CNN:经典Backbone和Block
一、网络的属性参数
选择网络backbone时除了考虑网络结果精准度外,还需要根据计算平台的性能约束(算力、内存、带宽),以及期望的网络推理帧率,选取合适的网络backbone,这就需要考察网络的属性指标:参数量、计算量、占用Memory。
1. 参数量
主要指网络权重的参数量,对于CNN网络,主要是卷积核、BN层、全连接层的参数量。
- 卷积核:设Nin, Nout, K分别表示in_channels,out_channels,和kernel_size,则参数量为:Nin*K*K*Nout + Nout (权重+bias)
- BN层:2*Nin
- 全连接层:Lin*Lout + Lout(设Lin,Lout分别表示输入和输出向量的长度)
在实操中,pytorch可以统计model.parameters()中参数量获得网络的参数的数量。
参考:神经网络参数量的计算:以UNet为例 - 知乎
2. 计算量
一次卷积操作的计算量为:Nin*(K*K+K*K-1) + Nin-1 , 其中,卷积的乘法为K*K,卷积核的加法K*K-1,Nin-1为跨通道的加法数。
需要进行的卷积次数:Hout*Wout。 设输入分辨率为Hin*Win,经过卷积后输出分辨率为
Hout=[Hin+2*padding[0]-dilation[0]*(kernel_size[0]-1)-1]/stride[0]+1,
Wout=[Win+2*padding[1]-dilation[1]*(kernel_size[1]-1)-1]/stride[1]+1,
再考虑需要的输出通道数Nout和Batch数B,
卷积的计算量为:B*Nout*Hout*Wout*(Nin*2K*K-1+Nin-1)
举例:当输入为224x224时,对于ResNet-50,计算量约4.5GFLOPs;对于ResNet-200, 计算量约15GFLOPs。
核算整个网络的计算量后,可以知道模型对应的计算量是多少floating-point operations (FLOPs)。随后结合计算平台的算力是多少FLOPS(floating-point operations per second)可以大概推算模型的帧率(当然,实际还涉及到模型的优化部署问题以及带宽等瓶颈是的实际帧率会低于该评估值)。
模型计算量评估可参考:神经网络中参数量以及计算量的计算 - 知乎
这里需要注意,评估模型的计算量单位是FLOPs,注意是小s,表示的是模型需要进行多少次浮点运算。评估计算平台的算力单位是FLOPS,表示的是计算平台在单位时间可以进行多少次浮点运算。根据模型推理的帧率需求fps,以及计算平台的物理算力FLOPS,可以计算模型的计算量FLOPs,三者之间关系:FLOPs= FLOPS/fps。
参考:FLOPS、TOPS和FLOPs的区别_BRUCE_WUANG的博客-CSDN博客_tops和flops
3. Memory
占用memory的网络要素包括:
- 各层的feature map(占用主要的memory)
- 网络的权重(根据float32占用4bytes可以折算上面的权重所占用的memory)
- 训练过程需要在考虑梯度占用内存
参考:神经网络参数量、数据量计算 - leizhao - 博客园
二、网络结构
一般而言,一个网络backbone包括多个Stages,每个Stage包含多个Block。
