Prometheus监控系统详解
一、监控原理简介
监控系统在这里特指对数据中心的监控,主要针对数据中心内的硬件和软件进行监控和告警。
从监控对象的角度来看,可以将监控分为网络监控、存储监控、服务器监控和应用监控等。
从程序设计的角度来看,可以将监控分为基础资源监控、中间件监控、应用程序监控和日志监控。
1、基础资源监控
从监控对象的角度来看,可以将基础资源监控分为网络监控、存储监控和服务器监控。
1)网络监控
这里讲解的网络监控主要包括:
- 对数据中心内网络流量的监控;
- 对网络拓扑发现及网络设备的监控;
- 对网络性能的监控及对网络攻击的探测等。
网络监控主要有以下几个方向:
(1)网络性能监控(Network Performance Monitor,NPM):主要涉及网络监测、网络实时流量监控(网络延迟、访问量、成功率等)和历史数据统计、汇总和历史数据分析等功能。
(2)网络攻击检查:主要针对内网或者外网的网络攻击如DDos攻击等,通过分析异常流量来确定网络攻击行为。
(3)设备监控:主要针对数据中心内的多种网络设备进行监控,包括路由器、防火墙和交换机等硬件设备,可以通过SNMP等协议收集数据。
2)存储监控
存储主要分为云存储和分布式存储两部分:
- 云存储主要通过存储设备构建存储资源池,并对操作系统提供统一的存储接口,例如块存储的 SCSI和文件存储 NFS等。它们的特点是存储接口统一,并不识别存储数据的格式和内容,例如块存储只负责保存二进制数据块,这些二进制数据可能来自图片或视频,对于块存储来说都是一样的。
- 分布式存储主要构建在操作系统之上,提供分布式集群存储服务,主要是针对特定数据结构的数据存储。例如HDFS的大文件存储、Dynamo的键值数据存储、Elasticsearch的日志文档存储等。
我们可以将云存储监控分为存储性能监控、存储系统监控、存储设备监控:
- 在存储性能监控方面,块存储通常监控块的读写速率、IOPS、读写延迟、磁盘用量等;文件存储通常监控文件系统Inode、读写速度、目录权限等。
- 在存储系统监控方面,不同的存储系统有不同的指标。例如,对于Ceph存储,需要监控OSD、MON的运行状态,各种状态PG的数量,以及集群IOPS等信息。
- 在存储设备监控方面,对于构建在x86服务器上的存储设备,设备监控通过每个存储节点上的采集器统一收集磁盘、SSD、网卡等设备信息;存储厂商以黑盒方式提供的商业存储设备通常自带监控功能,可监控设备的运行状态、性能和容量等。
3)服务器监控
服务器监控包括物理服务器监控,虚拟机监控和容器监控。
- 对服务器硬件的兼容。数据中心内的服务器通常来自多个厂商如Dell、华为或者联想等,服务器监控需要获取不同厂商的服务器硬件信息。
- 对操作系统的兼容。为了适应不同软件的需求,在服务器上会安装不同的操作系统如 Windows、Linux,采集软件需要做到跨平台运行以获取对应的指标。
- 对虚拟化环境的兼容。当前,虚拟化已经成为数据中心的标配,可以更加高效便捷地获取计算和存储服务。服务器监控需要兼容各种虚拟化环境如虚拟机(KVM、VMware、Xen)及容器(Docker、rkt)。
采集方式通常分为两种:一种是内置客户端,即在每台机器上都安装采集客户端;另一种是在外部采集,例如在虚化环境中可以通过Xen API、VMware Vcenter API或者Libvirt的接口分别获取监控数据。
从操作系统层级来看,采集直指标通常如下:CPU、内存、网络IO、磁盘IO
服务器监控还包括针对物理硬件的监控,可以通过IPMI(Intelligent Platform Management Interface,智能平台管理接口)实现。IPMI是一种标准开放的硬件管理接口,不依赖于操作系统,可以提供服务器的风扇、温度、电压等信息。
4)中间件监控
常用的中间件主要有以下几类:
- 消息中间件,例如RabbitMQ、Kafka。
- Web服务中间件,例如Tomcat、Jetty。
- 缓存中间件,例如Redis、Memcached。
- 数据库中间件,例如MySQL、PostgreSQL。
5)应用程序监控(APM)
6)日志监控
目前业内比较流行的监控组合:
- Fluentd----Kafka----logstash----Elasticsearch----Kibana
- Fluentd:主要负责日志采集,其他开源组件还有Filebeta、Flume、Fluent、Bit等,也有以西而应用集成log4g等日志组件直接输出日志。
- Kafka:主要负责数据整流合并,避免突发日志流量直接冲击Logstash,业内也有用Redis替换Kafka的方案。
- Logstash:负责日志整理,可以完成日志过滤、日志修改等功能。
- Elasticserach:负责日志存储和日志检索,自带分布式存储,可以将采集的日志进行分片存储。
- Kibana:是一个日志查询组件,负责日志展现,主要通过Elasticsearch的HTTP接口展现日志。
2、监控系统实现
1)指标采集
指标采集包括数据采集、数据传输和过滤、以及数据存储
2)数据处理
数据处理分为:数据查询、数据分析和基于规则告警等。
二、Prometheus简介
prometheus受启发于Google的Brogmon监控系统(相似kubernetes是从Brog系统演变而来), 从2012年开始由google工程师Soundcloud以开源形式进行研发,并且与2015年早起对外发布早期版本。 2016年5月继kubernetes之后成为第二个加入CNCF基金会的项目,童年6月正式发布1.0版本。2017年底发布基于全兴存储层的2.0版本,能更好地与容器平台、云平台配合。
官方网站:https://prometheus.io
项目托管:https://github.com/prometheus
1)prometheus的优势
prometheus是基于一个开源的完整监控方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相对传统的监控系统有如下几个优点。
- 易于管理: 部署使用的是go编译的二进制文件,不存在任何第三方依赖问题,可以使用服务发现动态管理监控目标。
- 监控服务内部运行状态: 我们可以使用prometheus提供的常用开发语言提供的client库完成应用层面暴露数据, 采集应用内部运行信息。
- 强大的查询语言promQL: prometheus内置一个强大的数据查询语言PromQL,通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如grafana)以及告警中的。
- 高效: 对于监控系统而言,大量的监控任务必然导致有大量的数据产生。 而Prometheus可以高效地处理这些数据。
- 可扩展: prometheus配置比较简单, 可以在每个数据中心运行独立的prometheus server, 也可以使用联邦集群,让多个prometheus实例产生一个逻辑集群,还可以在单个prometheus server处理的任务量过大的时候,通过使用功能分区和联邦集群对其扩展。
- 易于集成: 目前官方提供多种语言的客户端sdk,基于这些sdk可以快速让应用程序纳入到监控系统中,同时还可以支持与其他的监控系统集成。
- 可视化: prometheus server自带一个ui, 通过这个ui可以方便对数据进行查询和图形化展示,可以对接grafana可视化工具展示精美监控指标。
2)Prometheus基础架构
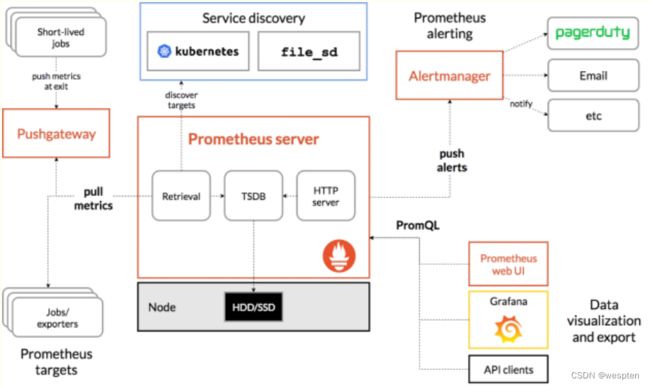
上面的架构图已经画的足够详细了。 这里在简单说下, prometheus负责从pushgateway和job中采集数据, 存储到后端Storatge中,可以通过PromQL进行查询, 推送alerts信息到AlertManager。 AlertManager根据不同的路由规则进行报警通知。
3)核心组件
(1)Prometheus
prometheus server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
(2)exporters
exporter简单说是采集端,通过http服务的形式保留一个url地址,prometheus server 通过访问该exporter提供的endpoint端点,即可获取到需要采集的监控数据。exporter分为2大类。
直接采集:这一类exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes等。
间接采集: 原有监控目标不支持prometheus,需要通过prometheus提供的客户端库编写监控采集程序,例如Mysql Exporter, JMX Exporter等。
(3)AlertManager
在prometheus中,支持基于PromQL创建告警规则,如果满足定义的规则,则会产生一条告警信息,进入AlertManager进行处理。可以集成邮件,Slack或者通过webhook自定义报警。
(4)PushGateway
由于Prometheus数据采集采用pull方式进行设置的, 内置必须保证prometheus server 和对应的exporter必须通信,当网络情况无法直接满足时,可以使用pushgateway来进行中转,可以通过pushgateway将内部网络数据主动push到gateway里面去,而prometheus采用pull方式拉取pushgateway中数据。
(5)Web UI
Prometheus内置一个简单的Web控制台,可以查询指标,查看配置信息或者Service Discovery等,实际工作中,查看指标或者创建仪表盘通常使用Grafana,Prometheus作为Grafana的数据源。
4)应用场景
适合场景:
普罗米修斯可以很好地记录任何纯数字时间序列。它既适合以机器为中心的监视,也适合高度动态的面向服务的体系结构的监视。在微服务的世界中,它对多维数据收集和查询的支持是一个特别的优势。普罗米修斯是为可靠性而设计的,它是您在停机期间使用的系统,允许您快速诊断问题。每台普罗米修斯服务器都是独立的,不依赖于网络存储或其他远程服务。当您的基础设施的其他部分被破坏时,您可以依赖它,并且您不需要设置广泛的基础设施来使用它。
不适合场景:
普罗米修斯值的可靠性。您总是可以查看有关系统的统计信息,即使在出现故障的情况下也是如此。如果您需要100%的准确性,例如按请求计费,普罗米修斯不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析用于计费的数据,并使用Prometheus来完成剩下的监视工作。
5)Prometheus数据模型
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。
时间序列格式:
{ 示例:
api_http_requests_total{method="POST", handler="/messages"}
度量名称{标签名=值}值。
HELP:说明指标是干什么的;
TYPE:指标类型,这个数据的指标类型;
注:度量名通常是一英文命名清晰。标签名英文、值推荐英文。
6)Prometheus指标类型
- Counter:递增的计数器
适合:API 接口请求次数,重试次数。 - Gauge:可以任意变化的数值
适合:cpu变化,类似波浪线不均匀。 - Histogram:对一段时间范围内数据进行采样,并对所有数值求和与统计数量、柱状图
适合:将web 一段时间进行分组,根据标签度量名称,统计这段时间这个度量名称有多少条。
适合:某个时间对某个度量值,分组,一段时间http相应大小,请求耗时的时间。 - Summary:与Histogram类似
三、Prometheus安装部署
1、下载
在prometheus的官网的download页面,可以找到prometheus的下载二进制包。
[root@node00 src]# cd /usr/src/
[root@node00 src]# wget https://github.com/prometheus/prometheus/releases/download/v2.12.0/prometheus-2.12.0.linux-amd64.tar.gz
[root@node00 src]# mkdir /usr/local/prometheus/
[root@node00 src]# tar xf prometheus-2.12.0.linux-amd64.tar.gz -C /usr/local/prometheus/
[root@node00 src]# cd /usr/local/prometheus/
[root@node00 prometheus]# ln -s prometheus-2.12.0.linux-amd64 prometheus
[root@node00 prometheus]# ll
total 0
lrwxrwxrwx 1 root root 29 Sep 20 05:06 prometheus -> prometheus-2.12.0.linux-amd64
drwxr-xr-x 4 3434 3434 132 Aug 18 11:40 prometheus-2.12.0.linux-amd64
[root@node00 prometheus]# cd prometheus
获取配置帮助:
[root@node00 prometheus]# ./prometheus --help2、启动服务
# 启动
[root@node00 prometheus]# ./prometheus
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:293 msg="no time or size retention was set so using the default time retention" duration=15d
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:329 msg="Starting Prometheus" version="(version=2.12.0, branch=HEAD, revision=43acd0e2e93f9f70c49b2267efa0124f1e759e86)"
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:330 build_context="(go=go1.12.8, user=root@7a9dbdbe0cc7, date=20190818-13:53:16)"
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:331 host_details="(Linux 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 node00 (none))"
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:332 fd_limits="(soft=1024, hard=4096)"
level=info ts=2019-09-20T09:45:35.470Z caller=main.go:333 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2019-09-20T09:45:35.473Z caller=main.go:654 msg="Starting TSDB ..."
level=info ts=2019-09-20T09:45:35.473Z caller=web.go:448 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2019-09-20T09:45:35.519Z caller=head.go:509 component=tsdb msg="replaying WAL, this may take awhile"
level=info ts=2019-09-20T09:45:35.520Z caller=head.go:557 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=0
level=info ts=2019-09-20T09:45:35.520Z caller=main.go:669 fs_type=XFS_SUPER_MAGIC
level=info ts=2019-09-20T09:45:35.520Z caller=main.go:670 msg="TSDB started"
level=info ts=2019-09-20T09:45:35.520Z caller=main.go:740 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2019-09-20T09:45:35.568Z caller=main.go:768 msg="Completed loading of configuration file" filename=prometheus.yml
level=info ts=2019-09-20T09:45:35.568Z caller=main.go:623 msg="Server is ready to receive web requests."
启动参数:
# 指定配置文件
--config.file="prometheus.yml"
# 指定监听地址端口
--web.listen-address="0.0.0.0:9090"
# 最大连接数
--web.max-connections=512
# tsdb数据存储的目录,默认当前data/
--storage.tsdb.path="data/"
# premetheus 存储数据的时间,默认保存15天
--storage.tsdb.retention=15d
3、测试访问
测试访问:http://localhost:9090
查看暴露指标:http://localhost.com:9090/metrics
4、配置开机自启
# 进入systemd文件目录
[root@node00 system]# cd /usr/lib/systemd/system
# 编写prometheus systemd文件
[root@node00 system]# cat prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/prometheus/prometheus
ExecStart=/usr/local/prometheus/prometheus/prometheus
[Install]
WantedBy=multi-user.target
# 启动
[root@node00 system]# systemctl restart prometheus
# 查看状态
[root@node00 system]# systemctl status prometheus
● prometheus.service - prometheus
Loaded: loaded (/usr/lib/systemd/system/prometheus.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2019-09-20 06:11:21 EDT; 4s ago
Main PID: 32871 (prometheus)
CGroup: /system.slice/prometheus.service
└─32871 /usr/local/prometheus/prometheus/prometheus
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.634Z caller=head.go:509 component=tsdb msg="replaying WAL, this may take awhile"
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.640Z caller=head.go:557 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=3
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.640Z caller=head.go:557 component=tsdb msg="WAL segment loaded" segment=1 maxSegment=3
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.641Z caller=head.go:557 component=tsdb msg="WAL segment loaded" segment=2 maxSegment=3
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.641Z caller=head.go:557 component=tsdb msg="WAL segment loaded" segment=3 maxSegment=3
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.642Z caller=main.go:669 fs_type=XFS_SUPER_MAGIC
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.642Z caller=main.go:670 msg="TSDB started"
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.642Z caller=main.go:740 msg="Loading configuration file" filename=prometheus.yml
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.686Z caller=main.go:768 msg="Completed loading of configuration file" filename=prometheus.yml
Sep 20 06:11:21 node00 prometheus[32871]: level=info ts=2019-09-20T10:11:21.686Z caller=main.go:623 msg="Server is ready to receive web requests."
# 开机自启配置
[root@node00 system]# systemctl enable prometheus
Created symlink from /etc/systemd/system/multi-user.target.wants/prometheus.service to /usr/lib/systemd/system/prometheus.service.
5、后端存储配置
默认情况下prometheus会将采集的数据防止到本机的data目录的, 存储数据的大小受限和扩展不便,这是使用influxdb作为后端的数据库来存储数据。
influxdb的官方文档地址为: Downloading InfluxDB OSS | InfluxDB OSS 1.7 Documentation 根据不同系统进行下载,这里使用官方提供的rpm进行安装。
# 下载rpm
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.8.x86_64.rpm
# 本地安装rpm
sudo yum localinstall influxdb-1.7.8.x86_64.rpm
# 查看安装的文件
[root@node00 influxdb]# rpm -ql influxdb
/etc/influxdb/influxdb.conf
/etc/logrotate.d/influxdb
/usr/bin/influx
/usr/bin/influx_inspect
/usr/bin/influx_stress
/usr/bin/influx_tsm
/usr/bin/influxd
/usr/lib/influxdb/scripts/influxdb.service
/usr/lib/influxdb/scripts/init.sh
/usr/share/man/man1/influx.1.gz
/usr/share/man/man1/influx_inspect.1.gz
/usr/share/man/man1/influx_stress.1.gz
/usr/share/man/man1/influx_tsm.1.gz
/usr/share/man/man1/influxd-backup.1.gz
/usr/share/man/man1/influxd-config.1.gz
/usr/share/man/man1/influxd-restore.1.gz
/usr/share/man/man1/influxd-run.1.gz
/usr/share/man/man1/influxd-version.1.gz
/usr/share/man/man1/influxd.1.gz
/var/lib/influxdb
/var/log/influxdb
# 备份默认的默认的配置文件,这里可以对influxdb的数据存放位置做些设置
[root@node00 influxdb]# cp /etc/influxdb/influxdb.conf /etc/influxdb/influxdb.conf.default
# 启动
[root@node00 influxdb]# systemctl restart influxdb
# 查看状态
[root@node00 influxdb]# systemctl status influxdb
# 客户端登陆测试, 创建一个prometheus的database供后续的prometheus使用。
[root@node00 influxdb]# influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.8
> show databases;
name: databases
name
----
_internal
> create database prometheus;
> show databases;
name: databases
name
----
_internal
prometheus
> exit
配置prometheus集成infludb:
官方的帮助文档在这里:
Prometheus endpoints support in InfluxDB | InfluxDB OSS 1.7 Documentation
[root@node00 prometheus]# pwd
/usr/local/prometheus/prometheus
cp prometheus.yml prometheus.yml.default
vim prometheus.yml
# 添加如下几行
remote_write:
- url: "http://localhost:8086/api/v1/prom/write?db=prometheus"
remote_read:
- url: "http://localhost:8086/api/v1/prom/read?db=prometheus"
systemctl restart prometheus
systemctl status prometheus
注意: 如果influxdb配置有密码, 请参考上面的官方文档地址进行配置。
6、测试数据是否存储到influxdb中
[root@node00 prometheus]# influx
Connected to http://localhost:8086 version 1.7.8
InfluxDB shell version: 1.7.8
> show databases;
name: databases
name
----
_internal
prometheus
> use prometheus
Using database prometheus
> show measures;
ERR: error parsing query: found measures, expected CONTINUOUS, DATABASES, DIAGNOSTICS, FIELD, GRANTS, MEASUREMENT, MEASUREMENTS, QUERIES, RETENTION, SERIES, SHARD, SHARDS, STATS, SUBSCRIPTIONS, TAG, USERS at line 1, char 6
> show MEASUREMENTS;
name: measurements
name
----
go_gc_duration_seconds
go_gc_duration_seconds_count
go_gc_duration_seconds_sum
go_goroutines
go_info
go_memstats_alloc_bytes
# 后面还是有很多,这里不粘贴了。
# 做个简单查询
> select * from prometheus_http_requests_total limit 10 ;
name: prometheus_http_requests_total
time __name__ code handler instance job value
---- -------- ---- ------- -------- --- -----
1568975686217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 1
1568975701216000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 2
1568975716218000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 3
1568975731217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 4
1568975746216000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 5
1568975761217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 6
1568975776217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 7
1568975791217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 8
1568975806217000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 9
1568975821216000000 prometheus_http_requests_total 200 /metrics localhost:9090 prometheus 10
四、Prometheus数据存储
Prometheus提供了两种存储方式,分别为本地存储和与远端存储。为了兼容本地存储和远程存储,Prometheus提供了fanout接口。
1、本地存储
Prometheus的本地存储为Promethazine TSDB。TSDB的设计有两个核心:block和WAL,而block有包含chunk、index、meta.json、tombstones。
- chunks:用于保存压缩后的时序数据。每个chunk的大小为512MB。
- index:是为了对监控数据进行快速检索和查询而设计的,主要用来记录chunk中时序的偏移位置。
- tombstone:用于数据进行软删除。
- meta.json:记录block的元数据信息,主要记录一个数据块记录样本的 起始时间(mintime)、截止时间(maxtime)、样本数、时序数和数据源等信息。
WAL(Writer-ahead logging,预写日志)是关系型数据库中利用日志来实现食物性和持久性的一种技术,既在进行某个操作之前先将这个事情记录下来,以便之后对数据进行回滚、重试等操作并保证数据可靠性。
2、远端存储
面对更多历史数据的持久化,Prometheus单纯依靠本地存储远不足以应对,围殴此引入远端存储。为了适应不同远端存储,Prometheus并没有选择对接各种存储,二十定义一套读写存储接口,并引入Adapter适配器。
目前已经实现Adapter的远程存储主要包括:InfluxDB、OpenTSDB 、CreateDB、TiKV、Cortex、M3DB。
五、Prometheus exporter
1、Node_exporter安装部署
[root@node00 ~]# cd /usr/src/
[root@node00 src]# wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
[root@node00 src]# mkdir /usr/local/exporter -pv
mkdir: created directory ‘/usr/local/exporter’
[root@node00 src]# tar xf node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/exporter/
[root@node00 src]# cd /usr/local/exporter/
[root@node00 exporter]# ls
node_exporter-0.18.1.linux-amd64
[root@node00 exporter]# ln -s node_exporter-0.18.1.linux-amd64/ node_exporter
node_exporter启动:
[root@node00 node_exporter]# ./node_exporter
INFO[0000] Starting node_exporter (version=0.18.1, branch=HEAD, revision=3db77732e925c08f675d7404a8c46466b2ece83e) source="node_exporter.go:156"
INFO[0000] Build context (go=go1.12.5, user=root@b50852a1acba, date=20190604-16:41:18) source="node_exporter.go:157"
INFO[0000] Enabled collectors: source="node_exporter.go:97"
# 中间输出省略
INFO[0000] Listening on :9100 source="node_exporter.go:170"
测试node_exporter:
[root@node00 ~]# curl 127.0.0.1:9100/metrics
# 这里可以看到node_exporter暴露出来的数据。
配置node_exporter开机自启:
[root@node00 system]# cd /usr/lib/systemd/system
# 准备systemd文件
[root@node00 systemd]# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
User=prometheus
Group=prometheus
ExecStart=/usr/local/exporter/node_exporter/node_exporter\
--web.listen-address=:20001\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat\
--collector.supervisord
[Install]
WantedBy=multi-user.target
# 启动
[root@node00 exporter]# systemctl restart node_exporter
# 查看状态
[root@node00 exporter]# systemctl status node_exporter
● node_exporter.service - node_exporter
Loaded: loaded (/usr/lib/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2019-09-20 22:43:09 EDT; 5s ago
Main PID: 88262 (node_exporter)
CGroup: /system.slice/node_exporter.service
└─88262 /usr/local/exporter/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(sshd|nginx).service
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - stat" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - systemd" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - textfile" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - time" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - timex" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - uname" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - vmstat" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - xfs" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg=" - zfs" source="node_exporter.go:104"
Sep 20 22:43:09 node00 node_exporter[88262]: time="2019-09-20T22:43:09-04:00" level=info msg="Listening on :9100" source="node_exporter.go:170"
# 开机自启
[root@node00 exporter]# systemctl enable node_exporter
2、配置prometheus采集node信息
修改配置文件:
[root@node00 prometheus]# cd /usr/local/prometheus/prometheus
[root@node00 prometheus]# vim prometheus.yml
# 在scrape_configs中加入job node ,最终scrape_configs如下配置
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
static_configs:
- targets:
- "192.168.100.10:20001"
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheus
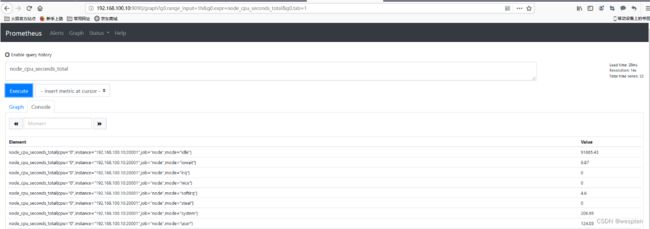
查看集成:

样例查询:
3、exporter详细配置
我们在主机上面安装了node_exporter程序,该程序对外暴露一个用于获取当前监控样本数据的http的访问地址, 这个的一个程序成为exporter,Exporter的实例称为一个target, prometheus通过轮训的方式定时从这些target中获取监控数据。
广义上向prometheus提供监控数据的程序都可以成为一个exporter的,一个exporter的实例称为target, exporter来源主要2个方面,一个是社区提供的,一种是用户自定义的。
1)常用exporter
官方和一些社区提供好多exproter, 我们可以直接拿过来采集我们的数据。
官方的exporter地址: Exporters and integrations | Prometheus
2)Blackbox Exporter
bloackbox exporter是prometheus社区提供的黑盒监控解决方案,运行用户通过HTTP、HTTPS、DNS、TCP以及ICMP的方式对网络进行探测。这里通过blackbox对我们的站点信息进行采集。
blackbox的安装:
# 进入下载目录
[root@node00 ~]# cd /usr/src/
# 下载
[root@node00 src]# wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.15.1/blackbox_exporter-0.15.1.linux-amd64.tar.gz
# 解压
[root@node00 src]# tar xf blackbox_exporter-0.15.1.linux-amd64.tar.gz
# 部署到特定位置
[root@node00 src]# mv blackbox_exporter-0.15.1.linux-amd64 /usr/local/exporter/
# 进入目录
[root@node00 src]# cd /usr/local/exporter/
# 软连接
[root@node00 exporter]# ln -s blackbox_exporter-0.15.1.linux-amd64 blackbox_exporter
# 进入自启目录
[root@node00 exporter]# cd /usr/lib/systemd/system
# 配置blackbox的开机自启文件
[root@node00 system]# cat blackbox_exporter.service
[Unit]
Description=blackbox_exporter
After=network.target
[Service]
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/exporter/blackbox_exporter
ExecStart=/usr/local/exporter/blackbox_exporter/blackbox_exporter
[Install]
WantedBy=multi-user.target
# 启动
[root@node00 system]# systemctl restart blackbox_exporter
# 查看状态
[root@node00 system]# systemctl status blackbox_exporter
# 开机自启
[root@node00 system]# systemctl enable blackbox_exporter
配置prometheus采集数据:
- job_name: "blackbox"
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/blackbox*.yml"
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.100.10:9115
[root@node00 prometheus]# cat conf/blackbox-dis.yml
- targets:
- https://www.alibaba.com
- https://www.tencent.com
- https://www.baidu.com
grafana展示blackbox采集数据:
重启prometheus查看数据, 可以在grafana导入dashboard id 9965 可以看到如下数据。

3)influxdb_export
influxdb_export 是用来采集influxdb数据的指标的,但是influxdb提供一个专门的一个产品来暴露metrics数据, 也就是说infludb_exporter这个第三方的产品将来会被淘汰了。
不过还是可以使用的,可以参考: https://github.com/prometheus/influxdb_exporter
infludb官方的工具来获取metrics数据是telegraf, 这个工具相当的强大,内部使用prometheus client插件来暴露数据给prometheus采集, 当然这个工具内部集成了几十种插件用户暴露数据给其他的监控系统。
详细的可以参考官方地址: Telegraf output plugins | InfluxData Documentation Archive
这里我们使用的监控系统是prometheus, 只需要关注如下配置即可:https://github.com/influxdata/telegraf/tree/release-1.7/plugins/outputs/prometheus_client
telegraf的安装配置:
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.12.2-1.x86_64.rpm
sudo yum localinstall telegraf-1.12.2-1.x86_64.rpm
rpm -ql |grep telegraf
cp /etc/telegraf/telegraf.conf /etc/telegraf/telegraf.conf.default
# 修改如下部分
[[outputs.prometheus_client]]
## Address to listen on
listen = ":9273"
systemctl restart telegraf
systemctl status telegraf
systemctl enabletelegraf
集成prometheus:
# prometheus加入如下采集
- job_name: "influxdb-exporter"
static_configs:
- targets: [ "192.168.100.10:9273" ]
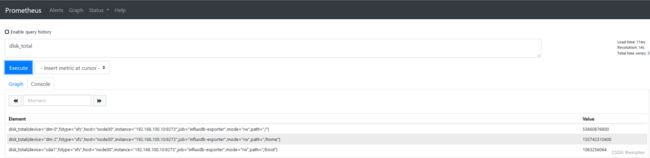
查看数据:
六、Prometheus配置详解
在prometheus监控系统,prometheus的职责是采集,查询和存储和推送报警到alertmanager。
1、全局配置文件
默认配置文件:
[root@node00 prometheus]# cat prometheus.yml.default
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- global: 此片段指定的是prometheus的全局配置, 比如采集间隔,抓取超时时间等。
- rule_files: 此片段指定报警规则文件, prometheus根据这些规则信息,会推送报警信息到alertmanager中。
- scrape_configs: 此片段指定抓取配置,prometheus的数据采集通过此片段配置。
- alerting: 此片段指定报警配置, 这里主要是指定prometheus将报警规则推送到指定的alertmanager实例地址。
- remote_write: 指定后端的存储的写入api地址。
- remote_read: 指定后端的存储的读取api地址。
global片段主要参数:
# How frequently to scrape targets by default.
[ scrape_interval: | default = 1m ] # 抓取间隔
# How long until a scrape request times out.
[ scrape_timeout: | default = 10s ] # 抓取超时时间
# How frequently to evaluate rules.
[ evaluation_interval: | default = 1m ] # 评估规则间隔
# The labels to add to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels: # 外部一些标签设置
[ : ... ]
scrapy_config片段主要参数:
一个scrape_config 片段指定一组目标和参数, 目标就是实例,指定采集的端点, 参数描述如何采集这些实例, 主要参数如下。
- scrape_interval: 抓取间隔,默认继承global值。
- scrape_timeout: 抓取超时时间,默认继承global值。
- metric_path: 抓取路径, 默认是/metrics
- scheme: 指定采集使用的协议,http或者https。
- params: 指定url参数。
- basic_auth: 指定认证信息。
- *_sd_configs: 指定服务发现配置
- static_configs: 静态指定服务job。
- relabel_config: relabel设置。
static_configs样例:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
static_configs:
- targets:
- "192.168.100.10:20001"
- "192.168.100.11:20001
- "192.168.100.12:20001"
file_sd_configs:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
# 独立文件配置如下
cat conf/node-dis.conf
- targets:
- "192.168.100.10:20001"
- "192.168.100.11:20001"
- "192.168.100.12:20001"
或者可以这样配置
[root@node00 conf]# cat node-dis.yml
- targets:
- "192.168.100.10:20001"
labels:
hostname: node00
- targets:
- "192.168.100.11:20001"
labels:
hostname: node01
- targets:
- "192.168.100.12:20001"
labels:
hostname: node02
通过file_fd_files 配置后我们可以在不重启prometheus的前提下, 修改对应的采集文件(node_dis.yml), 在特定的时间内(refresh_interval),prometheus会完成配置信息的载入工作。
consul_sd_file样例:
由于consul的配置需要有consul的服务提供, 这里简单部署下consul的服务。
# 进入下载目录
[root@node00 prometheus]# cd /usr/src/
# 下载
[root@node00 src]# wget https://releases.hashicorp.com/consul/1.6.1/consul_1.6.1_linux_amd64.zip
# 解压
[root@node00 src]# unzip consul_1.6.1_linux_amd64.zip
Archive: consul_1.6.1_linux_amd64.zip
inflating: consul
# 查看
[root@node00 src]# ls
consul consul_1.6.1_linux_amd64.zip debug kernels node_exporter-0.18.1.linux-amd64.tar.gz prometheus-2.12.0.linux-amd64.tar.gz
# 查看文件类型
[root@node00 src]# file consul
consul: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
# 防止到系统bin目录
[root@node00 src]# mv consul /usr/local/bin/
# 确保环境变量包含
[root@node00 src]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# 运行测试
[root@node00 consul.d]# consul agent -dev
# 测试获取成员
[root@node00 ~]# consul members
# 创建配置目录
[root@node00 ~]#mkdir /etc/consul.d
[root@node00 consul.d]# cat prometheus-node.json
{
"addresses": {
"http": "0.0.0.0",
"https": "0.0.0.0"
},
"services": [{
"name": "prometheus-node",
"tags": ["prometheus","node"],
"port": 20001
}]
}
# 指定配置文件运行
consul agent -dev -config-dir=/etc/consul.d
打开web管理界面 192.169.100.10:8500,查看相应的服务信息。
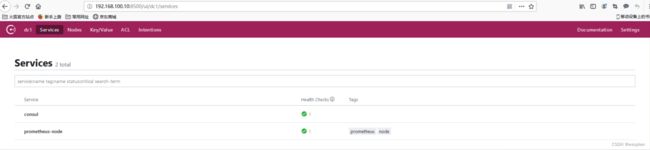
上面我们可以看到有2个service , 其中prometheus-node是我们定义的service。
和prometheus集成样例:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
consul_sd_configs:
- server: localhost:8500
services:
- prometheus-node
# tags:
# - prometheus
# - node
#- refresh_interval: 1m
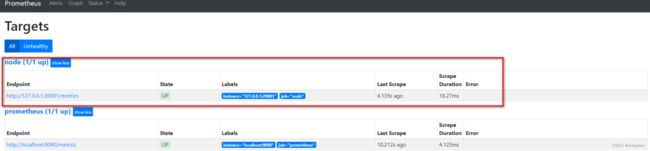
在prometheus的target界面上我们看到服务注册发现的结果。
我们通过api接口给该service添加一个节点, 看看是否可以同步过来。
[root@node00 ~]# curl -XPUT [email protected] 127.0.0.1:8500/v1/catalog/register
true
[root@node00 ~]# cat node01.json
{
"id":"0cc931ea-9a3a-a6ff-3ef5-e0c99371d77d",
"Node": "node01",
"Address": "192.168.100.11",
"Service":
{
"Port": 20001,
"ID": "prometheus-node",
"Service": "prometheus-node"
}
}
在consul和prometheus中查看:

2、Prometheus relabel配置
relabel_config:
重新标记是一个功能强大的工具,可以在目标的标签集被抓取之前重写它,每个采集配置可以配置多个重写标签设置,并按照配置的顺序来应用于每个目标的标签集。
目标重新标签之后,以__开头的标签将从标签集中删除的。
如果使用只需要临时的存储临时标签值的,可以使用_tmp作为前缀标识。
relabel的action类型:
- replace: 对标签和标签值进行替换。
- keep: 满足特定条件的实例进行采集,其他的不采集。
- drop: 满足特定条件的实例不采集,其他的采集。
- hashmod: 这个我也没看懂啥意思,囧。
- labelmap: 这个我也没看懂啥意思,囧。
- labeldrop: 对抓取的实例特定标签进行删除。
- labelkeep: 对抓取的实例特定标签进行保留,其他标签删除。
常用action的测试:
在测试前,同步下配置文件如下。
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
[root@node00 prometheus]# cat conf/node-dis.yml
- targets:
- "192.168.100.10:20001"
labels:
__hostname__: node00
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.11:20001"
labels:
__hostname__: node01
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.12:20001"
labels:
__hostname__: node02
__businees_line__: "line_c"
__region_id__: "cn-beijing"
__availability_zone__: "b"
此时如果查看target信息,如下图。

因为我们的label都是以__开头的,目标重新标签之后,以__开头的标签将从标签集中删除的。
一个简单的relabel设置:
将labels中的__hostname__替换为node_name。
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
relabel_configs:
- source_labels:
- "__hostname__"
regex: "(.*)"
target_label: "nodename"
action: replace
replacement: "$1"
重启服务查看target信息如下图:

说下上面的配置: source_labels指定我们我们需要处理的源标签, target_labels指定了我们要replace后的标签名字, action指定relabel动作,这里使用replace替换动作。 regex去匹配源标签(hostname)的值,"(.*)"代表__hostname__这个标签是什么值都匹配的,然后replacement指定的替换后的标签(target_label)对应的数值。采用正则引用方式获取的。
这里修改下上面的正则表达式为 ‘’regex: "(node00)"'的时候可以看到如下图。

keep:
修改配置文件:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
target如下图:

修改配置文件如下:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
relabel_configs:
- source_labels:
- "__hostname__"
regex: "node00"
action: keep
target如下图:

action为keep,只要source_labels的值匹配regex(node00)的实例才能会被采集。 其他的实例不会被采集。
drop:
在上面的基础上,修改action为drop。
target如下图:
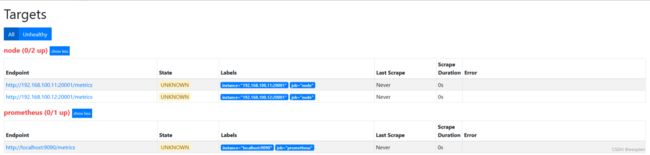
action为drop,其实和keep是相似的, 不过是相反的, 只要source_labels的值匹配regex(node00)的实例不会被采集。 其他的实例会被采集。
replace:
我们的基础信息里面有__region_id__和__availability_zone__,但是我想融合2个字段在一起,可以通过replace来实现。
修改配置如下:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
relabel_configs:
- source_labels:
- "__region_id__"
- "__availability_zone__"
separator: "-"
regex: "(.*)"
target_label: "region_zone"
action: replace
replacement: "$1"
target如下图:

abelkeep:
配置文件如下:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
relabel_configs:
- source_labels:
- "__hostname__"
regex: "(.*)"
target_label: "nodename"
action: replace
replacement: "$1"
- source_labels:
- "__businees_line__"
regex: "(.*)"
target_label: "businees_line"
action: replace
replacement: "$1"
- source_labels:
- "__datacenter__"
regex: "(.*)"
target_label: "datacenter"
action: replace
replacement: "$1"
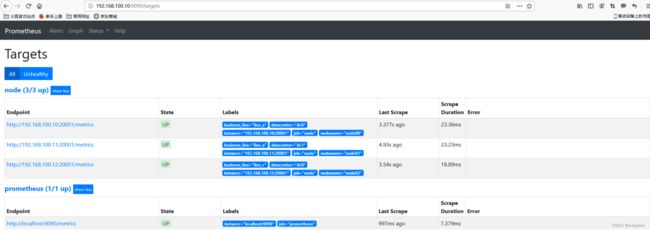
target如下图:
修改配置文件如下:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
relabel_configs:
- source_labels:
- "__hostname__"
regex: "(.*)"
target_label: "nodename"
action: replace
replacement: "$1"
- source_labels:
- "__businees_line__"
regex: "(.*)"
target_label: "businees_line"
action: replace
replacement: "$1"
- source_labels:
- "__datacenter__"
regex: "(.*)"
target_label: "datacenter"
action: replace
replacement: "$1"
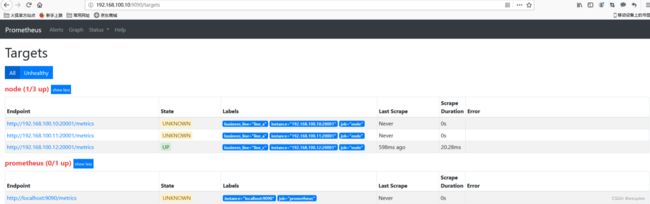
- regex: "(nodename|datacenter)"
action: labeldrop
target如下图:
七、PromQL查询语句
Prometheus提供了一种名为PromQL (Prometheus查询语言)的函数式查询语言,允许用户实时选择和聚合时间序列数据。表达式的结果既可以显示为图形,也可以在Prometheus的表达式浏览器中作为表格数据查看,或者通过HTTP API由外部系统使用。
1、准备工作
在进行查询,这里提供下我的配置文件如下
[root@node00 prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
file_sd_configs:
- refresh_interval: 1m
files:
- "/usr/local/prometheus/prometheus/conf/node*.yml"
remote_write:
- url: "http://localhost:8086/api/v1/prom/write?db=prometheus"
remote_read:
- url: "http://localhost:8086/api/v1/prom/read?db=prometheus"
[root@node00 prometheus]# cat conf/node-dis.yml
- targets:
- "192.168.100.10:20001"
labels:
__datacenter__: dc0
__hostname__: node00
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.11:20001"
labels:
__datacenter__: dc1
__hostname__: node01
__businees_line__: "line_a"
__region_id__: "cn-beijing"
__availability_zone__: "a"
- targets:
- "192.168.100.12:20001"
labels:
__datacenter__: dc0
__hostname__: node02
__businees_line__: "line_c"
__region_id__: "cn-beijing"
__availability_zone__: "b"
2、简单时序查询
1)直接查询特定metric_name
节点的forks的总次数:
node_forks_total
结果如下:
| Element | Value |
|---|---|
| node_forks_total{instance="192.168.100.10:20001",job="node"} | 201518 |
| node_forks_total{instance="192.168.100.11:20001",job="node"} | 23951 |
| node_forks_total{instance="192.168.100.12:20001",job="node"} | 24127 |
2)带标签的查询
node_forks_total{instance="192.168.100.10:20001"}
结果如下:
| Element | Value |
|---|---|
| node_forks_total{instance="192.168.100.10:20001",job="node"} | 201816 |
3)多标签查询
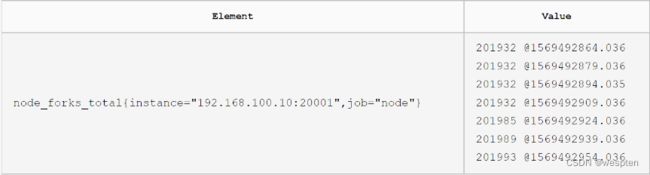
node_forks_total{instance="192.168.100.10:20001",job="node"}
结果如下:
Element Value
node_forks_total{instance="192.168.100.10:20001",job="node"} 201932
4)查询2分钟的时序数值
node_forks_total{instance="192.168.100.10:20001",job="node"}[2m]
5)正则匹配
node_forks_total{instance=~"192.168.*:20001",job="node"}
| Element | Value |
|---|---|
| node_forks_total{instance="192.168.100.10:20001",job="node"} | 202107 |
| node_forks_total{instance="192.168.100.11:20001",job="node"} | 24014 |
| node_forks_total{instance="192.168.100.12:20001",job="node"} | 24186 |
3、常用函数查询
官方提供的函数比较多, 具体可以参考地址如下: Query functions | Prometheus
这里主要就常用函数进行演示。
1)irate
irate用于计算速率。
通过标签查询,特定实例特定job,特定cpu 在idle状态下的cpu次数速率:
irate(node_cpu_seconds_total{cpu="0",instance="192.168.100.10:20001",job="node",mode="idle"}[1m])| Element | Value |
|---|---|
| {cpu="0",instance="192.168.100.10:20001",job="node",mode="idle"} | 0.9833988932595507 |
2)count_over_time
计算特定的时序数据中的个数。
这个数值个数和采集频率有关, 我们的采集间隔是15s,在一分钟会有4个点位数据:
count_over_time(node_boot_time_seconds[1m])| Element | Value |
|---|---|
| {instance="192.168.100.10:20001",job="node"} | 4 |
| {instance="192.168.100.11:20001",job="node"} | 4 |
| {instance="192.168.100.12:20001",job="node"} | 4 |
3)子查询
过去的10分钟内, 每分钟计算下过去5分钟的一个速率值。 一个采集10m/1m一共10个值。
rate(node_cpu_seconds_total{cpu="0",instance="192.168.100.10:20001",job="node",mode="idle"}[5m])[10m:1m]
4、复杂查询
1)计算内存使用百分比
node_memory_MemFree_bytes / node_memory_MemTotal_bytes * 100| Element | Value |
|---|---|
| {instance="192.168.100.10:20001",job="node"} | 9.927579722322251 |
| {instance="192.168.100.11:20001",job="node"} | 59.740727403673034 |
| {instance="192.168.100.12:20001",job="node"} | 63.2080982675149 |
2)获取所有实例的内存使用百分比前2个
topk(2,node_memory_MemFree_bytes / node_memory_MemTotal_bytes * 100 )| Element | Value |
|---|---|
| {instance="192.168.100.12:20001",job="node"} | 63.20129636298163 |
| {instance="192.168.100.11:20001",job="node"} | 59.50586164125955 |
5、实用查询样例
1)获取cpu核心个数
# 计算所有的实例cpu核心数
count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{mode="system"}) )
# 计算单个实例的
count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{mode="system",instance="192.168.100.11:20001"})
2)计算内存使用率
(1 - (node_memory_MemAvailable_bytes{instance=~"192.168.100.10:20001"} / (node_memory_MemTotal_bytes{instance=~"192.168.100.10:20001"})))* 100| Element | Value |
|---|---|
| {instance="192.168.100.10:20001",job="node"} | 87.09358620413717 |
3)计算根分区使用率
100 - ((node_filesystem_avail_bytes{instance="192.168.100.10:20001",mountpoint="/",fstype=~"ext4|xfs"} * 100) / node_filesystem_size_bytes {instance=~"192.168.100.10:20001",mountpoint="/",fstype=~"ext4|xfs"})

4)预测磁盘空间
# 整体分为 2个部分, 中间用and分割, 前面部分计算根分区使用率大于85的, 后面计算根据近6小时的数据预测接下来24小时的磁盘可用空间是否小于0 。
(1- node_filesystem_avail_bytes{fstype=~"ext4|xfs",mountpoint="/"}
/ node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"}) * 100 >= 85 and (predict_linear(node_filesystem_avail_bytes[6h],3600 * 24) < 0)
八、Prometheus Grafana 展示平台
在prometheus中,我们可以使用web页面进行数据的查询和展示, 不过展示效果不太理想,这里使用一款专业的展示平台进行展示。
1、grafana安装
# 下载
wget https://dl.grafana.com/oss/release/grafana-6.3.6-1.x86_64.rpm
# 安装
sudo yum localinstall grafana-6.3.6-1.x86_64.rpm
# 查看配置文件
[root@node00 ~]# rpm -ql grafana |grep etc
/etc/grafana
/etc/init.d/grafana-server
/etc/sysconfig/grafana-server
# 查看开机自启文件
[root@node00 ~]# rpm -ql grafana |grep systemd
/usr/lib/systemd/system/grafana-server.service
# 启动服务
[root@node00 grafana]# systemctl restart grafana-server
# 查看状态图
[root@node00 grafana]# systemctl status grafana-server
# 开机自启
[root@node00 grafana]# systemctl enable grafana-server
# 查看监听端口
[root@node00 grafana]# lsof -i :3000
2、WEB页面配置
1)首次登陆设置
访问web页面地址192.168.100.10:3000端口,会弹出基础的登陆窗口,默认的用户名和密码为: admin/admin。 首次登录会引导你修改密码的。
2)添加数据源
访问web页面地址192.168.100.10:3000/datasources, 点击 "Add data source" 按钮 ,选择Prometheus作为数据源类型。进入如下界面。
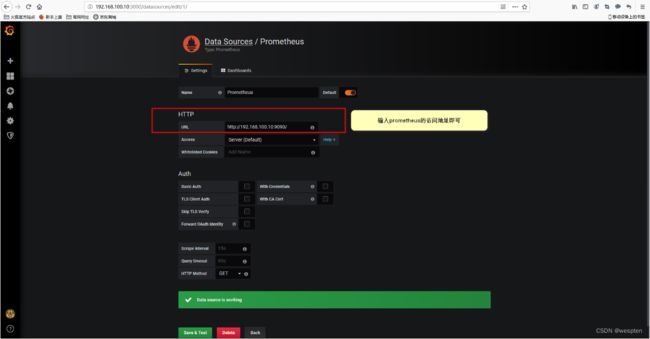
3)添加dashboard
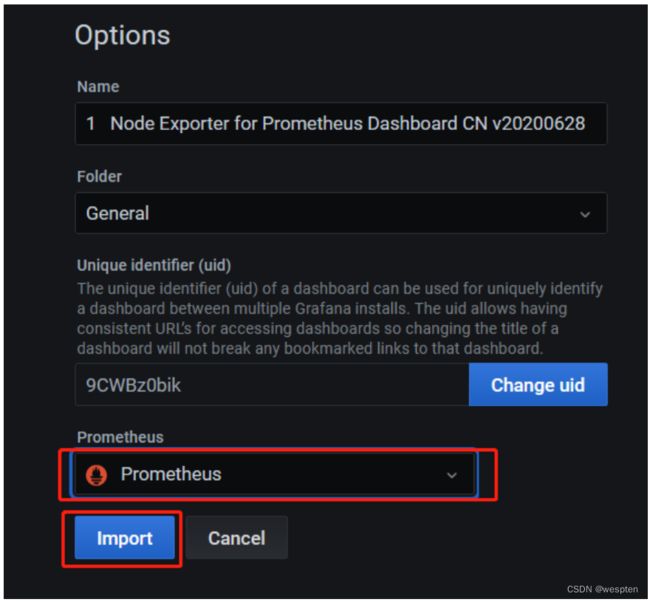
点击页面左上角的"+"号,然后选择import导入方式,输入1860,可以看到如下图:
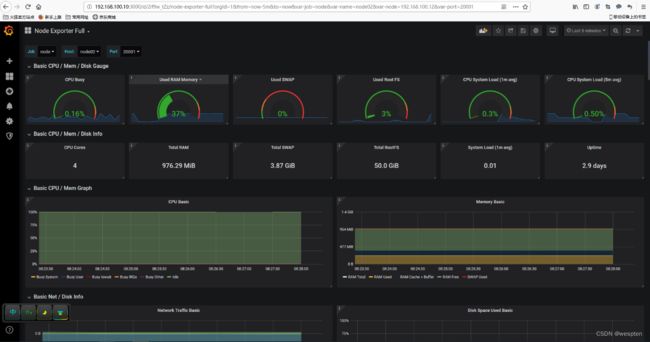
注意: 由于我是在虚拟机上面运行的node节点,运行采集时间较短,所以为了展示效果设置的展示时间为最近5分钟。
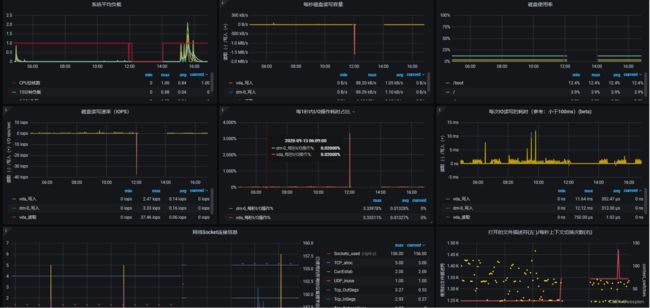
4)添加精简导出器
我这边根据网络上面的dashardboard进行修改,使用在工作中的dashboard如下图。


