A comparison of methods for fully automatic segmentation of tumors and involved nodes in PET/CT of h
A comparison of methods for fully automatic segmentation of tumors and involved nodes in PET/CT of head and neck cancers
原文链接

中科院SCI分区 二区
Abstract
靶区勾画是放射治疗中一个重要但耗时且具有挑战性的部分,其目标是在降低副作用风险的同时向靶区提供足够的剂量。对于头颈部癌症(HNC)来说,头颈部区域的复杂解剖和靶区与危险器官的接近使这一点变得复杂起来。本研究的目的是比较和评价传统的PET阈值方法、6种经典的机器学习算法和2DU-net卷积神经网络(CNN)在PET/CT图像中对HNC进行自动肿瘤体积(GTV)分割的效果。对于后两种方法,还评估了单模态输入与多模态输入对分割质量的影响。197名患者参加了这项研究。数据集被分成训练集和测试集(分别为157名和40名患者)。在训练集上使用五折交叉验证进行模型比较和选择。手工绘制的GTV代表了ground truth。根据交叉验证Sørensen-Dice相似系数(Dice)分别对阈值法、经典机器学习和CNN分割模型进行排序。==PET阈值的Dice的最大平均得分为0.62,而经典机器学习得到的最大平均得分分别为0.24(CT)和0.66(PET;PET/CT)。CNN模型获得的最大平均Dice 得分分别为0.66(CT)、0.68(PET)和0.74(PET/CT)。多模态PET/CT模型与单模态细胞神经网络模型的交叉验证DICE差异有统计学意义(p≤0.0001)。排名最靠前的基于PET/CT的细胞神经网络模型表现优于表现最好的阈值和经典机器学习模型,在交叉验证和测试集Dice、真阳性率、阳性预测值和基于表面距离的指标方面给出了显著更好的分割结果(p≤0.0001)。因此,基于多模态PET/CT输入的深度学习具有更好的目标覆盖率和较少的包含周围正常组织的能力。
Introduction
2018年,全球共诊断出超过80万例头颈癌(布拉耶特2018年)。大多数HNC是口腔、口咽、下咽和喉部的鳞状细胞癌(HNSCC)(ArGiriset al2008,Haddad和Shin2008)。大多数患者被诊断为局部晚期非转移性疾病,标准治疗是同步放化疗(Halperinet Al2013)。
一般而言,放射治疗的挑战是向目标体积(TV)提供足够的剂量,同时将危险器官的剂量保持在可接受的水平,以防止重大毒性反应。对于HNC来说,由于头部和颈部的复杂解剖,以及目标体积和风险器官之间的距离很近,这一点变得更加复杂(O‘Sullivanet al2012,Grégoireet al2015)。高适形剂量放射治疗技术,如调强放射治疗和容积弧形治疗,可减少与辐射相关的毒性(O‘Sullivanet al 2012),但需要精确和准确的体积定义(Eisbruch和Gregoire2009,Grégoireet al 2015)。在临床实践中,目前目标体积勾画的金标准是放射治疗计划系统中的手工勾画。然而,手工描绘是耗时的,而且受制于观察者内部和观察者之间的可变性(Birdet al2015,Gudial al2017,Kosminet al2019年,Lin等人2019年)。自动分割可能会潜在地缓解观察者内部和观察者间的差异,减少描绘所花费的时间,正如Linet al(2019年)最近所展示的那样,从而改善目标体积剂量覆盖并减少风险器官的剂量。
口腔、咽部和喉部HNSCC的放射治疗计划通常使用治疗位患者的CT图像进行。18F-氟脱氧葡萄糖PET(FDG-PET)可作为一种补充方式,因为它可以为目标体积描绘提供额外信息(Grégoireet al2015)。以往关于HNC自动分割的大多数研究涉及规划CT图像中的风险器官或节点/选择性目标体积分割(见Kosminet AL2019的综述)或FDGPET图像中原发肿瘤体积的分割(Berthonet al2017、Stefanoet al2017、Comelliet AL20182019a、2019b)。对于基于CT的自动分割研究,方法从基于Atlas的算法到使用卷积神经网络(CNN)的深度学习(Kosminet al2019)。上述基于PET的研究以有限数量的患者(<30)为基础,并应用半自动或全自动经典机器学习方法分割肿瘤总体积(GTV)(Berthonet al2017)或GTV内的生物学相关TV(Stefanoet al2017,Comelliet al 20182019a,2019b)。
然而,有多种PET自动分割方法可用,从固定阈值到各种机器学习方法(Hattet al2017)。在迄今为止最全面的PET自动分割方法比较中,包括HNC患者的模拟、体模和临床FDG-PET图像数据,首先是使用CNN的深度学习方法,然后是各种经典机器学习方法(Hattet al2018)。该对比研究表明,所有方法的性能都取决于肿瘤和背景组织的FDG-PET摄取特性,从而导致患者分割质量的显著差异(Hattet al2018)。由于FDG-PET摄取不完全是癌症特异性的,因此能够利用CT或多模态PET/CT图像的自动分割方法可能对异常摄取特征更为稳健,有可能为摄取不典型的患者提供更高质量的分割。Yuet等人(2009年)和Huanget等人(2018年)都在PET/CT组合图像中对GTV进行了自动分割,但HNC患者数量有限(≤22)。Guoet al(2019)最近的一项研究为HNC中的GTV分割提出了一个深入的学习框架,使用多模式PET/CT而不是单一模式输入为250名患者获得了更好的自动分割。当基于深度学习的分割应用于口咽癌患者的图像时,PET/CT也产生了最高质量的GTV自动分割(n=202)(Andrearczyket等人,2020年)。
