,而在右侧解码部分,信道数逐级减少。顶部的箭头显示了每个编码层的信息传输,并将其连接到相应的解码层。
因此,扩展分支提高了输出的分辨率。为了定位上采样特征,扩展路径通过 skip-connections将其与收缩路径的高分辨率特征相结合[4]。模型的输出是一个逐像素掩码,显示每个像素的类别。事实证明,这种体系结构对于数据量有限的分割问题非常有用,例如参见[5]。
U-Net能够从相对较小的训练集中学习。在大多数情况下,用于图像分割的数据集最多由数千张图像组成,因为手工准备掩模是一个非常昂贵的过程。通常,U-Net从零开始训练,从随机初始化的权重开始。众所周知,在不过度拟合的情况下,训练网络的数据集应该比较大,数以百万计的图像。在Imagenet[10]数据集上训练的网络被广泛用作其他任务中网络权重初始化的来源。通过这种方式,学习过程可以针对网络中未经预训练的几层(有时仅针对最后一层)进行,以考虑数据集的特征。 (预训练方式,保留几层与训练数据,另外的进行修正,减少数据集量和运算量)
作为U-Net网络中的编码器,我们使用了相对简单的VGG系列CNN[11],它由11个连续层组成,称为VGG11,见图2。VGG11包含七个卷积层,每个层后面都有一个ReLU激活函数,以及五个max轮询操作,每个操作将特征映射减少2。所有卷积层都有3×3个核,通道数如图2所示。第一个卷积层产生64个信道,然后,随着网络的加深,在每次最大池操作之后,信道数量会翻倍,直到达到512个。在以下图层上,通道数不变。
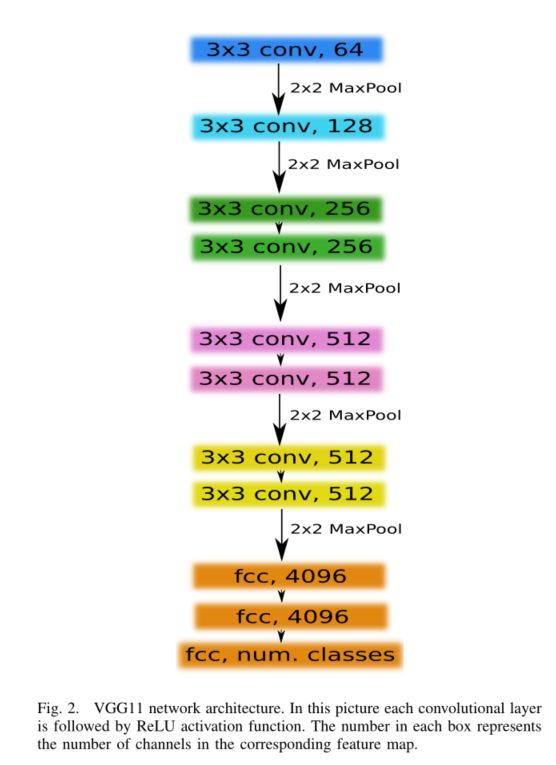
为了构造一个编码器,我们移除了完全连接的层,并将其替换为一个由512个通道组成的卷积层,作为网络的瓶颈中心部分,将编码器与解码器分离。为了构造解码器,我们使用转置卷积层,将特征映射的大小增加一倍,同时将通道数减少一半。然后将转置卷积的输出与解码器的相应部分的输出级联。通过卷积运算处理生成的特征映射,以保持通道数与对称编码器项中的通道数相同。该上采样过程重复5次,以与5个最大池配对,如图1所示。从技术上讲,完全连接的层可以接受任何大小的输入,但因为我们有5个最大池层,每个池层对一个图像进行两次下采样,只有边可被32( 2 5 2^5 25)整除的图像可以用作当前图像的输入
3、RESULTS
我们将我们的模型应用于Inria航空图像标记数据集[8]。该数据集由180张欧洲和美国城市住区的航空图像组成,标记为建筑类和非建筑类。数据集中的每个图像都是RGB,分辨率为5000×5000像素,其中每个像素对应于30×30 c m 2 cm^2 cm2的地球表面。我们使用了30张图像(火车组中每6个城市有5张)进行验证,如[12](valid.IoU ≃ \simeq ≃ 0.647)和[13](best-valid.IoU ≃ \simeq ≃ 0.73)所示,并在100个epochs的剩余150张图像上对网络进行了training。随机crops768×768用于训练,中心crops1440×1440用于验证。学习率为0.001的Adam作为优化算法[14]。
我们选择Jaccard指数作为评价指标。它可以解释为有限个集合之间的相似性度量。两组A和B之间相似性度量的并集上的交集可定义为:

正常化条件发生时:
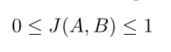
每个图像都是由像素组成的。为了适应离散对象的最后一个表达式,我们可以用以下方式编写它

其中, y i y_{i} yi是对应像素i的二进制值(标签),而$\hat{y_{i}} $是该像素的预测概率。
由于我们可以考虑图像分割任务作为像素分类问题,我们还使用共同损失函数的二进制分类任务-二进制交叉熵(就是一个二分类的交叉熵函数),定义为:
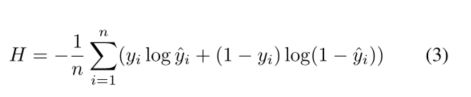
结合这些表达式,我们可以推广损失函数,即,

因此,最小化这个损失函数,我们同时最大化预测正确像素的概率,并最大化掩模和相应预测之间的交集J。有关更多详细信息,请参见[5]。
在给定神经网络的输出,我们得到一幅图像,其中每个像素对应于检测感兴趣区域的概率。输出图像的大小与输入图像一致。为了只有二进制像素值,我们选择阈值0.3。这个数字可以通过验证数据集找到,对于我们的广义损失函数和许多不同的图像数据集来说,它是非常普遍的。对于不同的损失函数,这个数字是不同的,应该单独找到。所有低于指定阈值的像素值,我们设置为零,而所有高于阈值的像素值,我们设置为1。然后,将输出图像中的每个像素乘以255,我们可以得到一个黑白预测掩模
在我们的实验中,我们测试了3个U-Net,它们的结构与图1所示的相同,只是在权重初始化方面有所不同。对于基本模型,我们使用由LeCun一致初始值设定项初始化的网络。在此初始值设定项中,样本从内部均匀分布中提取[-L, L],其中$L = \sqrt{\frac{1}{f_{in}}} , , ,{f_{in}}$是权重张量中的输入单位数。该方法在pytorch[15]中实现,作为卷积层中权重初始化的默认方法。接下来,我们使用与VGG11编码器相同的架构,在ImageNet上预先训练,而解码器中的所有层都由LeCun统一初始化器初始化。然后,作为最后一个例子,我们使用在Carvana数据集[9](编码器和解码器)上预训练权重的网络。因此,在100个epochs,之后,我们得到以下验证结果:
- LeCun uniform initializer: IoU = 0.593
- The Encoder is pre-trained on ImageNet: IoU = 0.686
- Fully pre-trained U-Net on Carvana: IoU = 0.687
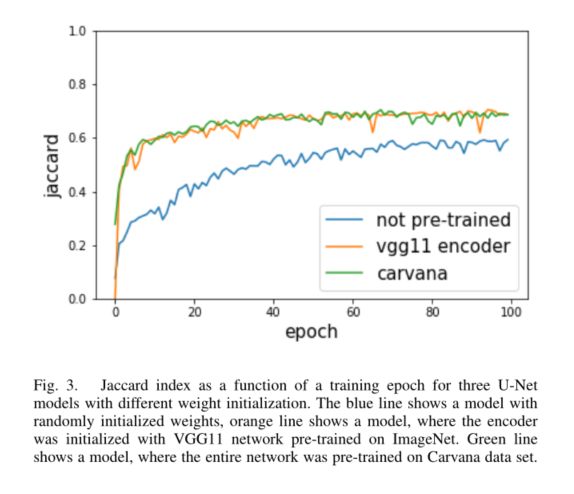
图3中的验证学习曲线显示了我们方法的优点。首先,与未经预训练的网络相比,预训练的模型收敛到稳定值的速度要快得多。此外,预训练模型的稳态值似乎更高。由这三个模型预测的Ground truth以及三个遮罩叠加在图4中的原始图像上。人们很容易注意到100个epochs后预测质量的差异。此外,使用不同的超参数优化技术或在预处理和后处理期间应用的标准计算机视觉方法,可以轻松地进一步改进Inria航空图像标签数据集结果中的验证学习曲线。

4、CONCLUSION
在本文中,我们展示了如何使用微调技术来初始化网络编码器的权值,从而提高U-Net的性能。这种神经网络被广泛应用于图像分割任务中,并在许多二值图像分割、竞赛中展示了最先进的结果。微调已经广泛用于图像分类任务,但据我们所知,U-Net类型的系列体系结构并不适用。对于图像分割问题,应该考虑更自然的微调,因为收集大量训练数据集(尤其是医学图像)并对其进行定性标记是有问题的。此外,预先训练的网络大大减少了训练时间,这也有助于防止过度适应。考虑到更先进的预训练编码器,如VGG16[11]或ResNet系列[16]的任何预训练网络,我们的方法可以进一步改进。有了这种改进的编码器,解码器就可以像我们使用的那样简单。我们的代码是麻省理工学院许可下的开源项目,可以在https://github.com/ternaus/TernausNet.
网络结构代码:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torchvision import models
def conv3x3(in_: int, out: int) -> nn.Module:
return nn.Conv2d(in_, out, 3, padding=1)
class ConvRelu(nn.Module):
def __init__(self, in_: int, out: int) -> None:
super().__init__()
self.conv = conv3x3(in_, out)
self.activation = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.conv(x)
x = self.activation(x)
return x
class DecoderBlock(nn.Module):
def __init__(
self, in_channels: int, middle_channels: int, out_channels: int
) -> None:
super().__init__()
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(
middle_channels,
out_channels,
kernel_size=3,
stride=2,
padding=1,
output_padding=1,
),
nn.ReLU(inplace=True),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.block(x)
class UNet11(nn.Module):
def __init__(self, num_filters: int = 32, pretrained: bool = False) -> None:
"""
Args:
num_filters:
pretrained:
False - no pre-trained network is used
True - encoder is pre-trained with VGG11
"""
super().__init__()
self.pool = nn.MaxPool2d(2, 2)
self.encoder = models.vgg11(pretrained=pretrained).features
self.relu = self.encoder[1]
self.conv1 = self.encoder[0]
self.conv2 = self.encoder[3]
self.conv3s = self.encoder[6]
self.conv3 = self.encoder[8]
self.conv4s = self.encoder[11]
self.conv4 = self.encoder[13]
self.conv5s = self.encoder[16]
self.conv5 = self.encoder[18]
self.center = DecoderBlock(
num_filters * 8 * 2, num_filters * 8 * 2, num_filters * 8
