【医学图像处理】融合 Transformer 和 CNN 进行医学图像分割
标题:TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation
作者:Yundong Zhang,乔治亚理工学院
来源:MICCAI 2021
代码:https://github.com/Rayicer/TransFuse
主题:Transformer;医学图像分割
1. 引言
❓ 论文的研究背景是什么?
虽然卷积神经网络(CNN) 在众多医学图像分割任务中取得了无与伦比的性能,但是它在捕获全局上下文信息方面缺乏效率,现有工作通过生成非常大的感受野来获取全局信息,这需要连续下采样和堆叠卷积层直到足够深。这带来了几个缺点:1)非常深的网络的训练会受到特征重用衰减(Diminishing feature reuse)问题的影响,其中低级特征被连续的乘法操作“冲洗”掉; 2)随着空间分辨率逐渐降低,对密集预测任务(例如逐像素分割)至关重要的局部信息丢失; 3)用小型医学图像数据集训练参数非常多的深度网络往往不稳定且容易过拟合。因此,医学图像分割等待着一个更好的解决方案,以提高对全局上下文建模的效率,同时保持对低级细节的有力捕获。
❓ 什么是特征重用衰减(Diminishing feature reuse)?
Diminishing feature reuse during forward propagation (also known as loss in information flow) refers to the analogous problem to vanishing gradients in the forward direction. The features of the input instance, or those computed by earlier layers, are “washed out” through repeated multiplication or convolution with (randomly initialized) weight matrices, making it hard for later layers to identify and learn “meaningful” gradient directions. Recently, several new architectures attempt to circumvent this problem through direct identity mappings between layers, which allow the network to pass on features unimpededly from earlier layers to later layers.
参考资料:Huang, Gao, et al. “Deep networks with stochastic depth.” European conference on computer vision. Springer, Cham, 2016.
❓ 论文相关研究有哪些?
-
完全基于 Transformer 的分割网络 SETR
SETR 网络在传统的基于编码器解码器的网络中用 Transformer 替换编码器,在自然图像分割任务上取得了最先进的结果。
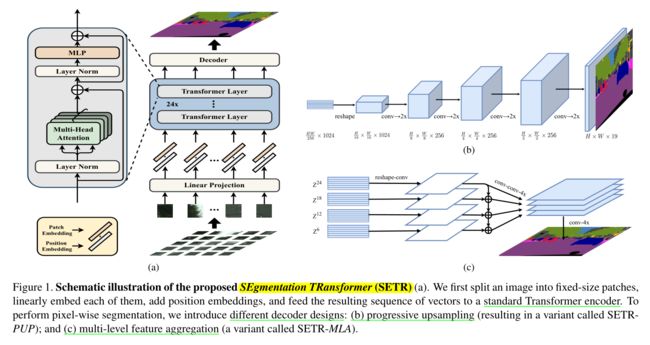
虽然 Transformer 擅长对全局上下文进行建模,但它在捕获细粒度细节方面显示出局限性,尤其是对于医学图像。研究表明,类似 SETR 完全基于 Transformer 的分割网络会产生不令人满意的性能,因为在建模局部信息时缺乏空间归纳偏置(inductive bias)。
❓ 什么是归纳偏置(inductive bias)?
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered.
In machine learning, one aims to construct algorithms that are able to learn to predict a certain target output. To achieve this, the learning algorithm is presented some training examples that demonstrate the intended relation of input and output values. Then the learner is supposed to approximate the correct output, even for examples that have not been shown during training. Without any additional assumptions, this problem cannot be solved since unseen situations might have an arbitrary output value. The kind of necessary assumptions about the nature of the target function are subsumed in the phrase inductive bias.
更多关于**归纳偏置(inductive bias)**的内容可以参考:Mitchell, Benjamin R. The Spatial Inductive Bias of Deep Learning. Diss. Johns Hopkins University, 2017.
