U-net细胞分割项目
1 实验概述
实验目的:精确提取提取图片中的细胞部分像素点
实验数据集:实验数据集
实验语言:Python
实验所需的库:PIL 、numpy 、torch、opencv(若安装后无法使用,请参照这篇博文opencv)
实验数据集示例:
(原图)
(标注)

2 U-net讲解
语义分割在生物医学图像分析中有着广泛的应用:x射线、MRI扫描、数字病理、显微镜、内窥镜等。https://grand-challenge.org/challenges上有许多不同的有趣和重要的问题有待探索。
详细讲解请至U-net详细讲解浏览。
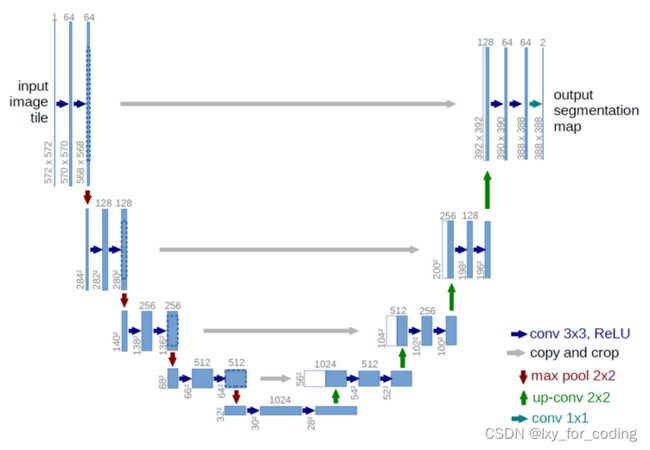
3 实验代码以及过程
step1:导入相关的包
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, models, transforms
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
from torchsummary import summary
from PIL import Image
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
step2:加载数据
img_size = (512, 512)
transform = transforms.Compose([
transforms.ToTensor()])
class MyData(Dataset):
def __init__(self, path, img_size, transform):
self.path = path
self.files = os.listdir(self.path+"/images")
self.img_size = img_size
self.transform = transform
def __getitem__(self, index):
fn = self.files[index]
img = Image.open(self.path + "/images/" + fn).resize(self.img_size)
mask = Image.open(self.path + "/masks/" + fn).resize(self.img_size)
if self.transform:
img = self.transform(img)
mask = self.transform(mask)
return img, mask
def __len__(self):
return len(self.files)
train_path = "train"
train_data = MyData(train_path, img_size, transform)
train_data_size = len(train_data)
train_dataloader = DataLoader(train_data, batch_size = 8, shuffle=True)
test_path = "test"
test_data = MyData(test_path, img_size, transform)
test_data_size = len(test_data)
test_dataloader = DataLoader(test_data, batch_size = 1, shuffle=True)
img, mask = train_data.__getitem__(0)
img, mask = img.mul(255).byte(), mask.mul(255).byte()
img, mask = img.numpy().transpose((1, 2, 0)), mask.numpy().transpose((1, 2, 0))
print("img.shape = {}, mask.shape = {}".format(img.shape, mask.shape))
fig, ax = plt.subplots(1, 3, figsize=(30, 10))
ax[0].imshow(img)
ax[0].set_title('Img')
ax[1].imshow(mask.squeeze())
ax[1].set_title('Mask')
ax[2].imshow(img)
ax[2].contour(mask.squeeze(), colors='k', levels=[0.5])
ax[2].set_title('Mixed')

