【深度学习】——梯度下降优化算法(批量梯度下降、随机梯度下降、小批量梯度下降、Momentum、Adam)
目录
梯度
梯度下降
常用的梯度下降算法(BGD,SGD,MBGD)
梯度下降的详细算法
算法过程
批量梯度下降法(Batch Gradient Descent)
随机梯度下降法(Stochastic Gradient Descent)
小批量梯度下降法(Mini-batch Gradient Descent)
梯度下降的优化算法
存在的问题
梯度下降优化的方法
机器学习中具体梯度下降的优化算法
基于陷入局部最优的问题的优化
Momentum算法
基于学习率方面进行的梯度优化
Adam算法(Adaptive Moment Estimation)
参考:梯度下降(Gradient Descent)小结
梯度
概念:在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
意义:梯度是函数在当前位置变化最快的方向,因此可以使得损失函数很快地找到极值,损失一般是找极小值,进而用于指导训练模型中参数的更新。
梯度下降
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
具体实施:从整体来看,当点下降最快的方向不是由某一个维度的偏导决定的1,而是由所有维度的偏导共同决定的,这也符合“梯度是变化最快的方向”和“梯度是函数对所有参数求偏导后的值的向量”这两个说法。在实际实施中,我们一般是通过偏导来指导不同参数的更新,以此来做到函数值下降得最快(梯度方向)。这就是梯度下降的本质。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。

常用的梯度下降算法(BGD,SGD,MBGD)
梯度下降的详细算法
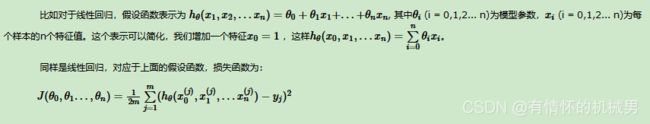
算法过程
一般有两种方法,一种迭代,一种矩阵运算,具体见:梯度下降(Gradient Descent)小结

批量梯度下降法(Batch Gradient Descent)

优点:对于准确率来说,因为使用了全部样本的梯度,所以准确率会更高
缺点:但是使用了全部样本,导致在训练速度和收敛速度上都比较慢
随机梯度下降法(Stochastic Gradient Descent)

优点:随机梯度下降就是BGD的极端,只是随机选择一个样本的梯度来指导梯度的下降,因为使用了一个样本,因此其训练速度会很快
缺点:但是非常依赖于初始值和步长的影响,有可能会陷入局部最优中,导致收敛速度慢
小批量梯度下降法(Mini-batch Gradient Descent)
在深度学习中,SGD和MBGD统称为SGD
这个梯度下降算法其实就是结合了BGD和SGD两者,采用了小批次的梯度来进行计算。

优点:分担了训练压力(小批量)、加快收敛
缺点:初始学习率难以确定、容易陷入局部最优
梯度下降的优化算法
存在的问题
BGD、SGD以及MBGD都是比较常见的梯度算法,但是都存在以下问题:
1)学习步长(学习率)难以确定,是超参数,太大导致跳过最优解,太小收敛速度慢,可能会导致陷入局部最优;
2)参数初始值的确定,不同初始值有可能会产生不同的最优解,比如初始值分别在两座山的山顶,那得到的山脚位置自然是可能不一样的;
3)样本特征值的差异性大,变化范围大
梯度下降优化的方法

机器学习中具体梯度下降的优化算法
基于陷入局部最优的问题的优化
Momentum算法
Momentum算法是在MBGD的基础上进行了修改,即在梯度方向上增加动量(Momentum),意思指在更新梯度时,会保留之前更新的梯度方向,然后利用当前批次的梯度进行微调
优点:
1)能够抑制梯度的震荡,在梯度与上次相同的时候梯度下降多一点,反之少一点
2)有可能跳出局部极值
基于学习率方面进行的梯度优化
Adam算法(Adaptive Moment Estimation)

优点:
1)每一次迭代的学习率都在依次确定的范围内 ,使得参数更新更加地稳定
2)使模型更加地收敛,适用于深层网络和较为复杂的场景
参考文献
https://blog.csdn.net/liuy9803/article/details/81780543
https://www.cnblogs.com/pinard/p/5970503.html
物体检测书籍