BiseNet学习:利用tensorflow2搭建BiseNet并训练完成语义分割任务
BiseNet学习:利用tensorflow2从头搭建BiseNet并训练完成语义分割任务
文章目录
- BiseNet学习:利用tensorflow2从头搭建BiseNet并训练完成语义分割任务
-
- 简介
- 1 数据集的简介
- BiseNet网络搭建
- 1)BiseNet网络各个模块简介
-
- 1.1 Spatial path搭建
- 1.2 Context path的搭建
- 1.3特征融合模块
- 2.模型的初始化,训练以及测试
-
- 2.2训练结果的评价与结果可视化
- 2.3效果可视化
- 3.结语
简介
BiseNet是于旷视于2018提出的轻量级实时语义分割网络,之所以今天谈到他是几个月前的博主在一项调研语义分割工作中,找到了它的改进版本BiseNetV2。但是最终无论如何都没有让程序跑动起来(这里可能是当时我懂得太少了,在各项如何修改错误方面完全不知道,最终留下遗憾),现在经过最近的学习,博主自认为应该可以来自己搭建网络,这样需要什么环境就可以靠自己来定,那么我就先从它的原型BiseNet开始学习并搭建。
1 数据集的简介
CityScapes数据集(https://www.cityscapes-dataset.com/),记录了欧洲各大城市的马路上数据,车载相机拍摄得照片,所以你可以在多个图片上看见有个圆圆的车标,

他的所有图片的尺寸都是 1024*2048,测试集共有2975张图片,验证集有500张图片,他已经成为了各个语义分割网络结构比拼性能的地方,甚至有排行榜
BiseNet网络搭建
阅读论文(https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1808.00897)的时候,作者认为在当前大部分语义分割网络为了提升速度(语义分割最终得到的是一张分割图,区别于之前图像分类,定位,预测等任务他们其实都只是输出一个分类值,而输出一张分割图无疑会使计算量大大增加)都大部分会通过剪裁(crop)或 resize 来限定输入大小或不断减少网络通道数,以降低计算复杂度。尽管这种方法简单而有效,但作者认为这会损失某些细节,让预测大打折扣。所以在BiseNet提出的结构中最后我们输出的会是一张和原图一模一样大小的分割图(虽然这样其实也会极大加大运行内存),但我们的精确度却会达到较高的水准

在论文中说明使用Xception在验证集能达到71.4,这里我就采用Xception来作为网络的BaseModel(ResNet,博主了解还不够好,在学了在学了),那么接下来我们就废话少说开始我们的网络搭建。
1)BiseNet网络各个模块简介
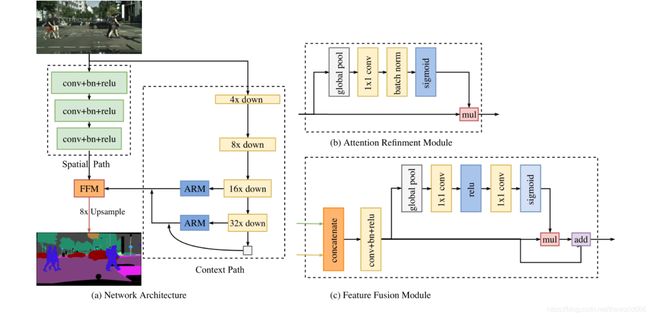
论文这里用了一张非常鲜明的图来介绍了我们的网络架构,可以看到整个模型分为了Spatial path,和contextpath两条分支,其中我们先来介绍Spatial path。
1.1 Spatial path搭建
这里论文里说明,“我们提出了一种空间路径来保留原始输入图像的空间大小并编码丰富的空间信息。空间路径中包含三层。每一层包括一个stride = 2的卷积,接着是BatchNormalization和ReLU激活(也有人说可以直接激活再BatchNormalization)。因此经过这三层卷积,该路径提取的输出特征映射是原始图像的1/8。由于地物地图的空间尺寸较大,它能够编码丰富的空间信息。”
那我们就简单了这里直接利用自定义层开始定义,由于这里每一层都是卷积+批标准化层加ReLU激活,这里我们可以直接定义一个组合层
class ConvBlock(layers.Layer):
def __init__(self,out_channels,kernel_size=3,stride=2,padding='same'):
super(ConvBlock,self).__init__()
self.conv1 = layers.Conv2D(out_channels,kernel_size=kernel_size,strides=stride,padding='same')
self.bn = layers.BatchNormalization()
def call(self, input):
x = self.conv1(input)
x = self.bn(x)
x=tf.nn.relu(x)
return x
