艺术~在单机和分布式环境下的限流算法(漏桶算法、令牌桶算法)
文章目录
-
- 前言
- 限流算法
-
- 滑动窗口限流
- 漏桶算法
- 令牌桶算法
- 单机限流和分布式限流
-
- 限流组件
前言
今天总结学习一下限流的相关内容,包括常见的限流算法、单机限流场景、分布式限流场景以及一些常见限流组件。
那就引来第一个问题,什么是限流?为什么要限流?
首先来解释下什么是限流?
在日常生活中限流很常见,例如去有些景区玩,每天售卖的门票数是有限的,例如 2000 张,即每天最多只有 2000 个人能进去游玩。
这就是一个限流,那么再来回答第二个问题为什么要限流?
依旧刚刚那个例子,如果不限流会怎么样,就会把景区挤爆。
那换在服务器中也是一样,如果我们不做限流,任凭大量的请求过来,再多的CPU再大的分布式都会存在一个阈值QPS,一旦超过这个QPS就会把CPU挤爆。
而通常我们说的限流指代的是 限制到达系统的并发请求数,使得系统能够正常的处理 部分 用户的请求,来保证系统的稳定性。
限流不可避免的会造成用户的请求变慢或者被拒的情况,从而会影响用户体验。因此限流是需要在用户体验和系统稳定性之间做平衡的。
所以限流是为了保证系统的稳定性,让前面的请求被正常处理。
日常的业务上有类似秒杀活动、双十一大促或者突发新闻等场景,用户的流量突增,后端服务的处理能力是有限的,如果不能处理好突发流量,后端服务很容易就被打垮。
那我就讲讲常见的限流算法。
限流算法
滑动窗口限流
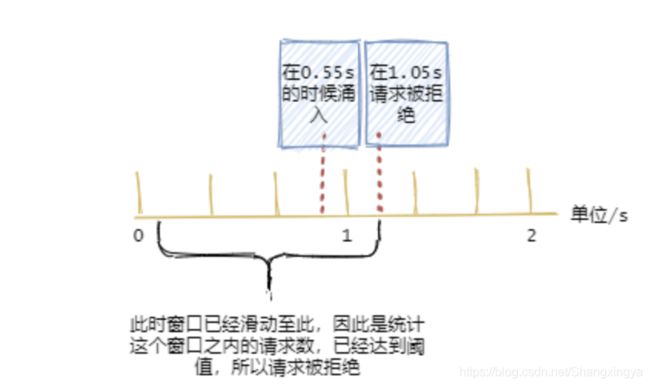
滑动窗口限流解决固定窗口临界值的问题,可以保证在任意时间窗口内都不会超过阈值。
相对于固定窗口,滑动窗口除了需要引入计数器之外还需要记录时间窗口内每个请求到达的时间点,因此对内存的占用会比较多。
规则如下,假设时间窗口为 1 秒:
记录每次请求的时间
统计每次请求的时间 至 往前推1秒这个时间窗口内请求数,并且 1 秒前的数据可以删除。
统计的请求数小于阈值就记录这个请求的时间,并允许通过,反之拒绝。
class SlidingWindow {
private int windowSize; //窗口大小
private Queue<Long> queue;
public SlidingWindow() {
this.windowSize = 10;
this.queue = new LinkedList<>();
}
public boolean tryQuire() {
Long now = System.currentTimeMillis(); //获取当前时间
int counter = getQuires(now); //根据当前时间获取一秒内请求的数目
if (counter < windowSize) { //如果还没有到阈值就接受请求
queue.offer(now);
return true;
}
return false;
}
private int getQuires(Long now) {
long count = this.queue.stream().filter(item -> item > now - 1000).count();
return (int) count;
}
}
但是滑动窗口和固定窗口都无法解决短时间之内集中流量的突击。
我们所想的限流场景,例如每秒限制 100 个请求。希望请求每 10ms 来一个,这样我们的流量处理就很平滑,但是真实场景很难控制请求的频率。因此可能存在 5ms 内就打满了阈值的情况。
当然对于这种情况还是有变型处理的,例如设置多条限流规则。不仅限制每秒 100 个请求,再设置每 10ms 不超过 2 个。
漏桶算法
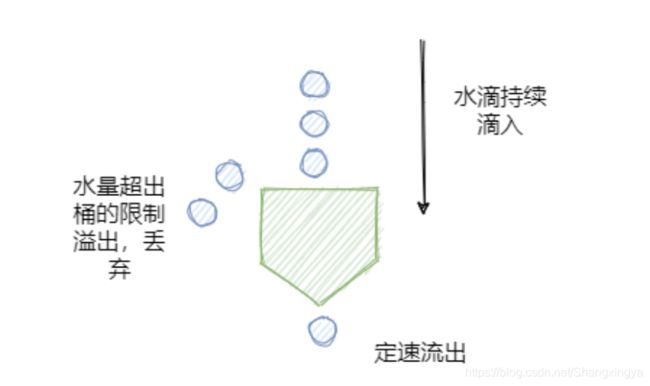
如下图所示,水滴持续滴入漏桶中,底部定速流出。如果水滴滴入的速率大于流出的速率,当存水超过桶的大小的时候就会溢出。
规则如下:
请求来了放入桶中
桶内请求量满了拒绝请求
服务定速从桶内拿请求处理
class water {
private int waters; //此时的水量
private int rate; //服务器消费水量的速率
private long lastTime; //上次注水时间
private int capacity; //阈值
