从数据爬取到决策树建模——预测北京二手房房价
一、项目背景
北京房价一直是大家非常关注的话题。本项目以研究北京二手房房价为目的,通过Scrapy框架爬取链家网站的二手房房源信息,对其进行基本的数据分析及可视化,并利用决策树算法对未来房价进行预测,最后,可视化模型的学习曲线,观察是否出现过拟合问题。(仅供参考)
二、爬取数据
链家网站的二手房房源信息展示如下:
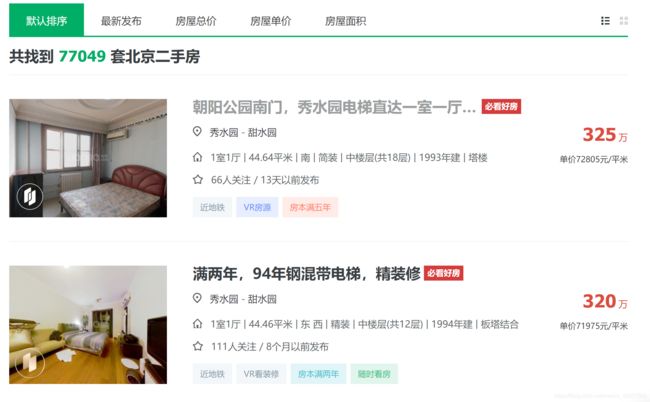
共有77049条房源信息,但是只显示了100页,每页30条。这些数据未设置反爬,可直接爬取。本文主要爬取如下红框内的11个字段,包括房源描述、房源所在位置、布局、面积、朝向、装修情况、楼层、建造时间、类型、总房价和每平米单价。

如下是具体的爬虫代码:
item.py
import scrapy
class LianjiaspiderprojectItem(scrapy.Item):
# define the fields for your item here like:
Description = scrapy.Field() #房源描述
Location = scrapy.Field() #房源所在位置
Layout = scrapy.Field() #房源布局
Size = scrapy.Field() #房源面积
Direction = scrapy.Field() #房源朝向
Renovation = scrapy.Field() #房源装修情况
Floorinfo = scrapy.Field() #房源所在楼层信息
Year = scrapy.Field() #房源建造年份
Type = scrapy.Field() #房源类型
Price = scrapy.Field() #房源总价
unitPrice = scrapy.Field() #房源单价
pass
lianjia.py
import scrapy
from lxml import etree
from LianjiaSpiderProject.items import LianjiaspiderprojectItem
class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://bj.lianjia.com/ershoufang/pg1/']
initial_url = "https://bj.lianjia.com/ershoufang/pg"
current_page = 2
def parse(self, response):
#获取第一页中所有房源信息所在的标签,其中每页包括30条房源信息,即30条li标签
sell_list = response.xpath('//ul[@class="sellListContent"]/li')
#对30条li标签进行解析获取相应的房源信息
for sell in sell_list:
Houseinfo = sell.xpath('./div[1]/div[@class="address"]/div//text()').extract()[0]
if len(Houseinfo.split(' | ')) == 7:
Layout = Houseinfo.split(' | ')[0]
Size = Houseinfo.split(' | ')[1]
Direction = Houseinfo.split(' | ')[2]
Renovation = Houseinfo.split(' | ')[3]
Floorinfo = Houseinfo.split(' | ')[4]
Year = Houseinfo.split(' | ')[5]
Type = Houseinfo.split(' | ')[6]
else:
break
Description = sell.xpath('./div[1]/div[@class="title"]/a/text()').extract()[0]
Location = sell.xpath('./div[1]/div[@class="flood"]//text()').extract()
Location_new = "".join([x.strip() for x in Location if len(x.strip()) > 0]) # 去除列表中的空格和空字符串,并将其拼接成一个字符串
Price = sell.xpath('./div[1]/div[@class="priceInfo"]/div[1]//text()').extract()
Price_new = "".join(Price)
unitPrice = sell.xpath('./div[1]/div[@class="priceInfo"]/div[2]//text()')[0].extract()
#将爬取的数据与item文件里面的数据对应起来
item = LianjiaspiderprojectItem()
item['Description'] = Description
item['Location'] = Location_new
item['Layout'] = Layout
item['Size'] = Size
item['Direction'] = Direction
item['Renovation'] = Renovation
item['Floorinfo'] = Floorinfo
item['Year'] = Year
item['Type'] = Type
item['Price'] = Price_new
item['unitPrice'] = unitPrice
yield item
#链家只展示了100页的内容,抓完100页就停止爬虫
#组装下一页要抓取的网址
if self.current_page != 101:
new_url = self.initial_url + str(self.current_page) + '/'
print('starting scrapy url:', new_url)
yield scrapy.Request(new_url, callback=self.parse)
self.current_page += 1
else:
print('scrapy done')
pass
pipelines.py
from itemadapter import ItemAdapter
import csv
class LianjiaspiderprojectPipeline(object):
fp = None
index = 0
#该方法只在爬虫开始的时候被调用一次
def open_spider(self, spider):
print('开始爬虫......')
