python+sklearn,机器学习-线性回归实现-以披萨尺寸预测价格
实例:

思路:
简单而直观的方式是通过数据的可视化直接观察成交价格与尺寸间是否存在线性关系。
对于本实验的数据来说,散点图就可以很好的将其在二维平面中进行可视化表示。
代码
# **用matplotlib画出图形**
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.font_manager import FontProperties
font = FontProperties(r"c:\windows\fonts\msyh.ttc", size=10)
in
def runplt(size = None):
plt.figure(figsize= size)
plt.axis([0, 25, 0, 25])
plt.grid(True)
return plt
plt = runplt()
x = [[6], [8], [10], [14], [18]] # 直径
y = [[7], [9], [13], [17.5], [18]] # 价格
plt.plot(x, y, 'k.')
plt.show()
out
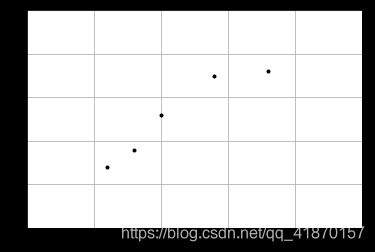
能够看出,匹萨价格与其直径正相关,这与我们的 日常经验也比较吻合,自然是越大越贵
in:
# **用scikit-learn来构建模型。**
from sklearn import linear_model
import numpy as np
# sklearn中的训练数据要求二维
# 列表不能转化为二维数组
x_train = np.array([6, 8, 10, 14, 18]).reshape(-1, 1)
y_ = np.array([7, 9, 13, 17.5, 18]).reshape(-1, 1)
# x_train = x_train.reshape(-1, 1)
model = linear_model.LinearRegression()
model.fit(x_train, y_)
display(model.intercept_) #截距
display(model.coef_) # 线性模型系数
a_ = np.array([12]).reshape(-1, 1)
a = model.predict(a_)
print("预测一张12英寸的披萨:{:.2f}".format(a[0][0]))
out
array([1.96551724])
array([[0.9762931]])
预测一张12英寸的披萨:13.68
# **画出匹萨直径与价格的线性关系。**
plt = runplt()
plt.plot(x, y, 'k.') # 'k.'黑色
X2 = [[0], [10], [14], [25]]
y2 = model.predict(X2)
# print(y2)
plt.plot(X2, y2, 'g-') # 'g_' 绿色
# x.y的点不能连成线,画出的是散点图
# x2,y2的点可以连城线,画出的是直线图
# **模型评估**
# 李航老师的统计学习方法中:将训练误差称为近似误差,将预测误差称为估计误差
# 残差预测值
yr = model.predict(x_train)
# enumerate 函数可以把一个 list 变成索引-元素对
for idx, x in enumerate(x_train):
plt.plot([x, x], [y[idx], yr[idx]], 'r_') # 'r_'红色
plt.show()

对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)
通过残差之和最小化实现最佳拟合
print('残差平方和:{:.2f}'.format(np.mean((model.predict(x_train)-y)** 2)))
out
残差平方和:1.75
调用sklearn.linear_model.LinearRegression()所需参数:
fit_intercept : 布尔型参数,表示是否计算该模型截距。可选参数。
normalize : 布尔型参数,若为True,则X在回归前进行归一化。可选参数。默认值为False。
copy_X : 布尔型参数,若为True,则X将被复制;否则将被覆盖。 可选参数。默认值为True。
n_jobs : 整型参数,表示用于计算的作业数量;若为-1,则用所有的CPU。可选参数。默认值为1。 线性回归fit函数用于拟合输入输出数据,调用形式为model.fit(X,y, sample_weight=None): • X : X为训练向量; • y : y为相对于X的目标向量; • sample_weight : 分配给各个样本的权重数组,一般不需要使用,可省略。 注意:X,y 以及model.fit()返回的值都是2-D数组,如:a= [[0]]
一元线性回归假设解释变量和响应变量之间存在线性关系;这个线性模型所构成的空间是一个超平面(hyperplane)。超平面是n维欧氏空间中余维度等于一的线性子空间,如平面中的直线、空间中的 平面等,总比包含它的空间少一维。在一元线性回归中,一个维度是响应变量,另一个维度是解释变量,总共两维。因此,其超平面只有一维,就是一条线。
上述代码中sklearn.linear_model.LinearRegression类是一个估计器(estimator)。估计 器依据观测值来预测结果。在scikit-learn里面,所有的估计器都带有fit()和predict()方 法。fit()用来分析模型参数,predict()是通过fit()算出的模型参数构成的模型,对解释变量 进行预测获得的值。因为所有的估计器都有这两种方法,所有scikit-learn很容易实验不同的模型。 截距α和系数β 是线性回归模型最关心的事情。
参考