对应的json文件如下,可以通过import方式导入的:
{
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": "-- Grafana --",
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations & Alerts",
"type": "dashboard"
}
]
},
"description": "node-exporter",
"editable": true,
"gnetId": 8919,
"graphTooltip": 1,
"id": 131,
"iteration": 1569546050404,
"links": [],
"panels": [
{
"collapsed": false,
"gridPos": {
"h": 1,
"w": 24,
"x": 0,
"y": 0
},
"id": 180,
"panels": [],
"repeat": null,
"title": "基础信息",
"type": "row"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorPostfix": false,
"colorPrefix": false,
"colorValue": true,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"datasource": "Prometheus",
"decimals": 1,
"description": "",
"format": "s",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 2,
"x": 0,
"y": 1
},
"hideTimeOverride": true,
"id": 15,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": false
},
"tableColumn": "",
"targets": [
{
"expr": "time() - node_boot_time_seconds{instance=~\"$instance\"}",
"format": "time_series",
"hide": false,
"instant": true,
"intervalFactor": 2,
"legendFormat": "",
"refId": "A",
"step": 40
}
],
"thresholds": "1,2",
"title": "系统运行时间",
"transparent": true,
"type": "singlestat",
"valueFontSize": "100%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorPostfix": false,
"colorValue": true,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"datasource": "Prometheus",
"description": "",
"format": "short",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 2,
"w": 2,
"x": 2,
"y": 1
},
"id": 14,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": false
},
"tableColumn": "",
"targets": [
{
"expr": "count(count(node_cpu_seconds_total{instance=~\"$instance\", mode='system',job=\"$job\"}) by (cpu))",
"format": "time_series",
"instant": true,
"intervalFactor": 1,
"legendFormat": "",
"refId": "A",
"step": 20
}
],
"thresholds": "1,2",
"title": "CPU 核数",
"transparent": true,
"type": "singlestat",
"valueFontSize": "100%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": 2,
"description": "",
"format": "percent",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 3,
"x": 4,
"y": 1
},
"id": 167,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 2,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "100 - (avg(irate(node_cpu_seconds_total{instance=~\"$instance\",mode=\"idle\",job=\"$job\"}[1m])) * 100)",
"format": "time_series",
"hide": false,
"interval": "",
"intervalFactor": 1,
"legendFormat": "",
"refId": "A",
"step": 20
}
],
"thresholds": "50,80",
"title": "CPU使用率(1m)",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": 2,
"description": "",
"format": "percent",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 3,
"x": 7,
"y": 1
},
"id": 20,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 2,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "avg(irate(node_cpu_seconds_total{instance=~\"$instance\",mode=\"iowait\",job=\"$job\"}[1m])) * 100",
"format": "time_series",
"hide": false,
"interval": "",
"intervalFactor": 1,
"legendFormat": "",
"refId": "A",
"step": 20
}
],
"thresholds": "10,20",
"title": "CPU iowait(1m)",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": 0,
"description": "",
"format": "percent",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 3,
"x": 10,
"y": 1
},
"hideTimeOverride": false,
"id": 172,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "(1 - (node_memory_MemAvailable_bytes{instance=~\"$instance\",job=\"$job\"} / (node_memory_MemTotal_bytes{instance=~\"$instance\",job=\"$job\"})))* 100",
"format": "time_series",
"hide": false,
"interval": "10s",
"intervalFactor": 1,
"refId": "A",
"step": 20
}
],
"thresholds": "80,90",
"title": "内存使用率",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorPostfix": false,
"colorPrefix": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": 2,
"description": "",
"format": "short",
"gauge": {
"maxValue": 10000,
"minValue": null,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 3,
"x": 13,
"y": 1
},
"hideTimeOverride": false,
"id": 16,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "node_filefd_allocated{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"instant": false,
"interval": "10s",
"intervalFactor": 1,
"refId": "B"
}
],
"thresholds": "7000,9000",
"title": "当前打开的文件描述符",
"transparent": true,
"type": "singlestat",
"valueFontSize": "70%",
"valueMaps": [],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": null,
"description": "",
"format": "percent",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 4,
"x": 16,
"y": 1
},
"id": 166,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"repeatDirection": "h",
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "100 - ((node_filesystem_avail_bytes{instance=~\"$instance\",mountpoint=\"/\",fstype=~\"ext4|xfs\",job=\"$job\"} * 100) / node_filesystem_size_bytes {instance=~\"$instance\",mountpoint=\"/\",fstype=~\"ext4|xfs\",job=\"$job\"})",
"format": "time_series",
"interval": "10s",
"intervalFactor": 1,
"refId": "A",
"step": 20
}
],
"thresholds": "70,90",
"title": "根分区使用率",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"datasource": "Prometheus",
"decimals": null,
"description": "通过变量maxmount获取最大的分区。",
"format": "percent",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": true,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 5,
"w": 4,
"x": 20,
"y": 1
},
"id": 154,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "50%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"repeat": null,
"repeatDirection": "h",
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": true
},
"tableColumn": "",
"targets": [
{
"expr": "100 - ((node_filesystem_avail_bytes{instance=~\"$instance\",mountpoint=\"$maxmount\",fstype=~\"ext4|xfs\",job=\"$job\"} * 100) / node_filesystem_size_bytes {instance=~\"$instance\",mountpoint=\"$maxmount\",fstype=~\"ext4|xfs\",job=\"$job\"})",
"format": "time_series",
"interval": "10s",
"intervalFactor": 1,
"refId": "A",
"step": 20
}
],
"thresholds": "70,90",
"title": "最大分区($maxmount)使用率",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"cacheTimeout": null,
"colorBackground": false,
"colorValue": true,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"datasource": "Prometheus",
"decimals": null,
"description": "",
"format": "bytes",
"gauge": {
"maxValue": 100,
"minValue": 0,
"show": false,
"thresholdLabels": false,
"thresholdMarkers": true
},
"gridPos": {
"h": 3,
"w": 2,
"x": 2,
"y": 3
},
"id": 75,
"interval": null,
"links": [],
"mappingType": 1,
"mappingTypes": [
{
"name": "value to text",
"value": 1
},
{
"name": "range to text",
"value": 2
}
],
"maxDataPoints": 100,
"minSpan": 4,
"nullPointMode": "null",
"nullText": null,
"postfix": "",
"postfixFontSize": "70%",
"prefix": "",
"prefixFontSize": "50%",
"rangeMaps": [
{
"from": "null",
"text": "N/A",
"to": "null"
}
],
"sparkline": {
"fillColor": "rgba(31, 118, 189, 0.18)",
"full": false,
"lineColor": "rgb(31, 120, 193)",
"show": false
},
"tableColumn": "",
"targets": [
{
"expr": "node_memory_MemTotal_bytes{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"instant": true,
"intervalFactor": 1,
"legendFormat": "{{instance}}",
"refId": "A",
"step": 20
}
],
"thresholds": "2,3",
"title": "内存总量",
"transparent": true,
"type": "singlestat",
"valueFontSize": "80%",
"valueMaps": [
{
"op": "=",
"text": "N/A",
"value": "null"
}
],
"valueName": "current"
},
{
"gridPos": {
"h": 1,
"w": 24,
"x": 0,
"y": 6
},
"id": 178,
"title": "Memory && CPU",
"type": "row"
},
{
"aliasColors": {
"内存_Avaliable": "#6ED0E0",
"内存_Cached": "#EF843C",
"内存_Free": "#629E51",
"内存_Total": "#6d1f62",
"内存_Used": "#eab839",
"可用": "#9ac48a",
"总内存": "#bf1b00"
},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"decimals": 2,
"fill": 1,
"gridPos": {
"h": 7,
"w": 6,
"x": 0,
"y": 7
},
"height": "300",
"id": 156,
"legend": {
"alignAsTable": false,
"avg": false,
"current": false,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"sort": "current",
"sortDesc": true,
"total": false,
"values": false
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "node_memory_MemTotal_bytes{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"hide": false,
"instant": false,
"intervalFactor": 2,
"legendFormat": "总内存",
"refId": "A",
"step": 4
},
{
"expr": "node_memory_MemTotal_bytes{instance=~\"$instance\",job=\"$job\"} - node_memory_MemAvailable_bytes{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"hide": false,
"instant": false,
"intervalFactor": 2,
"legendFormat": "已用内存",
"refId": "B",
"step": 4
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "内存信息",
"tooltip": {
"shared": true,
"sort": 1,
"value_type": "individual"
},
"transparent": true,
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "bytes",
"label": null,
"logBase": 1,
"max": null,
"min": "0",
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {
"15分钟": "#6ED0E0",
"1分钟": "#BF1B00",
"5分钟": "#CCA300"
},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"editable": true,
"error": false,
"fill": 1,
"grid": {},
"gridPos": {
"h": 7,
"w": 6,
"x": 6,
"y": 7
},
"height": "300",
"id": 13,
"legend": {
"alignAsTable": false,
"avg": false,
"current": false,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"total": false,
"values": false
},
"lines": true,
"linewidth": 2,
"links": [],
"minSpan": 4,
"nullPointMode": "null as zero",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"repeat": null,
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "node_load1{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"instant": false,
"interval": "10s",
"intervalFactor": 2,
"legendFormat": "load_1m",
"metric": "",
"refId": "A",
"step": 20,
"target": ""
},
{
"expr": "node_load5{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"instant": false,
"interval": "10s",
"intervalFactor": 2,
"legendFormat": "load_5m",
"refId": "B",
"step": 20
},
{
"expr": "node_load15{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"instant": false,
"interval": "10s",
"intervalFactor": 2,
"legendFormat": "load_15m",
"refId": "C",
"step": 20
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "系统平均负载",
"tooltip": {
"msResolution": false,
"shared": true,
"sort": 0,
"value_type": "cumulative"
},
"transparent": true,
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {
"Idle - Waiting for something to happen": "#052B51",
"guest": "#9AC48A",
"idle": "#052B51",
"iowait": "#EAB839",
"irq": "#BF1B00",
"nice": "#C15C17",
"sdb_每秒I/O操作%": "#d683ce",
"softirq": "#E24D42",
"steal": "#FCE2DE",
"system": "#508642",
"user": "#5195CE",
"磁盘花费在I/O操作占比": "#ba43a9"
},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"decimals": 2,
"description": "",
"fill": 1,
"gridPos": {
"h": 7,
"w": 6,
"x": 12,
"y": 7
},
"id": 7,
"legend": {
"alignAsTable": false,
"avg": false,
"current": false,
"hideEmpty": true,
"hideZero": true,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"sideWidth": null,
"sort": null,
"sortDesc": null,
"total": false,
"values": false
},
"lines": true,
"linewidth": 1,
"links": [],
"minSpan": 4,
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"repeat": null,
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "(1 - avg by (environment,instance) (irate(node_cpu_seconds_total{instance=~\"$instance\",mode=\"idle\",job=\"$job\"}[1m])))",
"format": "time_series",
"hide": false,
"instant": false,
"interval": "",
"intervalFactor": 2,
"legendFormat": "CPU_Total",
"refId": "A",
"step": 20
},
{
"expr": "avg(irate(node_cpu_seconds_total{instance=~\"$instance\",mode=\"user\",job=\"$job\"}[1m])) by (instance)",
"format": "time_series",
"hide": false,
"intervalFactor": 2,
"legendFormat": "CPU_User",
"refId": "B",
"step": 240
},
{
"expr": "avg(irate(node_cpu_seconds_total{instance=~\"$instance\",mode=\"iowait\",job=\"$job\"}[1m])) by (instance)",
"format": "time_series",
"hide": false,
"intervalFactor": 2,
"legendFormat": "CPU_Iowait",
"refId": "D",
"step": 240
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "CPU使用率",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"transparent": true,
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"decimals": null,
"format": "percentunit",
"label": "",
"logBase": 1,
"max": "1",
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"breakPoint": "25%",
"cacheTimeout": null,
"combine": {
"label": "Others",
"threshold": 0
},
"datasource": "Prometheus",
"decimals": null,
"fontSize": "80%",
"format": "short",
"gridPos": {
"h": 7,
"w": 6,
"x": 18,
"y": 7
},
"id": 182,
"interval": null,
"legend": {
"header": "",
"percentage": false,
"show": true,
"sideWidth": null,
"values": false
},
"legendType": "On graph",
"links": [],
"maxDataPoints": 3,
"nullPointMode": "connected",
"pieType": "pie",
"strokeWidth": 1,
"targets": [
{
"application": {
"filter": ""
},
"expr": "sum by (instance,cpu) ( node_cpu_seconds_total{instance=~\"$instance\" , mode!=\"idle\"})",
"format": "time_series",
"functions": [],
"group": {
"filter": ""
},
"host": {
"filter": ""
},
"instant": true,
"intervalFactor": 1,
"item": {
"filter": ""
},
"legendFormat": "cpu-{{cpu}}",
"mode": 0,
"options": {
"showDisabledItems": false,
"skipEmptyValues": false
},
"refId": "A",
"resultFormat": "time_series",
"table": {
"skipEmptyValues": false
},
"triggers": {
"acknowledged": 2,
"count": true,
"minSeverity": 3
}
}
],
"title": "本机多颗CPU使用占比",
"transparent": true,
"type": "grafana-piechart-panel",
"valueName": "avg"
},
{
"collapsed": false,
"gridPos": {
"h": 1,
"w": 24,
"x": 0,
"y": 14
},
"id": 176,
"panels": [],
"repeat": null,
"title": "Disk",
"type": "row"
},
{
"aliasColors": {
"vda_write": "#6ED0E0"
},
"bars": true,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"description": "Reads completed: 每个磁盘分区每秒读完成次数\n\nWrites completed: 每个磁盘分区每秒写完成次数\n\nIO now 每个磁盘分区每秒正在处理的输入/输出请求数",
"fill": 2,
"gridPos": {
"h": 8,
"w": 6,
"x": 0,
"y": 15
},
"height": "300",
"id": 161,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"hideEmpty": true,
"hideZero": true,
"max": true,
"min": false,
"show": true,
"sort": "current",
"sortDesc": true,
"total": false,
"values": true
},
"lines": false,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [
{
"alias": "/.*_读取$/",
"transform": "negative-Y"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "irate(node_disk_reads_completed_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"interval": "",
"intervalFactor": 2,
"legendFormat": "{{device}}_读取",
"refId": "A",
"step": 10
},
{
"expr": "irate(node_disk_writes_completed_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"intervalFactor": 2,
"legendFormat": "{{device}}_写入",
"refId": "B",
"step": 10
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "磁盘读写速率(IOPS)",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"decimals": null,
"format": "iops",
"label": "读取(-)/写入(+)I/O ops/sec",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {
"vda_write": "#6ED0E0"
},
"bars": true,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"description": "Read bytes 每个磁盘分区每秒读取的比特数\nWritten bytes 每个磁盘分区每秒写入的比特数",
"fill": 2,
"gridPos": {
"h": 8,
"w": 6,
"x": 6,
"y": 15
},
"height": "300",
"id": 168,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"hideEmpty": true,
"hideZero": true,
"max": true,
"min": false,
"show": true,
"total": false,
"values": true
},
"lines": false,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [
{
"alias": "/.*_读取$/",
"transform": "negative-Y"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "irate(node_disk_read_bytes_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"interval": "",
"intervalFactor": 2,
"legendFormat": "{{device}}_读取",
"refId": "A",
"step": 10
},
{
"expr": "irate(node_disk_written_bytes_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"intervalFactor": 2,
"legendFormat": "{{device}}_写入",
"refId": "B",
"step": 10
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "磁盘读写容量大小",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"decimals": null,
"format": "Bps",
"label": "读取(-)/写入(+)",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {
"vda": "#6ED0E0"
},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"description": "Read time ms 每个磁盘分区读操作花费的秒数\n\nWrite time ms 每个磁盘分区写操作花费的秒数\n\nIO time ms 每个磁盘分区输入/输出操作花费的秒数\n\nIO time weighted 每个磁盘分区输入/输出操作花费的加权秒数",
"fill": 3,
"gridPos": {
"h": 8,
"w": 6,
"x": 12,
"y": 15
},
"height": "300",
"id": 160,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"hideEmpty": true,
"hideZero": true,
"max": true,
"min": false,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [
{
"alias": "/,*_读取$/",
"transform": "negative-Y"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "irate(node_disk_io_time_seconds_total{instance=~\"$node\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": true,
"interval": "",
"intervalFactor": 2,
"legendFormat": "{{device}}",
"refId": "A",
"step": 10
},
{
"expr": "irate(node_disk_io_time_weighted_seconds_total{instance=~\"$node\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": true,
"intervalFactor": 1,
"legendFormat": "{{device}}_加权",
"refId": "D"
},
{
"expr": "irate(node_disk_read_time_seconds_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"interval": "",
"intervalFactor": 1,
"legendFormat": "{{device}}_读取",
"refId": "B"
},
{
"expr": "irate(node_disk_write_time_seconds_total{instance=~\"$instance\",job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"intervalFactor": 1,
"legendFormat": "{{device}}_写入",
"refId": "C"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "磁盘IO读写时间",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "s",
"label": "读取(-)/写入(+)",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"columns": [],
"datasource": "Prometheus",
"fontSize": "120%",
"gridPos": {
"h": 8,
"w": 6,
"x": 18,
"y": 15
},
"id": 164,
"links": [],
"pageSize": null,
"scroll": true,
"showHeader": true,
"sort": {
"col": 4,
"desc": false
},
"styles": [
{
"alias": "Time",
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"pattern": "Time",
"type": "hidden"
},
{
"alias": "分区",
"colorMode": null,
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 2,
"mappingType": 1,
"pattern": "mountpoint",
"thresholds": [
""
],
"type": "string",
"unit": "bytes"
},
{
"alias": "可用空间",
"colorMode": "value",
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 2,
"mappingType": 1,
"pattern": "Value #A",
"thresholds": [
"10000000000",
"20000000000"
],
"type": "number",
"unit": "bytes"
},
{
"alias": "使用率",
"colorMode": "cell",
"colors": [
"rgba(50, 172, 45, 0.97)",
"rgba(237, 129, 40, 0.89)",
"rgba(245, 54, 54, 0.9)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 2,
"mappingType": 1,
"pattern": "Value #B",
"thresholds": [
"70",
"90"
],
"type": "number",
"unit": "percentunit"
},
{
"alias": "磁盘日增长率",
"colorMode": "cell",
"colors": [
"#0a50a1",
"#7eb26d",
"rgba(245, 54, 54, 0.9)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 1,
"link": false,
"mappingType": 1,
"pattern": "Value #C",
"thresholds": [
"0",
"10"
],
"type": "number",
"unit": "percentunit"
},
{
"alias": "文件系统",
"colorMode": null,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 2,
"link": false,
"mappingType": 1,
"pattern": "fstype",
"thresholds": [],
"type": "hidden",
"unit": "short"
},
{
"alias": "IP",
"colorMode": null,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"dateFormat": "YYYY-MM-DD HH:mm:ss",
"decimals": 2,
"link": false,
"mappingType": 1,
"pattern": "instance",
"thresholds": [],
"type": "hidden",
"unit": "short"
},
{
"alias": "",
"colorMode": null,
"colors": [
"rgba(245, 54, 54, 0.9)",
"rgba(237, 129, 40, 0.89)",
"rgba(50, 172, 45, 0.97)"
],
"decimals": 2,
"pattern": "/.*/",
"preserveFormat": true,
"sanitize": false,
"thresholds": [],
"type": "hidden",
"unit": "short"
}
],
"targets": [
{
"expr": "node_filesystem_avail_bytes {instance=~'$instance',fstype=~\"ext4|xfs\"}",
"format": "table",
"hide": false,
"instant": true,
"interval": "10s",
"intervalFactor": 1,
"legendFormat": "",
"refId": "A"
},
{
"expr": "1-(node_filesystem_free_bytes{instance=~'$instance',fstype=~\"ext4|xfs\"} / node_filesystem_size_bytes{instance=~'$instance',fstype=~\"ext4|xfs\"})",
"format": "table",
"hide": false,
"instant": true,
"intervalFactor": 1,
"legendFormat": "",
"refId": "B"
},
{
"expr": "((node_filesystem_avail_bytes{instance=~'$instance',fstype=~\"ext4|xfs\"} offset 1d - node_filesystem_avail_bytes{instance=~'$instance',fstype=~\"ext4|xfs\"} ) / node_filesystem_size_bytes{instance=~'$instance',fstype=~\"ext4|xfs\"} * 100 ) ",
"format": "table",
"hide": false,
"instant": true,
"intervalFactor": 1,
"legendFormat": "",
"refId": "C"
}
],
"title": "各分区可用空间",
"transform": "table",
"transparent": true,
"type": "table"
},
{
"collapsed": false,
"gridPos": {
"h": 1,
"w": 24,
"x": 0,
"y": 23
},
"id": 184,
"panels": [],
"title": "Network",
"type": "row"
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fill": 1,
"gridPos": {
"h": 8,
"w": 6,
"x": 0,
"y": 24
},
"height": "300",
"id": 157,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"hideEmpty": true,
"hideZero": true,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"sort": "current",
"sortDesc": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 2,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [
{
"alias": "/.*_out上传$/",
"transform": "negative-Y"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "irate(node_network_receive_bytes_total{instance=~'$instance',device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*',job=\"$job\"}[5m])*8",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "{{device}}_in下载",
"refId": "A",
"step": 4
},
{
"expr": "irate(node_network_transmit_bytes_total{instance=~'$instance',device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*',job=\"$job\"}[5m])*8",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "{{device}}_out上传",
"refId": "B",
"step": 4
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "网络流量",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "bps",
"label": "上传(-)/下载(+)",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"fill": 1,
"gridPos": {
"h": 8,
"w": 6,
"x": 6,
"y": 24
},
"height": "300",
"id": 185,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"hideEmpty": true,
"hideZero": true,
"max": false,
"min": false,
"rightSide": false,
"show": true,
"sort": "current",
"sortDesc": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 2,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [
{
"alias": "/.*_out上传$/",
"transform": "negative-Y"
}
],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "irate(node_network_receive_packets_total{instance=~'$instance',device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*',job=\"$job\"}[5m])",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "{{device}}_接收包",
"refId": "A",
"step": 4
},
{
"expr": "irate(node_network_transmit_packets_total{instance=~'$instance',device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*',job=\"$job\"}[5m])",
"format": "time_series",
"intervalFactor": 2,
"legendFormat": "{{device}}_发送包",
"refId": "B",
"step": 4
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "网络包",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"transparent": true,
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": "上传(-)/下载(+)",
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": false
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
},
{
"aliasColors": {
"TCP": "#6ED0E0"
},
"bars": false,
"dashLength": 10,
"dashes": false,
"datasource": "Prometheus",
"description": "CurrEstab - 当前状态为 ESTABLISHED 或 CLOSE-WAIT 的 TCP 连接数\n\nActiveOpens - 已从 CLOSED 状态直接转换到 SYN-SENT 状态的 TCP 平均连接数(1分钟内)\n\nPassiveOpens - 已从 LISTEN 状态直接转换到 SYN-RCVD 状态的 TCP 平均连接数(1分钟内)\n\nTCP_alloc - 已分配(已建立、已申请到sk_buff)的TCP套接字数量\n\nTCP_inuse - 正在使用(正在侦听)的TCP套接字数量\n\nTCP_tw - 等待关闭的TCP连接数",
"fill": 0,
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 24
},
"height": "300",
"id": 158,
"legend": {
"alignAsTable": true,
"avg": false,
"current": true,
"max": false,
"min": false,
"rightSide": true,
"show": true,
"total": false,
"values": true
},
"lines": true,
"linewidth": 1,
"links": [],
"nullPointMode": "null",
"percentage": false,
"pointradius": 5,
"points": false,
"renderer": "flot",
"seriesOverrides": [],
"spaceLength": 10,
"stack": false,
"steppedLine": false,
"targets": [
{
"expr": "node_netstat_Tcp_CurrEstab{instance=~'$instance',job=\"$job\"}",
"format": "time_series",
"hide": false,
"interval": "10s",
"intervalFactor": 1,
"legendFormat": "ESTABLISHED",
"refId": "A",
"step": 20
},
{
"expr": "node_sockstat_TCP_tw{instance=~'$instance',job=\"$job\"}",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "TCP_tw",
"refId": "D"
},
{
"expr": "irate(node_netstat_Tcp_ActiveOpens{instance=~'$instance',job=\"$job\"}[1m])",
"format": "time_series",
"hide": false,
"intervalFactor": 1,
"legendFormat": "ActiveOpens",
"refId": "B"
},
{
"expr": "irate(node_netstat_Tcp_PassiveOpens{instance=~'$instance',job=\"$job\"}[1m])",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "PassiveOpens",
"refId": "C"
},
{
"expr": "node_sockstat_TCP_alloc{instance=~'$instance',job=\"$job\"}",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "TCP_alloc",
"refId": "E"
},
{
"expr": "node_sockstat_TCP_inuse{instance=~'$instance',job=\"$job\"}",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "TCP_inuse",
"refId": "F"
},
{
"expr": "node_tcp_connection_states{instance=~\"$instance\",job=\"$job\"}",
"format": "time_series",
"intervalFactor": 1,
"legendFormat": "{{state}}",
"refId": "G"
}
],
"thresholds": [],
"timeFrom": null,
"timeRegions": [],
"timeShift": null,
"title": "TCP 连接情况",
"tooltip": {
"shared": true,
"sort": 0,
"value_type": "individual"
},
"transparent": false,
"type": "graph",
"xaxis": {
"buckets": null,
"mode": "time",
"name": null,
"show": true,
"values": []
},
"yaxes": [
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
},
{
"format": "short",
"label": null,
"logBase": 1,
"max": null,
"min": null,
"show": true
}
],
"yaxis": {
"align": false,
"alignLevel": null
}
}
],
"refresh": false,
"schemaVersion": 16,
"style": "dark",
"tags": [
"Prometheus",
"node_exporter",
"StarsL.cn"
],
"templating": {
"list": [
{
"auto": true,
"auto_count": 10,
"auto_min": "10s",
"current": {
"selected": true,
"text": "30s",
"value": "30s"
},
"hide": 0,
"label": "interval",
"name": "interval",
"options": [
{
"selected": false,
"text": "auto",
"value": "$__auto_interval_interval"
},
{
"selected": false,
"text": "5s",
"value": "5s"
},
{
"selected": false,
"text": "10s",
"value": "10s"
},
{
"selected": true,
"text": "30s",
"value": "30s"
},
{
"selected": false,
"text": "1m",
"value": "1m"
},
{
"selected": false,
"text": "10m",
"value": "10m"
},
{
"selected": false,
"text": "30m",
"value": "30m"
},
{
"selected": false,
"text": "1h",
"value": "1h"
},
{
"selected": false,
"text": "6h",
"value": "6h"
},
{
"selected": false,
"text": "12h",
"value": "12h"
},
{
"selected": false,
"text": "1d",
"value": "1d"
}
],
"query": "5s,10s,30s,1m,10m,30m,1h,6h,12h,1d",
"refresh": 2,
"skipUrlSync": false,
"type": "interval"
},
{
"allValue": null,
"current": {
"text": "node-exporter",
"value": "node-exporter"
},
"datasource": "Prometheus",
"definition": "label_values(node_uname_info, job)",
"hide": 0,
"includeAll": false,
"label": null,
"multi": false,
"name": "job",
"options": [
{
"selected": true,
"text": "node-exporter",
"value": "node-exporter"
}
],
"query": "label_values(node_uname_info, job)",
"refresh": 0,
"regex": "",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allFormat": "glob",
"allValue": null,
"current": {
"tags": [],
"text": "172.16.21.197:20001",
"value": [
"172.16.21.197:20001"
]
},
"datasource": "Prometheus",
"definition": "label_values(node_uname_info,instance)",
"hide": 0,
"includeAll": false,
"label": "instance",
"multi": true,
"multiFormat": "regex values",
"name": "instance",
"options": [],
"query": "label_values(node_uname_info,instance)",
"refresh": 2,
"regex": "",
"skipUrlSync": false,
"sort": 1,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"allValue": null,
"current": {
"text": "/",
"value": "/"
},
"datasource": "Prometheus",
"definition": "query_result(topk(1, sort_desc(max by (mountpoint) (node_filesystem_size_bytes{instance=~\"$instance\",fstype=~\"ext4|xfs\"}))))",
"hide": 2,
"includeAll": false,
"label": "",
"multi": false,
"name": "maxmount",
"options": [],
"query": "query_result(topk(1, sort_desc(max by (mountpoint) (node_filesystem_size_bytes{instance=~\"$instance\",fstype=~\"ext4|xfs\"}))))",
"refresh": 2,
"regex": "/.*=\\\"(.*)\\\".*/",
"skipUrlSync": false,
"sort": 0,
"tagValuesQuery": "",
"tags": [],
"tagsQuery": "",
"type": "query",
"useTags": false
},
{
"datasource": "prometheus_111",
"filters": [],
"hide": 0,
"label": "",
"name": "Filters",
"skipUrlSync": false,
"type": "adhoc"
}
]
},
"time": {
"from": "now-24h",
"to": "now"
},
"timepicker": {
"now": true,
"refresh_intervals": [
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
],
"time_options": [
"5m",
"15m",
"1h",
"6h",
"12h",
"24h",
"2d",
"7d",
"30d"
]
},
"timezone": "browser",
"title": "node-exporter",
"uid": "node-exporter",
"version": 49
}
关于grafana的使用,详细的使用文档还是官方的文档,地址为: https://grafana.com
九、Prometheus Alertmanager 告警配置
在Prometheus的报警系统中,是分为2个部分的, 规则是配置是在prometheus中的, prometheus组件完成报警推送给alertmanager的, alertmanager然后管理这些报警信息,包括静默、抑制、聚合和通过电子邮件、on-call通知系统和聊天平台等方法发送通知。
alertmanager集成报警系统的几个重要功能:
- 分组: 可以通过route书的group_by来进行报警的分组,多条消息一起发送。
- 抑制: 重要报警抑制低级别报警。
- 静默: 故障静默,确保在接下来的时间内不会在收到同样报警信息。
告警配置主要步骤如下:
- 安装和部署alertmanager
- 在prometheus中配置alertmanager的地址信息。
- 在prometheus中设置报警规则
- 在alertmanager配置接受者信息等
1、安装和部署alertmanager
整体来说,prometheus的所有套件都是比较简单的,这里提供一个简单部署方式。
# 进入下载目录
[root@node00 ~]# cd /usr/src/
# 下载alertmanager
[root@node00 src]# wget https://github.com/prometheus/alertmanager/releases/download/v0.19.0/alertmanager-0.19.0.linux-amd64.tar.gz
# 解压
[root@node00 src]# tar xf alertmanager-0.19.0.linux-amd64.tar.gz
[root@node00 src]# ll
total 126440
drwxr-xr-x 2 3434 3434 93 Sep 3 11:39 alertmanager-0.19.0.linux-amd64
-rw-r--r-- 1 root root 24201990 Sep 3 11:39 alertmanager-0.19.0.linux-amd64.tar.gz
-rw-r--r-- 1 root root 6930 Sep 25 04:33 a.txt
-rw-r--r-- 1 root root 39965581 Sep 24 20:53 consul_1.6.1_linux_amd64.zip
-rw-r--r-- 1 root root 4077560 Sep 10 20:20 consul-template_0.22.0_linux_amd64.tgz
drwxr-xr-x. 2 root root 6 Nov 5 2016 debug
drwxr-xr-x. 2 root root 6 Nov 5 2016 kernels
-rw-r--r-- 1 root root 8083296 Sep 20 21:08 node_exporter-0.18.1.linux-amd64.tar.gz
-rw-r--r-- 1 root root 53127635 Sep 20 05:05 prometheus-2.12.0.linux-amd64.tar.gz
# 部署到特定位置
[root@node00 src]# mv alertmanager-0.19.0.linux-amd64 /usr/local/prometheus/
[root@node00 src]# cd /usr/local/prometheus/
# 查看目录情况
[root@node00 prometheus]# ll
total 4
drwxr-xr-x 2 3434 3434 93 Sep 3 11:39 alertmanager-0.19.0.linux-amd64
lrwxrwxrwx 1 prometheus prometheus 29 Sep 20 05:06 prometheus -> prometheus-2.12.0.linux-amd64
drwxr-xr-x 6 prometheus prometheus 4096 Sep 26 06:01 prometheus-2.12.0.linux-amd64
# 创建软连接
[root@node00 prometheus]# ln -s alertmanager-0.19.0.linux-amd64 alertmanager
# 确认软连接
[root@node00 prometheus]# ll
total 4
lrwxrwxrwx 1 root root 31 Sep 27 03:12 alertmanager -> alertmanager-0.19.0.linux-amd64
drwxr-xr-x 2 3434 3434 93 Sep 3 11:39 alertmanager-0.19.0.linux-amd64
lrwxrwxrwx 1 prometheus prometheus 29 Sep 20 05:06 prometheus -> prometheus-2.12.0.linux-amd64
drwxr-xr-x 6 prometheus prometheus 4096 Sep 26 06:01 prometheus-2.12.0.linux-amd64
# 准备开机自启配置文件
[root@node00 alertmanager]# cd /usr/lib/systemd/system/
[root@node00 system]# cat alertmanager.service
[Unit]
Description=alertmanager
After=network.target
[Service]
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/prometheus/alertmanager
ExecStart=/usr/local/prometheus/alertmanager/alertmanager --log.level=debug --log.format=json
# ExecStart=/usr/local/prometheus/alertmanager/alertmanager
[Install] WantedBy=multi-user.target
# 修改权限
[root@node00 alertmanager]# chown prometheus:prometheus /usr/local/prometheus/alertmanager -R
# 启动
[root@node00 alertmanager]# systemctl restart alertmanager
# 查看状态
[root@node00 alertmanager]# systemctl status alertmanager
# 开机自启
[root@node00 system]# systemctl enable alertmanager
在prometheus集成alertmanager:
部署完毕alertmanager, 需要告知prometheus告警信息推送的位置, 通过如下配置即可完成。相对比较简单。
# /usr/local/prometheus/prometheus/prometheus.yml
# 修改此文件中的alerting的配置如下配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.100.10:9093
配置完毕后重启prometheus服务。
2、创建报警规则
为了能先走通流程,这里的报警规则先弄一个简单一点的。
[root@node00 prometheus]# vim prometheus.yml
rule_files:
- "rules/*rules.yml"
# - "second_rules.yml"
[root@node00 prometheus]# mkdir rules
[root@node00 prometheus]# cat rules/node_rules.yml
groups:
- name: node-alert
rules:
- alert: disk-full
expr: 100 - ((node_filesystem_avail_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100) / node_filesystem_size_bytes {mountpoint="/",fstype=~"ext4|xfs"})
for: 1m
labels:
serverity: page
annotations:
summary: "{{ $labels.instance }} disk full "
description: "{{ $labels.instance }} disk > {{ $value }} "
重启prometheus服务,可以在web界面看到如下信息:
查看当前是否有报警信息:
目前看是没有磁盘满的, 我们这里配合下触发这个报警规则:
# 注意这个是在节点01上面执行的
[root@node01 ~]# df -h |grep "/$"
/dev/mapper/centos-root 50G 1.5G 49G 3% /
# 手工生成一个大文件
[root@node01 ~]# dd if=/dev/zero of=bigfile bs=1M count=40000
40000+0 records in
40000+0 records out
41943040000 bytes (42 GB) copied, 18.8162 s, 2.2 GB/s
# 节点上面确认磁盘是超过我们之前的报警设置值了
[root@node01 ~]# df -h |grep "/$"
/dev/mapper/centos-root 50G 41G 9.6G 81% /
等1分钟后在此查看alert信息,如下:
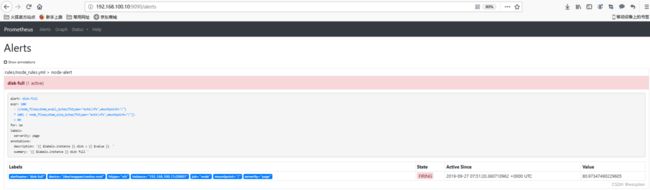
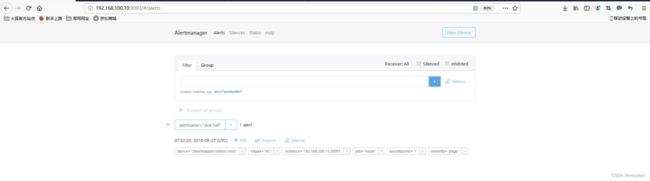
3、配置消息接收
上面的消息信息已经从prometheus推送给alertmanager了, 我们已经可以在alertmanager的web管理界面看到对应的报警信息,但是我们还没有配置如何让alertmanager把这些信息推送我们的社交软件上面去。
由于邮件系统大家用的比较多,这里就是用qq邮箱进行后续试验。
[root@node00 alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
###################################
smtp_auth_username: "[email protected]"
smtp_auth_password: "这是你的QQ邮箱授权码而不是密码,切记切记,具体授权码获取看后面的本文末尾介绍有"
#smtp_auth_secret: ""
smtp_require_tls: false
smtp_smarthost: "smtp.qq.com:465"
smtp_from: "[email protected]"
####################################
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email-zhaojiedi'
receivers:
- name: 'email-zhaojiedi'
email_configs:
- send_resolved: true
to: [email protected]
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置完毕alertmanager重启alertmanager,可以收到如下邮件信息。
4、测试邮件发送
使用如下命令触发报警:
[root@node01 ~]# dd if=/dev/zero of=bigfile bs=1M count=40000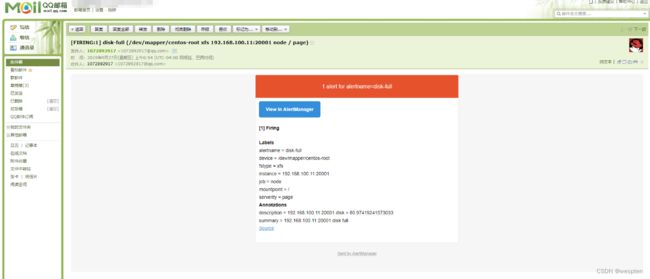
注意: 如果调试过程中有问题, 请查看/var/log/message信息,获取alertmanager发送邮件的错误信息。
测试报警恢复通知,使用如下命令清理文件:
[root@node01 ~]# >bigfile可以收到如下邮件:
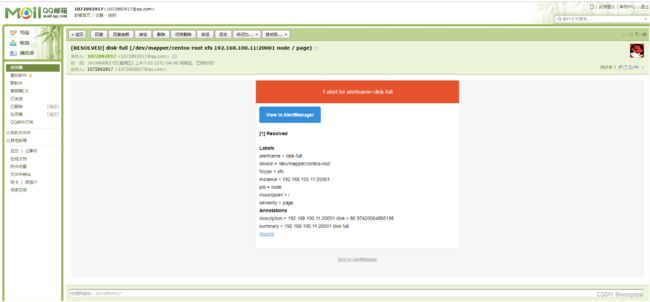
5、alertmanager配置文件
alertmanager是通过命令行标记和配置文件配置的,命令行标记配置不可变的系统参数,配置文件定义抑制规则、通知路由和通知接收器。可以通过官方提供的routing tree editor 查看配置的路由树详细信息。
默认配置文件如下:
[root@node00 ~]# cd /usr/local/prometheus/alertmanager/
[root@node00 alertmanager]# cat alertmanager.yml.default
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
这个默认配置文件时通过一个webhook作为接受者,alertmanager会在报警的时候给这个webhook地址发送一个post请求,提交报警信息, 由webhook内部完成消息发送。 下面的inhibit_rules配置一个抑制规则,就是critical级别的规则抑制warning级别的报警。
1)global配置
- resolve_timeout: 这个解释有点绕,简单说就是在报警恢复的时候不是立马发送的,在接下来的这个时间内,如果没有此报警信息触发,才发送报警恢复消息。 默认值为5m。
- smtp_from: 发件人邮箱地址。
- smtp_smarthost: 发件人对应邮件提供商的smtp地址。
- smtp_auth_username: 发件人的登陆用户名,默认和发件人地址一致。
- smtp_auth_password: 发件人的登陆密码,有时候是授权码。
- smtp_require_tls: 是否需要tls协议。默认是true。
- wechart_api_url: 微信api地址。
- wechart_api_secret: 密码
- wechat_api_corp_id: corp id信息。
2)templates配置
模板用于控制我们发送的消息格式控制和内容组织的,我们可以自定义一个模板, 模板中引用alertmanager提供的一些内置变量,最终完成消息的渲染。
样例如下:
# alertmanager配置文件
templates:
- '/usr/local/prometheus/alertmanager/templates/myorg.tmpl'
# cat /usr/local/prometheus/alertmanager/templates/myorg.tmpl
{{ define "slack.myorg.text" }}https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}{{ end}}
3)receivers配置
receivers的配置相对简单,没啥可以说的。提供一个样例配置文件。
receivers:
- name: 'email-zhaojiedi'
email_configs:
- to: '[email protected]'
- name: 'hipchat-zhaojiedi'
hipchat_configs:
- auth_token:
room_id: 85
message_format: html
notify: true
- name: 'pagerduty-zhaojiedi'
pagerduty_configs:
- service_key:
- name: 'opt-webhook'
send_resolved: true
url: "http://xxxxx.xxx.com/5002/dingding/xxx/send/
官方提供很多receviers的配置格式, 详细的参考官方文档: Configuration | Prometheus
4)route配置
route在这些配置中,相对是比较复杂的,这个配置主要是完成,报警规格会进入路由树,根据路由规则中的match或者match_re来匹配, 如果匹配中就会选择一个树分支来进行,找到此分支对应的receiver来发送对应的消息信息。
如果所有route信息都没法命中,就采用默认的receiver这个配置来发送消息。
样例如下:
routes:
- match_re:
service: ^(foo1|foo2|baz)$
receiver: team-X-mails
routes:
- match:
severity: critical
receiver: team-X-pager
- match:
service: files
receiver: team-Y-mails
routes:
- match:
severity: critical
receiver: team-Y-pager
- match:
service: database
receiver: team-DB-pager
# Also group alerts by affected database.
group_by: [alertname, cluster, database]
routes:
- match:
owner: team-X
receiver: team-X-pager
continue: true
- match:
owner: team-Y
receiver: team-Y-pager
这个配置文件时从alertmanager官方的github上面找到的。
地址如下:alertmanager/simple.yml at main · prometheus/alertmanager · GitHub , 我们可以通过官方的工具来看下这个路由树是什么样的。

