图像描述文献阅读(1)Comprehending and Ordering Semantics for Image Captioning

1. 摘要
理解图像中丰富的语义并按语言顺序排序,对于为图像标题编写一个有视觉基础的、语言上连贯的描述至关重要。现代技术通常利用预先训练好的物体检测器/分类器来挖掘图像中的语义,而对语义的内在语言排序却没有充分开发。在本文中,作者基于Transformer提出了一种新方法COS-Net,将语义理解和排序过程统一到新的框架内。首先利用一个跨模态的检索模型搜索每个图像相关的句子,并将搜索到的句子中的所用单词作为主要语义线索。接下来,我们设计了一个新的语义编译器来过滤掉主要语义线索中的不相关的语义词,同时推断出图像中缺少的相关语义词的视觉基础。然后,我们将所有筛选和丰富的语义词输入到一个语义排名器中,该排名器学习像人类一样按照语言顺序分配所有语义词。这种有序的语义词序列与图像的视觉标记进一步整合,从而触发句子生成。这种有序的语义词序列与图像的视觉标记进一步整合,从而触发句子生成。
2. 概述

文章主要出发点是将语义理解和词汇排列统一到一个框架内,使其能够被共同优化,以更好地对句子进行解码,其主要过程如下:
- 首先将现成的CLIP作为跨模式检索模型,为输入图像检索语义相似的句子,如上图b的情况所示。
- 其次,基于CLIP中图像编码器输出网格特征,利用视觉编码器通过自注意机制将每个网格特征上下文编码为视觉标记。
- 语义理解器(semantic comprehender)以初级语义线索和视觉表征为输入,过滤掉初级语义线索中不相关的语义词(例如过滤掉Woman,walking),同时通过交叉注意机制重建缺失的相关语义词(如lot cow等)
- 语义排序器(semantic ranker)通过更新每个语义词的编码,使其在语言学上的位置得到估计,从而学会将所有精炼的语义词分配到合适的顺序。
- 最后,视觉标记和有序语义词都通过注意力机制动态地整合起来,从而对输出句子进行逐字解码(encode)。
总结来讲,COS-Net利用transformer风格构造了大多数模块(如visual encoder, sentence decoder, and semantic comprehender),所以可以认为是基于transformer的编码器-解码器方案。
3. 方法细节
总体来讲,该方法主要有视觉内容编码;语义理解;语义排序和句子解码四部分组成。实现如图1所示: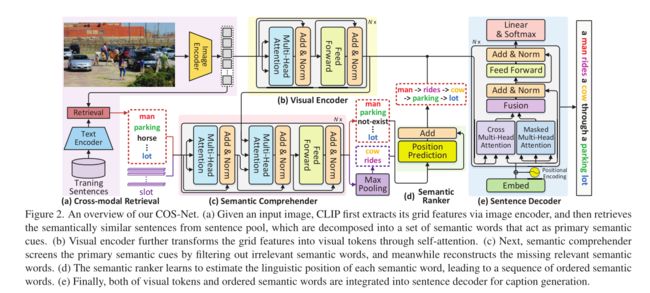
3.1 视觉内容编码
作者利用多个堆叠的Transformer,将是视觉内容编码为中间视觉标记。输入图像为 I I I,作者利用CLIP提取图像的网格特 V I = v i ∣ i = 1 N I \mathcal{V}_I=\left.\mathbf{v}_i\right|_{i=1} ^{N_I} VI=vi∣i=1NI,其中 N I N_I NI 是网格数,并结合全局的特征 v c v_c vc,然后我们将全局特征和网格特征转化为新的嵌入空间( embedding space),然后级联得到 V I ( 0 ) = [ v c ( 0 ) , v i ( 0 ) ∣ i = 1 N I ] \mathcal{V}_I^{(0)}=\left[\mathbf{v}_c^{(0)},\left.\mathbf{v}_i^{(0)}\right|_{i=1} ^{N_I}\right] VI(0)=[vc(0),vi(0)∣ ∣i=1NI],然后利用视觉编码器对得到的全局和网格特征 V I ( 0 ) \mathcal{V}_I^{(0)} VI(0) 进行上下文的编码,从而得到丰富的视觉标记 V I ( N v ) = [ v c ( N v ) , v i ( N v ) ∣ i = 1 N I ] \mathcal{V}_I^{\left(N_v\right)}=\left[\mathbf{v}_c^{\left(N_v\right)},\left.\mathbf{v}_i^{\left(N_v\right)}\right|_{i=1} ^{N_I}\right] VI(Nv)=[vc(Nv),vi(Nv)∣ ∣i=1NI],具体说作者是通过多个 N v N_v Nv Transformer blocks和多头注意力机制形成的。以第 i i i 个Transformer block为例,操作过程如下(公式1):