step3 U-net模型构建
# 连续两次卷积的模块
class Double_Conv2d(nn.Module):
def __init__(self,in_channel,out_channel):
super(Double_Conv2d,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channel,out_channel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True))
self.conv2=nn.Sequential(
nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True))
def forward(self, inputs):
outputs=self.conv1(inputs)
outputs=self.conv2(outputs)
return outputs
# 上采样块
class Up_Block(nn.Module):
def __init__(self,in_channel,out_channel):
super(Up_Block,self).__init__()
self.conv=Double_Conv2d(in_channel,out_channel)#卷积
self.up=nn.ConvTranspose2d(in_channel,out_channel,kernel_size=2,stride=2)#反卷积上采样
def forward(self, inputs1,inputs2):
outputs2 = self.up(inputs2)# 上采样
padding = (outputs2.size()[-1]-inputs1.size()[-1])//2 #shape(batch, channel, width, height)
outputs1 = F.pad(inputs1, 2*[padding, padding])
outputs = torch.cat([outputs1,outputs2],1)# 合并
return self.conv(outputs)# 卷积
#Unet网络
class Unet(nn.Module):
def __init__(self, in_channel=3):
super(Unet,self).__init__()
self.in_channel = in_channel
#特征缩放
#filters=[64,128,256,512,1024]# 特征数列表
filters=[16,32,64,128,256]
#下采样
self.conv1 = Double_Conv2d(self.in_channel, filters[0])#卷积
self.maxpool1 = nn.MaxPool2d(kernel_size=2)#最大池化
self.conv2 = Double_Conv2d(filters[0], filters[1])
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = Double_Conv2d(filters[1], filters[2])
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.conv4 = Double_Conv2d(filters[2], filters[3])
self.maxpool4 = nn.MaxPool2d(kernel_size=2)
#center
self.center = Double_Conv2d(filters[3],filters[4])
#上采样
self.Up_Block4 = Up_Block(filters[4],filters[3])
self.Up_Block3 = Up_Block(filters[3],filters[2])
self.Up_Block2 = Up_Block(filters[2],filters[1])
self.Up_Block1 = Up_Block(filters[1],filters[0])
#final conv
self.final=nn.Conv2d(filters[0], 1, kernel_size=1)
self.out = nn.Sigmoid()
def forward(self, inputs):
conv1=self.conv1(inputs)
maxpool1=self.maxpool1(conv1)
conv2=self.conv2(maxpool1)
maxpool2=self.maxpool2(conv2)
conv3=self.conv3(maxpool2)
maxpool3=self.maxpool3(conv3)
conv4=self.conv4(maxpool3)
maxpool4=self.maxpool4(conv4)
center=self.center(maxpool4)
up4=self.Up_Block4(conv4, center)
up3=self.Up_Block3(conv3, up4)
up2=self.Up_Block2(conv2, up3)
up1=self.Up_Block1(conv1, up2)
final = self.final(up1)
return self.out(final)
#创建模型实例,并查看3*512*512的输入图像在每层的参数和输出shape
model = Unet()#创建Unet模型实例
if use_gpu:model = model.cuda()#如果有GPU可用,则将模型转移到GPU上
print(summary(model,(3,512,512)))#输出模型参数
step4:模型训练
def train_model(model, dataloader, data_size, use_gpu, criterion, optimizer, scheduler, num_epochs):
best_model_wts = model.state_dict()#定义存储最佳模型的字典
best_loss = np.inf#定义最佳模型的损失
losslist = []
for epoch in range(num_epochs):
print('-' * 10, 'Epoch {}/{}'.format(epoch+1, num_epochs),'-' * 10)
model.train(True) # 设置模型为训练模式
running_loss = 0.0#定义当前轮迭代损失
for inputs, labels in dataloader:
if use_gpu:inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())#将输入输入转移到对应设备上
else:inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()# 初始化梯度
outputs = model(inputs)# Forward得到输出
loss = criterion(outputs.squeeze(1), labels.squeeze(1))#计算损失
loss.backward()#损失梯度反传
optimizer.step()#参数更新
running_loss += loss.item() * inputs.size(0)#训练损失求和
epoch_loss = running_loss / data_size
print('Loss: {:.4f}'.format(epoch_loss))#输出当前轮迭代损失平均值
scheduler.step()#学习率衰减
losslist.append(epoch_loss)
#保存最佳模型
if epoch_loss < best_loss:
print('Best Loss improved from {} to {}'.format(best_loss, epoch_loss))
best_loss = epoch_loss
best_model_wts = model.state_dict()
print('Best Loss: {:4f}'.format(best_loss))#输出最佳模型的损失
model.load_state_dict(best_model_wts)#加载最佳模型
return model, losslist
criterion = nn.BCEWithLogitsLoss()#定义损失函数
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)#参数优化器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#每7个epoch学习率下降0.1
num_epochs = 50#机器较差 仅训练10个epoch
#训练模型
model, losslist = train_model(
model=model,
dataloader=train_dataloader,
data_size=train_data_size,
use_gpu=use_gpu,
criterion=criterion,
optimizer=optimizer_ft,
scheduler=exp_lr_scheduler,
num_epochs=num_epochs)
#可视化训练过程中损失变化
plt.xlim(0, len(losslist))
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.ylim(0, 1)
plt.plot(losslist)
plt.title('Loss curve')

step5:模型预测及评估
计算混淆矩阵和精度Acc的函数
# 获得混淆矩阵
def BinaryConfusionMatrix(prediction, groundtruth):
TP = np.float64(np.sum((prediction == 1) & (groundtruth == 1)))
FP = np.float64(np.sum((prediction == 1) & (groundtruth == 0)))
FN = np.float64(np.sum((prediction == 0) & (groundtruth == 1)))
TN = np.float64(np.sum((prediction == 0) & (groundtruth == 0)))
return TN, FP, FN,TP
# 准确率的计算方法
def get_accuracy(prediction, groundtruth):
TN, FP, FN,TP = BinaryConfusionMatrix(prediction, groundtruth)
accuracy = float(TP+TN)/(float(TP + FP + FN + TN) + 1e-6)
return accuracy
#加载测试数据
acc = []#用于存储每一张test图片的精度
model = model.to('cpu')
model.eval()#不使用BN和Dropout,防止预测图片失真
#Forward不存储梯度
with torch.no_grad():
for img, mask in test_dataloader:
pre = model(img)#Forward输出预测结果
pre = pre.mul(255).byte().squeeze().numpy()#转为uint8的array,方便计算精度
mask = mask.mul(255).byte().squeeze().numpy()
_, pre = cv2.threshold(pre,0,1,cv2.THRESH_BINARY | cv2.THRESH_OTSU)#THRESH_OTSU大津法二值化图像,方便计算精度
_, mask = cv2.threshold(mask,0,1,cv2.THRESH_BINARY | cv2.THRESH_OTSU)
acc.append(get_accuracy(pre, mask))#计算并存储精度
print('Acc:', [x for x in acc])#输出每张图的精度及平均精度
print('Mean_Acc:{}'.format(np.mean(acc)))
step6:可视化展示
img = img.mul(255).byte().squeeze().numpy().transpose((1, 2, 0))
print("img.shape={}, mask.shape={}, pre.shape={}".format(img.shape, mask.shape, pre.shape))
fig, ax = plt.subplots(1, 3, figsize=(30, 10))
ax[0].imshow(img)
ax[0].set_title('Img')
ax[1].imshow(mask)
ax[1].set_title('Mask')
ax[2].imshow(pre)
ax[2].set_title('Pre')