综上所述,以往在HNC中进行GTV自动分割的大多数研究都受到患者数量较少的限制,并且/或者没有研究单模态PET/CT图像与多模态PET/CT图像的对比。此外,大多数仅基于PET的研究都依赖于人类操作者定位目标内或周围的感兴趣区域(Stefanoet al 2017,Comelliet al 20182019a,2019b),或关注小的预先选择的感兴趣量(VOI),包括每个目标区域周围的直接区域(Hattet al 2018)。因此,对于较大的HNC患者队列,需要对VOI偏差较小的图像评估不同的自动分割方法,比较使用单模态和多模态图像获得的分割性能。这是我们目前工作的重点。
本研究的目的是评估阈值、经典机器学习和深度学习在基于HNSCC患者PET/CT图像的GTV自动分割中的作用。使用(i)传统PET阈值方法,(ii)探索不同分类器和高级特征工程的经典机器学习方法,以及(iii)使用CNN的深度学习方法,自动提取特征,在197名患者队列中获得自动分割。通过比较使用CT或PET图像或两种模式组合作为经典机器学习和深度学习方法的输入获得的结果,评估成像模式对分割质量的影响。
Materials and methods
Study
Patients and treatment
本研究包括口腔、口咽、下咽和喉部HNSCC患者,他们接受了治疗性放射(化疗)治疗。先前已经描述了225名患者的患者队列和治疗方案(Moanet al2019)。在目前的研究中,我们排除了未进行PET检查的对比增强CT患者,因此有197名患者符合分析条件。表1总结了合格患者的特征。该研究得到了区域伦理委员会(REK)和机构审查委员会的批准。由于这是一项回顾性研究,患者被取消了身份,因此REK批准免除研究特定知情同意。
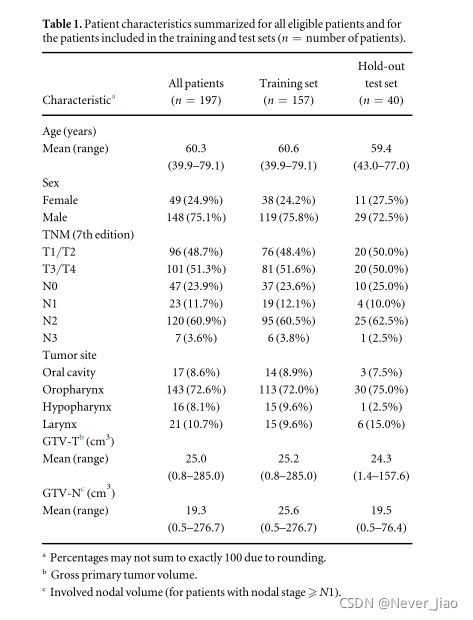
Imaging and manual delineations
FDG-PET/CT扫描在西门子Biograph 16(西门子Healthiners GmbH,Erlangen,德国)上进行,带有放射治疗兼容平台和放射治疗固定面罩。PET/CT方案包括从颅底到胸部中部的放射治疗优化PET/CT采集,手臂向下(5分钟/床位),然后进行标准全身PET/CT采集。对于目前的分析,仅包括放疗计划PET和相应的对比增强CT图像。有关成像协议的详细信息,请参见附录A。所有TV描绘均在治疗规划时完成,也在Moanet al(2019)中描述,遵循DAHANCA放射治疗指南(2013)。由经验丰富的核内科医师根据FDG PET检查结果,首先手动绘制原发肿瘤总体积(GTV-T)和相关淋巴结体积(GTV-N)。一个或两个肿瘤科住院医师根据对比增强CT和临床信息进一步完善了结果描述。为了最终的质量保证,由一位高级肿瘤学家审查了描述。
Image pre-processing
PET/CT图像系列和DICOM放疗计划结构导出到外部计算机,并使用交互式数据语言v8.5(哈里斯地理空间解决方案公司,美国科罗拉多州布鲁姆菲尔德)进行预处理。对于每个患者,PET、CT和Structure序列被重新采样到1×1×1mm3的各向同性体素大小,并注册到一个共同的参照系。PET图像值表示为标准化摄取值(SUV),归一化为体重。所有进一步的预处理都使用MATLAB®2019a(The Mathworks,Inc.Natick,USA,Massachusetts)进行。
通过在PET图像的最大强度投影上应用二维区域生长函数来识别和排除由高SUV脑组织组成的图像区域。图像被裁剪成包含GTV-T和GTV-N的VOI。每个VOI通过在轴面上包括围绕手动描绘的GTV结构的20 mm边缘和在z方向上的一个额外切片来定义。VOI中不包括中间勾画的结构的图像切片。上述VOI定义导致数据集减少,其中GTV-T和GTV-N体素的总数约占所有包括的体素的6%。根据原发肿瘤的体积和/或相关淋巴结的程度,这一比例在不同患者之间有适度的差异。图1(a)显示了典型的VOI,以及相应的PET/CT图像。

图1.实验设置示意图。(a)左:图像数据由放射治疗PET/CT图像组成。CT-W表示应用了窗口设置的CT(如图所示:中心60HU,宽度100HU)。实验中以手工勾画大体肿瘤体积为基础。在自动分割之前定义感兴趣的体积(VOI;白色正方形)。VOI内的每个图像体素由其强度值表示。对于经典的机器学习方法,使用2D或3D体素邻域内的强度作为特征。右图:进一步评估各种一维和二维图像变换作为经典学习者的特征(从左起:CT-W的局部二值模式、自然对数和PET的梯度幅度)。(b)使用PET阈值、六个经典机器学习分类器(线性判别分析(LDA)、二次判别分析(QDA)、高斯朴素贝叶斯(GNB)、Logistic回归(LR)、支持向量机(SVM)和随机森林(RF))和一个CNN架构(2D)获得自动分割。©将197名患者的队列分为训练组和测试组。根据自动分割与地面实况之间的Sørensen-Dice相似性系数,选择了高级模型进行进一步评估。
Model training and validation
使用四种PET阈值方法、六种经典机器学习分类算法和一种CNN结构进行自动分割。阈值、经典机器学习和CNN方法分别在2.5-2.7节中详细描述。分析的概述如图1所示。
在训练和评估自动分割模型时,使用手动GTV-T和GTV-N描述作为ground truth。自动分割任务被认为是一个两类分类问题:肿瘤和相关淋巴结组织属于GTV-T或GTV-N(1类),或未受影响的组织(0类)。