Stage是指卷积提取特征中,feature map的size是逐级降低的,一个feature map分辨率之间的所有网络结构叫做一个Stage;
Block是指用于构建网络的基本单元,每个block包含卷积层、pooling层等基本操作。
论文中网络结构会创造或优化Block,并搭建一个或多个Backbone。
1. 越来越深的网络
以ImageNet 2012~2017年(2017年是最后一届)冠军网络代表了深度神经网络的发展趋势,2012~2014年结果可参见论文(2015,Imagenet large scale visual recognition challenge),2016~2017年结果可参见链接:ImageNet历年冠军和相关CNN模型 - PilgrimHui - 博客园
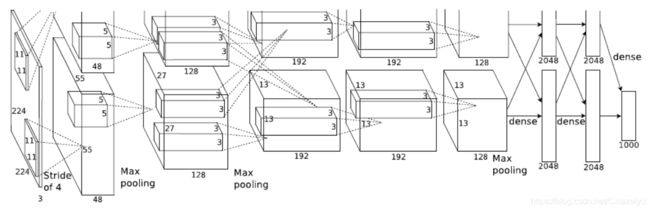
AlexNet
AlexNet(2012, Imagenet classification with deep convolutional neural networks)是2012年ImageNet的SOTA,通过CNN方法取得的性能远超过传统机器学习手动提取的特征,使得神经网络方法成为主流。其主要贡献是验证了深度神经网络在大规模数据集的性能。对后来网络的主要影响包括:
- 使用ReLU激活函数,相比于sigmoid和tanh而言,训练更快,并防止梯度弥散。
- 训练中提出了dropout正则化方法防止过拟合。
AlexNet共8层,是当时最深层的网络。结构如下:
VGG
VGG(2014, Very deep convolutional networks for large-scale image recognition)是2014年ImageNet的LOC任务的SOTA。VGG使用2个3x3的kernel,感受野达到5x5,使用3个3x3的kernel,感受野可以达到7x7,但是参数量显著降低。使用3x3设计了简单网络,发现随着层数增加,误差降低。(当时ResNet还没有横空出世,19层算深的网络。)
对应的VGG-11, VGG-13,VGG-16, VGG19的网络结构如下:
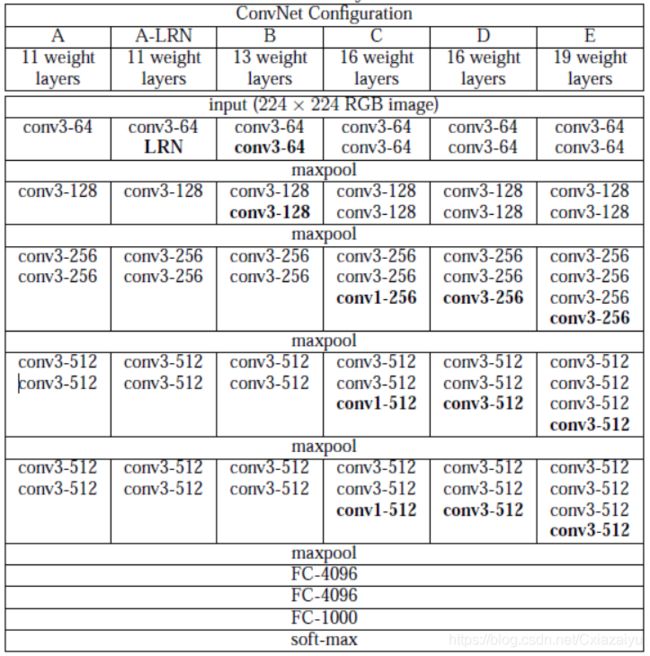
图片引自(2015, Very deep convolutional networks for large-scale image recognition)
性能如下:
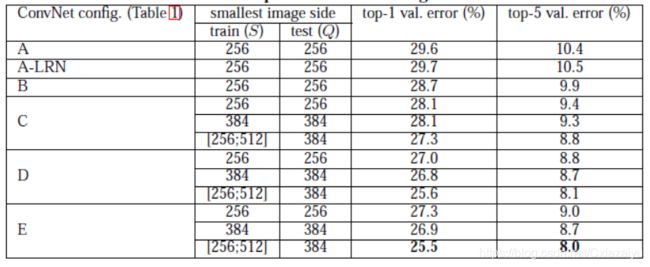
图片引自(2014, Very deep convolutional networks for large-scale image recognition)
Inception系列
Inception-V1(2015,Going Deeper with Convolutions) 是2014年ImageNet的CLS和DETo任务的SOTA。
Inception-V1的核心思想是构建符合Hebbian principle(neurons that fire together, wire together)的Block,即神经网络应该是稀疏的,然而,稀疏矩阵在计算机中实现效率较低,因此,使用如下多尺度的方法实现稀疏连接的效果。直观理解是:使用了不同尺度的filter concate到一起,得到的权重肯定会选择性地在最合适的尺度的filter上值较高,在不合适的filter上的值较低,从而实现一种稀疏连接。