self.fp = open('./lianjia.csv', 'a', encoding='utf-8')
def process_item(self, item, spider):
Description = item['Description']
Location = item['Location']
Layout = item['Layout']
Size = item['Size']
Direction = item['Direction']
Renovation = item['Renovation']
Floorinfo = item['Floorinfo']
Year = item['Year']
Type = item['Type']
Price = item['Price']
unitPrice = item['unitPrice']
if self.index == 0:
columnnames = "房源描述,位置,布局,面积,朝向,装修情况,楼层,建造年份,类型,总计,单价"
self.fp.write(columnnames+'\n')
self.index = 1
self.fp.write("{},{},{},{},{},{},{},{},{},{},{}\n".format(Description, Location, Layout, Size, Direction, Renovation, Floorinfo, Year, Type, Price, unitPrice))
return item
def close_spider(self, spider):
print('爬虫结束!')
self.fp.close()
pass
三、导入爬取的数据
#导入相关库
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from IPython.display import display
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set(style='darkgrid',context='notebook',font_scale=1.5) # 设置背景
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False #处理中文和坐标负号显示
#导入链家网站二手房数据集
lianjia = pd.read_csv('lianjia.csv')
display(lianjia.head())
Direction District Elevator Floor Garden Id Layout Price Region Renovation Size Year
0 东西 灯市口 NaN 6 锡拉胡同21号院 101102647043 3室1厅 780.0 东城 精装 75.0 1988
1 南北 东单 无电梯 6 东华门大街 101102650978 2室1厅 705.0 东城 精装 60.0 1988
2 南西 崇文门 有电梯 16 新世界中心 101102672743 3室1厅 1400.0 东城 其他 210.0 1996
3 南 崇文门 NaN 7 兴隆都市馨园 101102577410 1室1厅 420.0 东城 精装 39.0 2004
4 南 陶然亭 有电梯 19 中海紫御公馆 101102574696 2室2厅 998.0 东城 精装 90.0 2010
lianjia.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 23677 entries, 0 to 23676
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Direction 23677 non-null object
1 District 23677 non-null object
2 Elevator 15440 non-null object
3 Floor 23677 non-null int64
4 Garden 23677 non-null object
5 Id 23677 non-null int64
6 Layout 23677 non-null object
7 Price 23677 non-null float64
8 Region 23677 non-null object
9 Renovation 23677 non-null object
10 Size 23677 non-null float64
11 Year 23677 non-null int64
dtypes: float64(2), int64(3), object(7)
memory usage: 2.2+ MB
lianjia.describe()
Floor Id Price Size Year