那么对于Spatial path卷积层的卷积核数可以自己定义,我这里采用64-128-256形式不断增加,最终完成原图输入H * w *3——》H/8 * W/8 * 256
1.2 Context path的搭建
这里原文作者说明Context path这里可以直接采用Xception等预训练神经网络来作为特征提取所以我们这里也直接采用Xception网络
xception=keras.applications.Xception(include_top=False,weights='imagenet',input_shape=(1024,2048,3))
那么根据上图网络结构,我们分别需要对下采样到原图大小的1/16,1/32开始操作,那么我们先来查看xception网络结构
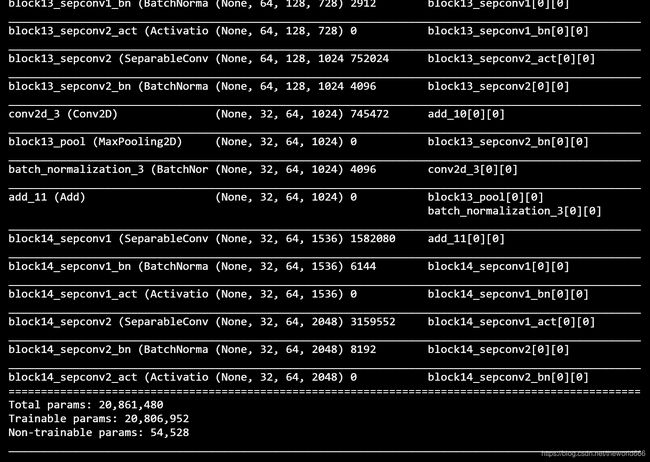
可以看到Xception的block13_sepconv2_bn , block14_sepconv2_act层就是我们要找的层(即原图的1/16,1/32),那么如何获取中间层的输出呢,我们接下来采用该方法来完成
layers_output=[xception.get_layer(layer_name).output for layer_name in layers_names]
multi_out_model=keras.models.Model(inputs=xception.input,outputs=layers_output)
那么获取了中间层的输出了,论文中说我们还有一个注意力增加(Attention Refinment Module)模块,我们通过该图得知

输入的张量分叉为两条,一条经过全局池化,卷积核大小为1的卷积,批标准化层,sigmoid激活后,最后与原输入相乘输出我们的最终结果。但是这里注意这里的全局池化并不是keras中内置的全局平均池化层,因为之后还要经过一个二维卷积层,那么我们的维度只能是四维,但原文在这里也没说太清楚,于是我去找了别人提供的代码(使用torch写的),发现这里的所谓全局池化其实是在最后channels,和长度这两维度求平均,所以我们的代码如此编写
class AttentionRefinementModule(layers.Layer):
def __init__(self,out_channels):
super(AttentionRefinementModule,self).__init__()
self.conv1=layers.Conv2D(out_channels,kernel_size=1,padding='same')
self.bn=layers.BatchNormalization()
def call(self, input):
x=tf.reduce_mean(input,axis=3,keepdims=True)
x=tf.reduce_mean(x,axis=2,keepdims=True)
#上面两行为求全局平均池化层
x=self.conv1(x)
x=self.bn(x)
x=tf.nn.sigmoid(x)
return tf.multiply(x,input)
这里要注意一点我们在写模型的时候最好是能知道输出的维度方便我们处理,这里我们推导一下输出的数据假设输入为(None, 32, 64, 2048),那么我们经过前面的全局池化后变为(None, 32, 1, 1),然后卷积激活不改变大小最后原输入(None, 32, 64, 2048)相乘最终结果为(None, 32, 64, 2048),也就是我们最终输出与输入保持了一致。
那么我们看到接下来下采样16倍和32倍和的数据还要在经过ARM和一系列的融合,这里我在代码里解释
down_16,down_32=self.ml(input)
#这里是我们刚才定义的多输出模型,他输出下采样16倍和32倍后的输出
output_arm16=self.arm16(down_16)
output_arm32=self.arm32(down_32)
#将他们经过多输出模型注意,这里输出后他们的形状与原来一模一样
tail=tf.reduce_mean(down_32,axis=3,keepdims=True)
tail=tf.reduce_mean(down_32,axis=2,keepdims=True)
output_tail=tf.multiply(output_arm32,tail)