-
将 CNN 与 Transformer 相结合的分割网络 TransUnet
TransUnet 首先利用 CNN 提取低级特征,然后通过 Transformer 对全局交互进行建模,并结合跳跃连接,在 CT 多器官分割任务中创造了新的记录。
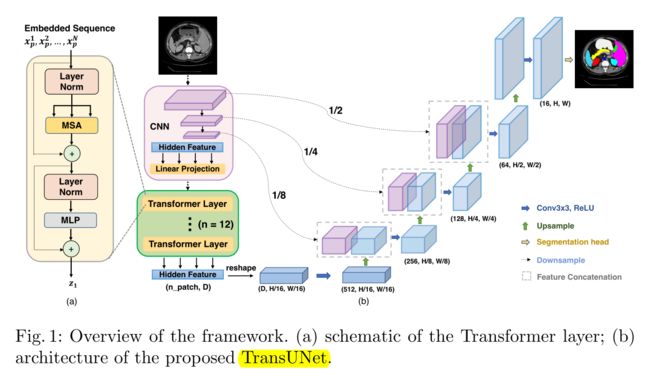
❓ 论文的主要创新性是什么?
已有的研究工作主要集中在用 Transformer 层代替卷积或将两者按顺序堆叠。本文提出了一种不同的架构——TransFuse,它以并行的方式运行基于 CNN 的编码器和基于 Transformer 的分割网络,然后使用提出的融合模块 BiFusion 有效地融合两个分支的多层级特征。 TransFuse 具有以下几个优点: 1) 可以有效捕获低级空间特征和高级语义上下文; 2)它不需要很深的网络,这缓解了梯度消失和特征重用衰减的问题; 3)它大大提高了模型大小和推理速度的效率,不仅可以在云端部署,还可以在边缘部署。据我们所知,TransFuse 是第一个综合 CNN 和 Transformer 的并行分支模型。
2. 方法
2.1 TransFuse 网络结构
TransFuse 由两个并行处理信息的分支组成:1)CNN 分支,逐渐增加感受野,从局部到全局编码特征; 2) Transformer 分支,从全局自注意力开始,最后恢复局部细节。从两个分支中提取的具有相同分辨率的特征被输入到本文提出的 BiFusion 模块中,其中应用自注意力和 Hadamard 乘积来选择性地融合信息。然后,结合多级融合特征图,使用注意门控(attention-gated, AG)跳跃连接生成分割图。提出的并行分支方法有两个主要好处:首先,通过利用 CNN 和 Transformer 的优点,TransFuse 可以在不构建非常深的网络的情况下捕获全局信息,同时保持对低级上下文的敏感性;其次,本文提出的 BiFusion 模块可以在特征提取过程中同时利用 CNN 和 Transformer 的不同特性,从而使融合表示强大且紧凑。

Transformer 分支
Transformer 分支的设计遵循典型的编码器-解码器架构。
编码器
首先将输入图像 x ∈ R H × W × 3 \mathbf{x} \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3 均匀划分为 N = H S × W S N=\frac{H}{S} \times \frac{W}{S} N=SH×SW 块,其中 S S S 通常设置为 16。然后将图像块展平并传递到输出维度为 D 0 D_{0} D0 的线性嵌入(linear embedding)层,得到原始嵌入序列(embedding sequence) e ∈ R N × D 0 \mathbf{e} \in \mathbb{R}^{N \times D_{0}} e∈RN×D0。为了利用空间先验,将相同维度的可学习的位置嵌入(positional embedding)添加到 $\mathbf{e} $。生成的嵌入 z 0 ∈ R N × D 0 \mathbf{z}^{0} \in \mathbb{R}^{N \times D_{0}} z0∈RN×D0 是 Transformer 编码器的输入,它包含 L L L 层多头自注意力 (multi-headed self-attention, MSA) 和多层感知机(Multilayer Perceptron, MLP)。作为 Transformer 核心原理的自注意(self-attention, SA)机制通过在每一层全局聚合信息来更新每个嵌入块的状态:
S A ( z i ) = softmax ( q i k T D h ) v \mathrm{SA}\left(\mathbf{z}_{i}\right)=\operatorname{softmax}\left(\frac{\mathbf{q}_{\mathbf{i}} \mathbf{k}^{T}}{\sqrt{D_{h}}}\right) \mathbf{v} SA(zi)=softmax(DhqikT)v