5)inhibit_rules配置
我们知道alertmanager对报警有抑制工程, 可以通过一定的规则,抑制一些报警消息,比如如下场景。
场景1 : 磁盘报警,80%报警设置为info级别,90设置为警告级别, 如果2个消息都发送,那就多余了。 我们需要设置相同报警高级别压制低级别的报警,只发送高级别的报警信息。
场景2: 节点宕机了, 在这个节点上面的各种服务报警都会触发的, 如果都发送不太方便定位问题,还容易带来巨大的压力。可以配置节点宕机压制节点层面的其他报警信息。
样例配置如下:
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
equal: ['alertname' ]
通过上面的配置,可以在alertname相同的情况下,critaical的报警会抑制warning级别的报警信息。
6)静默配置
静默配置是通过web界面配置的, 如下图。
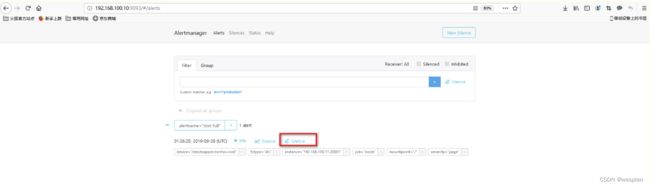
进入静默配置页面:
6、Prometheus告警规则配置
prometheus监控系统的的报警规则是在prometheus这个组件完成配置的。 prometheus支持2种类型的规则,记录规则和报警规则, 记录规则主要是为了简写报警规则和提高规则复用的, 报警规则才是真正去判定是否需要报警的规则。 报警规则中是可以使用记录规则的。
提供下我整理的node-exporter的记录规则和报警规则。
node-exporter-record-rules.yml:
groups:
- name: node-exporter-record
rules:
- expr: up{job=~"node-exporter"}
record: node_exporter:up
labels:
desc: "节点是否在线, 在线1,不在线0"
unit: " "
job: "node-exporter"
- expr: time() - node_boot_time_seconds{}
record: node_exporter:node_uptime
labels:
desc: "节点的运行时间"
unit: "s"
job: "node-exporter"
##############################################################################################
# cpu #
- expr: (1 - avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:total:percent
labels:
desc: "节点的cpu总消耗百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:idle:percent
labels:
desc: "节点的cpu idle百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="iowait"}[5m]))) * 100
record: node_exporter:cpu:iowait:percent
labels:
desc: "节点的cpu iowait百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="system"}[5m]))) * 100
record: node_exporter:cpu:system:percent
labels:
desc: "节点的cpu system百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="user"}[5m]))) * 100
record: node_exporter:cpu:user:percent
labels:
desc: "节点的cpu user百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode=~"softirq|nice|irq|steal"}[5m]))) * 100
record: node_exporter:cpu:other:percent
labels:
desc: "节点的cpu 其他的百分比"
unit: "%"
job: "node-exporter"
##############################################################################################
##############################################################################################
# memory #
- expr: node_memory_MemTotal_bytes{job="node-exporter"}
record: node_exporter:memory:total
labels:
desc: "节点的内存总量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:free
labels:
desc: "节点的剩余内存量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:used
labels:
desc: "节点的已使用内存量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemAvailable_bytes{job="node-exporter"}
record: node_exporter:memory:actualused
labels:
desc: "节点用户实际使用的内存量"
unit: byte
job: "node-exporter"
- expr: (1-(node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:used:percent
labels:
desc: "节点的内存使用百分比"
unit: "%"
job: "node-exporter"
- expr: ((node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:free:percent
labels:
desc: "节点的内存剩余百分比"
unit: "%"
job: "node-exporter"
##############################################################################################
# load #
- expr: sum by (instance) (node_load1{job="node-exporter"})
record: node_exporter:load:load1
labels:
desc: "系统1分钟负载"
unit: " "
job: "node-exporter"
- expr: sum by (instance) (node_load5{job="node-exporter"})
record: node_exporter:load:load5
labels:
desc: "系统5分钟负载"
unit: " "
job: "node-exporter"
- expr: sum by (instance) (node_load15{job="node-exporter"})
record: node_exporter:load:load15
labels:
desc: "系统15分钟负载"
unit: " "
job: "node-exporter"
##############################################################################################
# disk #
- expr: node_filesystem_size_bytes{job="node-exporter" ,fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:total
labels:
desc: "节点的磁盘总量"
unit: byte
job: "node-exporter"
- expr: node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:free
labels:
desc: "节点的磁盘剩余空间"
unit: byte
job: "node-exporter"
- expr: node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"} - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:used
labels:
desc: "节点的磁盘使用的空间"
unit: byte
job: "node-exporter"
- expr: (1 - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:disk:used:percent
labels:
desc: "节点的磁盘的使用百分比"
unit: "%"
job: "node-exporter"
- expr: irate(node_disk_reads_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:read:count:rate
labels:
desc: "节点的磁盘读取速率"
unit: "次/秒"
job: "node-exporter"
- expr: irate(node_disk_writes_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:write:count:rate
labels:
desc: "节点的磁盘写入速率"
unit: "次/秒"
job: "node-exporter"
- expr: (irate(node_disk_written_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:read:mb:rate
labels:
desc: "节点的设备读取MB速率"
unit: "MB/s"
job: "node-exporter"
- expr: (irate(node_disk_read_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:write:mb:rate
labels:
desc: "节点的设备写入MB速率"
unit: "MB/s"
job: "node-exporter"
##############################################################################################
# filesystem #
- expr: (1 -node_filesystem_files_free{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_files{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:filesystem:used:percent
labels:
desc: "节点的inode的剩余可用的百分比"
unit: "%"
job: "node-exporter"
#############################################################################################
# filefd #
- expr: node_filefd_allocated{job="node-exporter"}
record: node_exporter:filefd_allocated:count
labels:
desc: "节点的文件描述符打开个数"
unit: "%"
job: "node-exporter"
- expr: node_filefd_allocated{job="node-exporter"}/node_filefd_maximum{job="node-exporter"} * 100
record: node_exporter:filefd_allocated:percent
labels:
desc: "节点的文件描述符打开百分比"
unit: "%"
job: "node-exporter"
#############################################################################################
# network #
- expr: avg by (environment,instance,device) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:bit:rate
labels:
desc: "节点网卡eth0每秒接收的比特数"
unit: "bit/s"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:bit:rate
labels:
desc: "节点网卡eth0每秒发送的比特数"
unit: "bit/s"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_receive_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:packet:rate
labels:
desc: "节点网卡每秒接收的数据包个数"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:packet:rate
labels:
desc: "节点网卡发送的数据包个数"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:error:rate
labels:
desc: "节点设备驱动器检测到的接收错误包的数量"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:error:rate
labels:
desc: "节点设备驱动器检测到的发送错误包的数量"
unit: "个/秒"
job: "node-exporter"
- expr: node_tcp_connection_states{job="node-exporter", state="established"}
record: node_exporter:network:tcp:established:count
labels:
desc: "节点当前established的个数"
unit: "个"
job: "node-exporter"
- expr: node_tcp_connection_states{job="node-exporter", state="time_wait"}
record: node_exporter:network:tcp:timewait:count
labels:
desc: "节点timewait的连接数"
unit: "个"
job: "node-exporter"
- expr: sum by (environment,instance) (node_tcp_connection_states{job="node-exporter"})
record: node_exporter:network:tcp:total:count
labels:
desc: "节点tcp连接总数"
unit: "个"
job: "node-exporter"
#############################################################################################
# process #
- expr: node_processes_state{state="Z"}
record: node_exporter:process:zoom:total:count
labels:
desc: "节点当前状态为zoom的个数"
unit: "个"
job: "node-exporter"
#############################################################################################
# other #
- expr: abs(node_timex_offset_seconds{job="node-exporter"})
record: node_exporter:time:offset
labels:
desc: "节点的时间偏差"
unit: "s"
job: "node-exporter"
#############################################################################################
- expr: count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{ mode='system'}) )
record: node_exporter:cpu:count
#
node-exporter-alert-rules.yml:
groups:
- name: node-exporter-alert
rules:
- alert: node-exporter-down
expr: node_exporter:up == 0
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 宕机了"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} 关机了, 时间已经1分钟了。"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-cpu-high
expr: node_exporter:cpu:total:percent > 80
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-cpu-iowait-high
expr: node_exporter:cpu:iowait:percent >= 12
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-load-load1-high
expr: (node_exporter:load:load1) > (node_exporter:cpu:count) * 1.2
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} load1 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-memory-high
expr: node_exporter:memory:used:percent > 85
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-disk-high
expr: node_exporter:disk:used:percent > 88
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} disk 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-disk-read:count-high
expr: node_exporter:disk:read:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops read 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-disk-write-count-high
expr: node_exporter:disk:write:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops write 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-disk-read-mb-high
expr: node_exporter:disk:read:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 读取字节数 高于 {{ $value }}"
description: ""
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-disk-write-mb-high
expr: node_exporter:disk:write:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 写入字节数 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-filefd-allocated-percent-high
expr: node_exporter:filefd_allocated:percent > 80
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 打开文件描述符 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-network-netin-error-rate-high
expr: node_exporter:network:netin:error:rate > 4
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入的错误速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-network-netin-packet-rate-high
expr: node_exporter:network:netin:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-network-netout-packet-rate-high
expr: node_exporter:network:netout:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包流出速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-network-tcp-total-count-high
expr: node_exporter:network:tcp:total:count > 40000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} tcp连接数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-process-zoom-total-count-high
expr: node_exporter:process:zoom:total:count > 10
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 僵死进程数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
- alert: node-exporter-time-offset-high
expr: node_exporter:time:offset > 0.03
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} {{ $labels.desc }} {{ $value }} {{ $labels.unit }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
grafana: "http://xxxxxxxx.com/d/node-exporter/node-exporter?orgId=1&var-instance={{ $labels.instance }} "
console: "https://ecs.console.aliyun.com/#/server/{{ $labels.instanceid }}/detail?regionId=cn-beijing"
cloudmonitor: "https://cloudmonitor.console.aliyun.com/#/hostDetail/chart/instanceId={{ $labels.instanceid }}&system=®ion=cn-beijing&aliyunhost=true"
id: "{{ $labels.instanceid }}"
type: "aliyun_meta_ecs_info"
准备这2个文件放置到/usr/local/prometheus/prometheus/rules文件夹里面,确保prometheus的主配置文件有如下部分:
rule_files:
- "rules/*rules.yml"
# - "second_rules.yml"
重启prometheus服务, 可以在web界面看到对应的规则。
可以直接在表达式浏览器中输入我们定义好的记录规则表达式了,如下。
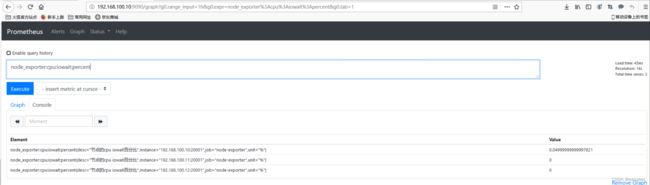
网上对prometheus的规则相对较少, 这里提供一个地址,可以参考参考: Awesome Prometheus alerts | Collection of alerting rules
7、Prometheus和AlertManager的高可用
前面的系列中, prometheus和alertmanager都是单机部署的,会有单机宕机导致系统不可用情况发生。本文主要介绍下prometheus和alertmanager的高可用方案。
服务的高可靠性架构(基本ha)。
promehtues是以pull方式进行设计的,因此手机时序资料都是通过prometheus本身主动发起的,而为了保证prometheus服务能够正常运行,只需要创建多个prometheus节点来收集同样的metrics即可。
架构图:

这个架构可以保证服务的高可靠性,但是并不能解决多个prometheus实例之间的资料一致性问题,也无法数据进行长期存储,且单一实例无法负荷的时候,将延伸出性能瓶颈问题,因此这种架构适合小规模进行监控。
优点:
- 服务能够提供基本的可靠性
- 适合小规模监控,只需要短期存储。
缺点:
- 无法扩展
- 数据有不一致问题
- 无法长时间保持
- 当承载量过大时,单一prometheus无法负荷。
服务高可靠性结合远端存储(基本ha + remote storage)。
这种架构是在基本ha的基础上面,加入远端存储的,将数据存储在第三方的存储系统中。
该架构解决了数据持久性问题, 当prometheus server发生故障、重启的时候可以快速恢复数据,同时prometheus可以很好的进行迁移,但是这也只适合小规模的监测使用。
优点:
- 服务能够提供可靠性
- 适合小规模监测
- 数据能够持久化存储
- prometheus可以灵活迁移
- 能够得到数据还原
缺点:
- 不适合大规模监控
- 当承载量过大时,单一prometheus server无法负荷
服务高可靠性结合远端存储和联邦(基本ha + remote storage + federation)
这种架构主要是解决单一 prometheus server无法处理大量数据收集的问题,而且加强了prometheus的扩展性,通过将不同手机任务分割到不同的prometheus实力上去。
该架构通常有2种使用场景:
单一资料中心,但是有大量收集任务,这种场景行prometheus server 可能会发生性能上的瓶颈,主要是单一prometheus server 要承载大量资料书籍任务, 这个时候通过federation来将不同类型的任务分到不同的prometheus 子server 上, 再有上层完成资料聚合。
多资料中心, 在多资料中心下,这种架构也能够使用,当不同资料中心的exporter无法让最上层的prometheus 去拉取资料是, 就能通过federation来进行分层处理, 在每个资料中心建立一组收集该资料中心的prometheus server , 在由上层的prometheus 来进行抓取, 并且也能够依据每个收集任务的承载量来部署分级,但是需要确保上下层的prometheus server 是互通的。
优点:
- 服务能够提供可靠性
- 资料能够被持久性保持在第三方存储系统中
- promethues server 能够迁移
- 能够得到资料还原
- 能够依据不同任务进行层级划分
- 适合不同规模监控
- 能够很好的扩展
缺点:
- 部署架构负载
- 维护困难性增加
- 在kubernetes部署不易
8、调试过程中遇见的错误
问题1:
does not advertise the STARTTLS extension:解决方案:
smtp_require_tls: false即可。问题2:
email.loginAuth auth: 535 Error解决方案:
smtp_auth_password: 这个配置项设置为授权码,而不是QQ邮箱登陆,详细获取授权码参考地址: https://zhidao.baidu.com/question/878811848141402332.html问题3:
一切配置正确,就是发不出去。
解决方案:
查看是否使用了25端口,默认云厂商会禁用25端口, 可以向云厂商申请解封25端口,或者使用465端口。
问题4:
报警消息能发送,但是报警恢复消息收不到。
解决方案:
缺少 send_resolved: true 配置文件, 请确保对应email_config配置文件,有此属性。
十、Prometheus采集器编写
在前面已经写了官方的几个exporter的使用了。 在实际使用环境中,我们可能需要收集一些自定义的数据, 这个时候我们一般是需要自己编写采集器的。
1、快速入门编写一个入门的demo
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件, 运行起来, 会监听在8000端口,访问127.0.0.1:8000端口。
效果图:
其实一个导出器就已经写好了, 就是这么简单的,我们只需要在prometheus配置来采集对应的导出器就可以了。 不过我们的导出的数据都是没有实际意义了。
数据类型介绍:
Counter 累加类型, 只能上升,比如记录http请求的总数或者网络的收发包累计值。
Gauge: 仪表盘类型, 适合有上升有下降的, 一般网络流量,磁盘读写这些,会有波动和变化的采用这个数据类型。
Summary: 基于采样的,在服务端完成统计。我们在统计平均值的时候,可能以为某个值异常导致计算平均值不能准确反映实际值, 就需要特定的点位置。
Histogram: 基于采样的,在客户端完成统计。我们在统计平均值的时候,可能以为某个值异常导致计算平均值不能准确反映实际值, 就需要特定的点位置。
2、采集内存使用数据
编写采集类代码:
from prometheus_client.core import GaugeMetricFamily, REGISTRY
from prometheus_client import start_http_server
import psutil
class CustomMemoryUsaggeCollector():
def format_metric_name(self):
return 'custom_memory_'
def collect(self):
vm = psutil.virtual_memory()
#sub_metric_list = ["free", "available", "buffers", "cached", "used", "total"]
sub_metric_list = ["free", "available", "used", "total"]
for sub_metric in sub_metric_list:
gauge = GaugeMetricFamily(self.format_metric_name() + sub_metric, '')
gauge.add_metric(labels=[], value=getattr(vm, sub_metric))
yield gauge
if __name__ == "__main__":
collector = CustomMemoryUsaggeCollector()
REGISTRY.register(collector)
start_http_server(8001)
import time
while True:
time.sleep(1)
暴露数据情况:

3、部署代码和集成prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.readthedocs.io/en/latest/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图:
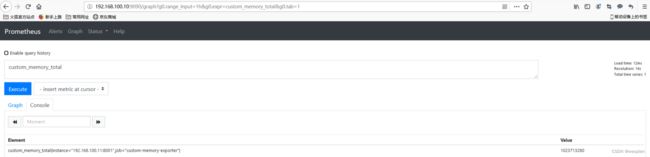
十一、Prometheus pushgateway使用
由于网络问题或者安全问题,可能我们的数据无法直接暴露出一个entrypoint 给prometheus采集。 这个时候可能就需要一个pushgateway来作为中间者完成中转工作。 prometheus还是采用pull方式来采集pushgateway的数据,我们的采集端通过push方式把数据push给pushgateway,来完成数据的上报。
1、pushgateway的安装
[root@node01 src]# wget https://github.com/prometheus/pushgateway/releases/download/v0.10.0/pushgateway-0.10.0.linux-amd64.tar.gz
[root@node01 src]# tar xf pushgateway-0.10.0.linux-amd64.tar.gz
[root@node01 src]# ll
total 8732
drwxr-xr-x. 2 root root 6 Nov 5 2016 debug
drwxr-xr-x. 2 root root 6 Nov 5 2016 kernels
drwxr-xr-x 2 3434 3434 54 Oct 10 19:29 pushgateway-0.10.0.linux-amd64
-rw-r--r-- 1 root root 8940709 Oct 10 19:30 pushgateway-0.10.0.linux-amd64.tar.gz
[root@node01 src]# mv pushgateway-0.10.0.linux-amd64 /usr/local/^C
[root@node01 src]# mkdir /usr/local/prometheus
[root@node01 src]# mv pushgateway-0.10.0.linux-amd64 /usr/local/prometheus/
[root@node01 src]# cd /usr/local/prometheus/
[root@node01 prometheus]# ls
pushgateway-0.10.0.linux-amd64
[root@node01 prometheus]# ln -s pushgateway-0.10.0.linux-amd64/ pushgateway
[root@node01 prometheus]# ll
total 0
lrwxrwxrwx 1 root root 31 Oct 11 04:00 pushgateway -> pushgateway-0.10.0.linux-amd64/
drwxr-xr-x 2 3434 3434 54 Oct 10 19:29 pushgateway-0.10.0.linux-amd64
2、pushgateway的配置
[root@node01 system]# cd /usr/lib/systemd/system
[root@node01 system]# vim pushgateway.service
[root@node01 system]# cat pushgateway.service
[Unit]
Description=prometheus
After=network.target
[Service]
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/prometheus/pushgateway
ExecStart=/usr/local/prometheus/pushgateway/pushgateway \
--web.enable-admin-api \
--persistence.file="pushfile.txt" \
--persistence.interval=10m
[Install]
WantedBy=multi-user.target
[root@node01 system]# systemctl enable pushgateway
Created symlink from /etc/systemd/system/multi-user.target.wants/pushgateway.service to /usr/lib/systemd/system/pushgateway.service.
[root@node01 system]# systemctl start pushgateway
[root@node01 system]# systemctl status pushgateway
注意: 上面的持久文件如果存储量大,需要考虑配置单独的磁盘来存储。
3、测试web页面

4、配置采集push端
1)添加一个数据,查看结果
[root@node02 ~]# !vim
vim push_memory.sh
#!/bin/bash
# desc push memory info
total_memory=$(free |awk '/Mem/{print $2}')
used_memory=$(free |awk '/Mem/{print $3}')
job_name="custom_memory"
instance_name="192.168.100.12"
cat <2)插入数据后效果图
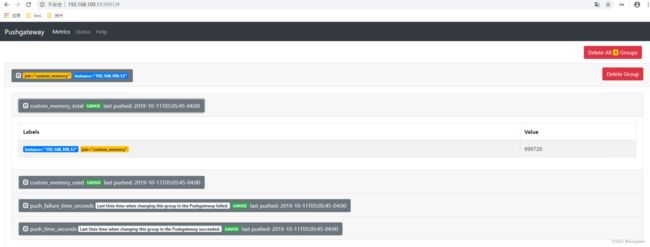
5、集成prometheus
1)添加pushgateway的采集
# 修改prometheus.yml 加入如下片段
- job_name: "custom-memory-pushgateway"
#honor_labels: true
static_configs:
- targets: ["192.168.100.11:9091"]
2)持续生成数据
上面执行的 push_memory.sh脚本也就是只是插入一次数据, 我们这里使用计划任务来周期push数据到pushgateway中。
[root@node02 ~]# crontab -e
no crontab for root - using an empty one
1 * * * * /root/push_memory.sh
[root@node02 ~]# chmod a+x push_memory.sh
3)效果图

可以发现instance和job标签有点问题, 这是pushgateway填充的, 我们可以加入honor配置使用我们自定义的。
4)修改配置如下
- job_name: "custom-memory-pushgateway"
honor_labels: true
static_configs:
- targets: ["192.168.100.11:9091"]
5)效果图

我们可以通过pushgateway来辅助采集。 此场景中,我们假定的192.168.100.10这个prometheus server服务器是到192.168.100.12网络是不通的, 但是192.168.100.11 这个ip地址是可以和2个ip是通的, 这里就可以在192.168.100.11 这个服务器上面部署pushgateway来作为桥梁, 采集到192.168.100.12的监控数据。
十二 、Prometheus安全
我们这里说的安全主要是基本认证和https2种, 目前这2种安全在prometheus中都没有的, 需要借助第三方软件实现, 这里以nginx为例。
1、配置基本认证
在前面的部署中,我们部署完毕prometheus server 后, 可以通过对应的http://192.168.100.10:9090就可以访问到我们的 表达式浏览器, 进行promql的查询了。 这是很不安全, 必要情况下,我们需要加入基本认证, 只有认证过的用户才能访问页面,进行数据的查询。
[root@node00 ~]# yum install httpd-tools nginx
[root@node00 ~]# cd /etc/nginx
[root@node00 nginx]# htpasswd -c /etc/nginx/.htpasswd admin
[root@node00 conf.d]# cat prometheus.linuxpanda.tech.conf
server {
listen 80;
server_name prometheus.linuxpanda.tech ;
location / {
auth_basic "Prometheus";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://localhost:9090/;
}
}
[root@node00 conf.d]# pwd
/etc/nginx/conf.d
[root@node00 conf.d]# cat prometheus.linuxpanda.tech.conf
server {
listen 80;
server_name prometheus.linuxpanda.tech ;
location / {
auth_basic "Prometheus";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://localhost:9090/;
}
}
[root@node00 conf.d]# systemctl restart nginx
[root@node00 conf.d]# systemctl status nginx
[root@node00 system]# pwd
/usr/lib/systemd/system
[root@node00 system]# cat prometheus.service
[Unit]
Description=prometheus
After=network.target
[Service]
User=prometheus
Group=prometheus
WorkingDirectory=/usr/local/prometheus/prometheus
ExecStart=/usr/local/prometheus/prometheus/prometheus --web.external-url=http://prometheus.linuxpanda.tech
[Install]
WantedBy=multi-user.target
[root@node00 system]# systemctl daemon-reload
[root@node00 system]# sytemctl restart prometheus
-bash: sytemctl: command not found
[root@node00 system]# systemctl restart prometheus
[root@node00 system]# systemctl status prometheus
测试:
1)配置域名解析
由于我们使用的是prometheus.linuxpanda.tech 这个域名, 我们需要确保这个域名能正常解析到对应的ip地址上面, 这里使用host绑定方式。
# 在我宿主机的hosts文件中加入如下行
192.168.100.10 prometheus.linuxpanda.tech
2)登陆
在浏览器输入prometheus.linuxpanda.tech 这个域名后, 效果图如下:
输入我们前面设置的账户和密码 admin/admin 登陆后,效果如下:
2、https
配置https是需要证书的, 正式环境中的域名是需要花钱的,我们这里使用openssl这个软件来生成一个自签证书测试使用。
[root@node00 nginx]# cd /etc/nginx/
[root@node00 nginx]# mkdir ssl
[root@node00 nginx]# cd ssl/
[root@node00 ssl]# openssl req -x509 -newkey rsa:4096 -nodes -keyout prometheus.linuxpanda.tech.key -out prometheus.linuxpanda.tech.crt
Generating a 4096 bit RSA private key
.............................................................++
...................................................................................................................................................++
writing new private key to 'prometheus.linuxpanda.tech.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:Bei
Locality Name (eg, city) [Default City]:^C
[root@node00 ssl]# openssl req -x509 -newkey rsa:4096 -nodes -keyout prometheus.linuxpanda.tech.key -out prometheus.linuxpanda.tech.crt
Generating a 4096 bit RSA private key
..............................................................................................................................................................++
...............................................................++
writing new private key to 'prometheus.linuxpanda.tech.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:BEIJING
Locality Name (eg, city) [Default City]:BEIJING
Organization Name (eg, company) [Default Company Ltd]:
Organizational Unit Name (eg, section) []:
Common Name (eg, your name or your server's hostname) []:prometheus.linuxpanda.tech
Email Address []:
[root@node00 conf.d]# pwd
/etc/nginx/conf.d
[root@node00 conf.d]# cat prometheus.linuxpanda.tech.conf
server {
listen 80;
listen 443 ssl;
server_name prometheus.linuxpanda.tech ;
ssl_certificate ssl/prometheus.linuxpanda.tech.crt;
ssl_certificate_key ssl/prometheus.linuxpanda.tech.key;
location / {
auth_basic "Prometheus";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://localhost:9090/;
}
}
[root@node00 conf.d]# systemctl restart nginx
[root@node00 conf.d]# systemctl status nginx
测试:
在浏览器输入https://prometheus.linuxpanda.tech 这个域名后,也是会提示不安全的, 那是因为我们使用的是openssl自签证书,忽略证书信息,继续访问,可以访问到如下页面。

十三、Prometheus企业级实战
网络拓扑:
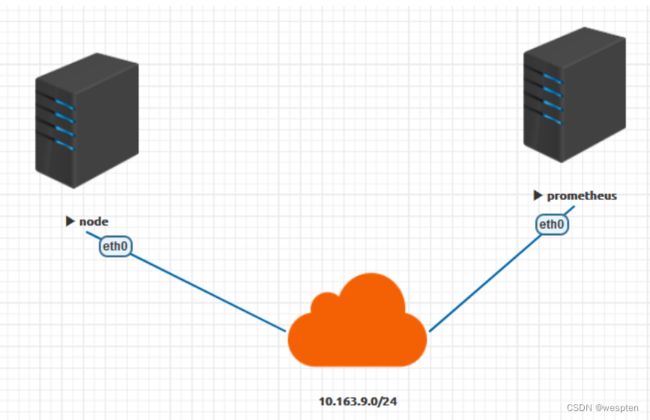
1、prometheus安装
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的 二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
解压后当前目录会包含默认的Prometheus配置文件promethes.yml.
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为 data/.用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径。
软件包下载链接如下:Download | Prometheus
使用版本:
prometheus-2.20.1.linux-amd64.tar.gz
node_exporter-1.0.1.linux-amd64.tar.gz
alertmanager-0.21.0.linux-amd64.tar.gz
prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz[root@localhost ~]# hostnamectl set-hostname prometheus
[root@prometheus ~]# sed -i "s/SELINUX=enforcing/SELINUX=permissive/" /etc/selinux/config [root@prometheus ~]# setenforce 0
[root@prometheus ~]# systemctl disable firewalld --now在prometheus节点上安装promethes:
[root@prometheus bin]# pwd
/usr/local/bin
[root@prometheus bin]# ls
prometheus-2.20.1.linux-amd64.tar.gz
[root@prometheus bin]# tar xf prometheus-2.20.1.linux-amd64.tar.gz
[root@prometheus bin]# mv prometheus-2.20.1.linux-amd64 prometheus
[root@prometheus bin]# cd prometheus
[root@prometheus prometheus]# ./prometheus --help
[root@prometheus prometheus]# ./prometheus --version
prometheus, version 2.20.1 (branch: HEAD, revision: 983ebb4a513302315a8117932ab832815f85e3d2)
build user: root@7cbd4d1c15e0
build date: 20200805-17:26:58
go version: go1.14.6
#使用默认的配置文件运行prometheus
[root@prometheus prometheus]# ./prometheus --config.file=prometheus.yml &
[root@prometheus prometheus]# netstat -tunlp | grep :9090
tcp6 0 0 :::9090 :::* LISTEN
1210/./prometheus
alert界面:
状态界面:
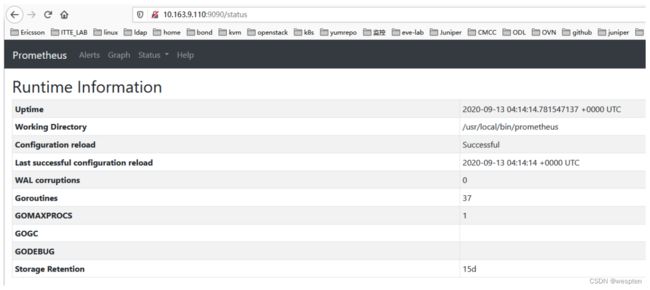
参数界面:
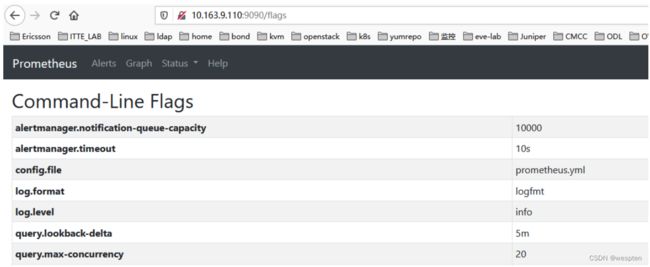
配置界面:
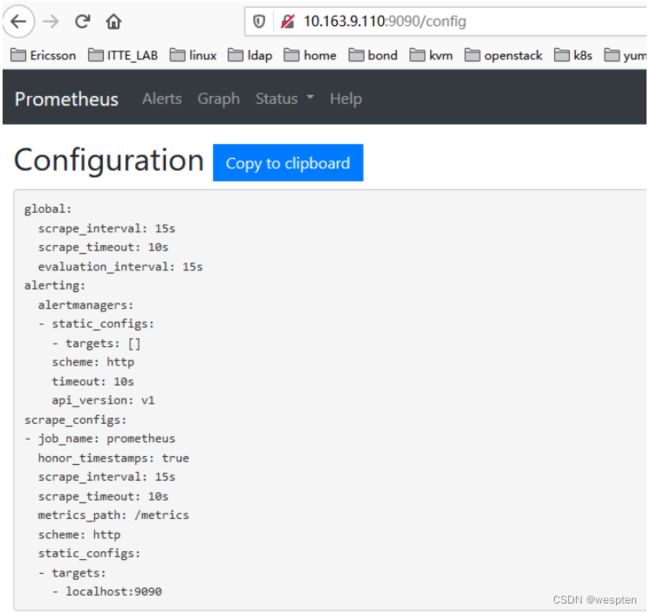
规则界面:

节点界面:

服务发现界面:

获取在线帮助:

将prometheus配置成systemd接管的服务:
[root@prometheus prometheus]# cat /etc/systemd/system/prometheus.service
[Unit]
Description=prometheus service
[Service]
ExecStart=/usr/local/bin/prometheus/prometheus -- config.file=/usr/local/bin/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target
[root@prometheus prometheus]# systemctl daemon-reload
[root@prometheus prometheus]# pkill prometheus
[root@prometheus prometheus]# systemctl enable prometheus --now
[root@prometheus prometheus]# systemctl status prometheus.service
● prometheus.service - node exporter Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2020-09-13 12:34:36 CST; 3s ago Main PID: 1386 (prometheus)
Tasks: 6 (limit: 6084)
Memory: 49.6M
CGroup: /system.slice/prometheus.service
─1386 /usr/local/bin/prometheus/prometheus --
config.file=/usr/local/bin/prometheus/prometheus.yml2、在被监控节点安装node_exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据 的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需 要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监 控样本数据。
从上面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目 标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以 从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
node_exporter安装:
[root@localhost ~]# hostnamectl set-hostname node
[root@node ~]# sed -i "s/SELINUX=enforcing/SELINUX=permissive/" /etc/selinux/config [root@node ~]# setenforce 0
[root@node ~]# systemctl disable firewalld --now
[root@node bin]# pwd /usr/local/bin
[root@node bin]# tar xf node_exporter-1.0.1.linux-amd64.tar.gz
[root@node bin]# mv node_exporter-1.0.1.linux-amd64 node_exporter
[root@node bin]# cd node_exporter/
[root@node node_exporter]# ./node_exporter --help
[root@node node_exporter]# ./node_exporter &
[root@node node_exporter]# netstat -tunlp | grep :9100
tcp6 0 0 :::9100 :::* LISTEN
1041/./node_exporte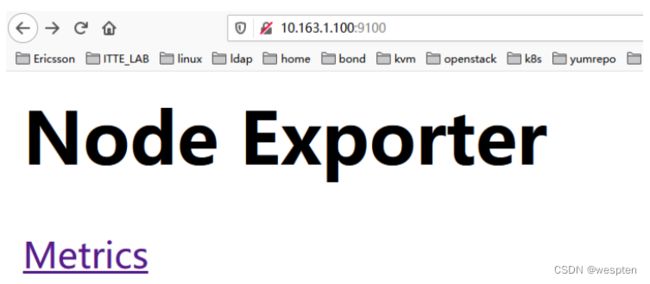

将node_exporter配置成systemd接管的服务:
[root@node node_exporter]# cat /etc/systemd/system/node_exporter.service
[Unit]
Description=node exporter
[Service]
ExecStart=/usr/local/bin/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target
[root@node node_exporter]# pkill node_exporter
[root@node node_exporter]# systemctl daemon-reload
[root@node node_exporter]# systemctl enable node_exporter.service --now
[root@node node_exporter]# systemctl status node_exporter.service
● node_exporter.service - node exporter
Loaded: loaded (/etc/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2020-09-13 13:58:16 CST; 21s ago
Main PID: 1472 (node_exporter)
Tasks: 3 (limit: 6084)
Memory: 4.4M
CGroup: /system.slice/node_exporter.service
└─1472 /usr/local/bin/node_exporter/node_exporter
[root@node node_exporter]# netstat -tunlp | grep :9100
tcp6 0 0 :::9100 :::* LISTEN
1472/node_exporter关联prometheus和node_exporter:
1. 修改配置文件
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- targets: ['10.163.9.111:9100'] 重启服务:
[root@prometheus prometheus]# systemctl restart prometheus.service
在prometheus的图形界面查看监控项:
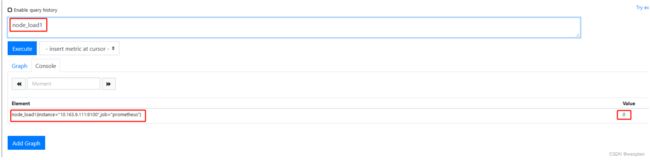