然后我们接下来要将这边的输出与空间路径的输出连接(concat)在一起,那么经过空间路径输出为原图的1/8,所以我们这里还要将原图这里的1/16,1/32上采样原来的1/8然后再concate连接到一起
self.up1=layers.UpSampling2D(2,interpolation='bilinear') self.up2=layers.UpSampling2D(4,interpolation='bilinear')
#注这里是将自定义模型中的代码抽出来展示,上采样既可以采取反卷积,也可以直接上采样,但考虑到这是轻量级神经网络,我们这里直接上采样减少计算量
output_1=self.up1(output_arm16)
output_tail=self.up2(output_tail)
output_cp=tf.concat([output_1,output_tail],axis=-1)
最终ContextPath输出的维度是(None,128,256,3072)
那么接下来我们介绍用于融合空间路径和Contextpath两个输出的模块的特征融合模块。
1.3特征融合模块
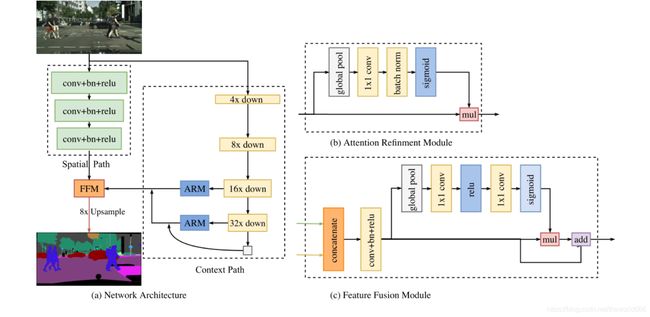
经过我们之前的叙述,他的输入是(None,128,256,256)(None,128,256,3072),他们被连接后的最终维度为(None,128,256,3328),然后接下来卷积我们这里由于是最后输出了,我们将卷积核个数变为种类数34,然后分支的与之前的分支结构相同这里不再过多赘述上代码
class FeatureFusionModule(layers.Layer):
def __init__(self,num_classes):
super(FeatureFusionModule,self).__init__()
self.convblock = ConvBlock(out_channels=num_classes,kernel_size=3,stride=1)
self.conv1 = layers.Conv2D(34,(1,1))
self.conv2 = layers.Conv2D(34,(1,1))
def call(self, input_1, input_2):
x=tf.concat([input_1,input_2],axis=-1)
feature = self.convblock(x)
x=tf.reduce_mean(feature,axis=3,keepdims=True)
x=tf.reduce_mean(x,axis=2,keepdims=True)
x=self.conv1(x)
x=tf.nn.relu(x)
x=self.conv2(x)
x=tf.nn.sigmoid(x)
x = tf.multiply(feature, x)
x = tf.add(x, feature)
return x
这样我们就将模型的每一步都具体分析并用代码展示完了,最后构成整个网络的结构代码如下
class ConvBlock(layers.Layer):
def __init__(self,out_channels,kernel_size=3,stride=2,padding='same'):
super(ConvBlock,self).__init__()
self.conv1 = layers.Conv2D(out_channels,kernel_size=kernel_size,strides=stride,padding='same')
self.bn = layers.BatchNormalization()
def call(self, input):
x = self.conv1(input)
x = self.bn(x)
x=tf.nn.relu(x)
return x
class Spatial_path(layers.Layer):
def __init__(self):
super(Spatial_path,self).__init__()
self.convblock1 = ConvBlock(out_channels=64)
self.convblock2 = ConvBlock(out_channels=128)
self.convblock3 = ConvBlock(out_channels=256)
def call(self, input):
x = self.convblock1(input)
x = self.convblock2(x)