其中 [ q , k , v ] = z W q k v , W q k v ∈ R D 0 × 3 D h [\mathbf{q}, \mathbf{k}, \mathbf{v}]=\mathbf{z} \mathbf{W}_{q k v}, \mathbf{W}_{q k v} \in \mathbb{R}^{D_{0} \times 3 D_{h}} [q,k,v]=zWqkv,Wqkv∈RD0×3Dh 是投影矩阵,向量 z i ∈ R 1 × D 0 \mathbf{z}_{i} \in \mathbb{R}^{1 \times D_{0}} zi∈R1×D0, q i ∈ R 1 × D h \mathbf{q}_{\mathbf{i}} \in \mathbb{R}^{1 \times D_{h}} qi∈R1×Dh 分别是 z \mathbf{z} z 和 q \mathbf{q} q 的第 i i i 行。 MSA 是 SA 的扩展,它连接多个 SA 并将维度投影回 R D 0 \mathbb{R}^{D_{0}} RD0,而 MLP 是密集层的堆叠。**层归一化(Layer normalization)**应用于最后一个 Transformer 层的输出以获得编码序列 z L ∈ R N × D 0 \mathbf{z}^{L} \in \mathbb{R}^{N \times D_{0}} zL∈RN×D0。
更多关于 Transformer 的内容可以参考论文 An image is worth 16x16 words: Transformers for image recognition at scale 和视频彻底搞懂 Vision Transformer。
解码器
解码器使用 SETR 论文中的渐进上采样(progressive upsampling, PUP)方法。具体来说,我们首先变换 z L \mathbf{z}^{L} zL 的维度为 t 0 ∈ R H 16 × W 16 × D 0 \mathbf{t}^{0} \in \mathbb{R} ^{\frac{H}{16} \times \frac{W}{16} \times D_{0}} t0∈R16H×16W×D0,可以将其视为具有 D 0 D_{0} D0 个通道的 2D 特征图。然后我们使用两个连续的标准上采样卷积层来恢复空间分辨率,分别得到 t 1 ∈ R H 8 × W 8 × D 1 \mathbf{t}^{1} \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times D_{1}} t1∈R8H×8W×D1 和 t 2 ∈ R H 4 × W 4 × D 2 \mathbf{t}^{2} \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times D_{2}} t2∈R4H×4W×D2。保存不同尺度 t 0 \mathbf{t}^{0} t0、 t 1 \mathbf{t}^{1} t1 和 t 2 \mathbf{t}^{2} t2 的特征图,以便与 CNN 分支的相应特征图进行后期融合。
CNN 分支
传统上,特征图被逐步下采样到 H 32 × W 32 \frac{H}{32} \times \frac{W}{32} 32H×32W,并且使用数百层 CNN 中来获得特征的全局上下文,这导致非常深的模型和非常大的资源消耗。考虑到 Transformer 带来的好处,我们从原始 CNN 中移除最后一层(因为最后一层的参数最多),并利用 Transformer 分支来获取全局上下文信息。这不仅会得到更浅的模型,而且还会保留更丰富的局部信息。例如,基于 ResNet 的模型通常有五个块,每个块以 2 为因子对特征图进行下采样。我们将第 4 个( g 0 ∈ R H 16 × W 16 × C 0 \mathbf{g}^{0} \in \mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C_{0}} g0∈R16H×16W×C0)、第 3 个( g 1 ∈ R H 8 × W 8 × C 1 \mathbf{g}^{1} \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times C_{1}} g1∈R8H×8W×C1)和第 2 个( g 2 ∈ R H 4 × W 4 × C 2 \mathbf{g}^{2} \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C_{2}} g2∈R4H×4W×C2)块的输出与来自 Transformer 的输出融合。
BiFusion 模块
为了有效地结合 CNN 和 Transformers 的编码特征,我们提出了一个新的 BiFusion 模块,它结合了自注意和多模式融合机制。具体来说,我们通过以下操作获得融合特征表示 f i , i = 0 , 1 , 2 \mathbf{f}^{i}, i=0,1,2 fi,i=0,1,2:
t ^ i = ChannelAttn ( t i ) g ^ i = SpatialAttn ( g i ) b ^ i = Conv ( t i W 1 i ⊙ g i W 2 i ) f i = Residual ( [ b ^ i , t ^ i , g ^ i ] ) \begin{aligned}\hat{\mathbf{t}}^{i} &=\operatorname{ChannelAttn}\left(\mathbf{t}^{i}\right) & \hat{\mathbf{g}}^{i} &=\operatorname{SpatialAttn}\left(\mathbf{g}^{i}\right) \\\hat{\mathbf{b}}^{i} &=\operatorname{Conv}\left(\mathbf{t}^{i} \mathbf{W}_{1}^{i} \odot \mathbf{g}^{i} \mathbf{W}_{2}^{i}\right) & \mathbf{f}^{i} &=\operatorname{Residual}\left(\left[\hat{\mathbf{b}}^{i}, \hat{\mathbf{t}}^{i}, \hat{\mathbf{g}}^{i}\right]\right)\end{aligned} t^ib^i=ChannelAttn(ti)=Conv(tiW1i⊙giW2i)g^ifi=SpatialAttn(gi)=Residual([b^i,t^i,g^i])
其中, W 1 i ∈ R D i × L i W_{1}^{i} \in \mathbb{R}^{D_{i} \times L_{i}} W1i∈RDi×Li, W 2 i ∈ R C i × L i W_{2}^{i} \in \mathbb{R}^{C_{i} \times L_{i}} W2i∈RCi×Li, ∣ ⊙ ∣ |\odot| ∣⊙∣ 是 Hadamard 积, Conv \operatorname{Conv} Conv 是一个 3 × 3 的卷积层。通道注意力采用 SE-Block ,促进来自 Transformer 分支的全局信息。空间注意力采用 CBAM 块,作为空间滤波器来增强局部细节,抑制不相关区域,因为 CNN 的低层特征可能会有噪声。然后采用 Hadamard 积对来自两个分支的特征图进行交互。最后,将交互特征 b ^ i \hat{\mathbf{b}}^{i} b^i 和注意特征 t ^ i \hat{\mathbf{t}}^{i} t^i, g ^ i \hat{\mathbf{g}}^{i} g^i 拼接起来并通过残留块。所得到的特征 f i \mathbf{f}^{i} fi 有效地捕获了当前空间分辨率的全局和局部上下文。为了生成最终的分割,使用 AG 跳跃连接来组合 f i \mathbf{f}^{i} fi,有 f ^ i + 1 = Conv ( [ U p ( f ^ i ) , A G ( f i + 1 , U p ( f ^ i ) ) ] ) \hat{\mathbf{f}}^{i+1}=\operatorname{Conv}\left(\left[\mathrm{Up}\left(\hat{\mathbf{f}}^{i}\right), \mathrm{AG}\left(\mathbf{f}^{i+1}, \mathrm{Up}\left(\hat{\mathbf{f}}^{i}\right)\right)\right]\right) f^i+1=Conv([Up(f^i),AG(fi+1,Up(f^i))]) 和 f ^ 0 = f 0 \hat{\mathbf{f}}^{0}=\mathbf{f}^{0} f^0=f0。
2.2 损失函数
整个网络使用加权 IoU 损失和二元交叉熵损失 L = L I o U w + L b c e w L=L_{I o U}^{w}+L_{b c e}^{w} L=LIoUw+Lbcew 进行端到端训练,其中边界像素被赋予更大的权重。除了对输出分割预测进行监督以外,我们使用深监督通过额外监督 Transformer 分支和第一个融合分支来改善梯度流。最终的训练损失为 L = α L ( G , head ( f ^ 2 ) ) + γ L ( G , head ( t 2 ) ) + β L ( G , head ( f 0 ) ) \mathcal{L}=\alpha L\left(G, \operatorname{head}\left(\widehat{\mathbf{f}}^{2}\right)\right)+\gamma L\left(G, \operatorname{head}\left(\mathbf{t}^{2}\right)\right)+\beta L\left(G, \text { head }\left(\mathbf{f}^{0}\right)\right) L=αL(G,head(f 2))+γL(G,head(t2))+βL(G, head (f0)) 其中 α , γ , β \alpha, \gamma, \beta α,γ,β 是可调超参数,根据经验设置分别为 0.5、0.3、0.2, G G G 是 ground truth。