另外,为了降低计算量,对于3x3和5x5的卷积可以先使用1x1的卷积降低其维度。
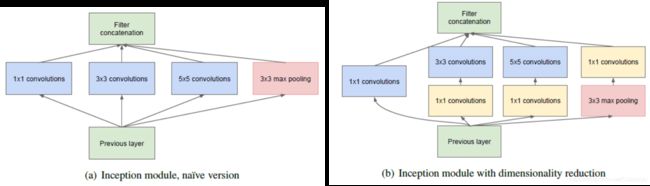
基于该block,搭建了22层的网络,将该网络称为GoogLeNet。为了监督较深的网络,在中间添加了一些辅助head求loss,防止梯度消失。
Inception-V2 (2015, Batch normalization: Accelerating deep network training by reducing internal covariate shift) & Inception-V3(2016,Rethinking the inception architecture for computer vision)对Inception-V1进行了一些改进:
- 借鉴VGG,使用两个3x3堆叠代替计算量大的5x5。并进一步设计了一些非对称的分解;
- 提出Batch Normalization进行正则化;
- 使用Label Smoothing做正则化。
并将网络进一步增加到42层。
Xception(Xception: Deep Learning with Depthwise Separable Convolutions)做了一个extreme的假设:跨channel的correlations和空间的correlations可以完全独立进行,从而使用了Depthwise separable convolution。虽然Xception的基本模块时从Inception module推出来的,但已经没有Inception模块多尺度的概念了,甚至可以说和Inception module没有明显的关系了。
ResNet系列
ResNet(2016,Deep residual learning for image recognition)是2015年ImageNet的SOTA。
以前VGG、Inception的论文显示随着网络深度加深,网络精度提升;然而,继续提升深度则发现网络不易训练优化。
一方面,更深的网络容易出现梯度爆炸和梯度消失的问题,使得模型训练不易收敛,这可以通过Normalization解决。
另一方面,在模型收敛后,发现非常深的网络模型收敛后的loss error反而比较浅的模型的loss errror高。Kaiming大神通过引入残差模块解决了这个问题,两种残差结构如下图所示:
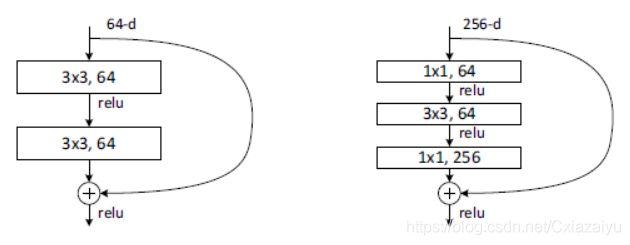
图片引自(2016,Deep residual learning for image recognition):直接加残差(左图) and bottleneck的残差(右图)
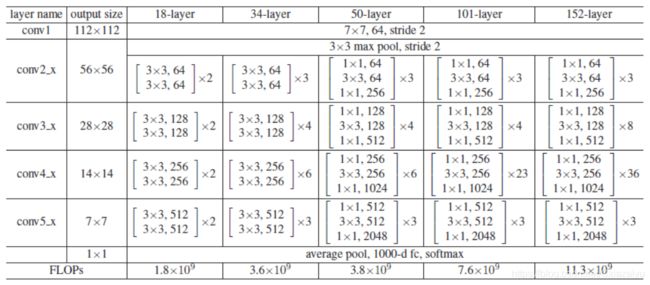
使得网络可以非常深(达到了152层),对应的ResNet-18, ResNet34,ResNet-50, ResNet-101,ResNet-152的结构如下:
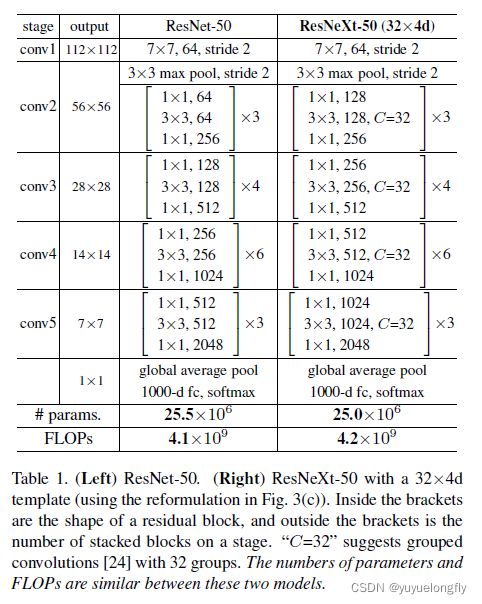
ResNext (2017, Aggregated residual transformations for deep neural networks)使用Group convolution减少计算量,因此,当保证计算量不变的条件下,可以增加channel数。改进后的基本block结构如下:
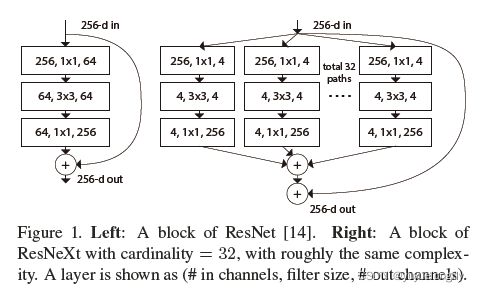