患根据TNM原发肿瘤(T)分期将患者分为训练组(157例;80%)和内部保留测试组(40例;20%)(见表1)。随机抽样五折交叉验证程序,按T阶段分层,与训练集一起用于超参数调整和模型比较。这确保了整个训练以及保留的测试集和交叉验证中可比较的TNM T阶段分布。在保留的测试集上评估了优异阈值,经典机器学习和CNN自动分割模型的泛化性能。在最终测试集评估之前,在完整的训练集上重新训练了优越的阈值和经典的机器学习模型。
利用MATLAB进行阈值分割和经典机器学习®. CNN模型使用Python和TensorFlow进行训练。
Performance evaluation
Sørensen–Dice相似系数(Dice)(Dice 1945,Sørensen1948)用于评估每个自动分割模型的交叉验证性能。可以使用集合表示法或真阳性(TP)、假阳性(FP)和假阴性(FN)体素的数量来定义DICE:
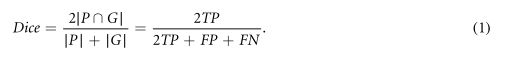
在等式(1)中,GandP分别表示包括在ground truth(G)描绘和预测§分割掩码中的体素集合。因此,Dice测量ground truth和预测的分割掩码之间的空间重叠程度,作为自动分割模型的输出,**Dice为0.70或更高的Dice分数可以被认为是体积分割之间的良好重叠(Zijdenboset Al1994)。**基于Dice的性能,我们分别选择了较好的阈值、经典机器学习和CNN模型,并使用下面第2.8节描述的方法进行了进一步的评估和比较。
进一步从真阳性率(TPR)、阳性预测值(PPV)、第95百分位数Hausdorff距离(HD95)(Huttenlocheret Al 1993)和平均表面距离(MSD)(Taha And Hanbury2015)等方面对优势模型进行了评估。这些指标提供了关于预测质量的补充信息。
TPR也称为敏感度,是与预测分割掩码重叠的ground truth描述的分数,并根据TP和FN 体素定义:

另一方面,PPV也称为精度,是预测分割掩码与ground truth描述重叠的分数,表示为:

Hausdorff距离(HD)定义为ground truth集合G的表面体素与预测mask 集合P之间的最大距离,表示为(Taha And Hanbury2015):
![]()
其中h(G,P)是定义为:

公式(5)中的||g-p||表示曲面点g和p之间的欧几里得范数。由于HD对异常值很敏感,因此不建议直接使用该度量(Zhang和Lu2004)。因此,它被排除了最极端观测的95%HD(HD95)所取代。此外,MSD被定义为ground truth集合G的表面体素与预测集合P之间的平均距离,由下式给出:
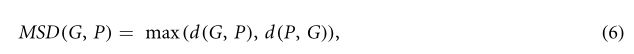
式中,d(G,P)是直接平均HD,定义为:

MSD度量提供了ground truth描绘和预测分割之间的典型距离,而HD95反映了两个集合的表面体素之间的最长距离,因此是最严重的失配。上述距离度量可以提供关于由于DICE固有的体积依赖性而未被DICE捕获的分割之间的边缘差异的临床相关信息。此外,Dice不区分类型1错误(FP)和类型II错误(FN)。然而,报告TPR和PPV都传达了关于这两种错误类型的不同信息(Hattet Al2017)。我们所有的性能指标都是按患者计算的。HD95和MSD是使用https://github.com/yngvem/mask_stats.提供的内部开发的Python库计算的。
Auto-segmentation using PET thresholding
使用绝对SUV阈值、最大SUV(SUVmax)阈值的百分比或基于高斯拉普拉斯(LOG)滤波的方法,以Gonzalez和Woods(2010)中概述的程序为基础,执行PET阈值,以下称为基于对数的阈值。
基于对数的阈值处理由几个顺序操作组成,其总体目标是使用LOG滤波器所指示的边缘来改进阈值处理获得的分割。首先,原始图像(PET)用卷积核中标准差(SDS)为{1.5,2.0,2.5,3.0,3.5,4.0,4.5}mm的3D LoG滤波器进行变换。对于每个SD,对应的核大小为n3,其中,n ≥6SD。为了避免不需要的边缘效应,在排除脑组织和图像裁剪之前进行LoG滤波。将得到的LoG滤波图像(FLOG)转换为绝对值,并使用百分位数阈值来创建二进制掩码。将该mask应用于FLOG和PET的产品上,以排除相关性最小的背景体素。然后将Otsu的方法(Otsu1979)应用于mask fLoG×PET,从背景中分割肿瘤/淋巴结。
在交叉验证过程中,通过最大化每个训练次数的每位患者平均数(mDice),对上述阈值模型进行了优化。绝对SUV阈值在0到8之间变化,增量变化为0.25,而SUVmax阈值的百分比在0%到100%之间变化,增量为1%。对于基于对数的阈值,百分位值在50到95之间变化,增量为5。
为了进行比较,我们还使用了一个固定百分比阈值,该阈值等于SUVmax的41%,该阈值已被推荐用于PET阈值(Daviset al2006,Boellaardet al2015)。
Auto-segmentation using classical machine learning
Feature extraction
基于经典机器学习的分割方法使用从原始PET和CT图像中提取的不同图像特征组合作为模型输入。使用CT特征、PET特征或PET和CT特征的组合作为分类器的输入来评估成像方式的效果。此外,我们还评估了用仅基于加窗CT图像(CT-W)的特征替换原始CT特征来减小CT图像动态范围(加窗)的效果。
原始体素强度值构成了最简单的特征,而每个体素周围的2D和3D邻域中的原始强度被用作空间特征。如图1(a)所示,2D邻域被定义为给定轴图像切片内的8-邻域(先前在Torheimet al 2017中描述),而3D邻域被定义为26-邻域,其还包括来自相邻图像切片的体素。
