ICCV 2021 | Swin transformer: Hierarchical vision transformer using shifted windows 阅读笔记
Swin transformer: Hierarchical vision transformer using shifted windows
Author Unit: 1 ^1 1Microsoft Research Asia 2 ^2 2University of Science and Technology of China 3 ^3 3Xian Jiaotong University 4 ^4 4Tsinghua University
Authors: Ze Liu 1 , 2 † ∗ ^{1,2†*} 1,2†∗ Yutong Lin 1 , 3 † ∗ ^{1,3†*} 1,3†∗ Yue Cao 1 ∗ ^{1*} 1∗ Han Hu 1 ∗ ‡ ^{1*‡} 1∗‡ Yixuan Wei 1 , 4 † ^{1,4†} 1,4† Zheng Zhang 1 ^1 1 Stephen Lin 1 ^1 1 Baining Guo 1 ^1 1
Code: https://github.com/microsoft/Swin-Transformer
Conference: ICCV 2021
Paper address: https://openaccess.thecvf.com/content/ICCV2021/html/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.html
以下是根据李沐团队做的视频写的笔记 https://www.bilibili.com/video/BV13L4y1475U?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=9a9f9a00848a88972d0fcfd341e9e738
Swin Transformer 主要是想让 ViT 像卷积神经网络一样,也能够分成几个 block,也能做层级式的特征提取,从而导致提取出来的特征具有多尺度的概念。
Abstract
将 Transformer 从语言适应到视觉的挑战主要有两个方面,一是视觉实体的规模变化很大( 相同语义的物体在不同图片中可能会有较大的变化 ,nlp中就不会存在这一点),以及与文本中的单词相比,图像中像素的高分辨率( 这个主要是计算代价 )。为了解决这些差异,我们提出了一种分层 Transformer,其表征是用 Shifted windows (Swin)计算的。移位窗口方案通过将 self-attention 计算限制在不重叠的局部窗口上,同时还允许跨窗口连接 cross-window connection,从而带来更高的效率。这种分层架构具有在各种尺度上建模的灵活性,并且具有相对于图像大小的线性计算复杂度。
这种使用 shifted windows 的方式降低了计算量(因为是局部窗口),并且可以 cross-window connection,从而变相达到全局建模。
1. Introduction
Swin Transformer 借鉴了很多卷积神经网络的先验知识。如图1所示,ViT是只在单一尺度上对图像进行下采样然后处理,但是很多工作例如图像分割中的U-Net使用skip-connection做到不同尺度特征的补偿,图像检测中FPN就说分层式的网络每个卷积层出来特征的感受野是不一样的,可以抓住物体不同尺寸的特征,于是Swin也采用了分层式(Swin采用了类似于pooling的操作来模拟了不同卷积层特征所代表的不同感受野,就是 patch merging,这样下一层的 patch 就能看到上一层中多个 patch 的内容);同时ViT的复杂度是会随着图像尺寸的平方级进行增长的(因为始终都是在整张图像上进行自注意力计算),而Swin的方式就可以做到线性增长(因为是在小窗口内做自注意力计算,图像尺寸增加,也就对应着窗口的增加;之所以采用小窗口,也是因为图像中语义相同的物体,大概率还是相邻的,所以够用了,整张图像计算注意力是有点浪费了)。
根据以上的特点,所以作者说 Swin 不仅能够做分类任务,还能做密集型的预测任务,例如检测或分割,故 Swin 是一种更通用的骨干网络。