V I ( i + 1 ) = F ( norm ( V I ( i ) + MultiHead ( V I ( i ) , V I ( i ) , V I ( i ) ) ) ) MultiHead I ( Q , K , V ) = Concat ( h e a d 1 , … , head h ) W O head i = Attention ( Q W i Q , K W i K , V W i V ) Attention ( Q , K , V ) = softmax ( Q K T d ) V \begin{aligned} &\mathcal{V}_I^{(i+1)}=\mathcal{F}\left(\operatorname{norm}\left(\mathcal{V}_I^{(i)}+\operatorname{MultiHead}\left(\mathcal{V}_I^{(i)}, \mathcal{V}_I^{(i)}, \mathcal{V}_I^{(i)}\right)\right)\right) \\ &\text { MultiHead }_I(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{Concat}\left(h e a d_1, \ldots, \text { head }{ }_h\right) W^O \\ &\text { head }_i=\operatorname{Attention}\left(\mathbf{Q} W_i^Q, \mathbf{K} W_i^K, \mathbf{V} W_i^V\right) \\ &\text { Attention }(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{softmax}\left(\frac{\mathbf{Q} \mathbf{K}^T}{\sqrt{d}}\right) \mathbf{V} \end{aligned} VI(i+1)=F(norm(VI(i)+MultiHead(VI(i),VI(i),VI(i)))) MultiHead I(Q,K,V)=Concat(head1,…, head h)WO head i=Attention(QWiQ,KWiK,VWiV) Attention (Q,K,V)=softmax(dQKT)V 其中 F \mathcal{F} F 代表前向传播层, norm \operatorname{norm} norm 代表了层归一化, W i Q , W i K , W i V , W O W_i^Q, W_i^K, W_i^V, W^O WiQ,WiK,WiV,WO 是权重标准, d d d 为缩放因子。同时,为了使层间全局特性交互,我们额外连接了来自所有Transformer块的输出全局特性,这些输出全局特性进一步转换为整体全局特性:
v ~ c = W c [ v c ( 0 ) , v c ( 1 ) , … , v c ( N v ) ] \tilde{\mathbf{v}}_c=W_c\left[\mathbf{v}_c^{(0)}, \mathbf{v}_c^{(1)}, \ldots, \mathbf{v}_c^{\left(N_v\right)}\right] v~c=Wc[vc(0),vc(1),…,vc(Nv)] W c W_c Wc 是权重矩阵,最后将视觉编码器编码的网格特征与全局特征 v ~ \tilde{\mathbf{v}} v~ 相结合,我们获得了最终的输出视觉标记 V ~ I = [ v ~ c , v i ( N v ) ∣ i = 1 N I ] \tilde{\mathcal{V}}_I=\left[\tilde{\mathbf{v}}_c,\left.\mathbf{v}_i^{\left(N_v\right)}\right|_{i=1} ^{N_I}\right] V~I=[v~c,vi(Nv)∣ ∣i=1NI]
3.2 语义理解
为了解当前图像生成字幕,主要依赖于预定义的语义/类别标签的限制,这使得难以自适应地调整对象检测器/分类器来更好地强调输出句子中值得提及的显著语义。本研究,作者提出利用不同和大规模数据训练的现成CLIP作为一种强大的跨模态检索模型,它直接积累更多的语义候选词,这些词往往在视觉上相似的图像中被提及。本文基于跨模态检索挖掘到的主要语义线索,设计了一种新的语义理解器,它可以筛选出不相关的语义词,同时推断缺失的相关语义词,实现全面、准确的语义理解。
