关于系列化和反序列化的一个问题
一、情景重现
昨天在做数据库同步测试的时候,用到了一点序列化和反序列化的技术。我把某个表的字段抽象成一个实体类DiagramInfo,然后把客户端新增的记录用一个泛型集合存储,再把这个泛型集合系列化,通过TCP发送到服务端,服务端对其进行反序列化,再把这些数据写入数据库。这大概就是这个操作的流程。
序列化我用的是System.Runtime.Serialization.Iformatter类,把泛型集合序列化成二进制流。序列化的部分代码如下:
然后使用TCP协议发送,这部分内容省略。
服务端部分接收数据,并保存成MemoryStream,然后对其反序列化,部分代码如下:
{
bytesRead = stream.Read(responseBuffer, 0 , bufferSize);
memstream.Write(responseBuffer, 0 , bytesRead);
}
while (bytesRead > 0 );
IFormatter formater = new BinaryFormatter();
diagrams = (List < DiagramInfo > )formater.Deserialize(memstream);
stream.Close();
memstream.Close();
client.Close();
这时运行客户端和服务端,进行数据同步,结果出现了如下的错误信息:
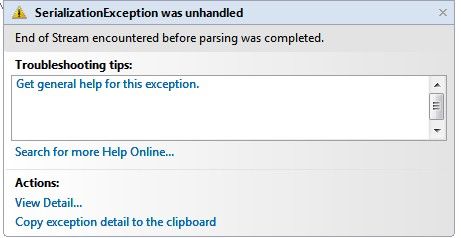
错误行为:diagrams = (List<DiagramInfo>)formater.Deserialize(memstream);
按字面意思是:在转换完成前遇到了流结束。
二、解决方案
经过google搜索,对于这个错误有人回答了以下几种错误可能:
1.序列化和反序列化时类型不同,这里可以排除;
2.在序列化时没有清空流的缓冲区,及没有使用Flush()方法,这里也可以排除;
3.反序列化前的接收过程缓冲区大小可能不够,对于这条我觉得应该没问题才对,反序列化是在获取流之后进行的,跟缓冲区大小应该没关系,个人意见,也没试过;
4.在反序列化前加上strem.Position=0。(stream是待反序列化的流,实指memstream)
经过测试,第四种可能适用于我的程序。那么为什么会这样呢,经过单步调试,观察memstream.Postion的值变化,发现每对其进行一次写操作,该值都会指向末尾,这就解释了为什么程序会报这样的错误了。但是我搞不懂的是为什么反序列化函数(Deserialize)不是默认对整个流进行反序列化,而是从Positon的位置开始呢?