x = self.convblock3(x)
return x
class AttentionRefinementModule(layers.Layer):
def __init__(self,out_channels):
super(AttentionRefinementModule,self).__init__()
self.conv1=layers.Conv2D(out_channels,kernel_size=1,padding='same')
self.bn=layers.BatchNormalization()
def call(self, input):
x=tf.reduce_mean(input,axis=3,keepdims=True)
x=tf.reduce_mean(x,axis=2,keepdims=True)
x=self.conv1(x)
x=self.bn(x)
x=tf.nn.sigmoid(x)
return tf.multiply(x,input)
class FeatureFusionModule(layers.Layer):
def __init__(self,num_classes):
super(FeatureFusionModule,self).__init__()
self.convblock = ConvBlock(out_channels=num_classes,kernel_size=3,stride=1)
self.conv1 = layers.Conv2D(34,(1,1))
self.conv2 = layers.Conv2D(34,(1,1))
def call(self, input_1, input_2):
x=tf.concat([input_1,input_2],axis=-1)
feature = self.convblock(x)
x=tf.reduce_mean(feature,axis=3,keepdims=True)
x=tf.reduce_mean(x,axis=2,keepdims=True)
x=self.conv1(x)
x=tf.nn.relu(x)
x=self.conv2(x)
x=tf.nn.sigmoid(x)
x = tf.multiply(feature, x)
x = tf.add(x, feature)
return x
class BiseNet(keras.Model):
def __init__(self,numclasses=34):
super(BiseNet,self).__init__()
self.sp=Spatial_path()
self.arm16=AttentionRefinementModule(1024)
self.arm32=AttentionRefinementModule(2048)
self.up1=layers.UpSampling2D(2,interpolation='bilinear')
self.up2=layers.UpSampling2D(4,interpolation='bilinear')
self.ffm=FeatureFusionModule(34)
self.ml=keras.models.Model(inputs=xception.input,outputs=layers_output)
self.conv=layers.Conv2D(34,(1,1),padding='same')
def call(self,input):
x1=self.sp(input)
down_16,down_32=self.ml(input)
output_arm16=self.arm16(down_16)
output_arm32=self.arm32(down_32)
tail=tf.reduce_mean(down_32,axis=3,keepdims=True)
tail=tf.reduce_mean(down_32,axis=2,keepdims=True)
output_tail=tf.multiply(output_arm32,tail)
output_1=self.up1(output_arm16)
output_tail=self.up2(output_tail)
output_cp=tf.concat([output_1,output_tail],axis=-1)
result=self.ffm(x1,output_cp)