对于CT,CT-W和PET,我们也评估了几种一维和二维图像变换作为特征,通过评估它们与ground truth情况的点-双线相关性,只使用训练数据。一维变换包括van Griethuysenet et al(2017)定义的强度值的自然对数、指数、平方根和平方根。评估的2D变换包括使用Sobel算子(Gonzalez和Woods2010)、LoGfilter(Gonzalez和Woods2010)、局部二进制模式(LBP)(Ojalaet Al2002)以及第一级Haar(Gonzalez和Woods2010)和Coiflet(Daubechies1993)离散平稳小波的梯度幅度和方向。LoG滤波采用SDso f{1.5,2.0,2.5,3.0,3.5,4.0,4.5}mm,而LBP采用样本半径为{1,2,4,6}mm,固定样本大小为8个体素。对于基于对数的阈值,在排除高SUV脑体素和VOI清晰度之前执行空间相关(2D)变换。
此外,我们评估了10种不同的CT窗口设置,窗口中心为{60,70}HU,对应于典型的肿瘤内强度值,窗口宽度为{100,200,350,500,1000}HU。各种窗口设置被认为既包括在基于CT的分类中作为特征,也用于确定CT-W的设置。
所有与ground truth的绝对点-双列相关性等于或大于相应未变换图像的变换都被包括为特征。类似地,选择与ground truth具有最高点-双线相关性的窗口设置来创建CT-W,即(中心:60Hu;宽度:100Hu)。
Standardization, image unfolding and class-imbalance
对于每位患者,原始和转换后的3D图像堆栈分别标准化均值为零和标准差为1。在执行体素方面的分类之前,标准化的3D图像堆栈被展开成2D数据矩阵,其中每行由一个独特体素的给定输入特征组成,如Torheimet al(2017)中详细描述的。描绘的结构展开到相应的响应矢量,包含每个体素的类成员资格(根据ground truth,类0或1)。总共使用31个不同的txmatrices(见图4)作为分类算法的输入。对于由单模态2D或3D邻域组成的X矩阵,我们还评估了根据强度值按降序对每个体素及其邻域进行排序的效果。这些排序后的X矩阵给出了邻域体素强度变化的总体表示,而不是关注关于体素位置的强度。
为了缓解受影响组织(1类)和未受影响组织(0类)之间的严重类别不平衡,在交叉验证方案中,对大多数类别(即未受影响组织类别)进行随机欠抽样,以在每个训练折数中获得每个患者50-50的类别平衡。随机欠抽样是处理不平衡数据集的一种简单的方法,但已被证明提高了少数类的分类精度(Chawlaet al 2002,Zhang and Mani2003,Batuwita and Palade2010)。
Classification algorithms
基于机器学习的自动分割使用6种经典机器学习算法,即线性判别分析(Fisher1936)、二次判别分析(Hastieet Al 2001)、高斯朴素贝叶斯(Hastieeet Al 2001)、Logistic回归(LR)(Hastieet Al 2001)、线性支持向量机(SVM)(Cortes And Vapnik 1995)和随机森林(RF)(Breiman 2001)。LR和SVM分别使用套索型(最小绝对收缩和选择算子)(Tibshiani1996)或脊型(Hastieet Al2001)正则化(也称为L1和L2正则化)针对对数间隔的正则化参数值λ进行训练。改变λ值,直到在交叉验证过程中观察到峰值(LR:λ∈[10-6,104],SVM:λ∈[10-6,102])。RF使用固定参数进行训练(每个分裂随机选择的预测值(P)数量:P;每个树叶的最小观察值数量:1;引导样本大小等于训练集观察值的数量),除了从2到128不等的树数,直到交叉验证MDice收敛。
Auto-segmentation using CNNs
具有Dice Loss 函数(Milletariet Al2016)的2D U-Net CNN架构(Ronneberget Al2015)接受了训练,以便基于单一(PET、CT、CT-W)或多模态(PET/CT、PET/CT-W)图像输入(没有图像堆栈标准化)在轴向图像切片中执行自动分割。CT-W使用的设置与经典学习相同(中心:60Hu;宽度:100Hu)。由于不同患者的VOI大小不同,图像切片用零填充以获得176×176mm2的共同矩阵尺寸。CNN模型使用ADAM优化器(Kingma和Ba2014)进行训练,学习率为10−5。关于CNN体系结构的详细信息见附录B。
对于CNN模型的选择,首先根据五次交叉验证(见下文第2.8节)确定最优的输入模态。接下来,从五个交叉验证模型中选择其相关验证结果中mDice最高的一个模型进行最终测试集评估。
Statistical analysis
采用非参数Friedman检验(Friedman1937)对重复测量的单因素方差分析分别对阈值、经典机器学习和CNN进行了评估,分别基于五次交叉验证中的Dice score对阈值、经典机器学习和CNN进行了评估。如果Friedman检验检测到显著差异,则使用Nemenyi的多对一检验(Hollanderet Al2014)来分别比较所考虑的模型或算法对Dice或者mDice的处理效果。使用具有最高Friedman秩和的模型或算法作为对照,测试说明秩和无差异的零假设和说明对照具有显著高于其所与之比较的模型或算法的秩和的片面替代假设。因此,对零假设的拒绝表明控制模型或算法在Dice或者mDice方面获得了优越的分割质量。
进一步使用Friedman检验和Nemenyi配对比较(Hollanderet Al2014)来比较所选阈值、经典机器学习和CNN模型的每个患者的分割性能。
统计分析在R(版本4.0.2)中进行,使用PMCMRplus软件包(版本1.4.4)。所有测试均以0.05的显著性水平进行。
