【路径规划】基于蚁群算法实现多式联运路径规划问题matlab源码
2.蚁群算法基本原理
2.1 算法综述
对于VRP问题,求解算法大致可分为精确算法和人工智能算法两大类。精确性算法基于严格的数学手段,在可以求解的情况下,解的质量较好。但是由于算法严格,运算量大,特别是大规模的问题几乎无法求解。所以其应用只能是小规模的确定性问题,面对中小规模问题,人工智能算法在精度上不占优势。但规模变大时,人工智能方法基本能在可接受时间里,找到可接受的满意解,这是精确算法难以做到的。由于的实际问题,各种约束错综复杂,人工智能算法显示出了巨大的优越性,也正因为如此,实际应用中,人工智能算法要更广泛。求解车辆路径调度问题的精确算法有动态规划法、分枝定界法等。并开始寻求所得结果可接受的启发式算法,以处理大规模实际问题,一些其他学科的新一代优化算法相继出现,如禁忌搜索算法,遗传算法,人工神经网络算法,以及现在研究较多的蚁群算法等。
2.2 蚁群算法的原理
蚁群算法是受到对真实蚂蚁群觅食行为研究的启发而提出。生物学研究表明:一群相互协作的蚂蚁能够找到食物和巢穴之间的最短路径,而单只蚂蚁则不能。生物学家经过大量细致观察研究发现,蚂蚁个体之间的行为是相互作用相互影响的。蚂蚁在运动过程中,能够在它所经过的路径上留下一种称之为信息素的物质,而此物质恰恰是蚂蚁个体之间信息传递交流的载体。蚂蚁在运动时能够感知这种物质,并且习惯于追踪此物质爬行,当然爬行过程中还会释放信息素。一条路上的信息素踪迹越浓,其它蚂蚁将以越高的概率跟随爬行此路径,从而该路径上的信息素踪迹会被加强,因此,由大量蚂蚁组成的蚁群的集体行为便表现出一种信息正反馈现象。某一路径上走过的蚂蚁越多,则后来者选择该路径的可能性就越大。蚂蚁个体之间就是通过这种间接的通信机制实现协同搜索最短路径的目标的。我们举例简单说明蚂蚁觅食行为:
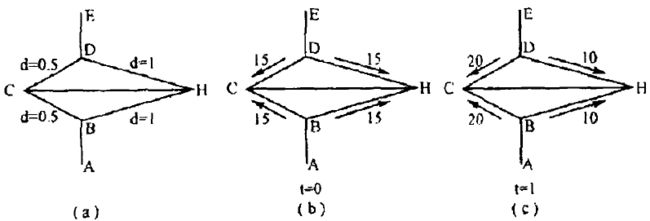
如上图a,b,c的示意图:
a图是原始状态,蚂蚁起始点为A,要到达E,中途有障碍物,要绕过才能到达。BC和BH是绕过障碍物的2条路径(假设只有2条)。各个路径的距离d已经标定。
b图是t=0时刻蚂蚁状态,各个边上有相等的信息素浓度,假设为15;
c图是t=1时刻蚂蚁经过后的状态,各个边的信息素浓度,有变化;因为大量蚂蚁的选择概率会不一样,而选择概率是和路径长度相关的。所以越短路径的浓度会越来越大,经过此短路径达到目的地的蚂蚁也会比其他路径多。这样大量的蚂蚁实践之后就找到了最短路径。所以这个过程本质可以概括为以下几点:
1.路径概率选择机制信息素踪迹越浓的路径,被选中的概率越大
2.信息素更新机制路径越短,路径上的信息素踪迹增长得越快
3.协同工作机制蚂蚁个体通过信息素进行信息交流。
从蚂蚁觅食的原理可见,单个个体的行为非常简单蚂蚁只知道跟踪信息素爬行并释放信息素,但组合后的群体智能又非常高蚂蚁群能在复杂的地理分布的清况下,轻松找到蚁穴与食物源之间的最短路径。这种特点恰恰与元启发算法的特点相一致,蚁群优化算法正是受到这种生态学现象的启发后加以模仿并改进而来,觅食的蚂蚁由人工蚁替代,蚂蚁释放的信息素变成了人工信息素,蚂蚁爬行和信息素的蒸发不再是连续不断的,而是在离散的时空中进行。
上述例子如果不好理解,我在这里贴几张PPT,个人感觉非常不错,也是我找了很多资料觉得最好理解的【来源是大连理工大学谷俊峰】,点击这里提供下载:蚁群算法基本知识.rar。


从深层意义上来讲,蚁群算法作为优化的方法之一,属于人工群集智能领域。人工群集智能,大都受自然群集智能如昆虫群和动物群等的启发而来。除了具有独特的强有力的合作搜索能力外,还可以利用一系列的计算代理对问题进行分布式处理,从而大大提高搜索效率。
回到目录
3.蚁群算法的基本流程
我们还是采用大连理工大学谷俊峰的PPT来说明问题,重要公式进行截图计算和解释,对PPT难以理解的地方进行单独解释:
3.1 基本数学模型
首先看看基本TSP问题的基本数学模型:

问题其实很简单,目标函数就是各个走过路径的总长度,注意的就是距离矩阵根据实际的问题不一样,长度是不一样的。
3.2 蚁群算法说明
在说明群蚁算法流程之前,我们对算法原理和几个注意点进行描述:
1.TSP问题的人工蚁群算法中,假设m只蚂蚁在图的相邻节点间移动,从而协作异步地得到问题的解。每只蚂蚁的一步转移概率由图中的每条边上的两类参数决定:1. 信息素值也称信息素痕迹。2.可见度,即先验值。 2.信息素的更新方式有2种,一是挥发,也就是所有路径上的信息素以一定的比率进行减少,模拟自然蚁群的信息素随时间挥发的过程;二是增强,给评价值“好”(有蚂蚁走过)的边增加信息素。 3.蚂蚁向下一个目标的运动是通过一个随机原则来实现的,也就是运用当前所在节点存储的信息,计算出下一步可达节点的概率,并按此概率实现一步移动,逐此往复,越来越接近最优解。 4.蚂蚁在寻找过程中,或者找到一个解后,会评估该解或解的一部分的优化程度,并把评价信息保存在相关连接的信息素中。
3.3 蚁群算法核心步骤
更加我们前面的原理和上述说明,群蚁算法的2个核心步骤是 路径构建 和 信息素更新。我们将重点对这2个步骤进行说明。
3.3.1 路径构建
每个蚂蚁都随机选择一个城市作为其出发城市,并维护一个路径记忆向量,用来存放该蚂蚁依次经过的城市。蚂蚁在构建路径的每一步中,按照一个随机比例规则选 择下一个要到达的城市。随机概率是按照下列公式来进行计算的:

上述公式就是计算 当前点 到 每一个可能的下一个节点 的概率。分子是 信息素强度 和 能见度 的幂乘积,而分母则是所有 分子的和值。这个刚开始是很不容易理解的,我们在最后实例计算的时候,可以看得很清楚,再反过来理解公式。注意每次选择好节点后,就要从可用节点中移除选择的节点。
3.3.2 信息素更新
信息素更新是群蚁算法的核心。也是整个算法的核心所在。算法在初始期间有一个固定的浓度值,在每一次迭代完成之后,所有出去的蚂蚁回来后,会对所走过的路线进行计算,然后更新相应的边的信息素浓度。很明显,这个数值肯定是和蚂蚁所走的长度有关系的,经过一次次的迭代, 近距离的线路的浓度会很高,从而得到近似最优解。那我们看看信息素更新的过程。
初始化信息素浓度C(0),如果太小,算法容易早熟,蚂蚁会很快集中到一条局部最优路径上来,因为可以想想,太小C值,使得和每次挥发和增强的值都差不多,那么 随机情况下,一些小概率的事件发生就会增加非最优路径的信息素浓度;如果C太大,信息素对搜索方向的指导性作用减低,影响算法性能。一般情况下,我们可以使用贪婪算法获取一个路径值Cnn,然后根据蚂蚁个数来计算C(0) = m/Cnn ,m为蚂蚁个数
每一轮过后,问题空间中的所有路径上的信息素都会发生蒸发,然后,所有的蚂蚁根据自己构建的路径长度在它们本轮经过的边上释放信息素,公式如下:


信息素更新的作用: 1.信息素挥发(evaporation)信息素痕迹的挥发过程是每个连接上的 信息素痕迹的浓度自动逐渐减弱的过程,这个挥发过程主要用于避 免算法过快地向局部最优区域集中,有助于搜索区域的扩展。 2.信息素增强(reinforcement)增强过程是蚁群优化算法中可选的部 分,称为离线更新方式(还有在线更新方式)。这种方式可以实现 由单个蚂蚁无法实现的集中行动。基本蚁群算法的离线更新方式是 在蚁群中的m只蚂蚁全部完成n城市的访问后,统一对残留信息进行 更新处理。
3.3.3 迭代与停止
迭代停止的条件可以选择合适的迭代次数后停止,输出最优路径,也可以看是否满足指定最优条件,找到满足的解后停止。最重要的是,我刚开始理解这个算法的时候,以为每一只蚂蚁走一条边就是一次迭代,其实是错的。这里算法每一次迭代的意义是:每次迭代的m只蚂蚁都完成了自己的路径过程,回到原点后的整个过程。
回到目录
4.蚁群算法计算实例
使用PPT中的一个案例,非常直观,对几个符号错误进行了修改,主要是计算概率的乘号,结果没有错误:






过程总体还是比较简单的,注意理解公式,然后把公式和实例结合起来看,最好是拿笔自己手动画一画,容易理解。
clear all
close all
%% 基于灰狼改进蚁群算法求解多式联运问题
%%=========================================================================
%%第一步:变量初始化
%% 距离数据
distance_rail=xlsread('data.xlsx','铁路','B2:AB28');%铁路距离
distance_rail(isnan(distance_rail))=inf;
for i=1:size(distance_rail,1)
for j=1:i
distance_rail(i,j)=distance_rail(j,i);
end
end
distance_road=xlsread('data.xlsx','公路','B2:AB28');%公路距离
distance_road(isnan(distance_road))=inf;
for i=1:size(distance_road,1)
for j=1:i
distance_road(i,j)=distance_road(j,i);
end
end
distance_water=xlsread('data.xlsx','水路','B2:AB28');%水路距离
distance_water(isnan(distance_water))=inf;
for i=1:size(distance_water,1)
for j=1:i
distance_water(i,j)=distance_water(j,i);
end
end
%% 风险数据
risk_rail=xlsread('data.xlsx','铁路风险','B2:AB28');%铁路距离
risk_rail(isnan(risk_rail))=inf;
for i=1:size(risk_rail,1)
for j=1:i
risk_rail(i,j)=risk_rail(j,i);
end
end
risk_road=xlsread('data.xlsx','公路风险','B2:AB28');%公路距离
risk_road(isnan(risk_road))=inf;
for i=1:size(risk_road,1)
for j=1:i
risk_road(i,j)=risk_road(j,i);
end
end
risk_water=xlsread('data.xlsx','水路风险','B2:AB28');%水路距离
risk_water(isnan(risk_water))=inf;
for i=1:size(risk_water,1)
for j=1:i
risk_water(i,j)=risk_water(j,i);
end
end
%%
D=distance_rail;
startpoint=1;%起点
endpoint=27;%终点
C =[0 0
100 200
200 -200
300 -400
200 300
300 100
400 -200
300 -300
400 -500
400 500
400 400
400 200
400 100
500 100
400 0
400 -100
400 -300
400 -500
500 -250
500 -350
500 400
600 -500
600 400
600 200
600 0
600 -300
800 0
];%C n个城市的坐标,n×2的矩阵
QQ=1000;%货运量
n=size(C,1);%n表示问题的规模(城市个数)
risk=[0.968
0.955
0.968
0.962
0.966
0.952
0.937
0.928
0.971
0.948
0.973
0.974
0.883
0.890
0.905
0.897
0.913
0.838
0.874
0.843
0.976
0.967
0.959
0.979
0.980];%换装风险
t_cost=0.3;%时间权值
h_cost=0.3;%能耗权值
d_cost=0.2;%距离权值
f_cost=0.2;%风险权值
v_rail=35;%铁路速度
v_road=43;%公路速度
v_water=28;%水路速度
distance=inf;
%% 蚁群算法参数
m=10;%蚂蚁数量
NC_max=1;%%% NC_max 最大迭代次数
Alpha=3;%% Alpha 表征信息素重要程度的参数
Beta=2;%% Beta 表征启发式因子重要程度的参数
Rho=0.5;%% Rho 信息素蒸发系数
Q=1;%% Q 信息素增加强度系数
% Calculate objective function for each search agent
[Shortest_Route,Shortest_Route_fangshi,L_best,fit_t_best_quanju,fit_h_best_quanju,fit_d_best_quanju,fit_f_best_quanju]=aco_qiujie(startpoint,endpoint,distance_rail,distance_road,distance_water,n,m,QQ,NC_max, Alpha,Beta,...
Rho,Q,v_rail,v_road,v_water,distance,risk_rail,risk_road,risk_water,risk,t_cost,h_cost,d_cost,f_cost);
city={'长沙','武汉','重庆','怀化','郑州','西安','成都','贵阳','南宁','满洲里','二连浩特','阿拉山口',...
'喀什','瓜达尔','上海' ,'广州','昆明','北海','仰光','胡志明','曼谷','新加坡',...
'华沙','杜伊斯堡','汉堡','鹿特丹','柏林'};
lujing={'铁路','公路','水路'};
for i=1:length(Shortest_Route)-1
fprintf('%s 经 %s 到 %s\n',city{Shortest_Route(i)},lujing{Shortest_Route_fangshi(i)},city{Shortest_Route(i+1)})
end
disp('最佳成本=')
Shortest_Length=fitvalue(Shortest_Route,Shortest_Route_fangshi,distance_rail,distance_road,distance_water,v_rail,v_road,v_water,QQ,risk_rail,risk_road,risk_water,risk,t_cost,h_cost,d_cost,f_cost) %最大迭代次数后最短距离
jieguoplot(startpoint,endpoint,Shortest_Route_fangshi,C,n,Shortest_Route,Shortest_Length,distance_rail,distance_road,distance_water,city);
disp(['最短时间=',num2str(fit_t_best_quanju)])
disp(['最低能耗成本=',num2str(fit_h_best_quanju)])
disp(['最短距离成本=',num2str(fit_d_best_quanju)])
disp(['最低风险=',num2str(fit_f_best_quanju)])
% figure(2)
% plot( L_best_quanju)
% xlabel('迭代次数')
% ylabel('适应度值')
% title('蚁群适应度曲线') %标题

