【菜菜的sklearn课堂】决策树-泰坦尼克号幸存者预测
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
导入数据
data = pd.read_csv(r'D:\ObsidianWorkSpace\SklearnData\data.csv')
# 前面加r防止\转义,或者改\为/
探索数据
data.head(5) # 探索数据常用方法,head()里面是几就显示前几行,默认为5
---
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
data.info() # 探索数据常用方法
---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
筛选特征。删除缺失过多的列,自己判断认为与预测结果没有关系的列
Name和Tickle和是否存活无关,Cabin缺失过多
data.drop(['Cabin','Name','Ticket'],axis=1,inplace=True)# 用drop删除数据
# 默认axis=0,沿行的方向删除,axis=1,沿列的方向删除
# 列表中写要删除的列名/行名
# inplace:是否用删除后的表覆盖原表,True替换,False不替换。用data = data.drop(inplace=False)也可以替换
处理缺失值。对缺失值较多的列进行填补,有一些特征只缺失一两个值,可以采取直接删除记录的方法
data['Age'] = data['Age'].fillna(data['Age'].mean())
data = data.dropna() # 什么也不填,即只要有缺失值就整行删除
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) # axis:轴向,默认0删除行,1删除列 # inplace:是否覆盖原表,如果不覆盖,则返回新表,如果覆盖,无返回值 # how:默认'any'即所在行/列有一个空值就删除,'all'即所在行/列全为空值才删除 # thresh:填int,当非空值数量大于等于该值就保留 # subset:填列表,当axis=0,列表元素为列标签,对每一行数据,对应列如果有空值,则删除;当axis=1,列表元素为行标签,对每一列数据,对应行如果有空值,则删除 df = pd.DataFrame([[1,2,3,None],[None,5,6,7]]) print(df) df.dropna(axis=1, subset=[0]) --- 0 1 2 3 0 1.0 2 3 NaN 1 NaN 5 6 7.0 0 1 2 0 1.0 2 3 1 NaN 5 6
data.info()
---
<class 'pandas.core.frame.DataFrame'>
Int64Index: 889 entries, 0 to 890
Data columns (total 9 columns):
PassengerId 889 non-null int64
Survived 889 non-null int64
Pclass 889 non-null int64
Sex 889 non-null object
Age 889 non-null float64
SibSp 889 non-null int64
Parch 889 non-null int64
Fare 889 non-null float64
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(2)
memory usage: 69.5+ KB
我们需要将分类变量转换为数值型变量。也就是object转换为num
Sex和Embarked是Object,需要改为数字
labels = data['Embarked'].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda x:labels.index(x))
# 要求该特征不同取值无关联,一般unique以后数量少于10个,可以这样处理
data['Embarked'].unique() # unique取出所有的值并删除重复值 --- array(['S', 'C', 'Q'], dtype=object)
data['Sex'] = (data['Sex'] == 'male').astype('int')
# astype能够将一个pandas对象转换为某种类型
# 和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷的将二分类特征转换为0-1
这里也可以用
data.loc[:,'Sex']
data.loc[:,'Sex']依据标签的索引,后面只能加列名或列名切片,不接收数字(列号)
data.iloc[:,3]即依据位置的索引,后面只能加数字或数字切片
二者都可以接收布尔索引
提取标签和特征矩阵,分离测试集和训练集
x = data.iloc[:,data.columns != 'Survived']
y = data.iloc[:,data.columns == 'Survived']
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x, y, test_size=0.3)
Xtrain.head()
---
PassengerId Pclass Sex Age SibSp Parch Fare Embarked
846 847 3 1 29.699118 8 2 69.5500 0
858 859 3 0 24.000000 0 3 19.2583 1
564 565 3 0 29.699118 0 0 8.0500 0
220 221 3 1 16.000000 0 0 8.0500 0
774 775 2 0 54.000000 1 3 23.0000 0
修正索引
如果索引乱了,而且我们不是有意让它乱,最好恢复成0-shape[0]的形式
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
导入模型,粗略跑一下查看结果
clf = DecisionTreeClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
---
0.7265917602996255
clf = DecisionTreeClassifier(random_state=0)
score = cross_val_score(clf,x,y,cv=10).mean()
score
---
0.7571118488253319
在不同max_depth下观察模型的拟合情况
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=0
,max_depth=i+1
)
clf = clf.fit(Xtrain,Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.figure()
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
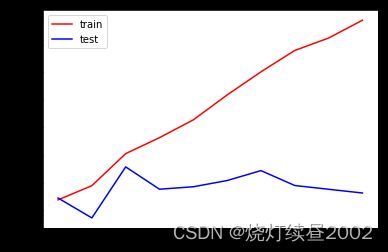
我们考虑用entropy。之前说entropy容易过拟合,但这是对训练集来说的,对测试集不一定,且此时训练集拟合程度也不太好
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=0
,max_depth=i+1
,criterion='entropy'
)
clf = clf.fit(Xtrain,Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.figure()
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
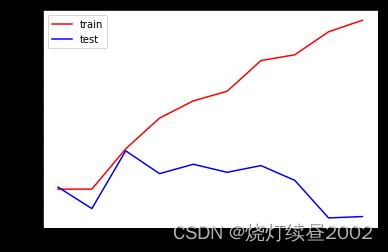
网格搜索:能够帮助我们同时调整多个参数的技术,是一种枚举技术
给定字典,字典中有参数范围,找到参数范围内能让模型最好的效果的组合
因为是多个参数组合,看起来像网格,所以叫网格搜索;因为是枚举,所以计算量很大,要注意参数数量,界定好参数范围
实际上,多数时间参数选择什么都是依赖自己的判断,或者只跑一两个参数组合
# 一串参数和这些参数对应的我们希望网格搜索来搜索的参数取值范围
gini_thresholds = np.linspace(0,0.5,5)
# 原课程用的50,我就不折腾我这破铜烂铁了
parameters = {'criterion':('gini','entropy')
,'splitter':('best','random')
,'max_depth':[*range(2,6)]
,'min_samples_leaf':[*range(5,50,5)]
,'min_impurity_decrease':[*gini_thresholds]
}
clf = DecisionTreeClassifier(random_state=0)
GS = GridSearchCV(clf, parameters, cv=10)# 同时有fit,score,交叉验证三种功能
GS = GS.fit(Xtrain,Ytrain)
GS.best_params_ # 从我们输入的参数和参数取值的列表中,返回最佳组合
---
{'criterion': 'gini',
'max_depth': 6,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 11,
'splitter': 'best'}
GS.best_score_ # 网格搜索后的模型评判标准
---
0.819935691318328
现在选择参数的方法有:学习曲线和网格搜索