❓ 什么是深监督(Deep Supervision)?
所谓深监督(Deep Supervision),就是在深度神经网络的某些中间隐藏层添加伴随目标函数(companion objective functions),然后将最终损失计算为输出损失加上伴随损失的总和,用来解决深度神经网络训练梯度消失和收敛速度过慢等问题。
更多关于深度监督的内容可以参考论文 Training deeper convolutional networks with deep supervision。
3. 实验过程与结果
3.1 数据集
为了更好地评估 TransFuse 的有效性,考虑了具有不同成像方式、疾病类型、目标对象、目标大小等的四个分割任务:
息肉分割
使用 5 个公开息肉数据集:Kvasir、CVC- ClinicDB、CVC-ColonDB、EndoScene 和 ETIS。从 Kvasir 和 CVC-ClinicDB 中选择 1450 张训练图像,从所有 5 个数据集中选择 798 张测试图像。将每张图像的大小调整为 352×352。更具体的数据处理方案参考论文 Pranet: Parallel reverse attention network for polyp segmentation。
皮肤病变分割
使用 2017 International Skin Imaging Collaboration(ISIC 2017)数据集。 ISIC 2017 提供 2000 张训练图像、150 张验证图像和 600 张测试图像。将所有图像的大小调整为 192 × 256。
髋关节分割
从医院收集了总共 641 张图像。每张图像都由一名临床专家标注,并由两名专家进行双盲审查。将所有图像的大小调整为 352 × 352,并以 7:1:2 的比例随机分配图像用于训练、验证和测试。
前列腺分割
使用来自 Medical Segmentation Decathlon 的容积前列腺多模态 MRI。该数据集包含来自 32 名患者的多模态 MRI。我们将所有 MRI 切片的大小调整为为 320 × 320,并使用 Z-Score 标准化独立地对每个体积进行标准化。
3.2 实施
- 框架:PyTorch
- 硬件:NVIDIA-A100 GPU
- 优化器:Adam
- 学习率:1e-4
- 批量大小:16
- Number of epochs:60
3.3 实验结果
为了更好地展示本文方法的有效性和灵活性以及与其他方法进行公平的比较,本文提供了三种 TransFuse 变体:
- TransFuse-S 使用 ResNet-34 (R34) 和 8 层 DeiT-S 分别作为 CNN 分支和 Transformer 分支的主干。
- TransFuse-L 使用 ResNet-50 (R50) 和 10 层 DeiT-B 分别作为 CNN 分支和 Transformer 分支的主干。
- TransFuse-L* 使用 ResNet-50(R50) 和 ViT-B 分别作为 CNN 分支和 Transformer 分支的主干。
息肉分割
根据平均 Dice系数(mDice)和平均 IoU(mIoU)评估本文提出的息肉分割方法与各种 SOTA 方法的性能。如下表所示,本文提出的 TransFuse-S/L 大大优于基于 CNN 的 SOTA 方法,同样,与其他基于 Transformer 的方法相比,TransFuse-L* 取得了最好的结果。

此外,在 Xeon® Gold 5218 CPU 和 RTX2080Ti 上评估了参数数量和推理速度(inference speed)方面的效率。与之前基于 CNN 的技术相比,TransFuse-S 仅使用 26.3 M 个参数就能获得最佳的性能,比 HarDNet-MSEG(33.3 M)和 PraNet(32.5 M)降低了约 20%。此外,TransFuse-S 能够以 98.7 FPS 运行,比 HarDNet-MSEG(85.3 FPS)和 PraNet(63.4 FPS)快得多,这得益于我们提出的并行分支设计。同样,TransFuse-L* 不仅比其他基于 transformer 的方法获得了更好的结果,而且运行速度为 45.3 FPS,比 TransUnet 快 12% 左右。
❓ 什么是模型的推理速度(inference speed)?
Inference time is the amount of time it takes for applying a trained neural network model to process new data and make a prediction. Inference speed is measured with frames per second (FPS), namely the average iterations per second, which can show how fast the model can handle an input.