作者利用跨模态检索模型(CLIP)为每个输入图像在训练句子池中搜索语义相关的句子。 v c v_c vc 和 s c s_c sc 是CLIP在输入图像 I I I 和句子 S S S 时图像编码器(image encoder)和文本编码器(image encoder)输出的视觉特征和文本特征。作者通过输入图像 I I I 进行搜索查询,并在检索到K个最相关的句子 S r = { S r 1 , S r 2 , … , S r K } \mathcal{S}_{r}=\left\{\mathcal{S}_{r_1}, \mathcal{S}_{r_2}, \ldots, \mathcal{S}_{r_K}\right\} Sr={Sr1,Sr2,…,SrK},公式实现如下:
Similarity ( I , S r k ) = v c ⋅ s r k c ∥ v c ∥ ∥ s r k c ∥ \operatorname{Similarity}\left(I, \mathcal{S}_{r_k}\right)=\frac{\mathbf{v}_c \cdot \mathbf{s}_{r_k}^c}{\left\|\mathbf{v}_c\right\|\left\|\mathbf{s}_{r_k}^c\right\|} Similarity(I,Srk)=∥vc∥∥ ∥srkc∥ ∥vc⋅srkc 其中,其中 s r k c \mathbf{s}_{r_k}^c srkc 是标题 s r k \mathbf{s}_{r_k} srk 的文本特征。在获得k个标题之后,去掉停止词,将其分解 V s = s i ∣ i = 1 N r \mathcal{V}_s=\left.\mathbf{s}_i\right|_{i=1} ^{N_r} Vs=si∣i=1Nr 个语义单词。
文章将语义的筛选和丰富的过程公式化为一个集合预测的问题,该问题将主要语义线索 V s = s i ∣ i = 1 N r \mathcal{V}_s=\left.\mathbf{s}_i\right|_{i=1} ^{N_r} Vs=si∣i=1Nr 转化为以视觉标记 V ~ I \tilde{\mathcal{V}}_I V~I 为条件的精炼语义预测。为了,能够重建缺失的关键词,作者用附加的参数语义查询(即一组 O = o i ( 0 ) ∣ i = 1 N o \mathcal{O}=\left.\mathbf{o}_i^{(0)}\right|_{i=1} ^{N_o} O=oi(0)∣ ∣i=1No)来增加主要语义线索 V ~ I \tilde{\mathcal{V}}_I V~I 的输入,其目的是为了丰富语义词的集合预测。这里作者堆叠了 N s N_s Ns 个 Transformer blocks。每个block自注意机制对输入的每一个语义词(即语义标记)进行上下文编码,并通过利用它们与 V ~ I \tilde{\mathcal{V}}_I V~I 之间的交互来进一步增强语义标记,其流程表述如下:
V s ( i + 1 ) = F ( norm ( V s ′ + MultiHead ( V s ′ , V ~ I , V ~ I ) ) ) V s ′ = norm ( V s ( i ) + MultiHead ( V s ( i ) , V s ( i ) , V s ( i ) ) ) \begin{aligned} \mathcal{V}_s^{(i+1)} &=\mathcal{F}\left(\operatorname{norm}\left(\mathcal{V}_s^{\prime}+\operatorname{MultiHead}\left(\mathcal{V}_s^{\prime}, \tilde{\mathcal{V}}_I, \tilde{\mathcal{V}}_I\right)\right)\right) \\ \mathcal{V}_s^{\prime} &=\operatorname{norm}\left(\mathcal{V}_s^{(i)}+\operatorname{MultiHead}\left(\mathcal{V}_s^{(i)}, \mathcal{V}_s^{(i)}, \mathcal{V}_s^{(i)}\right)\right) \end{aligned} Vs(i+1)Vs′=F(norm(Vs′+MultiHead(Vs′,V~I,V~I)))=norm(Vs(i)+MultiHead(Vs(i),Vs(i),Vs(i)))