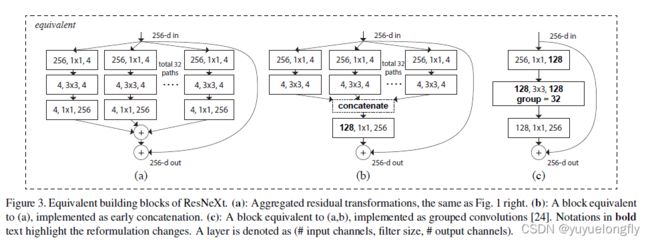
(上面的实现是和group convolution等价的)
整个ResNext的结构如下:
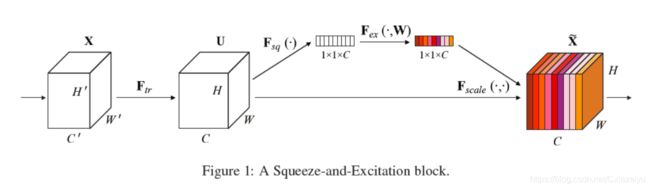
SENet(2017,Squeeze-and-excitation networks)是2017年ImageNet分类任务的SOTA。其实质是引入注意力机制(Attention),使得网络可以关注更有效的feature的channel。具体实现方法如下图,在论文中,通过对每个channel提取average pooling,获得表征channel的feature的指标,随后,用该指标乘以每个channel的feature map。这可以防止在channel信息叠加是较小值累加到一起超过具有明显特征的feature的channel。
2. 更好的网络设计
Efficientnet
Efficientnet(2019,Efficientnet: Rethinking model scaling for convolutional neural networks)使用NAS搜索出来的结构,并通过scale时保持depth,width, resolution的关系保证网络应用到不同算力限制的平台下都达到较好的效果。
RegNet
RegNet(2020,Designing Network Design Spaces) 在更广泛的意义进行了网络结构的设计,即设计“网络设计空间”。通过逐渐引入一些简单的设计规则,如果在约束后的新的设计空间上对参数进行采样后获得的网络在统计意义上的error empirical distribution function(EDF)分布是更优的,则相应的网络设计空间认为是更优的。如下图中的EDF分布,该曲线是通过不断增加e,则更多的采样的网络满足ei < e的条件,对应的F(e)增加;如果在EDF分布中,如果较小的e阈值时就有更多比例的模型满足条件了,则说明这个设计空间更好。
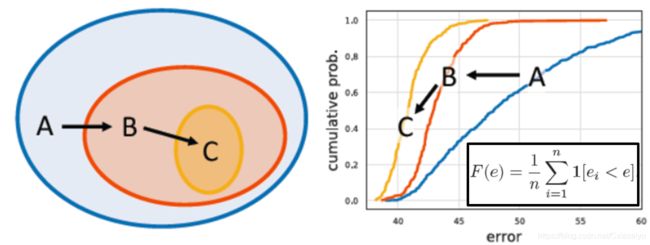
图片引自(2020,Designing Network Design Spaces),略作修改
在论文中,先设计了AnyNet的空间,做了stem,backbone, head的基本结构的约束,并focus在对backbone进行优化。随后,本着如下设计原则:1. 简化设计空间结构,2. 使得设计空间更易解释(数学表达其中的参数), 3.提升或者至少保持设计空间的质量,4. 保证设计空间内网络的多样性, 开始进行条件约束,并在约束后的空间上对网络参数进行采样,获得网络后计算出新的EDF曲线。进行的约束包括:a. backbone中使用的Xblock的约束 =》 b. 另所有的stage都使用相同的bottleneck ratio =》 c.另所有的stage都使用相同的group width =》 d. channel数随stage逐渐增加 =》e.深度(block数)随着stage逐渐增加。 其中,b和c的约束对EDF分布不造成明显差异,但满足了设计原则中的1和2。 d和e约束明显使得 EDF曲线上升更加陡峭,即更好的设计空间。
随后,在e的约束条件下,作者拟合了其中最优的20个模型的width随block index增加的曲线,并在该曲线的约束下,又进一步获得了一个更小的优化了的设计空间,命名为RegNet.