以框图和小提琴图相结合的方式显示患者的性能指标和相关的汇总统计数据,其中小提琴部分使用核密度估计来可视化数据分布,以获得概率密度函数。框图包括中值和四分位数范围(白框)、平均值(红点)、第5-95个百分位数的竖线和异常值(黑点)。小提琴曲线图是使用高斯平滑核创建的,分布尾部被修剪成只包括观察到的数据范围。
Results
Auto-segmentations obtained by PET thresholding
图2显示了每个患者的基于阈值的分割模型,以及相应的汇总统计数据和最佳阈值参数。绝对SUV阈值(Tabs)和优化的SUVmax阈值百分比分别得到0.62和0.59的mDice得分。相比之下,参考41%的SUVmax阈值和基于对数的阈值分别获得0.51和0.53的mDice分数。
绝对SUV阈值模型(Tabs)排名最高,在每个患者Dice上的显示明显高于其余模型(图2)。因此,Tabb被选作进一步评估。

图2.使用PET阈值在训练集(n=157名患者)上获得的手动描绘和自动分割之间的每位患者Sørensen-Dice相似系数(Dice)的组合框图和小提琴图。使用五折交叉验证进行阈值优化和随后的自动分割。报告的阈值在五个交叉验证训练折叠中取平均值。图中显示了Friedman检验的结果(评估模型之间每名患者的差异)以及随后与绝对SUV作为对照模型的多对一比较(显着性水平a=0.05,单侧Nemenyi多对一检验)。
Auto-segmentations obtained by classical machine learning
Comparisons across imaging modalities
基于CT、CT-W、PET、PET/CT或PET/CT-W数据的各种分类模型交叉验证的概述如图3所示,每个算法和输入组合的准确数值如图4所示。
仅基于PET的自动分割模型产生的mDice与基于PET/CT和PET/CT-W的模型的mDice范围相同(mDice:0.39-0.66;图4)。因此,将PET与CT或CT-W数据结合使用时,没有增加数据分割性能(图3)。仅基于CT或CT-W的自动分割效果很差,mDice范围从0.12到0.24(图4),表明与ground truth描述的一致性较差。对于CT和CT-W,分类算法在mDice方面只有很小的变化,但RF导致大多数输入的mDice值最高(图4)。
用CT-W替换原始CT数据通常会改进mDice(图4)。然而,排名最高的CT和CT-W模型有相同的mDice值为0.24。这两种模型都导致分割不完整和不精确。
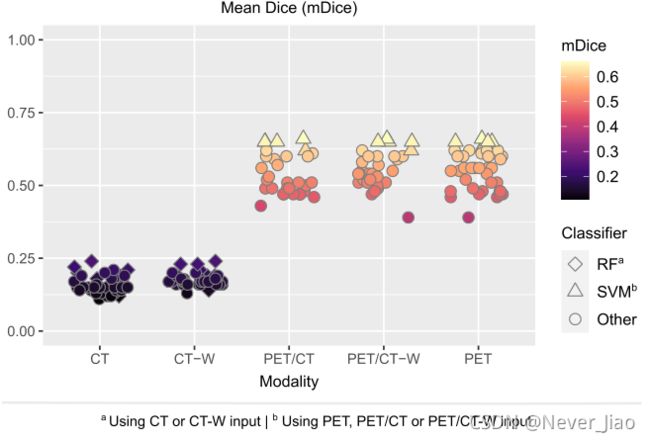
图3.使用基于CT、CT-W(带窗口的CT)、PET、PET/CT或PET/CT-W的图像输入,通过六种机器学习算法获得的手动描绘和自动分割之间的每个患者的平均Sørensen-Dice相似系数(MDice)概述。每个点对应于图像输入和分类器的唯一组合。结果是通过对训练集(n=157名患者)进行五次交叉验证得到的。重点介绍了使用CT或CT-W输入的随机森林(RF)和使用PET、PET/CT或PET/CT-W的支持向量机(SVM)的结果

图4. 使用机器学习分类器随机森林(RF)、线性判别分析(LDA)、二次判别分析(QDA)、高斯朴素贝叶斯(GNB)、逻辑回归(LR)和支持向量机获得的手动描述和自动分割之间每位患者平均Sørensen-骰子相似系数(mDice)的热图(SVM),使用基于CT、CT-W、PET或其组合的不同图像输入数据。达到最高mDicea的模型以粗体显示。结果是通过对训练集(n=157名患者)进行五次交叉验证得到的。图中显示了Friedman检验结果(评估PET、PET/CT和PET/CT-W输入算法之间的mDice差异)以及随后以支持向量机为控制算法的多对一比较(显著性水平=0.05,单侧Nemenyi多对一检验)。
Algorithm and model selection
由于与ground truth描绘的重叠性差,仅基于CT或CT-W的模型不包括在进一步的模型选择中。对于其余的机器学习模型,Friedman测试表明在使用分类算法的mDice方面存在显著差异(图4)。排名最高的算法是SVM分类器,与其他算法相比获得了一致的更高的分类精度。对于基于PET、PET/CT或PET/CT-W的SVM模型,mDice的取值范围为0.63比0.66。
Friedman检验还表明,在纳入的SVM模型中,每位患者的分割表现存在显著差异(p<0. 0001). 三个具有最高mDice的SVM模型(图4)也基于每名患者的mDice排名最高,具有相同的Friedman秩和。这些模型分别使用L1正则化和PET、PET/CT或PET/CT-W强度值以及按降序排序的3D邻居作为输入特征。由于L1正则化的特征选择特性,排名最高的PET/CT和PET/CT-W模型基本相同,每个患者的交叉验证结果大致相同。
三个排名靠前的支持向量机模型中的每一个都比排名靠后的支持向量机模型(Nemenyi多对一测试,所有的p≤0. 05). 尽管排名靠前的模型基于秩和是不可分割的,但仅考虑PET强度值的SVM模型(PET 3Dsinfigure4,以下简称为SVMPET)根据其优势和中位数(SD:0.13对0.17;中位数:0.68对0.65)被挑选出来进行进一步评估。

图5.结合方框图和小提琴图的每个患者的索伦森-Dice相似系数(Dice)之间的手动描绘和自动分割,使用2DU-Net CNN架构获得以下图像输入(从左):PET/CT-W(CTW:CT加窗),PET/CT,PET,CT-W或CT。结果是通过对训练集(n=157名患者)进行五次交叉验证得到的。图中显示了Friedman检验(评估CNN模型之间每个患者Dice的差异)以及随后与以PET/CT-W为基础的模型作为对照的多对一比较的结果(显著性水平=0.05,单侧Nemenyi多对一检验).