其中 V s ( i + 1 ) \mathcal{V}_s^{(i+1)} Vs(i+1) 表示第 i i i 个Transformer block的输出增强语义标记。因此,最终输出语义理解器的语义标记记为 V s ( N s ) = [ O i ( N s ) ∣ i = 1 N o , s i ( N s ) ∣ i = 1 N r ] \mathcal{V}_s^{\left(N_s\right)}=\left[\left.\mathbf{O}_i^{\left(N_s\right)}\right|_{i=1} ^{N_o},\left.\mathbf{s}_i^{\left(N_s\right)}\right|_{i=1} ^{N_r}\right] Vs(Ns)=[Oi(Ns)∣ ∣i=1No,si(Ns)∣ ∣i=1Nr],用于预测精炼和重构的语义单词。
在训练时,作者引入了一个代理目标,主要是过滤掉主要语义词中不相关的语义词并重建缺乏的相关语义词,进而优化语义理解器。作者将这个问题表述为单标签和多标签分类组合问题。以语义理解器 V s ( N s ) = [ O i ( N s ) ∣ i = 1 N o , s i ( N s ) ∣ i = 1 N r ] \mathcal{V}_s^{\left(N_s\right)}=\left[\left.\mathbf{O}_i^{\left(N_s\right)}\right|_{i=1} ^{N_o},\left.\mathbf{s}_i^{\left(N_s\right)}\right|_{i=1} ^{N_r}\right] Vs(Ns)=[Oi(Ns)∣ ∣i=1No,si(Ns)∣ ∣i=1Nr] 的输出语义标记为条件,利用预测层来估计每个语义标记在整个语义词汇上的概率分布,从而产生语义预测 P s = [ P o i ∣ i = 1 N o , P s i ∣ i = 1 N r ] \mathcal{P}_s=\left[\left.P_{o_i}\right|_{i=1}^{N_o},\left.P_{s_i}\right|_{i=1} ^{N_r}\right] Ps=[Poi∣i=1No,Psi∣i=1Nr]。需要说明的是语义词汇是由训练集 N c N_c Nc 个语义词,加上一个表示表示无关语义词的特殊标记构成的。所以,用于预测主要语义线索中第 i i i 个语义标记 P s i P_{s_i} Psi 的ground-truth标签记为 y i ∈ R N c + 1 y_i \in \mathbb{R}^{N_c+1} yi∈RNc+1。这样,基于 P s i ∣ i = 1 N r \left.P_{s_i}\right|_{i=1} ^{N_r} Psi∣i=1Nr,我们将过滤主要语义线索中无关语义词的过程作为单标签分类任务,其目标用交叉熵损失来衡量:
L x = − 1 N r ∑ i = 1 N r ∑ c = 1 N c + 1 y i c log P s i c \mathcal{L}_x=-\frac{1}{N_r} \sum_{i=1}^{N_r} \sum_{c=1}^{N_c+1}y_i^c \log P_{s_i}^c Lx=−Nr1i=1∑Nrc=1∑Nc+1yiclogPsic 其中 y i c y_i^c yic 和 P s i c P_{s_i}^c Psic 分别表示 y i y_i yi 和 P s i P_{s_i} Psi 的第 c c c 个元素。同时,将缺失相关语义词的推断过程视为多标签分类的任务。具体而言,在用 s i g m o i d sigmoid sigmoid 激活对参数语义查询的预测 P o i ∣ i = 1 N o \left.P_{o_i}\right|_{i=1} ^{N_o} Poi∣i=1No 进行归一化之后,对它们执行最大池化以实现语义词汇上的整体概率分布 P ~ o \tilde{P}_o P~o,因此,多标签分类的目标是用非对称损失计算的:
L m = asym ( P ~ o , y m ) \mathcal{L}_m=\operatorname{asym}\left(\tilde{P}_o, \mathbf{y}_m\right) Lm=asym(P~o,ym)
其中, asym \operatorname{asym} asym 表示不对称损失, y m \mathbf{y}_m ym 是所有缺失的相关语义词的基本事实标签。最终这两个损失加起来联合优化:
L s = L x + L m \mathcal{L}_s=\mathcal{L}_x+\mathcal{L}_m Ls=Lx+Lm
3.3 语义排序