result=layers.UpSampling2D(8,interpolation='bilinear')(result)
result=self.conv(result)
return result
2.模型的初始化,训练以及测试
那么接下来,我们开始对于模型的使用,对于自定义模型,我们需要知道,自己打的代码是非常容易出错的,那么我们在训练的时候加载数据又非常耗时间,所以我们如果在没有确认自定义模型无错误就去训练,代价是非常大的,所以我们要先去修改完错误,那么怎么不读取数据就完成自定义模型初始化呢,很简单
net=BiseNet()
net(xception.input)
#xception.input数据类型是下面这个
<KerasTensor: shape=(None, 1024, 2048, 3) dtype=float32 (created by layer 'input_1')>
我们可以利用这个方法来完成模型内部各项数据的初始化,同时各项错误也会显示出来,以便我们做出修改。
那么接下来我们自定义各项训练步骤
class MeanIOU(keras.metrics.MeanIoU):
def __call__(self,y_true,y_pred):
y_pred=tf.argmax(y_pred,axis=-1)
return super().__call__(y_true,y_pred)
keras.optimizers.Adam(0.0001)
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True)#因为我最后没有激活所以这里损失函数用from_logits参数改为True
train_loss=keras.metrics.Mean(name='train_loss')
train_acc=keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
train_iou=MeanIOU(34,name='train_iou')
test_loss=keras.metrics.Mean(name='test_loss')
test_acc=keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
test_iou=MeanIOU(34,name='test_iou')
上面我们定义了优化器,评价标准IOU,损失函数,准确率,那么接下你我们自定义训练步骤
@tf.function
def train_step(images,labels):
with tf.GradientTape() as t:
pred=net(images)
loss_step=loss(labels,pred)
gradies=t.gradient(loss_step,net.trainable_variables)#求解梯度
optimizer.apply_gradients(zip(gradies,net.trainable_variables))#将梯度应用于优化器从而让模型的可训练参数改变
train_loss(loss_step)
train_acc(labels,pred)
train_iou(labels,pred)
@tf.function
def test_step(images,labels):
pred=net(images)
loss_step=loss(labels,pred)
test_loss(loss_step)
test_acc(labels,pred)
test_iou(labels,pred)
这里我们在每一批次的训练函数上加tf.function,tf2会自动将该运算转化为图运算从而加快运算速度。最后我们就直接开始训练,(这里要说一句,由于我们的运算最终得到的是原图大小所以最终导致Batch_size在kaggle提供的GPU上都只能为1,。。。并且一次训练接近一小时,不竟让我怀疑他到底是不是轻量级网络。。还是我经历的太少了。。)
Epoch=1
for epoch in range(Epoch):
train_loss.reset_states()
train_acc.reset_states()
train_iou.reset_states()
test_acc.reset_states()
test_loss.reset_states()
train_iou.reset_states()
