Text to image论文精读 StackGAN:Text to Photo-realistic Image Synthesis with Stacked GAN具有堆叠生成对抗网络文本到图像合成
StackGAN:Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
- 一、摘要
- 二、关键词
- 三、GAN-CLS和GAN-INT的局限性
- 四、主要内容
- 4.1、条件反射增强(Conditioning Augmentation)
- 4.2、StackGAN的两层结构
-
-
- 4.2.1、Stage-I GAN
- 4.2.2、Stage-II GAN
-
- 4.3、实验
-
- 4.3.1、数据集
- 4.3.2、评价指标
- 4.3.3、实验结果
- 4.4.3 消融实验
- 5、总结与体会
- 相关阅读
本篇文章提出了叠加生成对抗网络(StackGAN)与条件增强,用于从文本合成现实图像,被2017年ICCV(International Conference on Computer Vision)会议录取。
论文地址: https://arxiv.org/pdf/1612.03242.pdf
代码地址: https://github.com/hanzhanggit/StackGAN
本篇是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、摘要
从文本描述中合成高质量的图像是计算机视觉中一个具有挑战性的问题,具有许多实际应用。现有的文本到图像方法生成的样本可以大致反映给定描述的含义,但它们无法包含必要的细节和生动的对象部分。在本文中,我们提出了堆叠生成对抗网络(StackGAN)来生成基于文本描述的256×256照片真实感图像。我们通过草图细化过程将困难问题分解为更易于管理的子问题。Stage-I GAN根据给定的文本描述绘制对象的基本形状和颜色,生成Stage-I低分辨率图像。Stage-II AN将第一阶段的结果和文本描述作为输入,并生成具有照片真实细节的高分辨率图像。它能够纠正第一阶段结果中的缺陷,并通过细化过程添加引人注目的细节。为了提高合成图像的多样性并稳定条件GAN的训练,我们引入了一种新的条件增强技术,该技术鼓励潜在条件流形中的平滑性。在基准数据集上进行的大量实验和与现有技术的比较表明,该方法在生成基于文本描述的照片真实感图像方面取得了显著的改进。
二、关键词
Deep Learning, Generative Adversarial Network, Image Synthesis, Computer Vision
三、GAN-CLS和GAN-INT的局限性
GAN-CLS和GAN-INT 论文精读与理解
Reed等人仅成功生成了基于文本描述的合理的64×64图像,通常缺乏细节和生动的对象部分,此外,他们无法合成更高分辨率(例如128×128)的图像,而不提供额外的对象注释。GANs生成高分辨率图像的主要困难在于自然图像分布和隐含模型分布的支持在高维像素空间中可能不会重叠(大概理解就是高维空间无法找到一个常用的公式/分布来表示自然图像),随着图像分辨率的增加,此问题更加严重。
四、主要内容
4.1、条件反射增强(Conditioning Augmentation)
在之前GAN-CLS和GAN-INT中,文字描述t会被编码器生成一个text embedding φ但是这个φ 的维度一般很高(>100),而训练数据是有限的,所以会造成特征空间不连续(discontinuity in the latent data manifold),这不适合作为GAN中生成器的输入。
为了缓解这个问题,作者引入了条件增强技术(Conditioning Augmentation),stackGAN 没有直接将text_embedding 作为条件变量输入,而是产生一个额外的条件变量c,c是从独立的高斯分布N(μ(φ_t ),∑(φ_t ))中随机采样得到隐含变量,再放入生成器。其中μ(φ_t )和∑(φ_t )是关于φ_t的的均值和方差函数。

4.2、StackGAN的两层结构

已知conditionalGAN的损失函数:
![]() 其中c表示条件变量,可以控制G生成符合条件c的图像。
其中c表示条件变量,可以控制G生成符合条件c的图像。
4.2.1、Stage-I GAN
Stage-I GAN: 它根据给定的文本描述绘制对象的基本形状和基本颜色,并根据随机噪声向量绘制背景布局,生成低分辨率图像。其损失函数和conditionalGAN相似,其中I_0表示真实图像;t表示文字描述;z表示噪声,从正态分布p_z中取样;φ_t表示 text_embedding,是t通过char-CNN-RNN后生成的;λ一般取1。损失函数如下:

模型结构:首先为了得到c^,将φ_t传入一个全连接层得到其均值µ和方差σ,即可得到一个正态分布N(μ(φ_t ),σ(φ_t )),c^就是从这个正态分布取样得到的值,传入G中。λD_KL (N(μ(φ_t ),∑(φ_t ))||N(0,I))用于正则化。而后加入噪声z,传入G中,此时G就能生成图像了。对于D,text_embeddingφ_t首先被压缩为Nd维,同时,图像经过一系列下采样块,直到具有md×md的空间维度。然后,图像滤波器映射沿通道维度与文本张量连接。所得到的张量进一步馈送到1×1卷积层,以共同学习图像和文本中的特征。最后,使用一个具有一个节点的完全连接层来生成决策得分。
4.2.2、Stage-II GAN
Stage-II GAN: 第一阶段GAN生成的低分辨率图像通常缺少生动的对象部分,并且可能包含形状扭曲。文本中的一些细节在第一阶段也可能被省略。Stage-II GAN纠正第一阶段低分辨率图像中的缺陷,并通过再次读取文本描述完成对象的细节,生成高分辨率照片真实感图像。与通常的GAN不同,本阶段不使用随机噪声z。
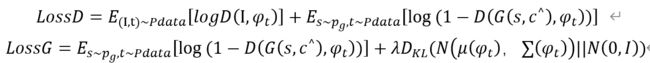
模型结构:我们将第二阶段生成器设计为一个具有残差块的编解码网络,与第一阶段一样,首先用text_embedding生成c^。同时,由第一阶段GAN生成的结果s传入几个下采样块(即编码器),直到达到一定维度。然后将编码后的图像特征与文本特征沿通道标注连接,传入若干用于学习图像和文本特征的多模态表示的残差块,最后,使用一系列上采样层(即解码器)生成高分辨率图像。这种生成器能够帮助纠正输入图像中的缺陷,同时添加更多细节以生成逼真的高分辨率图像。对于鉴别器,其结构类似于第一阶段鉴别器,仅具有额外的下采样块。另外,为了明确地强制GAN更好地学习图像和条件文本之间的对齐,我们在两个阶段都采用了匹配感知鉴别器。
4.3、实验
4.3.1、数据集
CUB包含200种鸟类和11788张图,不过80%的图像中鸟的大小占图像的比例小于50%,故进行了裁剪调整让其大于75%,,每个图像有对应10个文本描述。
Oxford-102包含来自102个不同类别的8189幅花卉图像,每个图像有对应10个文本描述。
MS COCO数据集包含具有多个对象和各种背景的图像。它有一个包含80k图像的训练集和一个包含40k图像的验证集。COCO中的每个图像有5个描述。
4.3.2、评价指标
inception score(IS):I=exp(E_x D_KL (p(y|x)||p(y)),其中x表示一个生成的样本,y是预测的标签,p(y)表示边际分布,可以代表图像的多样性,我们希望p(y)分布均匀,即最好p(y1=p(y2)=…=1/n,从熵的角度来说希望p(y)的熵越大越好;p(y|x)表示条件分布,可以代表图像的质量,我们希望条件概率p(y|x) 可以被高度预测(x表示给定的图片,y表示这个图片包含的主要物体),也就是希望它的熵值较低,简单来说,假如inception network能够以较高的概率预测图片中包含的物体,也就是有很高的把握对其进行正确分类,这就说明图片质量较高,即p(y|x)的值越高,表示熵越低,图片质量越高,故希望p(y|x)的熵越小越好。p(y)的熵越大越好,p(y|x)的熵越小越好,故此时引入KL散度,KL散度表示两者的离散状态,越大越好。
4.3.3、实验结果



总体来说:Stage-I GAN能够根据文本描述绘制对象的大致形状和颜色。然而,第一阶段的图像通常是模糊的,有各种缺陷和缺少细节,特别是对于前景对象。StageII GAN生成更高分辨率的图像,具有更令人信服的细节,以更好地反映相应的文本描述,且StageII GAN能够通过再次处理文本描述来纠正第一阶段结果的缺陷。
StackGAN与GAN-INT-CLS: StackGAN在IS分数和人类主观评分上面都比GAN-INT-CLS要好得多,图片尺寸大(256*256)且在细节方面(如鸟的喙、腹)更加真实。
StackGAN和GAWWN:StackGAN虽然只比GAWWN分数高一点,但是仅以文本描述为条件时,GAWWN无法生成任何合理的图像。相比之下,StackGAN可以仅从文本描述生成256×256照片真实感图像。
4.4.3 消融实验


-
堆叠结构(Stack)的使用: 只使用Stage-IGAN,IS分数会显著降低,没有CA的Stage-IGAN根本无法产生256*256的图像,有CA的Stage-IGAN虽然能产生,但是不像StackGAN那样逼真,证了提出叠层结构的必要性。另外,如果文本仅输入到第一阶段,第二阶段不输入,IS分数会下降,表明第二阶段文本的再处理有助于细化第一阶段的结果。
-
条件增强(Conditioning Augmentation)的使用:在不使用CA的情况下,由于GAN的训练动态不稳定,GAN生成的256×256样本会崩溃为无意义的图像。因此,所提出的条件增强有助于稳定条件GAN训练,并改善生成样本的多样性,因为它能够鼓励对沿潜在流形的小扰动的鲁棒性。
-
句子嵌入插值(Sentence embedding interpolation):为了进一步证明StackGAN学习了一个平滑的潜在数据流形,我们使用它从线性插值的句子嵌入中生成图像,修正了噪声矢量,实验证明能够生成流形的图像。
5、总结与体会
本篇文章的创新点有三:(1)提出了一种新的堆叠生成对抗网络,用于从文本描述合成照片真实感图像。它将生成高分辨率图像分解为更易于管理的子问题,并显著提高了技术水平。StackGAN首次从文本描述生成256×256分辨率的图像,具有照片般逼真的细节。(2) 提出了一种新的条件增强(CA)技术来稳定条件GAN训练,并提高了生成样本的多样性。(3) 大量的定性和定量实验证明了整体模型设计的有效性以及各个组件的影响,这为设计未来的条件GAN模型提供了可参考的模板和比较。
相关阅读
下一篇:论文精读StackGAN++