count 23677.000000 2.367700e+04 23677.000000 23677.000000 23677.000000
mean 12.765088 1.011024e+11 610.668319 99.149301 2001.326519
std 7.643932 5.652477e+05 411.452107 50.988838 9.001996
min 1.000000 1.010886e+11 60.000000 2.000000 1950.000000
25% 6.000000 1.011022e+11 365.000000 66.000000 1997.000000
50% 11.000000 1.011025e+11 499.000000 88.000000 2003.000000
75% 18.000000 1.011027e+11 717.000000 118.000000 2007.000000
max 57.000000 1.011028e+11 6000.000000 1019.000000 2017.000000
- 初步观察,该数据集一共有23677条数据,11个特征变量,‘Price’在这里是目标变量。其中‘Elevator’特征存在缺失值。另外,从统计值中观察到‘Size’特征最大值为1019m2,最小值为2m2,这种情况在现实中极有可能不存在,那么这个数据很可能是一个异常值,会严重影响模型的性能。当然,这只是初步猜测,后面会用数据可视化来展示,并证实猜测。
#添加新特征-房屋均价
df = lianjia.copy()
df['PerPrice'] = lianjia['Price']/lianjia['Size']
#调整各个特征的排列顺序,其中'Id'特征实际意义不大,故将其移除
columns = ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', \
'Elevator', 'Direction', 'Renovation', 'PerPrice', 'Price']
df = pd.DataFrame(df, columns = columns)
#重新审视数据
display(df.head())
Region District Garden Layout Floor Year Size Elevator Direction Renovation PerPrice Price
0 东城 灯市口 锡拉胡同21号院 3室1厅 6 1988 75.0 NaN 东西 精装 10.400000 780.0
1 东城 东单 东华门大街 2室1厅 6 1988 60.0 无电梯 南北 精装 11.750000 705.0
2 东城 崇文门 新世界中心 3室1厅 16 1996 210.0 有电梯 南西 其他 6.666667 1400.0
3 东城 崇文门 兴隆都市馨园 1室1厅 7 2004 39.0 NaN 南 精装 10.769231 420.0
4 东城 陶然亭 中海紫御公馆 2室2厅 19 2010 90.0 有电梯 南 精装 11.088889 998.0
四、数据可视化分析
Region特征分析
#对Region进行分组,研究不同区域的二手房数量、单价和总价情况
df_house_count = df.groupby('Region').count()['Price'].sort_values(ascending=False).reset_index().rename({'Price':'Count'},axis=1)
df_house_mean = df.groupby('Region').mean()['PerPrice'].sort_values(ascending=False).reset_index().rename({'PerPrice':'MeanPrice'},axis=1)
plt.figure(figsize=(20,30))
plt.subplot((311))
sns.barplot(x='Region', y='Count', palette='Blues_d', data=df_house_count)
plt.title('北京各区域二手房数量对比', fontsize=15)
plt.xlabel('区域')
plt.ylabel('数量')
plt.subplot((312))
sns.barplot(x='Region', y='MeanPrice', palette='Greens_d', data=df_house_mean)
plt.title('北京各区域二手房单价对比', fontsize=15)
plt.xlabel('区域')
plt.ylabel('每平米单价')
plt.subplot((313))
sns.boxplot(x='Region', y='Price', palette='Blues_d', data=df)
plt.title('北京各区域二手房房价对比', fontsize=15)
plt.xlabel('区域')