for images,labels in dataset_train:
train_step(images,labels)
print('-',end='')#标志训练完一个batch
print('>')
for img_test,label_test in dataset_val:
test_step(img_test,label_test)
template = 'Epoch {:.3f}, Loss: {:.3f}, Accuracy: {:.3f}, \
IOU: {:.3f}, Test Loss: {:.3f}, \
Test Accuracy: {:.3f}, Test IOU: {:.3f}'
print (template.format(epoch+1,
train_loss.result(),
train_acc.result()*100,
train_iou.result(),
test_loss.result(),
test_acc.result()*100,
test_iou.result()
))
2.2训练结果的评价与结果可视化

可以看到我在一次训练就在测试集达到89.703%的准确率,IOU达到了0.405,这里相比于博主之前训练的Unet
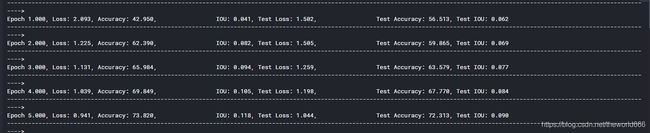
一次训练正确率只在56%,IOU也只有0.062的可以看到正确率和IOU都有非常大的提高,这里我总共训练了10次,每次都是接近一小时的训练时间,最终我们在测试集达到了一个很高的准确率95.014%和一个较好的IOU 71.6%
![]()
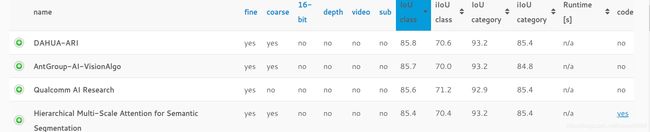
对比论文提供的效果
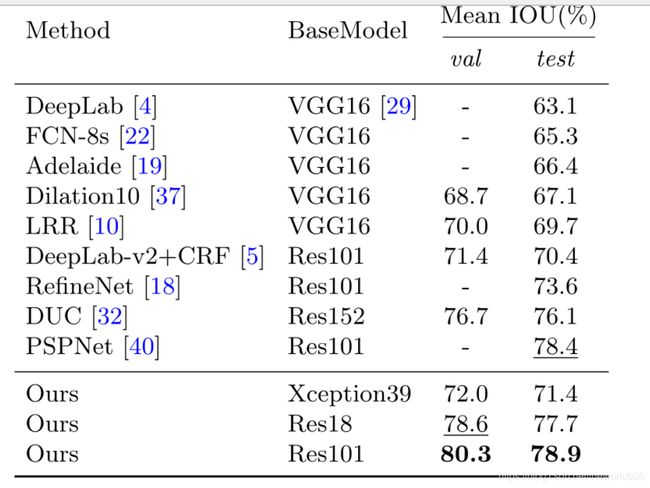
可以看到我们在测试集取得的效果(这里我采用的是Xception,所以我们对比看这一行)距离作者在测试集上我们取得的效果已经是非常接近了,不足的是这里我们的模型过拟合,在测试集上的IOU也只有0.483,但是由于设备有限(设置的batch大小只是1,并且训练十遍机器就停了),所以我也没有继续训练下去,(也是我菜不知道该在哪里,添加网络抑制过拟合(数据增强的话我就加了一个随机左右翻转,毕竟他要原图大小,不知道怎么裁剪),有会的朋友可以评论区交流),那么接下来展示效果可视化,我在这里是多次断点训练在训练的中间采集效果
2.3效果可视化
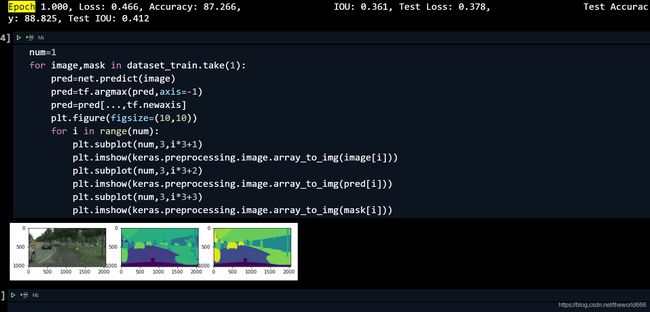
1.Epoch1: Loss: 0.466, Accuracy: 87.266, IOU: 0.361, Test Loss: 0.378, Test Accuracy: 88.825, Test IOU: 0.412
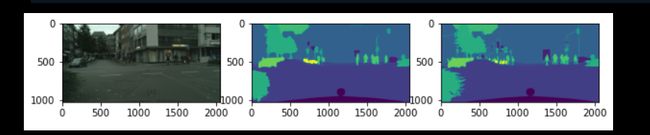
(以下测试图片从左往右是原图,预测值,真值)
2.Epoch3 Loss: 0.279, Accuracy: 91.349, IOU: 0.492,
Test Loss: 0.309, Test Accuracy: 90.371, Test IOU: 0.454
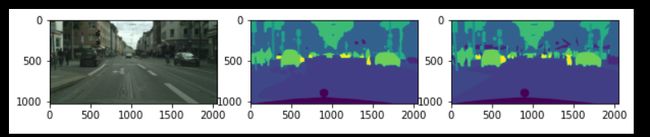
3.Epoch5 2.000, Loss: 0.223, Accuracy: 92.818, IOU: 0.572,
Test Loss: 0.315, Test Accuracy: 91.316, Test IOU: 0.459
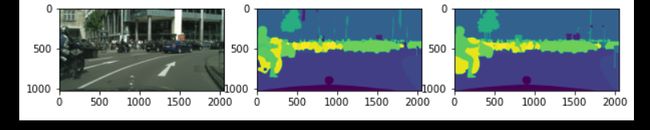
4 Epoch7, Loss: 0.189, Accuracy: 93.801, IOU: 0.637,
Test Loss: 0.307,Test Accuracy: 91.440, Test IOU: 0.472

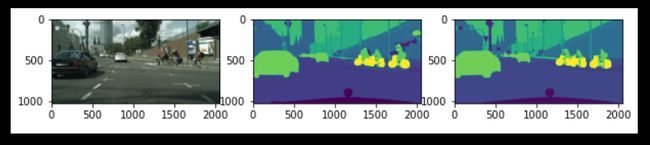
3.结语
博主在这篇博客里完成了对于BiseNet语义分割网络的从头搭建,并且配置了网络各项优化器损失函数,对于网络训练后的效果进行了评估,总体上在测试集上达到了非常高的IOU与论文较为接近,但在验证集上欠拟合,也是博主没有解决的问题。然后对于训练各项结果,最终我进行了效果可视化,将每阶段的效果逐一呈现,可以看到是整个效果模型输出的预测图整体上效果是在不断加强的,关于本篇博客有任何建议或者问题,可以评论区交流,多谢!