Auto-segmentations obtained by CNNs
图5显示了使用具有不同输入模态的2D U-net CNN架构获得的Dice score。CNN方法对包括CT和CT-W在内的所有输入模式都有足够高的Dice性能,并且多模式输入的性能比单一模式输入的性能有显著的提高(mDice:0.74(PET/CT-W);0.73(PET/CT):0.68(PET);0.66(CT-W);0.64(CT))。
根据Friedman秩和,基于PET/CT-W图像的CNN模型(以下简称U-NETPET/CT-W)排名最高,并且每个患者获得的结果明显高于所有单峰模型(图5)。基于其优越的排名,U-NETPET/CT-W被选为坚持测试集评估的对象。
Performance of the superior models
图6显示了优势阈值(Tabs)、经典机器学习(SVMPET)和CNN(U-NETPET/CT-W)模型的联合交叉验证和保留测试集的分割性能。表2给出了交叉验证和坚持测试集的单独汇总统计数据。对于所有三个模型,保留测试集上的分割性能与其交叉验证性能相当(表2)。
如图6所示,对于所有指标,U-NETPET/CT-W获得的分割质量明显高于阈值和经典机器学习模型(p≤0.0001;图6(a)-(e))。SVMPET的得分明显高于Tabs(p≤0.0001;图6(a)),TPR和PPV的均值和中位数稍高,SVMPET和Tabs的均值、SD值和中位数MSD相当,而Tabs阈值的均值、SD值和中位数HD95最低。
在保留测试集上获得的代表性自动分割如图7所示,其中由优越模型预测的分割轮廓与ground truth情况进行比较。所有模型对低背景FDG-PET信号的分割质量相对较高,结合GTV-T和/或GTV-N内高而均匀的示踪剂摄取。两个纯PET模型(SVMPET和Tabs)都不能在ground truth的基础上分割低FDG-PET摄取区(图7(a))。这两个模型也倾向于包含中等到高SUV的FP体素。然而,与经典机器学习相比,阈值学习的这种趋势更为明显(图7(b)和©)。Tabs相对于SVMPET的优势HD95(见图6;表2)在许多情况下与阈值模型在分割掩码中包括更多体素有关,从而与ground truth边缘重合或接近,特别是GTV-N边界(图7(b))。SVMPET获得的自动分割通常比阈值更精细(图7(b)和©)。正如预期的那样,多模态U-NETPET/CT-W模型比纯PET模型更接近非典型FDG-PET摄取特征,因此在更大程度上能够分割低摄取区(图7(a))和GTV-N边缘(图7(b)),以及避免包含FP体素。
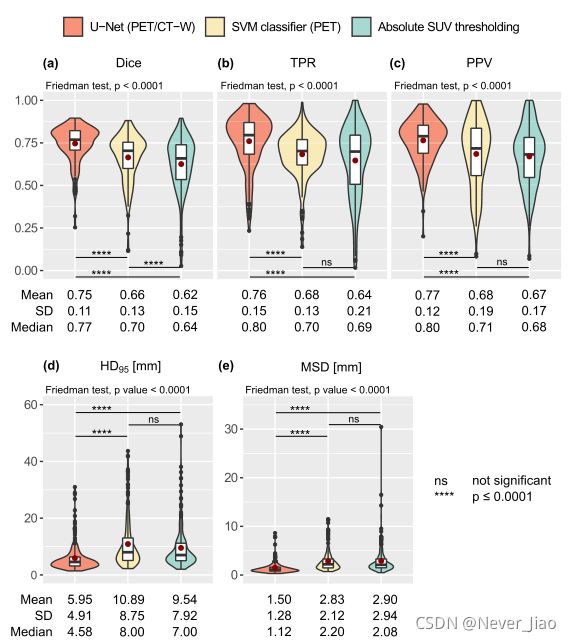 图6.结合盒图和小提琴图,显示了卓越的CNN(U-Net与PET/CT-W输入)、经典机器学习(使用3D邻域PET信息的SVM分类器)和PET阈值(绝对SUV)模型的每个患者分割性能的组合曲线图。显示的数据是训练集(n=157名患者)和保留测试集(n=40名患者)交叉验证的综合结果。结果显示:(a)Sørensen-Dice相似系数,(b)真阳性率,©阳性预测值,(d)第95百分位Hausdorff距离,(e)平均表面距离。对于每个性能度量(a)-(e),指示Friedman检验(评估模型之间每个患者性能的差异)和随后的成对比较的结果(显著性水平=0.05,双侧Nemenyi成对比较)。
图6.结合盒图和小提琴图,显示了卓越的CNN(U-Net与PET/CT-W输入)、经典机器学习(使用3D邻域PET信息的SVM分类器)和PET阈值(绝对SUV)模型的每个患者分割性能的组合曲线图。显示的数据是训练集(n=157名患者)和保留测试集(n=40名患者)交叉验证的综合结果。结果显示:(a)Sørensen-Dice相似系数,(b)真阳性率,©阳性预测值,(d)第95百分位Hausdorff距离,(e)平均表面距离。对于每个性能度量(a)-(e),指示Friedman检验(评估模型之间每个患者性能的差异)和随后的成对比较的结果(显著性水平=0.05,双侧Nemenyi成对比较)。
表2.卓越PET阈值(Tabs)、经典机器学习(SVMPET)和CNN(U-NETPET/CT-W)模型的每个患者分割性能指标(Dice、TPR、PPV、HD95、MSD)的中值、平均和标准偏差(SD)。结果通过对训练集(n=157名患者)和保留测试集(n=40名患者)进行五折交叉验证(CV)获得。
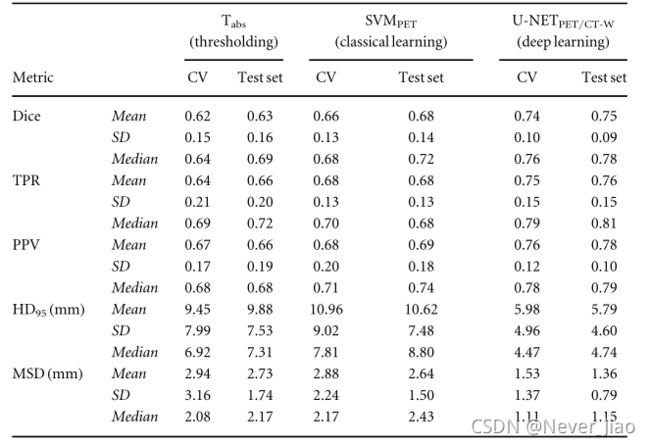