https://www.quora.com/What-is-inference-time-in-deep-learning
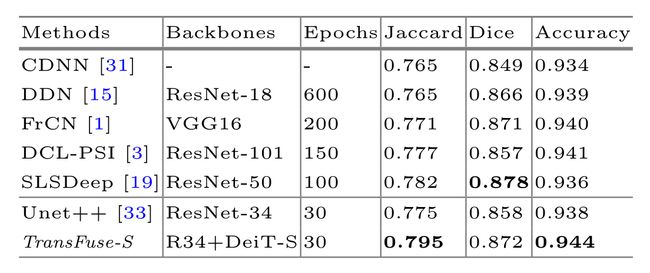
皮肤病变分割
ISBI 2017 挑战赛根据 ISIC 2017 测试集上的 Jaccard 系数对方法进行排序。在这里,我们使用 Jaccard 系数、Dice 系数和**像素准确度(pixel-wise accuracy)**作为评估指标。与各种 SOTA 方法的比较结果如下表所示。TransFuseS 在 Jaccard 系数方面比之前的最先进的方法 SLSDeep 好约 1.7%,收敛时间不到 SLSDeep 的 1/3。
髋关节分割
下表显示了我们在髋关节分割任务上的结果,该任务涉及三个人体部位:骨盆、左股骨(L-Femur)和右股骨 (R-Femur)。由于轮廓在诊断和术前计划中更为重要,因此我们使用 **Hausdorff 距离(HD)和平均表面距离(ASD)**来评估预测质量。与两种先进的分割方法相比,TransFuse-S 在这两个指标上都表现最好,并且显着降低了 Hausdorff 距离,表明我们提出的方法能够捕捉更精细的结构并生成更精确的轮廓。

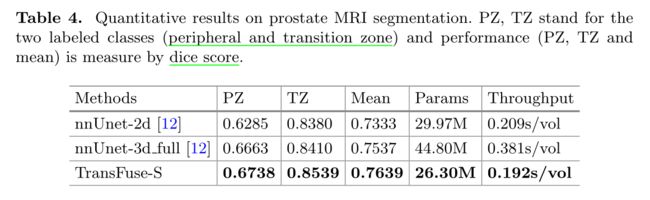
前列腺分割
比较了 TransFuse-S 和 nnUNet,后者在前列腺分割挑战中排名第一。实验中使用与公开的 nnUNet 框架(https://github.com/MIC-DKFZ/nnUNet)相同的预处理、训练和评估方案,结果如下表所示。可以发现,与 nnUNet-3d 相比,TransFuse-S 不仅获得了更好的性能,而且参数减少了大约 41%,吞吐量提高了大约 50%(在 GTX1080 上)。
消融研究
在消融研究中,通过选择不同的主干、组合和融合方案来评估并行分支设计和 BiFusion 模块的有效性。
使用息肉数据集 Kvasir 作为训练集,ColonDB 作为测试集,平均 Dice 系数作为评估指标,结果如表 5 所示。通过将 E.3 与 E.1 和 E.2 进行比较,我们可以看到将 CNN 和 Transformer 结合可以带来更好的性能。此外,通过将 E.3 与 E.5、E.6 进行比较,我们观察到并行模型的性能优于顺序模型。此外,使用与 E.6 相同的并行结构和融合设计来评估双分支 CNN 模型(E.4)的性能。我们观察到 E.6 在 Kvasir 中的性能比 E.4 高 2.2%,在 ColonDB 中高出 18.7%,这表明 CNN 分支和 Transformer 分支相辅相成,能产生更好的融合结果。
最后,将一个包含拼接操作和残差块的融合模块与本文提出的 BiFusion 模块(E.5 和 E.6)进行性能比较。给定相同的主干和组合设置,使用 BiFusion 的 E.6 取得了更好的结果。表 6 显示了在 ISIC2017 上进行的其他实验,以验证 BiFusion 模块的设计选择,从中我们发现每个组件都显示出其独特的优势。
Table 5. Ablation study on parallel-inbranch design. Res: Residual.

Table 6. Ablation study on BiFusion module. Res: Residual; TFM: Transformer; Attn: Attention.

4.重要参考文献
-
Transformer
Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
Zheng, Sixiao, et al. “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2021.
Chen, Jieneng, et al. “Transunet: Transformers make strong encoders for medical image segmentation.” arXiv preprint arXiv:2102.04306 (2021).
-
SE-Block
Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition . 2018.
-
CABM
