Mixture Density Network:拟合多值函数
参考:当神经网络撞上薛定谔:混合密度网络入门 - 代码律动的文章 - 知乎,本文中的图片也来自这篇知乎文章,版权归原作者所有。
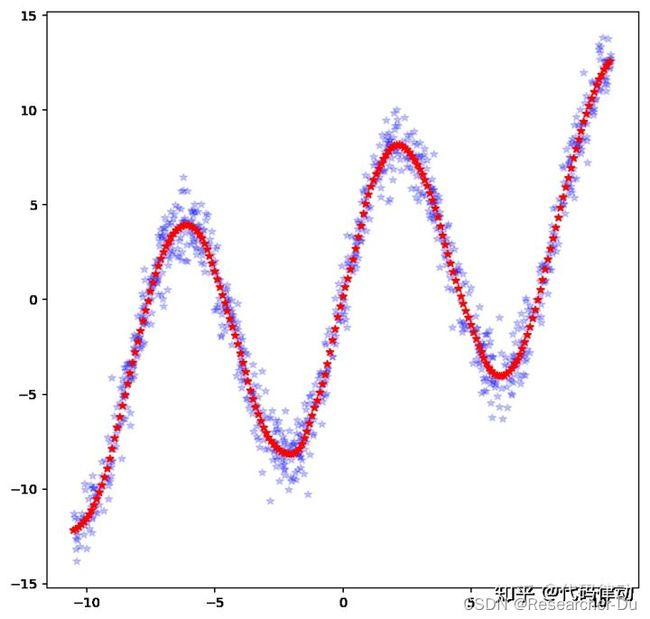
一般可通过神经网络来拟合任意的函数,为了进行简单的测试,作者通过: y = 7.0 ∗ s i n ( 0.75 x ) + 0.5 x + G a u s s i a n n o i s e y=7.0*sin(0.75x)+0.5x+ Gaussian \ noise y=7.0∗sin(0.75x)+0.5x+Gaussian noise 得到如下所示的蓝色数据点。那么就可以使用简单的神经网络对这些数据进行拟合,假设拟合的函数是 F ( x ) F(x) F(x),训练好后,就可以对任意 x x x的函数值进行预测,红色点的高度就是每个 x x x对应的函数值。
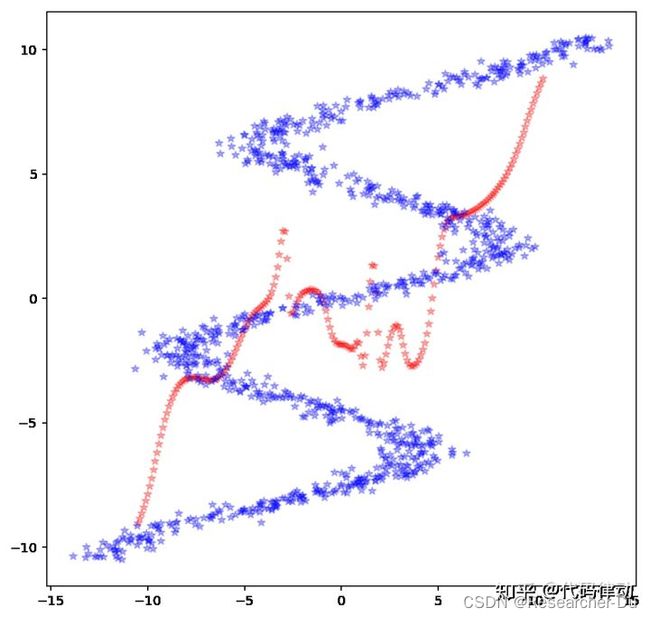
如果这些蓝色数据点以 y = x y=x y=x 进行镜面对称的话,那么我们得到的数据无法再通过刚才的方法进行拟合,因为它本质上不是函数。如果非要拟合,将得到如下误差非常大的效果:
为此 Mixture Density Network 应运而生,它不是直接预测函数值,实际上也不好操作,因为对于具体的每个 x x x,它有几个函数值是不确定的。因此, Mixture Density Network直接预测函数值对应的分布。假设 x x x对应的多个函数值服从混合高斯分布,假设该混合高斯模型由 n n n个高斯模型构成,那么,神经网络的输出就是: n n n个权重: { w 1 , w 2 , w 3 , . . . w n } \{w_1,w_2,w_3,...w_n\} {w1,w2,w3,...wn}, n n n个均值: { μ 1 , μ 2 , μ 3 , . . . μ n } \{\mu_1, \mu_2,\mu_3,...\mu_n\} {μ1,μ2,μ3,...μn}, n n n个方差: { σ 1 , σ 2 , σ 3 , . . . σ n } \{\sigma_1, \sigma_2, \sigma_3,...\sigma_n\} {σ1,σ2,σ3,...σn}. 混合高斯模型可以简单的表示为:
∑ i n w i 1 ( 2 π ) σ i e − x − μ i 2 σ i 2 \sum^n_iw_i\frac{1}{\sqrt(2\pi)\sigma_i}e^{-\frac{x-\mu_i}{2\sigma^2_i}} i∑nwi(2π)σi1e−2σi2x−μi
有了这个高斯分布,就可以通过在这个分布上采样得到多个函数值。
为此,可以在训练集上训练一个模型表示函数值服从的高斯混合分布。在对数据进行测试的时候,对于每一个数据 x x x 均可预测出 n n n个权重: { w 1 , w 2 , w 3 , . . . w n } \{w_1,w_2,w_3,...w_n\} {w1,w2,w3,...wn}, n n n个均值: { μ 1 , μ 2 , μ 3 , . . . μ n } \{\mu_1, \mu_2,\mu_3,...\mu_n\} {μ1,μ2,μ3,...μn}, n n n个方差: { σ 1 , σ 2 , σ 3 , . . . σ n } \{\sigma_1, \sigma_2, \sigma_3,...\sigma_n\} {σ1,σ2,σ3,...σn},那么就可以在这个混合高斯分布上采样多个点作为 x x x 对应的多个函数值 y y y。 这里在 x ∈ [ − 15 , 15 ] x\in[-15,15] x∈[−15,15]区间内,以0.1为步长,对每个 x x x都随机采样10个 y y y 值, 也就是每个 x x x对应10个 y y y值,把所有这些 ( x , y ) 点画到图上(红色的点) (x,y)点画到图上(红色的点) (x,y)点画到图上(红色的点),就以得到如下的图像。可以看到,这些红色的点很好的拟合了蓝色数据点的分布。
