【Stochastic Depth】《Deep Networks with Stochastic Depth》

ECCV-2016
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Deep Networks with Stochastic Depth
- 5 Experiments
-
- 5.1 Datasets
- 5.2 Results
- 6 Conclusion(own)
1 Background and Motivation
网络做深了,看起来拟合能力增强了,实际,面临着如下的困境
- vanishing gradients in backward propagation
- diminishing feature reuse in forward propagation(loss in
information flow,跑到后面前面的信息贡献就很少了) - long training time
效果可能还不如浅网络
作者提出了 deep networks with stochastic depth(can be interpreted as an implicit ensemble of networks of different depths)
as a regularizer, short train,deep test
让网络可以做的很深,也能释放出深网络的拟合能力
2 Related Work
略
3 Advantages / Contributions
It reduces training time substantially and improves the test errors on almost all data sets significantly (CIFAR-10, CIFAR-100, SVHN).
4 Deep Networks with Stochastic Depth
short (in expectation) during training and deep during testing
哈哈哈,后面的工作追求的都是训练 deep and 测试 short
(1)ResNet architecture
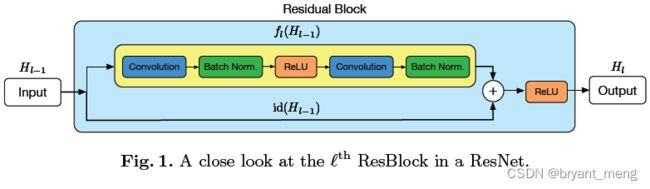
先看看正常的残差模块
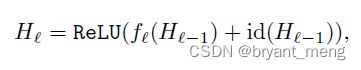
-
l l l 是 Residual Block 的索引
-
f l f_l fl 是系列操作(Conv-BN-ReLU-Conv-BN)
-
H l H_l Hl 是 Block l l l 的输出
-
id 表示 identity transformation
(2)Stochastic depth
再看看 Stochastic depth 是怎么实现的
randomly altered for each minibatch(每次迭代深度都不一样)
具体如下公式所示
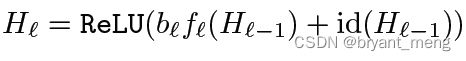
区别在于多了个系数 b l b_l bl
b l ∈ { 0 , 1 } b_l \in \{0,1\} bl∈{0,1} is a Bernoulli random variable
很形象,每个 block 要么不激活系数为 0,要么激活系数为 1
当 b l = 0 b_l = 0 bl=0 的时候,上述公式退化为了
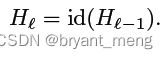
为啥 ReLU 也省了,因为前一层有 ReLU 保证了输入 is always non-negative
(3)The survival probability
知道了随机深度的形式,那么每个 block 随机的概率是多少呢?
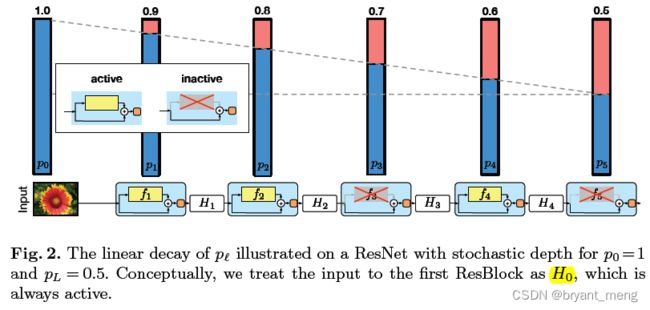
作者介绍了两种形式
第一种是均匀分布的形式
p l = p L p_l = p_L pl=pL
uniformly for all l l l
第一层到最后一层 L L L 层的 survival probability 概率都是一样的,都为 p l p_l pl
也即图 2 的水平虚线
第二种是线性递减的形式(linear decay rule)
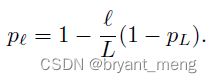
概率从第一个 block 的 1 递减到最后一个 block 的 P L P_L PL,作者实验中 P L P_L PL 都设置成了 0.5
概率的变化如图 2 中倾斜虚线所示
作者设计成概率递减的原因为
earlier layers extract low-level features that will be used by later layers and should therefore be more reliably present.