ConvNeXt
ConvNeXt(2022, A ConvNet for the 2020s)通过Transformer的设计来模态CNN。在Macro design中,使用了经典的4 stage的结构,并改变了stage compute ratio,将原来ResNet-50中各stage的block数3:4:6:3改为了1:1:3:1(和Swin-T的比例一致);使用了patchify stem,将大分辨率快速降低到原图分辨率的1/4,如下图所示: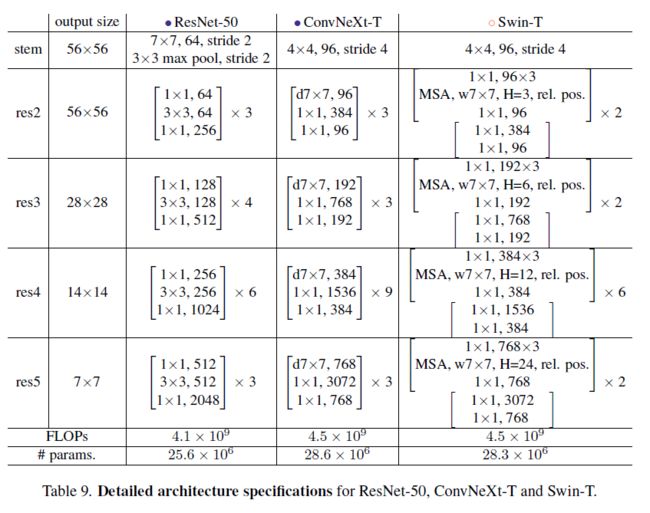
模型采用了depthwise convolution来降低计算量,但也会带来降低精度的问题,再通过增加channel数来提升模型精度。论文中将channel数增加了原ResNet-50的channel数的1/3。结果是计算量相比于原来大,精度也提升了。
使用inverted bottleneck结合large kernel size (7x7)可以提升性能,进一步增大kernel size不会进一步提升。
针对层的micro design发现,修改ReLU到GELU对性能影响不大;减少激活层,减少BN层,以及把BN层换成LN层(Layer Normalization)都会提升性能。使用单独的下采样层(2x2 kernel size, stride =2 )代替原来直接在block的conv中做下采样会提升。
3. 更多的feature融合
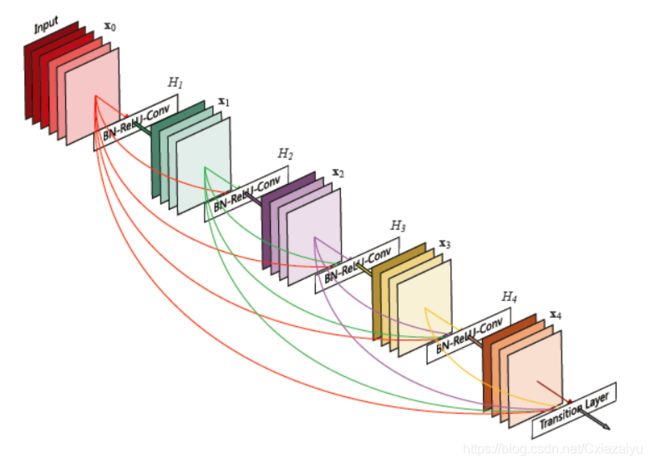
DenseNet(2017,Densely connected convolutional networks)对于一个stage(相同分辨率多层),将之前所有层作为本层的输入,与本层的feature concatenate到一起,当前层也作为后续每层的输入。与ResNet相比(Note: ResNet的skip connection是加和的),在保持相同channel数的条件下,通过concatenate可以使用更少的kernel,降低参数量;另外,通过更多的连接,可以消除梯度弥散,使得模型更容易训练。
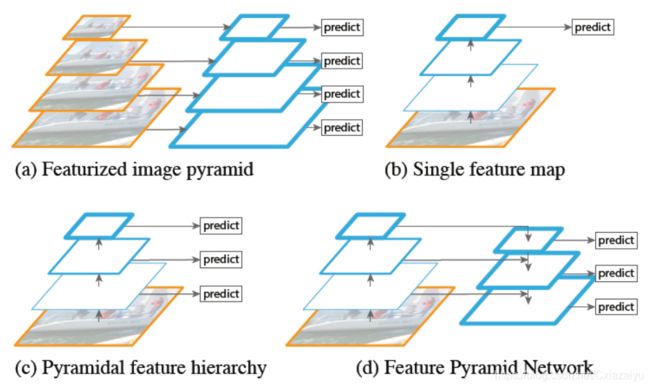
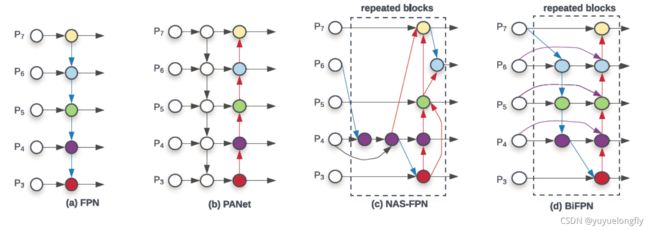
FPN (2017,Feature Pyramid Networks for Object Detection)进行多尺度feature的fusion,并在不同尺度预测结果。