Woo, Sanghyun, et al. “Cbam: Convolutional block attention module.” Proceedings of the European conference on computer vision (ECCV) . 2018.
-
Attention-gated (AG) skip-connection
Oktay, Ozan, et al. “Attention u-net: Learning where to look for the pancreas.” arXiv preprint arXiv:1804.03999 (2018).
-
Deep Supervision
Lee, Chen-Yu, et al. “Deeply-supervised nets.” Artificial intelligence and statistics. PMLR, 2015.
Wang, Liwei, et al. “Training deeper convolutional networks with deep supervision.” arXiv preprint arXiv:1505.02496 (2015).
5. 评审意见
官方评审意见:https://miccai2021.org/openaccess/paperlinks/2021/09/01/496-Paper0016.html
评分:6,6,6
5.1 优点
- The authors explored and exploited transformer-alike architectures on medical segmentation tasks.
- Extensive experiments were demonstrated on different medical image segmentation tasks, including polyp, skin lesion, and hip segmentation.
5.2 缺点
- The proposed model improves upon the performance of the serial configuration marginally and the improvement in inference speed is not drastic. As these models are deployed over the cloud typically and not on edge devices, the slight reduction in parameters and inference speed might not affect user experience.
- The BiFusion module is heavily engineered with channel attention for transformer features, spatial attention for CNN features, dot product to fuse the CNN and transformer features and gated skip attention for the concatenated features. A simple concatenate and residual connections for fusing the transformer and CNN features provides nearly equivalent performance. Can this module be simplified?
5.3 建议
- The contribution of each Transformer/CNN branch was not explicitly and visually justified. Adding more detailed ablation studies of each CNN/Transformer branch would help the readers to get a clue about their individual contribution towards the final segmentation results.
- In terms of method, the design of BiFusion module is mostly engineering or system building built on slightly weak motivations, using several existing attention mechanisms. The design motivation of the proposed BiFusion module should be enhanced.