(4)Expected network depth
知道了每个 block 的概率,我们可以计算出随机深度网络的深度期望,公式如下
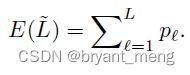
比较简单粗暴,更完整的公式应该 p l p_l pl 后面乘个 1,哈哈
把 p l p_l pl 代入可以堆出
E ( L ~ ) = ( 3 L − 1 ) / 4 ≈ 3 L / 4 E(\widetilde{L}) = (3L-1)/4 \approx 3L / 4 E(L )=(3L−1)/4≈3L/4
注意: p L p_L pL 计算时候的值为 0.5,此时深度能随机掉 25%
此时,ResNet110(L = 54),采用了随机深度训练方式后,深度的期望约为 54 x 3/4 ≈ 40 个 Blcok
(5)Training time savings
由上述公式推导,深度能随机掉 25%,
训练时间的话,作者给出的结论是 approximately 25% of training time could be saved under the linear decay rule with p L p_L pL = 0.5
实验结果也趋向于这个数字
(6)Implicit model ensemble
training with stochastic depth can be viewed as training such an ensemble
implicitly in a single training effort
(7)Stochastic depth during testing
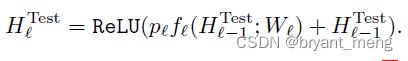
测试的时候也要 weighted by its survival probability,这和 drop out 是一样的
5 Experiments
5.1 Datasets
CIFAR-10, CIFAR-100, SVHN
5.2 Results
(1)CIFAR-10 / CIFAR-100 / SVHN
看看在小数据集上的表现
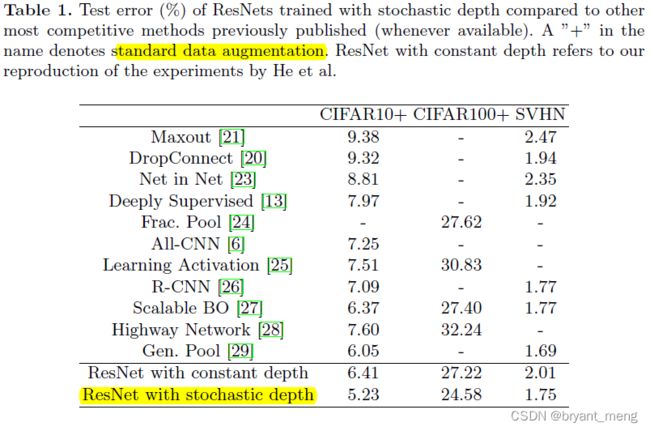