)
self.dec5 = DecoderBlock(
num_filters * (16 + 8), num_filters * 8 * 2, num_filters * 8
)
self.dec4 = DecoderBlock(
num_filters * (16 + 8), num_filters * 8 * 2, num_filters * 4
)
self.dec3 = DecoderBlock(
num_filters * (8 + 4), num_filters * 4 * 2, num_filters * 2
)
self.dec2 = DecoderBlock(
num_filters * (4 + 2), num_filters * 2 * 2, num_filters
)
self.dec1 = ConvRelu(num_filters * (2 + 1), num_filters)
self.final = nn.Conv2d(num_filters, 1, kernel_size=1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
conv1 = self.relu(self.conv1(x))
conv2 = self.relu(self.conv2(self.pool(conv1)))
conv3s = self.relu(self.conv3s(self.pool(conv2)))
conv3 = self.relu(self.conv3(conv3s))
conv4s = self.relu(self.conv4s(self.pool(conv3)))
conv4 = self.relu(self.conv4(conv4s))
conv5s = self.relu(self.conv5s(self.pool(conv4)))
conv5 = self.relu(self.conv5(conv5s))
center = self.center(self.pool(conv5))
dec5 = self.dec5(torch.cat([center, conv5], 1))
dec4 = self.dec4(torch.cat([dec5, conv4], 1))
dec3 = self.dec3(torch.cat([dec4, conv3], 1))
dec2 = self.dec2(torch.cat([dec3, conv2], 1))
dec1 = self.dec1(torch.cat([dec2, conv1], 1))
return self.final(dec1)
class Interpolate(nn.Module):
def __init__(
self,
size: int = None,
scale_factor: int = None,
mode: str = "nearest",
align_corners: bool = False,
):
super().__init__()
self.interp = nn.functional.interpolate
self.size = size
self.mode = mode
self.scale_factor = scale_factor
self.align_corners = align_corners
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.interp(
x,
size=self.size,
scale_factor=self.scale_factor,
mode=self.mode,
align_corners=self.align_corners,
)
return x
class DecoderBlockV2(nn.Module):
def __init__(
self,
in_channels: int,
middle_channels: int,
out_channels: int,
is_deconv: bool = True,
):
super().__init__()
self.in_channels = in_channels
if is_deconv:
"""
Paramaters for Deconvolution were chosen to avoid artifacts, following
link https://distill.pub/2016/deconv-checkerboard/
"""
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(
middle_channels, out_channels, kernel_size=4, stride=2, padding=1
),
nn.ReLU(inplace=True),
)
else:
self.block = nn.Sequential(
Interpolate(scale_factor=2, mode="bilinear"),
ConvRelu(in_channels, middle_channels),