DLA (2018, Deep Layer Aggregation)中把stage内部相同分辨率层的连接称为hierarchical deep aggregation(HDA),即Semantic fusion;把跨分辨率的连接称为iterative deep aggregation(IDA),即实现Spatial fusion。更深的stage更加语义清晰,但是空间分辨率更粗糙(Deeper stages are more semantic but spatially coarser)。通过Spatial fusion实现更准确地确定where,通过Semantic fusion实现更准确地确定what。DLA结合了IDA和HDA,示例连接结构如下图:
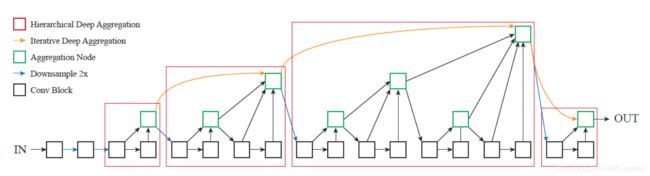
通过利用DLA思想改进ResNet-34形成的DLA-34准确率更高。
HRNet (2020, Deep high-resolution representation learning for visual recognition) 整个过程保持高分辨率,使得预测的位置更精确,同时使用低分辨率的feature来融合给高分辨率的feature使得高分辨率的feature同样做到semantically strong。

PANet(2018,Path aggregation network for instance segmentation)在FPN的Top-down pathway融合的基础上增加了Bottom-up pathway的融合,如图(b)所示。
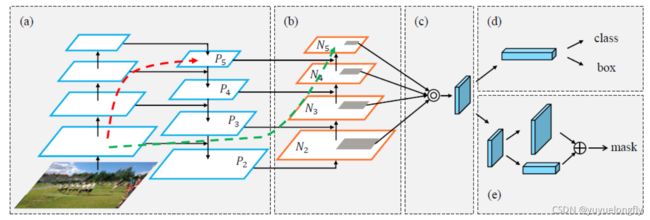
EfficientDet(2020, EfficientDet: Scalable and Efficient Object Detection)中PANet基础上进一步提出了几点改进形成weighted bi-directional feature pyramid network:1. 去除了PANet中单边输入的feature(单输入的feature没有融合,对最终效果应该贡献不大);2. 在同一stage上,增加原始输入和输出skip链接起来;3. 重复top-down和bottom-up的BiFPN模块。4. 不同尺度的feature在融合时的贡献是不同的,不应该简单地加和,所以增加可学习的权重。
三、轻量化网络
MobileNet系列
MobileNets系列中的v1,v2,v3分别在卷积基本操作(depthwise separable convolutions)、block(inverted residual)、整个网络(NAS搜索得到)三个层面对网络进行了设计和优化。
MobileNets(2017,MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications),主要创新点是使用了depthwise separable convolutions。 Input feature map: FxFxM ,Output feature map: GxGxN的问题。