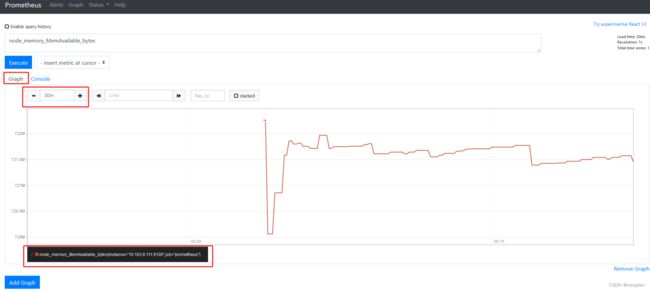
3、数据库节点安装mysqld_exporter
1. 关闭selinux和防火墙
sed -i "s/SELINUX=enforcing/SELINUX=permissive/" /etc/selinux/config
setenforce 0
systemctl disable firewalld --now2. mysqld_exporter安装
tar xf mysqld_exporter-0.12.1.linux-amd64.tar.gz
mv mysqld_exporter-0.12.1.linux-amd64 mysqld_exporter
cd mysqld_exporter/
mysql -uroot -p123456
MariaDB [(none)]> grant all privileges on *.* to prometheus@'%' identified by 'prometheus'; MariaDB [(none)]> flush privileges;
MariaDB [(none)]> exit
mysql -uprometheus -pprometheus
MariaDB [(none)]> exit
cat > .my.cnf <3. systemd接管mysqld_exporter服务
cat /etc/systemd/system/mysqld_exporter.service
[Unit]
Description=mysqld exporter
[Service]
ExecStart=/usr/local/bin/mysqld_exporter/mysqld_exporter
[Install]
WantedBy=multi-user.target
pkill mysqld_exporter
systemctl daemon-reload
systemctl enable mysqld_exporter.service --now
systemctl status mysqld_exporter.service
netstat -tunlp | grep :9104
tcp6 0 0 :::9104 :::* LISTEN
1603/./mysqld_expor4、alertmanager安装与配置
1. 关闭selinux和防火墙
sed -i "s/SELINUX=enforcing/SELINUX=permissive/" /etc/selinux/config
setenforce 0
systemctl disable firewalld --now2. alertmanager安装
[root@prometheus bin]# pwd
/usr/local/bin
[root@prometheus bin]# tar xf alertmanager-0.21.0.linux-amd64.tar.gz
[root@prometheus bin]# mv alertmanager-0.21.0.linux-amd64 alertmanager
[root@prometheus bin]# cd alertmanager/
[root@prometheus alertmanager]# ./alertmanager &
[root@prometheus alertmanager]# netstat -tunlp | grep alertmanager
tcp6 0 0 :::9093 :::* LISTEN 756/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 756/alertmanager
udp6 0 0 :::9094 :::* 756/alertmanager3. 访问alertmanager图形界面
告警界面:
状态界面:
4. systemd接管alertmanager服务
[root@prometheus alertmanager]# cat /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
[Service]
ExecStart=/usr/local/bin/alertmanager/alertmanager -- config.file=/usr/local/bin/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
[root@prometheus alertmanager]# pkill alertmanager
[root@prometheus alertmanager]# systemctl enable alertmanager --now
[root@prometheus alertmanager]# netstat -tunlp | grep alertmanager
tcp6 0 0 :::9093 :::* LISTEN 1876/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 1876/alertmanager
udp6 0 0 :::9094 :::* 1876/alertmanager5. 配置prometheus关联alertmanager
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- targets: ['10.163.9.111:9100']
[root@prometheus prometheus]# systemctl restart prometheus.service 6. 配置报警规则
配置报警规则文件:
[root@prometheus prometheus]# mkdir rules
[root@prometheus prometheus]# cat rules/node.yml
groups:
- name: test
rules:
- alert: 内存使用率过高
expr: (1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)*100 > 50
for: 1m # 告警持续时间,超过这个时间才会发送给alertmanager
labels: s
everity: warning
annotations:
summary: "Instance {{ $labels.instance }} 内存使用率过高"
description: "{{ $labels.instance }} of job {{$labels.job}}内存使用率超过 50%,当前使用率[{{ $value }}]."
- alert: cpu1分钟负载过高
expr: node_load1 > 0.8
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} cpu1分钟负载过高,超过0.8"
description: "{{ $labels.instance }} of job {{$labels.job}}cpu1分钟负载过 高,超过0.8,当前负载[{{ $value }}]."配置prometheus关联报警规则文件:
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- 'rules/*.yml'
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- targets: ['10.163.9.111:9100']
[root@prometheus prometheus]# systemctl restart prometheus.service 在web界面查看报警规则:

触发告警:
[root@node ~]# dd if=/dev/zero of=/dev/null bs=400M &
Alert的三种状态:
1. pending:警报被激活,但是低于配置的持续时间。这里的持续时间即rule里的FOR字段设置的时间。该 状态下不发送报警。
2. firing:警报已被激活,而且超出设置的持续时间。该状态下发送报警。
3. inactive:既不是pending也不是firing的时候状态变为inactive
prometheus触发一条告警的过程:
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--- >邮件|钉钉|微信等。
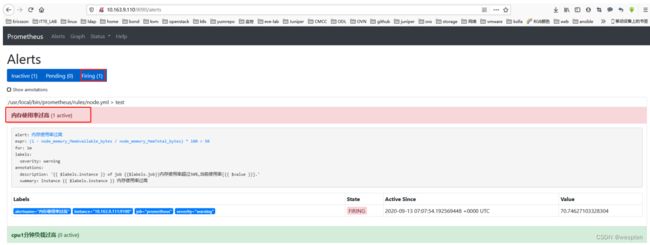
在alertmanager上查看告警:
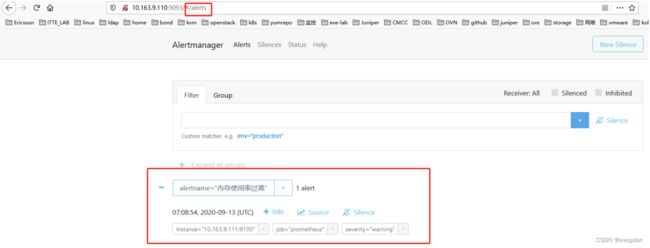
过一会儿观察:

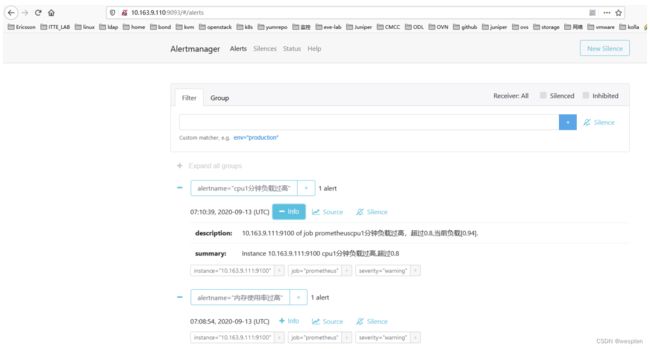
[root@node ~]# pkill dd
[root@node ~]#
[1]+ Terminated dd if=/dev/zero of=/dev/null bs=400M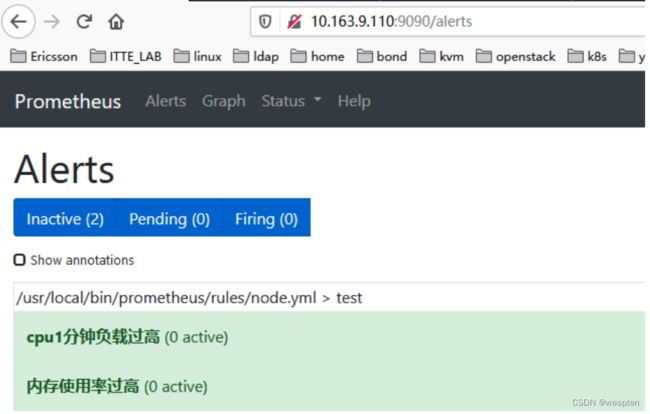

5、配置邮件告警
配置alertmanager配置文件:
[root@prometheus alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'ZOXAXUXBWEKNCUUJ'
route:
group_by: ['alertname']
group_wait: 1s
group_interval: 1s
repeat_interval: 10s
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '[email protected]'
# webhook_configs:
# - url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']重启alertmanager服务:
[root@prometheus alertmanager]# systemctl restart alertmanager拉起负载告警测试:
[root@node ~]# dd if=/dev/zero of=/dev/null bs=400M &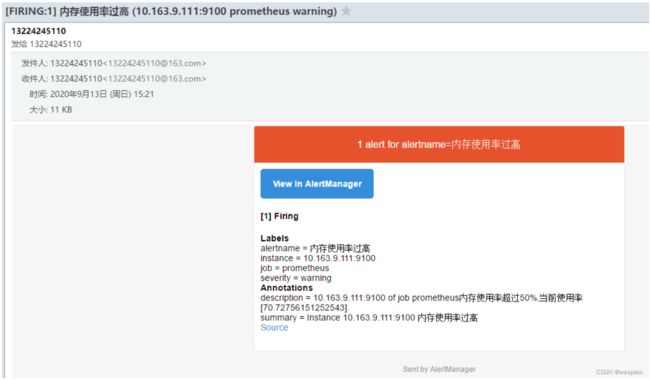
[root@node ~]# pkill dd
[root@node ~]#
[1]+ Terminated dd if=/dev/zero of=/dev/null bs=400M6、配置微信告警
配置微信报警模板:
[root@prometheus alertmanager]# cat /tmp/wechat.tmpl
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
========监控报警==========
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
告警应用:{{ $alert.Annotations.summary }}
告警主机:{{ $alert.Labels.instance }}
告警详情:{{ $alert.Annotations.description }}
触发阀值:{{ $alert.Annotations.value }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
========end=============
{{ end }}
{{ end }}修改alertmanager配置文件:
[root@prometheus alertmanager]# cat alertmanager.yml
global:
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 请勿修改
wechat_api_corp_id: 'ww49a6a056f0bc439e' # 企业ID
templates:
- '/tmp/wechat.tmpl' # wechat.tmpl 消息模板的位置
route:
receiver: "wechat" # 和下面 receivers.name 一致
group_by: ['alertname']
group_wait: 30s
group_interval: 3m
repeat_interval: 3m
routes:
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true # 是否发生 resolved 消息
to_user: '@all' # 所有用户
message: '{{ template "wechat.default.message" . }}' # 使用消息模板
agent_id: '1000002' # 应用的 AgentId
api_secret: '-mpRrgww3yFzyVec-zjPtCMsaEsisZGYP1CzgS2uD9o' # 应用的 Secret重启服务:
[root@prometheus alertmanager]# systemctl restart alertmanager拉起负载查看告警:
[root@node ~]# dd if=/dev/zero of=/dev/null bs=400M &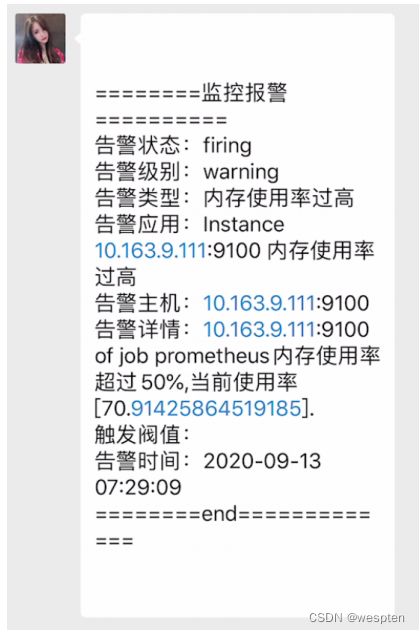

关闭负载:
[root@node ~]# pkill dd
[root@node ~]#
[1]+ Terminated dd if=/dev/zero of=/dev/null bs=400M

7、配置钉钉告警
1. 安装钉钉告警消息发送代理软件
[root@prometheus bin]# wget https://github.com/timonwong/prometheus-webhook- dingtalk/releases/download/v0.3.0/prometheus-webhook-dingtalk-0.3.0.linux- amd64.tar.gz [root@prometheus bin]# tar xf prometheus-webhook-dingtalk-0.3.0.linux- amd64.tar.gz [root@prometheus bin]# mv prometheus-webhook-dingtalk-0.3.0.linux-amd64 prometheus-webhook2. systemd服务接管
[root@prometheus prometheus-webhook]# cat /etc/systemd/system/dingtalk.service
[Unit]
Description=dingtalk
[Service]
ExecStart=/usr/local/bin/prometheus-webhook/prometheus-webhook-dingtalk -- ding.profile="webhook1=https://oapi.dingtalk.com/robot/send? access_token=6ecb8ada7de105c5eefda3b5f433c7e0f2b10036e3f93ae14a50d3b5e77db6da"
[Install]
WantedBy=multi-user.target
[root@prometheus prometheus-webhook]# systemctl daemon-reload
[root@prometheus prometheus-webhook]# systemctl enable dingtalk.service --now [root@prometheus prometheus-webhook]# netstat -tunlp | grep :8060
tcp6 0 0 :::8060 :::*
LISTEN 2591/prometheus-web[root@prometheus alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
route:
receiver: webhook
group_wait: 10s
group_interval: 10s
repeat_interval: 10s
group_by: [alertname]
routes:
- receiver: webhook
group_wait: 10s
receivers:
- name: webhook
webhook_configs:
- url: http://localhost:8060/dingtalk/webhook1/send
send_resolved: true
[root@prometheus alertmanager]# systemctl restart alertmanager.service
[root@prometheus alertmanager]# netstat -tunlp | grep alertmanager
tcp6 0 0 :::9093 :::*
LISTEN 2665/alertmanager
tcp6 0 0 :::9094 :::*
LISTEN 2665/alertmanager
udp6 0 0 :::9094 :::*
2665/alertmanager4. 拉起负载
[root@node ~]# dd if=/dev/zero of=/dev/null bs=400M &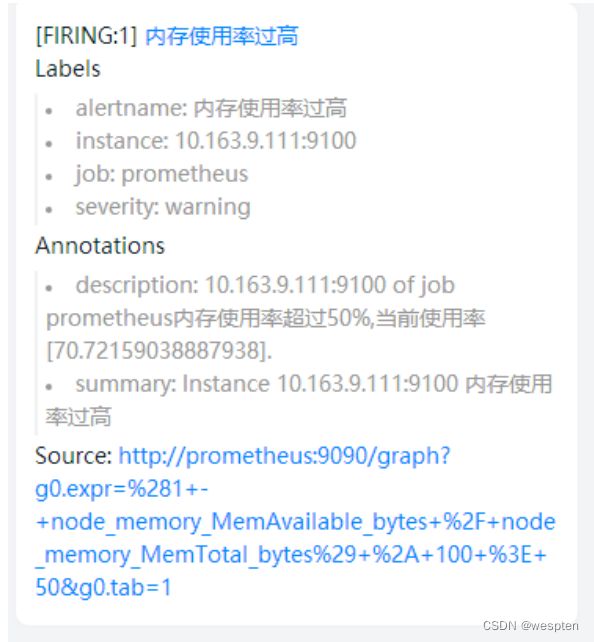

5. 关闭负载
[root@node ~]# pkill dd
[root@node ~]#
[1]+ Terminated dd if=/dev/zero of=/dev/null bs=400M

8、prometheus+grafana
下载软件包并安装:
[root@prometheus ~]# wget https://dl.grafana.com/oss/release/grafana-7.1.5- 1.x86_64.rpm [root@prometheus ~]# ls anaconda-ks.cfg grafana-7.1.5-1.x86_64.rpm
[root@prometheus ~]# yum install grafana-7.1.5-1.x86_64.rpm -y
[root@prometheus ~]# systemctl enable grafana-server --now进入grafana的web界面:

缺省的用户名和密码都是admin。

添加prometheus数据源:
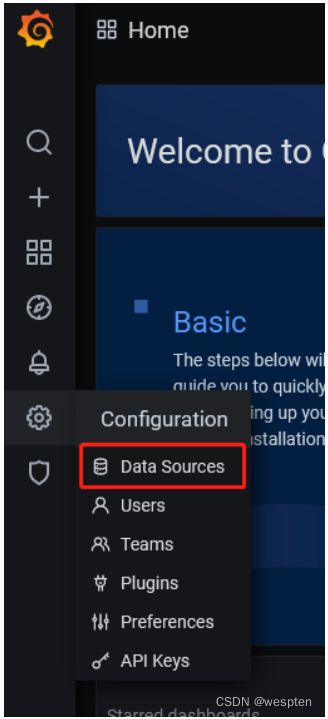


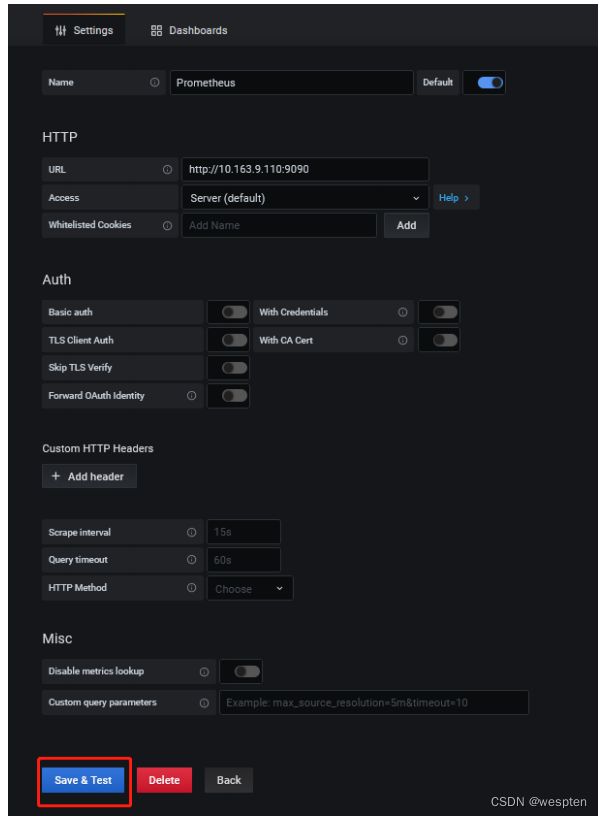

在dashboard界面添加图形:
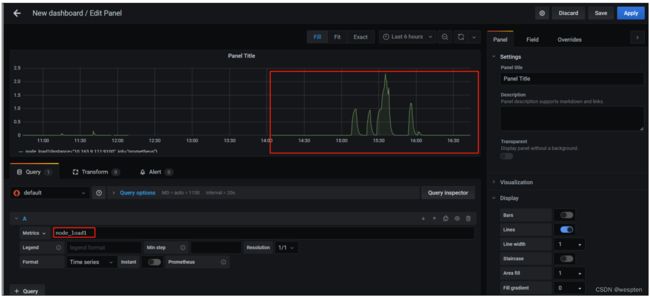



9、使用grafana官网别人共享的图形模板
Dashboards | Grafana Labs

2. 创建新的图形使用下载的模板