ConvRelu(middle_channels, out_channels),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.block(x)
class UNet16(nn.Module):
def __init__(
self,
num_classes: int = 1,
num_filters: int = 32,
pretrained: bool = False,
is_deconv: bool = False,
):
"""
Args:
num_classes:
num_filters:
pretrained:
False - no pre-trained network used
True - encoder pre-trained with VGG16
is_deconv:
False: bilinear interpolation is used in decoder
True: deconvolution is used in decoder
"""
super().__init__()
self.num_classes = num_classes
self.pool = nn.MaxPool2d(2, 2)
self.encoder = torchvision.models.vgg16(pretrained=pretrained).features
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Sequential(
self.encoder[0], self.relu, self.encoder[2], self.relu
)
self.conv2 = nn.Sequential(
self.encoder[5], self.relu, self.encoder[7], self.relu
)
self.conv3 = nn.Sequential(
self.encoder[10],
self.relu,
self.encoder[12],
self.relu,
self.encoder[14],
self.relu,
)
self.conv4 = nn.Sequential(
self.encoder[17],
self.relu,
self.encoder[19],
self.relu,
self.encoder[21],
self.relu,
)
self.conv5 = nn.Sequential(
self.encoder[24],
self.relu,
self.encoder[26],
self.relu,
self.encoder[28],
self.relu,
)
self.center = DecoderBlockV2(
512, num_filters * 8 * 2, num_filters * 8, is_deconv
)
self.dec5 = DecoderBlockV2(
512 + num_filters * 8, num_filters * 8 * 2, num_filters * 8, is_deconv
)
self.dec4 = DecoderBlockV2(
512 + num_filters * 8, num_filters * 8 * 2, num_filters * 8, is_deconv
)
self.dec3 = DecoderBlockV2(
256 + num_filters * 8, num_filters * 4 * 2, num_filters * 2, is_deconv
)
self.dec2 = DecoderBlockV2(
128 + num_filters * 2, num_filters * 2 * 2, num_filters, is_deconv
)
self.dec1 = ConvRelu(64 + num_filters, num_filters)
self.final = nn.Conv2d(num_filters, num_classes, kernel_size=1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
conv1 = self.conv1(x)
conv2 = self.conv2(self.pool(conv1))
conv3 = self.conv3(self.pool(conv2))
conv4 = self.conv4(self.pool(conv3))
conv5 = self.conv5(self.pool(conv4))
center = self.center(self.pool(conv5))
dec5 = self.dec5(torch.cat([center, conv5], 1))
dec4 = self.dec4(torch.cat([dec5, conv4], 1))
dec3 = self.dec3(torch.cat([dec4, conv3], 1))
dec2 = self.dec2(torch.cat([dec3, conv2], 1))
dec1 = self.dec1(torch.cat([dec2, conv1], 1))
return self.final(dec1)