还有一个关键的操作就是使用 shifted window,如图2所示。在 l+1 层中 window 的格式是 l 层 window 向右上方滑动了两个 patch 的结果(示例,实际上并不一定是这个比例) ,而且 l+1 层获得的 patch 是由 l 层计算得来的,这样就能做到 cross-window connection 的效果,而不只是在固定的 window 中做 self-attention,再加上 patch merging 的操作,到后面的层中就能达到全局建模的目的,而且还省内存省计算量。 太妙了!!!
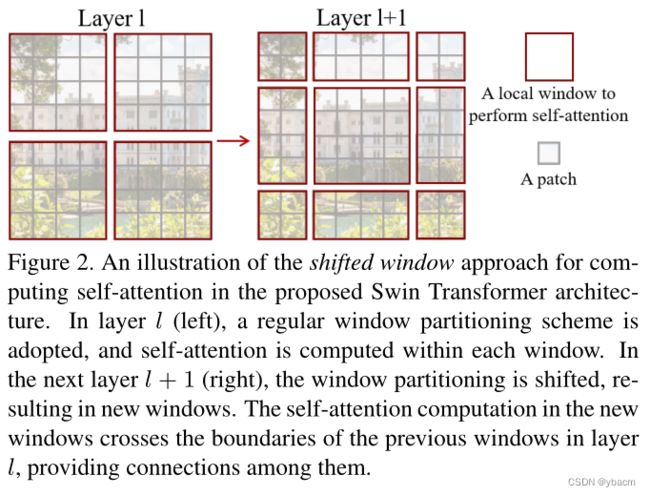
2. Related Work
与 ViT 差不多
3. Method
3.1. Overall Architecture
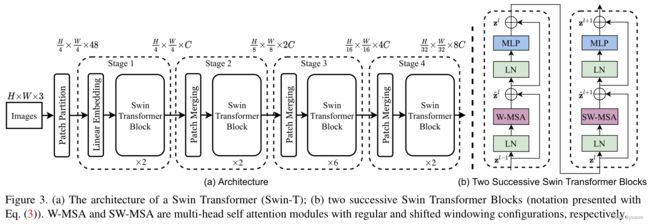
这个网络前向过程强烈建议看视频(时间是20:30~29:00),老师讲的很清晰。
Swin Transformer 有四个 stage,有类似于池化的 patch merging 操作,它的自注意力还是在小窗口之内做的,最后用的是 global average pooling。所以说 Swin 真的是把卷积网络和 Transformer 两个系列的工作完美的结合到了一起。
3.2. Shifted Window based Self-Attention
Self-attention in non-overlapped windows 具体的复杂度分析请听老师讲(31:10~34:50),结论是在以下两个公式中,第一项是一样的,但是第二项的计算量上 Swin 要比 ViT 少了几十甚至上百倍。

Shifted window partitioning in successive blocks 这里达到 cross-window connection 的方式就是图2所示的那样,所以 如图3(b)中所示的两个 block 连在一起形成了 Swin 中的一个计算单元,这也解释了为什么 swin transformer block 的数量都是偶数个。
Efficient batch computation for shifted configuration

具体看视频 35:00~51:00
作者说将窗口移动后会得到9个window,这样会导致计算量增长,而且window大小也都不一样了,为了解决这个问题,作者不是移动窗口,而是将patch进行移动,如图4表示。但是这样移动patch之后,又会出现不连续patch之间的注意力计算的情况,这不是我们想要的,也不应该出现非连续patch之间注意力的计算(例如图像上方是天空,下方是陆地,两者就没什么关系),所以作者又提出一种mask的机制,将非连续patch的自注意力计算给屏蔽掉,只保留连续patch之间的自注意力计算。最后再将patch转移回去,要不然会出现特征破坏的情况。
太巧妙了!
3.3. Architecture Variants
为了进行更加公平的对比(而不是一味的增大模型来提升指标),作者提出了四个变体。
4. Experiments
这个实验太丰富了。。
5. Conclusion
大佬写的文章就是不一样,不仅是精确度的提升,更多的是对 CNN 和 NLP 两个领域的思考。
听完大佬讲解完其他大佬的视频,感觉又受到了一次精神洗礼,但突然又有点悲伤,因为自己是想不出来这种思路的,也没有财力做到。
继续努力吧,做力所能及的事。