public water() {
this.lastTime = System.currentTimeMillis();
this.rate = 1; //一毫秒消费一滴水
}
public boolean tryQuire() {
long now = System.currentTimeMillis(); //获取此时时间
int usedWaters = (int) ((now - lastTime) * rate); //计算消耗的水量
waters = Math.max(0, waters - usedWaters);
if (waters < capacity) {
lastTime = now;
waters++;
return true;
}
return false;
}
}
可以看到水滴对应的就是请求。它的特点就是宽进严出,无论请求多少,请求的速率有多大,都按照固定的速率流出,对应的就是服务按照固定的速率处理请求。
经过漏洞这么一过滤,请求就能平滑的流出,看起来很像很挺完美的?实际上它的优点也即缺点。
面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样。
也就是说我们服务器应该可以变得灵活一点,将自己的接受能力主动的体现出来,而不是被动的去接受水桶流出来的水量。
所以就有了令牌桶算法。
令牌桶算法
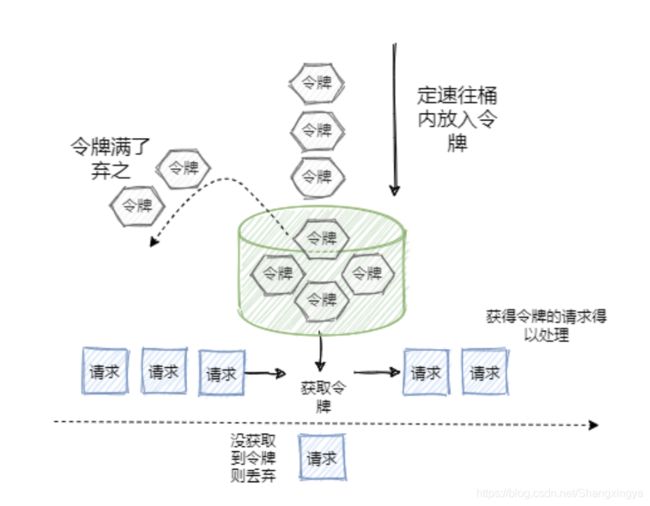
令牌桶其实和漏桶的原理类似,只不过漏桶是定速地流出,而令牌桶是定速地往桶里塞入令牌,然后请求只有拿到了令牌才能通过,之后再被服务器处理。
当然令牌桶的大小也是有限制的,假设桶里的令牌满了之后,定速生成的令牌会丢弃。
规则:
定速的往桶内放入令牌
令牌数量超过桶的限制,丢弃
请求来了先向桶内索要令牌,索要成功则通过被处理,反之拒绝
class TokenBucket {
private int tokens; //此时的令牌数目
private int rate; //服务器令牌生成速率
private long lastTime; //上一次放令牌的时间
public TokenBucket(int rate) {
this.rate = rate;
this.lastTime = System.currentTimeMillis();
}
public boolean tyrQuire() {
long now = System.currentTimeMillis(); // 获取当前时间
tokens += (now - lastTime) * rate; //计算此时有多少个令牌
if (tokens > 0) {
lastTime = now;
tokens--;
return true;
}
return false;
}
}
可以看出和漏桶的区别就在于一个是加法,一个是减法。
令牌桶在应对突发流量的时候,桶内假如有 100 个令牌,那么这 100 个令牌可以马上被取走,而不像漏桶那样匀速的消费。所以在应对突发流量的时候令牌桶表现的更佳。
单机限流和分布式限流
本质上单机限流和分布式限流的区别其实就在于 “阈值” 存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Tair 或 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗,所以有个优化点就是 「批量」。例如每次取令牌不是一个一取,而是取一批,不够了再去取一批。这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
限流组件
一般而言我们不需要自己实现限流算法来达到限流的目的,不管是接入层限流还是细粒度的接口限流其实都有现成的轮子使用,其实现也是用了上述我们所说的限流算法。
比如Google Guava 提供的限流工具类 RateLimiter,是基于令牌桶实现的,并且扩展了算法,支持预热功能。
阿里开源的限流框架 Sentinel 中的匀速排队限流策略,就采用了漏桶算法。
Nginx 中的限流模块 limit_req_zone,采用了漏桶算法,还有 OpenResty 中的 resty.limit.req库等等。