整体还是不错的
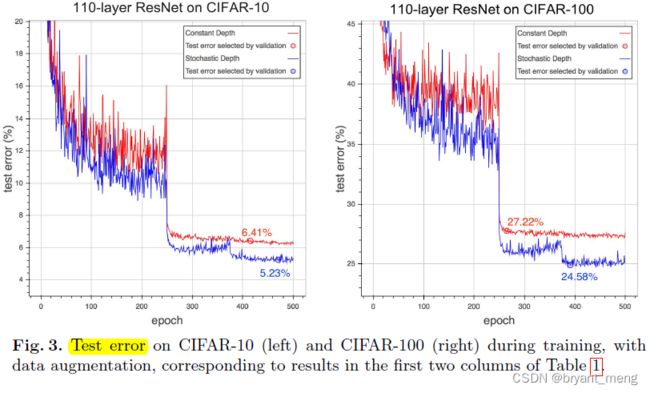
小圆圈处的模型,selected by the lowest validation error
test error 也降的很低
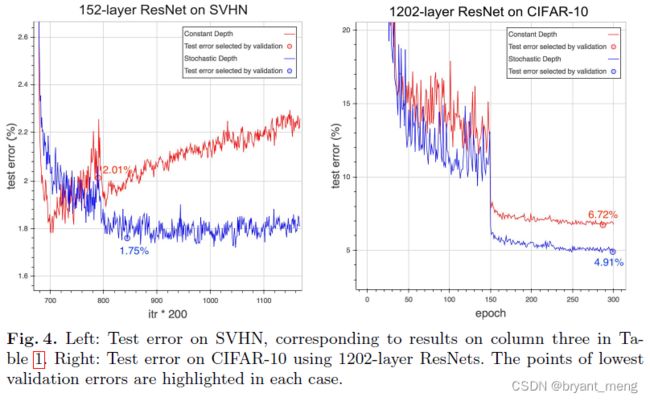
用 152 层的跑 SVHN,不用随机深度的训练方法,后续有点过拟合了
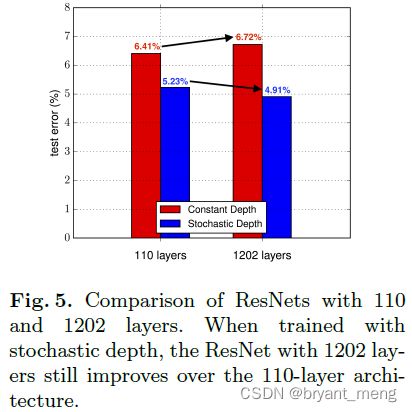
(2)Training with a 1202-layer ResNet
1202 层的,采用随机深度的训练方法,性能可以进一步提升
(3)Training time comparison
再看看速度方面
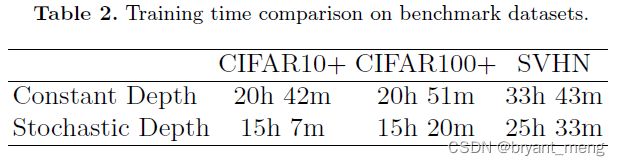
提升了 ~25%
(4)Vanishing gradients
梯度方面
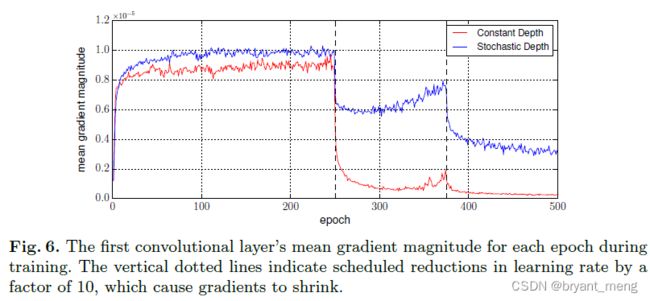
采用随机深度的训练方法,有更高的梯度响应(stochastic depth indeed significantly reduces the vanishing gradient problem)
(5)Hyper-parameter sensitivity
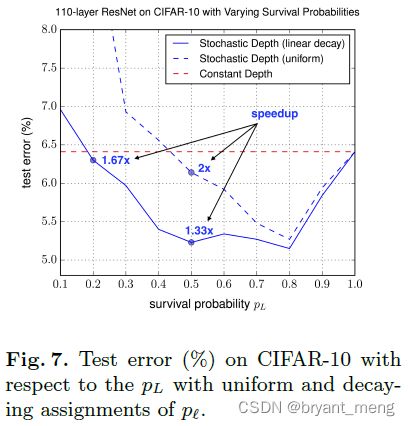
linear decay 的概率设计要比 uniform 的效果好,基本都比不用 stochastic depth 的训练方式要好
p L p_L pL 介于 0.4~0.8 之间的时候,还是比较稳的,说明对这个参数还是很鲁棒的
For p L = 0.2 p_L = 0.2 pL=0.2 the training is reduced by close to 40%, while still yielding reductions in error.
6 Conclusion(own)
-
DenseNet 的作者
-
和 BN 是兼容的
-
可惜没有在大一点的数据集上验证其性能
-
如何看待谷歌研究人员提出的卷积正则化方法「DropBlock」? - Kevin S的回答 - 知乎