plt.ylabel('房总价')
plt.show()
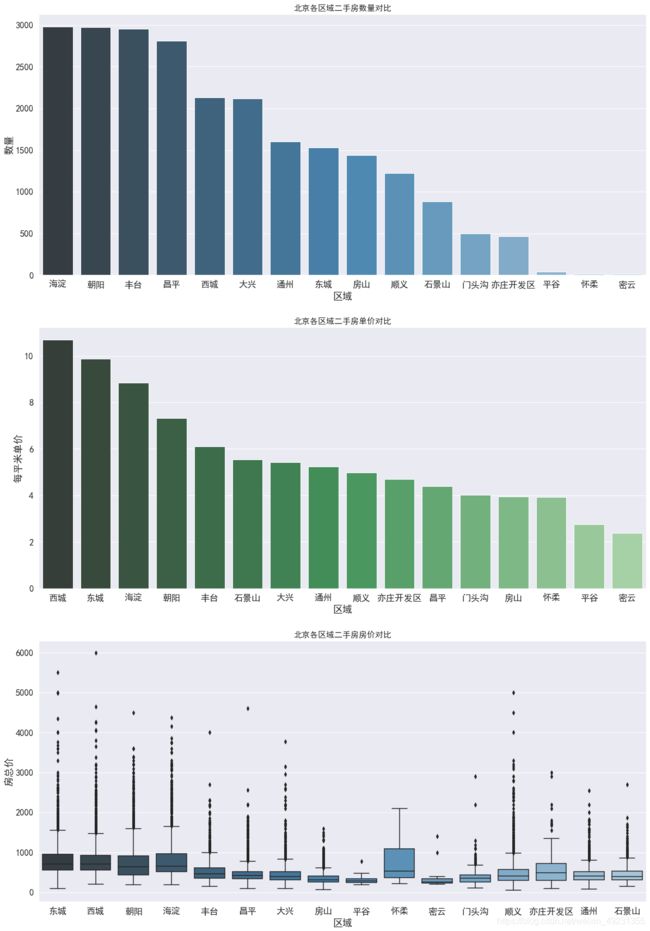
- 二手房数量:海淀区与朝阳区数量最多,接近3000套。然后是丰台区,近几年正在改造建设,有赶超之势。
- 二手房单价:西城区房价最贵,约11万/平,因为西城区在二环内,且有很多热门学区房。其次是东城区,约10万/平,然后是海淀区8.5万/平,其余区域均低于8万/平。
- 二手房总价:各区房二手房总价的中位数均为1000万以下,且总价离散值较高,西城最高达到了6000万,说明二手房价格特征不是理想的正态分布。
Size特征分析
plt.figure(figsize=(20,20))
plt.subplot((211))
#二手房面积的分布情况
sns.distplot(df['Size'], bins=20, color='r', kde=True, kde_kws={'color':'steelblue','shade':True,'linewidth':6})
#二手房价格与面积的关系
plt.subplot((212))
sns.regplot(x='Size', y='Price', data=df)
plt.show()
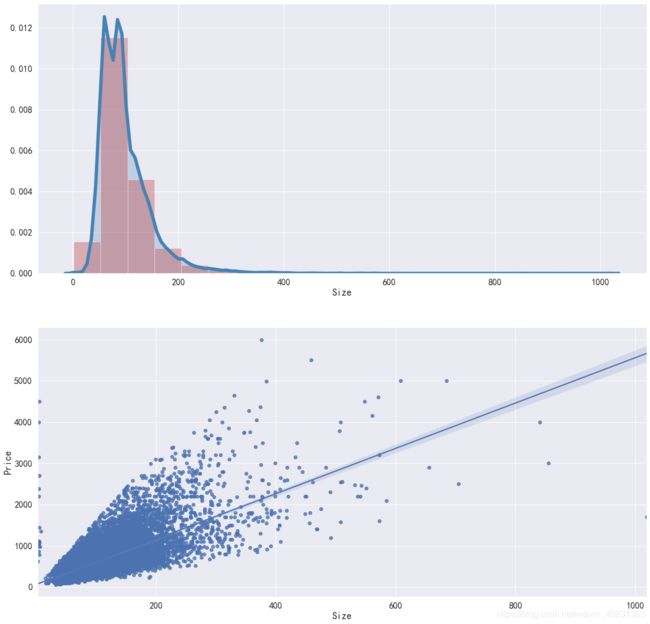
- Size分布:通过观察distplot和kdeplot,二手房面积属于长尾类型的分布,这说明有很多面积很大且超出正常范围的二手房。
- Size与Price的关系:Price与Size基本呈现线性关系,符合常识,面积越大,价格越高。但是存在两类异常数据:1.面积不到10m2,但价格超过了1000万;2.面积超过了1000m2,但价格相对较低,需要查看具体情况。
df.loc[df['Size']<10]
df.loc[df['Size']>1000]
- 经过查看发现:该异常点不是一般的民用二手房,很有可能是商用房,所以才有1房间0卫确有超过1000m2的面积,本次项目也将其移除。
#移除异常数据
df = df[(df['Layout']!='叠拼别墅') & (df['Size']<1000)]
#重新绘制Size分布、Size与Price之间的关系
plt.figure(figsize=(20,20))
plt.subplot((211))
#二手房面积的分布情况
sns.distplot(df['Size'], bins=20, color='r', kde=True, kde_kws={'color':'steelblue','shade':True,'linewidth':6})
#二手房价格与面积的关系
plt.subplot((212))
sns.regplot(x='Size', y='Price', data=df)
plt.show()

Layout特征分析
plt.figure(figsize=(20,20))
sns.countplot(y='Layout', data=df)
plt.title('户型', fontsize=15)
plt.xlabel('数量')
plt.ylabel('户型')
plt.show()

- 经过观察发现:户型有很多种,其中2室1厅占大多数,其次是3室1厅、2室2厅、3室2厅。仔细观察Layout特征发现,其分类下存在一些不规则的命名,如2室1厅和2房间1卫,叫法不统一,在进行机器学习之前需要使用特征工程进行相应地处理。
Renovation特征分析
df['Renovation'].value_counts()
精装 11345
简装 8496
其他 3239
毛坯 576
Name: Renovation, dtype: int64
#绘制Renovation各分类的数量情况
plt.figure(figsize=(15,30))
plt.subplot((311))
sns.countplot(df['Renovation'])
#绘制Renovation与Price之间的关系
plt.subplot((312))
sns.barplot(x='Renovation', y='Price', data=df)
plt.subplot((313))
sns.boxplot(x='Renovation', y='Price', data=df)
plt.show()

- 经过观察发现:精装修的二手房数量最多,其次是简装。另外,毛坯类型价格却最高,其次是精装修。
Elevator特征分析
df['Elevator'].value_counts()
有电梯 9341
无电梯 6078
Name: Elevator, dtype: int64
#查看缺失值
df.loc[df['Elevator'].isnull()].shape
(8237, 12)
- Elevator特征存在8237条缺失数据,这里采用替换法对缺失值进行填补。思路:一般楼层大于6曾都有电梯,6层以下一般没有电梯。
#填补缺失值