在从语义理解器获得经过筛选和丰富的语义之后,最典型的生成描述的方式是将它们直接送入基于RNN/Transformer 的句子解码器进行句子建模。但是作者认为,这种方式过度依赖语言的先验,可能会由于对象幻觉现象而导致语义词的不存在。为了解决这个问题,他们引入了一个新的语义排序器模块(Semantic Ordering),它可以学习估计每个语义词的语言位置,从而按照人类的语言顺序分配所有语义词。通过这种方式,有序语义词的输出序列作为额外的视觉基础语言先验,鼓励生成相关且连贯的描述。
作者提出了Semantic Ordering是利用注意力机制来动态地推断每个语义词的语言位置。形式上,我们首先初始化一组 D D D 维位置编码 V p ∈ R N p × D \mathcal{V}_p \in \mathbb{R}^{N_p \times D} Vp∈RNp×D,描绘出序列中的所有语言顺序,其中 N p N_p Np 是语义词序列的最大长度。接下来,对于每个语义词(例如, V s ( N s ) \mathcal{V}_s^{\left(N_s\right)} Vs(Ns) 中的第 i i i 个语义token v ~ s i \tilde{v}_{s_i} v~si),我们测量它在所有位置编码 V p \mathcal{V}_p Vp 上的注意力分布,然后通过聚集所有带有注意力的位置编码计算它的参与位置编码:
p i = soft max ( v ~ s i V p T ) V p p_i=\operatorname{soft} \max \left(\tilde{v}_{s_i} \mathcal{V}_p^T\right) \mathcal{V}_p pi=softmax(v~siVpT)Vp
这里,所关注的位置编码 p i p_i pi 可以被解释为对语义单词序列中的每个语义标记 v ~ s i \tilde{v}_{s_i} v~si 的语言顺序的“软”估计。此后,我们用估计的语言顺序更新每个语义标记,从而得到位置感知语义标记:
v ~ s i p = v ~ s i + p i \tilde{v}_{s_i}^p=\tilde{v}_{s_i}+p_i v~sip=v~si+pi
因此,语义排序器产生一组位置感知语义标记 V ~ s = { v ~ s 1 p , v ~ s 2 p , … , v ~ s N o + N r p } \tilde{\mathcal{V}}_s=\left\{\tilde{v}_{s_1}^p, \tilde{v}_{s_2}^p, \ldots, \tilde{v}_{s_{N_o+N_r}}^p\right\} V~s={v~s1p,v~s2p,…,v~sNo+Nrp} 表示有序语义词的序列。
3.4 句子解码
使用来自视觉编码器的丰富的视觉标记 V i ~ \tilde{\mathcal{V}_{i}} Vi~ 和来自语义排序器的位置感知语义标记 V s ~ \tilde{\mathcal{V}_{s}} Vs~,然后我们讨论如何将它们集成到基于transformer的解码器中以生成句子。形式化地,设 S = { w 0 , w 1 , … , w T − 1 } \mathcal{S}=\left\{w_0, w_1, \ldots, w_{T-1}\right\} S={w0,w1,…,wT−1} 表示描述输入图像 I I I 的文本句子( T T T 为单词数目)。每个单词被表示为“one-hot”向量,通过权重矩阵被进一步转化为 D D D 维的文本特征 H 0 : T − 1 ( 0 ) = { h 0 ( 0 ) , h 1 ( 0 ) , … , h T − 1 ( 0 ) } H_{0: T-1}^{(0)}=\left\{h_0^{(0)}, h_1^{(0)}, \ldots, h_{T-1}^{(0)}\right\} H0:T−1(0)={h0(0),h1(0),…,hT−1(0)},一般来说,句子解码器将每个单词作为输入,并根据丰富的视觉标记 V i ~ \tilde{\mathcal{V}_{i}} Vi~ 和位置感知语义标记 V s ~ \tilde{\mathcal{V}_{s}} Vs~,自回归预测下一个单词。作者采用 N d N_d Nd 个Transformer block实现解码,每个Transformer block由一个屏蔽多头注意层和一个交叉多头注意层组成,前者用于建模先前生成的单词的整体文本上下文,后者集成了视觉和语义标记以触发句子生成。具体来说,在第 t t t 个解码时间步,第 i i i 个块中的屏蔽多头意层对先前输出隐藏状态 h t ( i ) h_t^{(i)} ht(i) 的查询,对先前生成的单词进行自我关注,从而得到整体文本上下文 h t ′ ( i ) h_t^{\prime(i)} ht′(i):