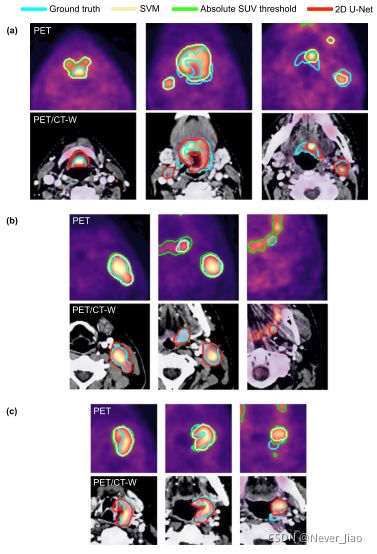
图7.来自三个不同患者(a)-©的上、中和下图像切片(列)中的自动分割轮廓示例。自动分割是通过绝对SUV PET阈值(绿色)、基于三维邻域PET信息的支持向量机(SVM)分类器的经典机器学习(黄色)和基于组合PET/CT-W图像输入的2DU-net CNN(绿色)获得的。阈值模型、支持向量机模型和U-Net模型的Sørensen-Dice相似系数分别为:(a)0.68,0.70,0.74;(b)0.62,0.79,0.76;©0.71,0.73,0.79。
Discussion
在这项研究中,我们评估了PET阈值方法、经典机器学习分类器和基于CT、CT-W、PET、PET/CT或PET/CT-W输入的U-net CNN,用于对197例HNSCC患者的原发肿瘤和相关淋巴结进行全自动分割。CNN方法的表现优于阈值和经典机器学习,为所有输入模式提供了与ground truth最高的重叠度。排名最靠前的CNN模型结合了PET/CT-W信息(U-NETPET/CT-W),与表现最好的经典学习(SVMPET)和阈值(Tabs)模型相比,在Dice、TPR、PPV、HD95和MSD方面的分割效果明显更好。SVMPET进一步取得了比排名靠前的阈值模型更好的Dice性能。CNN模型的TPR值和PPV值越高,分别表明TV覆盖率越高,正常组织的包含率越低,而其他两种模型方法的TPR值和PPV值都比其他两种模型方法高。所选CNN模型的明显较小的距离度量进一步表明更准确和精确的描述,这可以转化为在临床环境中对分割的手动修改的较少需要。
固定PET阈值有其局限性,但由于其简单性,仍被广泛使用。在我们的研究中,在优化和未优化的百分比阈值之间观察到的分割性能的差异强调了阈值优化的优势,无论是在应用方面还是在患者队列方面都是如此。例如,与固定的41%阈值相比,我们优化的百分比阈值导致mDice增加了0.08(16%)。优化后的阈值百分比(27%)也大大低于SUVmax的41%(Daviset al2006,Boellaardet al2015)。这在一定程度上可以归因于这样一个事实,即我们研究中的ground truth描述是基于CT,而不是PET。因此,所描绘的区域通常比高代谢区域包含更大的体积。
在评估的经典机器学习算法中,支持向量机在mDice方面提供了最高质量的自动分割,而LR算法排名第二。与大多数其他评估的算法相反,线性支持向量机和似然比算法不需要假设特定的概率分布,只要求类是线性可分的(Hastieet Al2001)。这两个分类器通常会给出相似的结果,但由于它们的结构不同,可能会出现较小的差异。LR是从概率的角度开发的,为属于肿瘤类别的每个体素分配最佳概率。相反,线性支持向量机是从几何角度发展的,寻找最大化体素分类分离的线性子空间。最优的支持向量机模型(SVMPET)使用原始PET图像强度,3D邻居根据强度降序排序。因此,分类是基于体素附近高SUV的程度,而不是这些体素的确切位置。
对于仅基于PET的分割,最优阈值和经典机器学习模型的性能与CNN模型相当,交叉验证mDice值约为0.65,这表明PET分割所需的信息在于体素强度,而不是微妙而复杂的空间模式。因此,作为人类专家的辅助,简单的阈值方法可能足以用于预备PET分割。
以前关于基于PET的自动分割的研究对于经典学习者来说已经达到了0.77-0.87的范围(Berthonet al2017,Stefanoet al2017,Comelliet al2018,2019a,2019b,Hattet al2018)。在Hattet al(2018)的比较研究中,基于SUVmax的40%的固定阈值得到0.70的mDice值,而CNN模型报告的mDice值为0.80。然而,图像数据(Hattet Al2018)、ground truth描述的基础(Berthonet Al2017)、TV的定义(Stefanoet al2017,Comelliet al 2018,2019a,2019b,Hattet al2018)、先前的VOI定义(Hattet Al2018)和/或自动化水平(Stefanoet al2017,Comelliet al2018,2019a,2019b)的差异使上述研究与在(Stefanoet al2017,Comelliet al2018,2019a,2019b)中的方法依赖于用户手动在不包括高摄取示踪剂的健康组织的癌症区域内或其周围绘制一条线或轮廓,从而限制FP体素的数量。此外,涉及的节点没有包括在任何这些研究中。在Hattet al(2018)中,这些方法被应用于模拟、体模和临床数据的组合,其中临床图像的数量有限,预定义的VOI仅限于包含每个原发肿瘤的直接背景。因此,这些研究的自动分割任务可能被认为比在更大的VOI中执行GTV-T和GTVN的全自动分割更具挑战性,就像我们目前的工作一样。