df.loc[(df['Floor']>6)&(df['Elevator'].isnull()), 'Elevator'] = '有电梯'
df.loc[(df['Floor']<=6)&(df['Elevator'].isnull()), 'Elevator'] = '无电梯'
#绘制Elevator不同类别的数量
plt.figure(figsize=(20,15))
plt.subplot((121))
sns.countplot(df['Elevator'])
plt.title('有无电梯数量对比',fontsize=15)
plt.xlabel('是否有电梯',fontsize=15)
plt.ylabel('数量',fontsize=15)
#绘制Elevator类别与Price的关系
plt.subplot((122))
sns.barplot(x='Elevator', y='Price', data=df)
plt.title('有无电梯房价对比',fontsize=15)
plt.xlabel('是否有电梯',fontsize=15)
plt.ylabel('房价',fontsize=15)
plt.show()
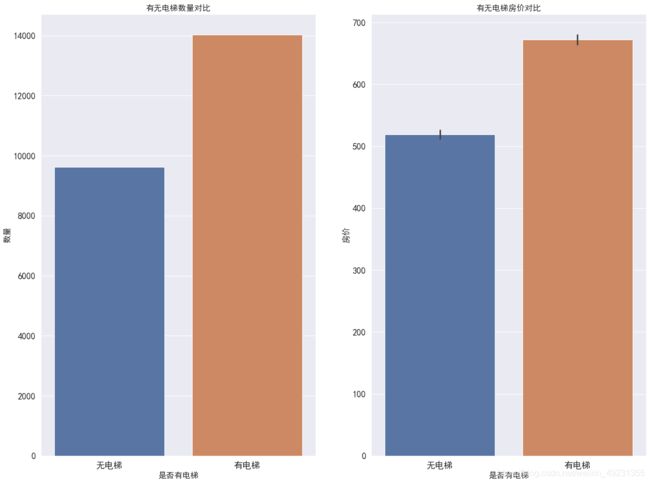
- 经过观察发现:有电梯的二手房数量居多,因为高层土地利用率较高,适合北京庞大人群的需要,而高层就需要有电梯。相应的,有电梯房价一般就会较高。
Year特征分析
#绘制Elevator和Renovation不同的分类情况下,Year与Price的关系
grid = sns.FacetGrid(df, row='Elevator', col='Renovation', palette='pal', size=5) #size可调节图形间距
grid.map(plt.scatter, 'Year', 'Price')
grid.add_legend()
plt.show()

经过观察发现:
- 二手房房价随房龄的增长而降低;
- 2000年以后建造的二手房房价相较于2000年以前的有很明显的上涨;
- 1980年之前几乎不存在有电梯的二手房,说明1980年之前还没有大面积安装电梯;
- 1980年之前无电梯的二手房中,简装占绝大多数,精装反而很少。
Floor特征分析
#绘制不同楼层的数量关系
plt.figure(figsize=(20,8))
sns.countplot(x='Floor', data=df)
plt.title('二手房楼层',fontsize=15)
plt.xlabel('楼层')
plt.ylabel('数量')
plt.show()
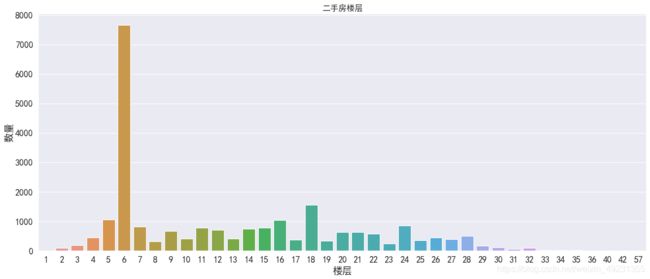
- 经过观察发现:6层的二手房数量最多,但是单独的楼层特征没有意义,因为每个小区住房的总楼层数不一样。正常情况下,中间楼层比较受欢迎,价格也高,底层和顶层受欢迎度较低,价格也相对较低。
四、特征工程
机器学习之前需要对数据进一步处理,具体如下:
Layout特征
#只保留'xx室xx厅'数据,将其它少数房间与卫移除
df = df.loc[df['Layout'].str.extract('^\d(.*?)\d.*?', expand=False)=='室']
#提取'室'和'厅'创建新特征
df['Layout_room_num'] = df['Layout'].str.extract('(^\d).*', expand=False).astype('int64')
df['Layout_hall_num'] = df['Layout'].str.extract('^\d.*?(\d).*', expand=False).astype('int64')
df['Layout'].value_counts()
2室1厅 9485
3室1厅 3999
3室2厅 2765
1室1厅 2681
2室2厅 1671
4室2厅 930
1室0厅 499
4室1厅 295
5室2厅 200
4室3厅 96
5室3厅 75
1室2厅 67
6室2厅 59
2室0厅 50
3室3厅 43
6室3厅 29
3室0厅 29
5室1厅 27
7室3厅 7
7室2厅 6
2室3厅 5
8室3厅 4
4室4厅 4
5室4厅 4
6室4厅 4
8室2厅 3
4室0厅 3
6室0厅 2
9室3厅 1
9室2厅 1
7室1厅 1
8室5厅 1
5室0厅 1
8室4厅 1
6室5厅 1
1室3厅 1
9室1厅 1
6室1厅 1
Name: Layout, dtype: int64
Year特征
#对Year特征进行分箱,等频分段(按年限,Year划分太细,故将连续型数值Year特征离散化)
df['Year'] = pd.qcut(df['Year'],8).astype('object')
df['Year'].value_counts()
(2000.0, 2003.0] 3705
(2004.0, 2007.0] 3369