经典的方式是使用N个KxKxM的卷积核,即KxKxM的卷积核的每个channel与FxFxM的feature map对应的channel做卷积运算,并将结果在depthwise方向加和,从而获得输出的feature map中的一个channel;N个KxKxM的卷积核分别与输入的feature map进行这样的运算,从而获得N个channel。 运算cost为:KxKxFxFxMxN (注意,输出feature map的尺寸主要通过stride调整)。 depthwise separable convolutions,即将卷积分解为depthwise convolutions和pointwise convolution。在depthwise convolutions中,使用KxKxM的卷积核的每个channel分别与input feature map对应channel进行卷积运算,但与上面经典卷积操作不同的是,这里运算后并不将depthwise方向进行加和,所以输出的是一个channel为M的feature map。随后,使用N个1x1xM的卷积核分别与depthwise convolution获得的feature map进行运算,获得depthwise的线性加和,新的运算cost降低到:KxKxFxFxM+ FxFxMxN。
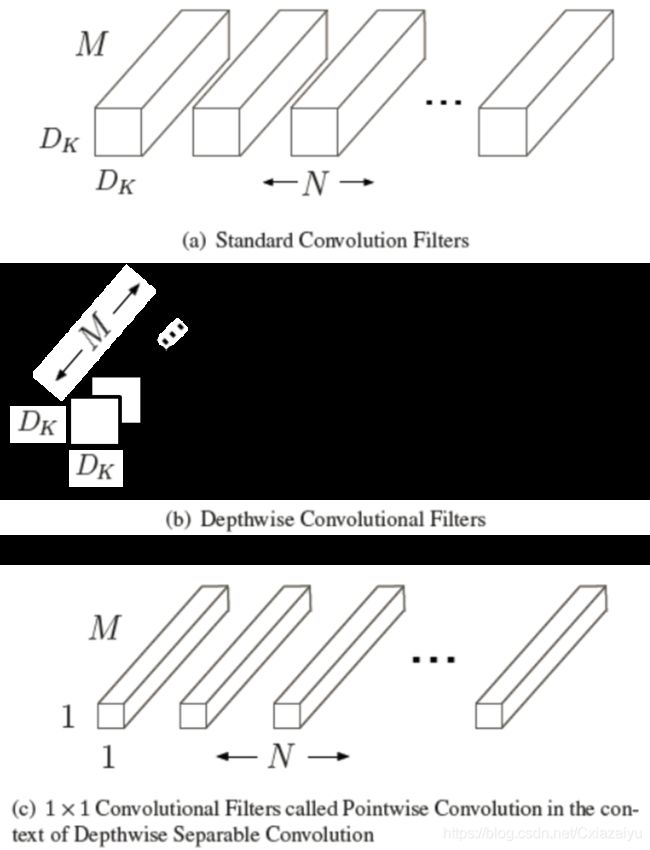
图片引自 (2017,MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications),(b)中略作修改
在基础的MobileNet上, 通过引入两个超参改变MobileNet的网络的参数,即Width Multipiler作用于中间layers的channel,获得更thinner的模型,一般取0.75, 0.5, 0.25;以及Resolution Multipiler,改变输入的resolution。
MobileNetV2(2018, MobileNetV2: Inverted Residuals and Linear Bottlenecks)中,提出了Inverted residual block的模块,其设计理念主要是在high dimension更容易进行分类,而表示feature则可以使用low dimension保留其主要分量。如下图所示,其中的卷积的厚度示意的是卷积的channel数,在Inverted residual block中先使用1x1的卷积核扩展channel数,随后在high dimension的feature map上进行3x3的depthwise seperable convolution,最后再使用1x1的卷积核将channel数压缩到输入时的channel数。(在更早的工作ResNet中是先使用1x1的卷积核压缩channel数,再在low dimension的feature map上进行3x3的常规卷积,随后再使用1x1的卷积核将channel扩展回原来的channel数。之所以要进行channel维度的压缩,是为了降低参数量和计算量。在MobileNet中由于使用了depthwise seperable convolution,已经大大降低了参数量和计算量,从性能上看反而发现设计成Inverted residual block效果更好。)即下表中t>1为inverted residual block, t<1为residual block。