h t ′ ( i ) = MultiHead ( h t ( i ) , H 0 : t ( i ) , H 0 : t ( i ) ) h_t^{\prime(i)}=\operatorname{MultiHead}\left(h_t^{(i)}, H_{0: t}^{(i)}, H_{0: t}^{(i)}\right) ht′(i)=MultiHead(ht(i),H0:t(i),H0:t(i))
之后,使用交叉多头注意层对依赖于同一查询(即 h t ( i ) h_t^{(i)} ht(i))的视觉标记 V i ~ \tilde{\mathcal{V}_{i}} Vi~ 和语义标记 V s ~ \tilde{\mathcal{V}_{s}} Vs~ 分别进行交叉注意,产生整体视觉上下文 h t v ( i ) h_t^{v(i)} htv(i):
h t v ( i ) = MultiHead ( h t ( i ) , V ~ I , V ~ I ) + MultiHead ( h t ( i ) , V ~ s , V ~ s ) h_t^{v(i)}=\operatorname{MultiHead}\left(h_t^{(i)}, \tilde{\mathcal{V}}_I, \tilde{\mathcal{V}}_I\right)+\operatorname{MultiHead}\left(h_t^{(i)}, \tilde{\mathcal{V}}_s, \tilde{\mathcal{V}}_s\right) htv(i)=MultiHead(ht(i),V~I,V~I)+MultiHead(ht(i),V~s,V~s)
接下来,使用 s i g m o i d sigmoid sigmoid 门函数融合整体文本上下 h t ′ ( i ) h_t^{\prime(i)} ht′(i) 和视觉上下文 h t v ( i ) h_t^{v(i)} htv(i),将学习到的隐藏状态 h t ( i + 1 ) h_t^{(i+1)} ht(i+1) 作为第 i i i 个块的输出:
h t ( i + 1 ) = F ( norm ( h t ( i ) + ( g ∗ h t ′ ( i ) + ( 1 − g ) ∗ h t v ( i ) ) ) ) g = Sigmoid ( W g [ h t v ( i ) , h t ′ ( i ) ] ) \begin{aligned} &h_t^{(i+1)}=\mathcal{F}\left(\operatorname{norm}\left(h_t^{(i)}+\left(g * h_t^{\prime(i)}+(1-g) * h_t^{v(i)}\right)\right)\right) \\ &g=\operatorname{Sigmoid}\left(W_g\left[h_t^{v(i)}, h_t^{\prime(i)}\right]\right) \end{aligned} ht(i+1)=F(norm(ht(i)+(g∗ht′(i)+(1−g)∗htv(i))))g=Sigmoid(Wg[htv(i),ht′(i)])
最后,利用最后一个块 h t ( N d ) h_t^{\left(N_d\right)} ht(Nd) 的输出隐藏状态,通过softmax预测下一个单词 w t + 1 w_{t+1} wt+1。
3.5 总体目标
文章的优化损失主要包括,前文的用于语义理解的损失 L s L_s Ls 和典型的交叉熵损失 L X E L_{X E} LXE,所以最终优化的总体目标为 L = L s + L X E \mathcal{L}=\mathcal{L}_s+\mathcal{L}_{X E} L=Ls+LXE。
4. 实验部分
作者首先进行了消融实验证明设计模块的有效性。

与其他sota方法的对比
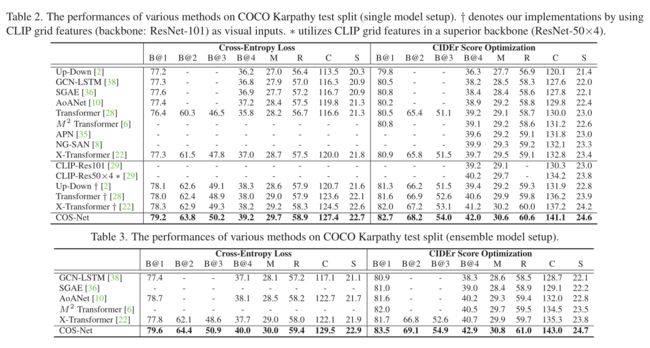
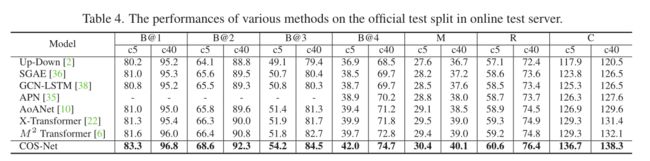


参考论文:Comprehending and Ordering Semantics for Image Captioning
声明:论文为京东探索研究院发表于2022CVPR会议,代码已经公开,此文是论文阅读的自我总结,用于自我提升,版权归原作所有。