(1990.0, 1997.0] 3110
(1949.999, 1990.0] 3024
(1997.0, 2000.0] 2829
(2010.0, 2017.0] 2687
(2007.0, 2010.0] 2571
(2003.0, 2004.0] 1757
Name: Year, dtype: int64
Direction特征
df['Direction'].value_counts()
南北 11367
南 2726
东西 1388
东南 1311
西南 1094
东 843
西 802
西北 733
东北 645
北 484
东南北 465
南西北 370
南西 158
东西北 139
东南西 133
西南北 124
东南西北 90
西南东北 23
南东北 19
东南西南 15
东南南 13
东东南 10
西东北 10
西南西北 10
东西南 9
南西南 9
东南东北 7
西南西 5
东南南北 5
南西东北 3
东西南北 3
西西南 2
东东北 2
东北东北 2
南西西北 2
西北东北 2
西西北 2
南西北北 2
南东 2
南西南北 2
西北北 2
南西南西 2
西南西北东北 1
南北东 1
东南南西北 1
东西北东北 1
东南西北北 1
东南西北东北 1
东西北北 1
北南 1
东西东北 1
西南西北北 1
南北西 1
东南西南东北 1
东南北西 1
东南西南北 1
东东南南 1
南北东北 1
北西 1
Name: Direction, dtype: int64
定义函数,将Direction中重复但顺序不一样的特征值合并,比如’西南北’和’南西北’,并且移除一些不合理的值,如’西南西北北’
list_one_num = ['东','西','南','北']
list_two_num = ['东西','东南','东北','西南','西北','南北']
list_three_num = ['东西南','东西北','东南北','西南北']
list_four_num = ['东西南北']
def direct_func(x):
if not isinstance(x, str):
raise TypeError
x = x.strip()
x_len = len(x)
x_list = pd.unique([y for y in x])
if x_len != len(x_list):
return 'no'
if (x_len==2)&(x not in list_two_num):
m0=x[0]
m1=x[1]
return m1+m0
elif (x_len==3)&(x not in list_three_num):
for n in list_three_num:
if (x_list[0] in n)&(x_list[1] in n)&(x_list[2] in n):
return n
elif (x_len==4)&(x not in list_four_num):
return list_four_num[0]
else:
return x
df['Direction'] = df['Direction'].apply(direct_func)
df = df.loc[(df['Direction']!='no')&(df['Direction']!='nan')]
df['Direction'].value_counts()
南北 11368
南 2726
东西 1388
东南 1313
西南 1252
东 843
西 802
西北 734
东北 645
西南北 495
东南北 485
北 484
东西北 149
东西南 142
东西南北 120
Name: Direction, dtype: int64
创建新特征
#每个房间的平均面积
df['Layout_total_num'] = df['Layout_room_num'] + df['Layout_hall_num']
df['Size_room_ratio'] = df['Size']/df['Layout_total_num']
删除旧的特征
#删除无用特征
df = df.drop(['Layout','PerPrice','Garden'], axis=1)
display(df.head())
Region District Floor Year Size Elevator Direction Renovation Price Layout_room_num Layout_hall_num Layout_total_num Size_room_ratio
0 东城 灯市口 6 (1949.999, 1990.0] 75.0 无电梯 东西 精装 780.0 3 1 4 18.75
1 东城 东单 6 (1949.999, 1990.0] 60.0 无电梯 南北 精装 705.0 2 1 3 20.00
2 东城 崇文门 16 (1990.0, 1997.0] 210.0 有电梯 西南 其他 1400.0 3 1 4 52.50