进行基于PET的HNSCC自动分割的最新研究(Guoet al 2019,Andrearczyk et al 2020)评估了单模态和多模态PET/CT输入的深度学习,包括淋巴结和原发肿瘤GTV,以及更大的图像VOI。这两项研究均基于多中心患者队列,这可能比我们目前的单中心任务更具挑战性。当仅基于PET图像进行分割时,DenseNet(Guoet al2019)和3D V-Net(Andrearczyket al2020)分别获得0.64和0.58的mDICE。前者与我们的基于SVM和PET的CNN模型相当,后者获得0.66和0.68的交叉验证mDice。
不管分割方法如何,我们的仅基于PET的模型在具有相当大的FP和/或FNFDG-PET摄取区的患者中表现相对较差,这表明了仅基于分子成像进行自动分割的缺点。本研究中考虑的经典机器学习算法在CT或CT-W图像中没有提供令人满意的自动分割,当PET图像与解剖CT或CT-W信息相结合时,分割性能没有提高。一般而言,经典CT或CT-W模型的分割性能得益于图像变换的加入,这表明CT信号与ground truth之间存在非线性关系。CNN可以自动发现图像中复杂和微妙的模式,用于一系列诊断和应用的基于CT的分割(参见Cardenaset al2019年)的成功,以及我们基于CT的CNN模型的良好表现支持了这一假设。Guoet al(2019)和Andrearczyket al(2020)在单独使用CNN进行基于CT的GTV分割时,mDice得分分别为0.31和0.49。这比我们基于CT的CNN模型(mDice:0.64-0.66)要低得多,但与我们的经典机器学习方法(mDice:0.24)相比,mDice仍然有很大的提高。因此,分割所需的信息存在于CT图像中,但是用经典的机器学习方法手动设计相关特征是困难的。因此,使用CNN,绕过特征工程步骤,应该是基于CT的分割的首选方法。
与经典的机器学习算法相比,在给定多模态PET/CT输入的情况下,我们的2D U-Net能够进一步显著提高分割性能,得到0.73-0.75的mDice得分。这与Guoet al(2019)和Andrearczyket al(2020)的结果一致,当时PET/CT的mDicescore分别为0.71和0.60,也给出了优越的结果。因此,当分割仅基于PET图像时,似乎更简单的分类算法(如我们提出的SVM模型)可以与CNN相媲美,但是CNN可以利用PET/CT图像中包含的互补信息来改进分割。
之前的几项研究已经评估了HNSCC手动GTV描述中观察者间的可变性(Riegletal2006,Murakamiet al2008,Kajitaniet al2013,Birdet al2015,Gudidial2017)。然而,只有Gudi等人(2017)报告了使用Dice的PET/CT观察员间协议,允许与我们目前的工作进行直接比较。Gudial(2017)调查了三位经验丰富的放射肿瘤学家之间GTV-T和OAR描述的差异,每一位都在当代HNC放射治疗方面有10年以上的经验。对10例不同的HNSCC病例进行了手工勾画。使用(增强)CT或FDGPET/CT进行GTV-T勾画的观察者之间的一致性分别为(mDice±SD)0.57±0.12和0.69±0.08。因此,报告的观察者间协议与我们所有的CNN模型(mDice:0.64-0.75;SDs:0.10-0.15)和我们的经典SVMPET模型(0.66±0.13)的性能相当。
Conclusion
在这项研究中,我们广泛评估了几种PET阈值方法、经典机器学习分类器和使用单模或多模PET/CT输入的2D U-net CNN结构在197例HNSCC患者中全自动分割原发性和结节GTV的适用性。这种自动分割方法以前没有在大型HNSCC患者队列中进行评估和比较。所有仅使用基于PET的输入的模型总体上都具有较好的分割性能。传统的机器学习分类器不能仅基于CT图像的输入提供令人满意的自动分割,也不能利用多模态PET/CT中的解剖和分子信息来改善仅基于PET的模型的分割质量。但CNN模型的情况并非如此,在基于纯CT或组合PET/CT输入的自动分割方面,CNN模型的表现优于传统的学习者。更好的模型是基于PET和加窗CT图像的U网络,其结果是比性能最好的PET阈值和经典学习方法有更好的目标覆盖率和更少的正常组织包含。