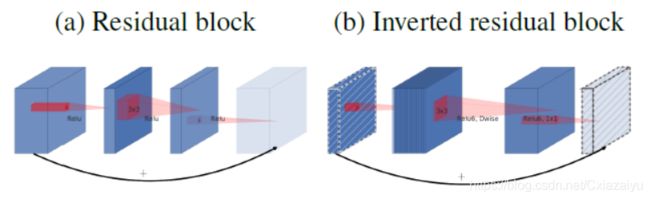

图片引自(2018, MobileNetV2: Inverted Residuals and Linear Bottlenecks)
另外,论文中提出,在最后压缩channel的1x1的卷积之后,使用linear的激活函数代替Relu,以保证feature在“投影到”low dimension时最大可能地保留原始信息。作者证明在这样的inverted residual block的设计结构在分类、目标检测、语义分割一系列任务中都表现良好。
MobileNetV3(2019,Searching for MobileNetV3)是使用network architecture search (NAS)获得了两个优化的结构,MobileNet V3-large和MobileNet V3-small。同时,对Inverted residual block增加了Squeeze-and-Excite子结构,并使用了h-swish激活层。
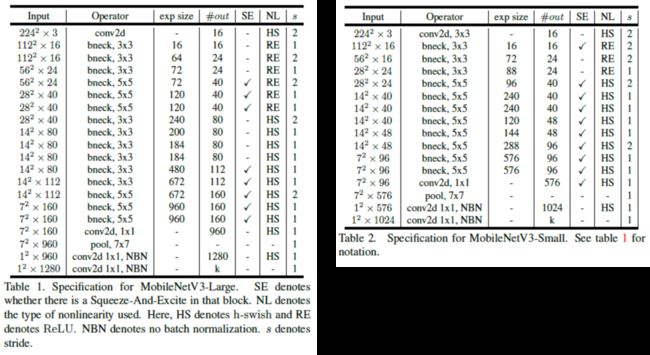
图片引自(2019,Searching for MobileNetV3)
VarGNet(2020, VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing)中考虑嵌入式部署的computing intensity,提出应该固定group convolution中的通道数而不是channel数。在ResNext中是把group数都固定在32,当不同stage的channel数增加时,分到每组里的channel数是变换的。VarGNet提出,要保持每个group的channel数固定,那么分成的group个数是随着总的channel数和固定的group的channel数变化的(group=channels/channels_per_group),这样更有利于嵌入式部部署提速。
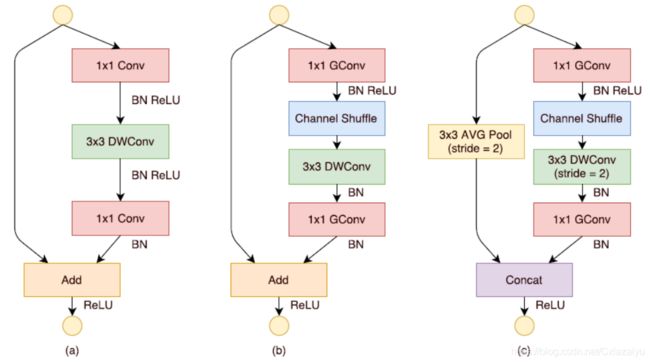
ShuffleNet
ShuffleNet (2017, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile
Devices)在通过Group convolution降低计算量的同时,通过使用channel shuffle,增加channel间信息交换,达到超过MobileNet的性能,如下图(b)和(c)所示。