3 东城 崇文门 7 (2003.0, 2004.0] 39.0 有电梯 南 精装 420.0 1 1 2 19.50
4 东城 陶然亭 19 (2007.0, 2010.0] 90.0 有电梯 南 精装 998.0 2 2 4 22.50
对object类型的特征进行One-hot编码
#定义函数,One-hot编码
def one_hot_encoder(df, nan_as_category=True):
original_columns = list(df.columns)
categorical_columns = [col for col in df.columns if df[col].dtype=='object']
df = pd.get_dummies(df, columns=categorical_columns, dummy_na=nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
df, df_cat = one_hot_encoder(df)
特征相关性
colormap = plt.cm.RdBu
plt.figure(figsize=(30,20))
sns.heatmap(df.corr(), linewidths=0.1, vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
- 颜色偏红或者偏蓝都说明相关性较大,即这两个特征对于目标变量的影响程度相似,即存在严重的重复信息,会造成过拟合现象。通过以上特征相关性分析,可以找出有严重重叠信息的特征,然后择优选择。
五、决策树算法预测房价
-使用Cart决策树的回归模型对二手房房价进行预测
-使用交叉验证充分利用数据集进行训练,避免数据划分不均匀的影响
-使用GridSearchCV优化模型参数
-使用学习曲线观察是否出现过拟合
prices = df['Price'] #目标值
features = df.drop(['Price'], axis=1) #特征值
prices = np.array(prices)
features = np.array(features)
#建立决策树回归模型
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV
#利用GridSearchCV计算最优解
def fit_model(features, prices):
features_train, features_test, prices_train, prices_test = train_test_split(features, prices, test_size=0.2, random_state=22)
corss_validation = KFold(10, shuffle=True)
regressor = DecisionTreeRegressor()
params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
grid = GridSearchCV(estimator=regressor, param_grid=params, cv=corss_validation)
grid.fit(features_train, prices_train)
print('预测的准确率为:',grid.score(features_test, prices_test))
print('选择的决策树深度为{}'.format(grid.best_estimator_))
print('交叉验证中最好的结果为{}'.format(grid.best_score_))
return None
fit_model(features, prices)
# 可视化模拟学习曲线,观察是否出现过拟合问题。
from sklearn.model_selection import learning_curve, validation_curve
from sklearn.model_selection import ShuffleSplit
#绘制Learning_curve曲线
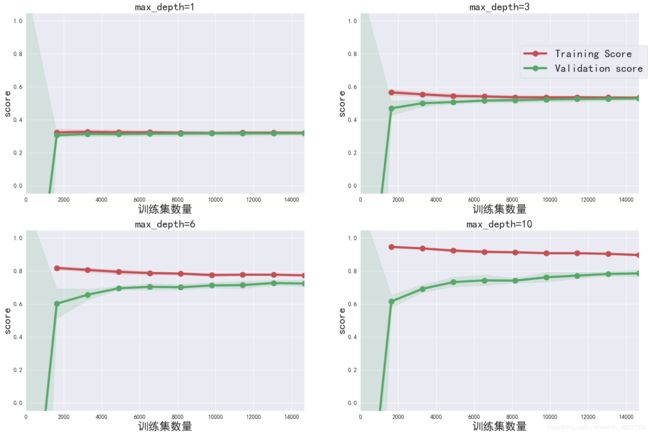
def ModelLearning(X, y):
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
train_sizes = np.rint(np.linspace(1, X.shape[0]*0.8-1, 10)).astype(int)
#print(train_sizes)
fig = plt.figure(figsize=(30,20))
for k, depth in enumerate([1,3,6,10]):
regressor = DecisionTreeRegressor(max_depth=depth)
sizes, train_scores, test_scores = learning_curve(regressor, X, y, cv=cv, train_sizes=train_sizes)
train_std = np.std(train_scores, axis=1)
train_mean = np.mean(train_scores, axis=1)
valid_std = np.std(test_scores, axis=1)
valid_mean = np.mean(test_scores, axis=1)
ax = fig.add_subplot(2, 2, k+1)
ax.plot(sizes, train_mean, 'o-', color='r', linewidth=6, markersize=15, label='Training Score')
ax.plot(sizes, valid_mean, 'o-', color='g', linewidth=6, markersize=15, label='Validation score')
ax.fill_between(sizes, train_mean - train_std, train_mean + train_std, alpha=0.15, color='r')
ax.fill_between(sizes, valid_mean - valid_std, valid_mean + valid_std, alpha=0.15, color='g')
ax.set_title('max_depth={}'.format(depth), fontsize=30)
ax.set_xlabel('训练集数量', fontsize=30)
ax.set_ylabel('score', fontsize=30)
ax.set_xlim([0, X.shape[0]*0.8])
ax.set_ylim([-0.05, 1.05])
ax.legend(bbox_to_anchor=(1.05,2.05), loc='upper right', fontsize=30)
fig.show()
#绘制Validation_curve曲线
def ModelComplexity(X, y):
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
max_depth = np.arange(1,11)
train_scores, valid_scores = validation_curve(DecisionTreeRegressor(), X, y, param_name='max_depth', param_range=max_depth, cv=cv)
train_std = np.std(train_scores, axis=1)
train_mean = np.mean(train_scores, axis=1)
valid_std = np.std(valid_scores, axis=1)
valid_mean = np.mean(valid_scores, axis=1)
plt.figure(figsize=(8,6))
plt.plot(max_depth, train_mean, 'o-', color='r', label='Training Score', linewidth=3, markersize=6)
plt.plot(max_depth, valid_mean, 'o-', color='g', label='Validation Score', linewidth=3, markersize=6)
plt.fill_between(max_depth, train_mean - train_std, train_mean + train_std, alpha=0.15, color='r')
plt.fill_between(max_depth, valid_mean - valid_std, valid_mean + valid_std, alpha=0.15, color='g')
plt.legend(loc='lower right')
plt.xlabel('max_depth')
plt.ylabel('Score')
plt.ylim([-0.05, 1.05])
plt.show()
ModelLearning(features_train, prices_train)
ModelComplexity(features_train, prices_train)

预测的准确率为: 0.831288503230392
选择的决策树深度为DecisionTreeRegressor(max_depth=10)
交叉验证中最好的结果为0.7887002299501087
- 由以上曲线可以看出:当决策树回归模型的决策深度约为10的时候,偏差与方法达到平衡,即最优模型
- 本模型的准确率为0.83,基本可以对二手房价进行预测。(仅供参考)