论文研读-文献聚类可视化-文献聚类结果可视分析方法研究
文献聚类结果可视分析方法研究
- 1 论文概述
-
- 1.1 摘要
- 1.2 引言
- 1.3 脉络
- 2 可视分析框架
- 2.1 框架概述
- 2.2 框架组成
- 3 可视化设计
-
- 3.1 语料结构可视化
- 3.2 语料内容可视化
- 3.3 聚类结果调整和优化
- 4 系统实现及案例分析
-
- 4.1 选择聚类方法
- 4.2 调整聚类数量
- 4.3 优化和诊断聚类结果
- 4.4 用户反馈
- 5 结论
- 6 收获
1 论文概述
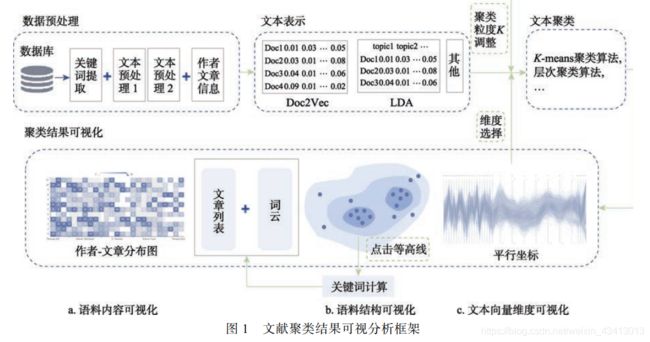
2020年10月发表在《计算机辅助设计与图形学学报》上的中科院网络中心的一篇文章,主要是探究文献聚类结果的可视分析,提出了一个完整的文献聚类结果可视分析框架。该框架包含数据预处理、文本表示、文本聚类、聚类结果可视分析各个环节, 采用语料结构可视化、语料内容可视化、文本向量维度可视化以及可视化交互对聚类结果进行解释、分析、评估、调整和优化.
1.1 摘要
问题:在信息化时代, 文献数据呈爆炸式增长. 面对海量无标签的文献数据, 无监督文本聚类能够快速、高效地对大规模数据重新组织和归纳. 然而, 影响文献聚类效果的因素是多方面的, 从数据处理到文本表示方法到聚类算法的选择, 在任意一个环节不同的选择产生的结果可能大相径庭; 且在各环节方法种类多样使得文献聚类结果难以解释和评估, 对做好文献聚类工作造成了很大困扰.
方法:为此, 提出了一个完整的文献聚类结果可视分析框架. 该框架包含数据预处理、文本表示、文本聚类、聚类结果可视分析各个环节, 采用语料结构可视化、语料内容可视化、文本向量维度可视化以及可视化交互对聚类结果进行解释、分析、评估、调整和优化.
基于该框架, 设计并实现了文献聚类结果可视分析系统, 研究了采用不同文本表示方法、不同聚类算法对聚类结果产生的影响.
评估: 最后, 通过 3 个案例, 验证了该框架有效性.
1.2 引言
需要解决的问题:
- 各个环节选择不同的方法所产生的结果可能大相径庭,如何为海量无标记的文献数据选择合适的聚类方法;
- 文献聚类结果也很难解释和评价:聚类结果评价依赖于人工标注这一难题、每一个类的内容以及是否可以进一步调整仍需查看文献内容。
解决方法
- 对聚类结果进行评价。展示语料结构和语料内容来解释聚类结果, 从而感知、对比不同文献聚类方法产生的聚类结果的差异。
- 对聚类结果进行分析、调整和诊断。设计了基于等高线的文档选择方法。
- 设计并实现了文献聚类结果可视分析系统。数据集验证、案例分析评估系统有效性。
1.3 脉络
- 相关工作
- 可视分析框架
- 可视化设计
- 系统实现及案例分析
- 结论
2 可视分析框架
2.1 框架概述
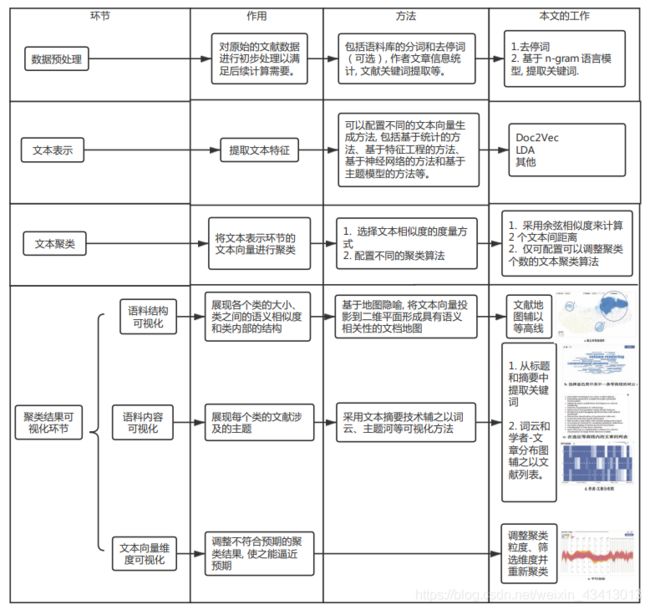
- 文献聚类通常包括文本数据预处理、文本表示和文本聚类等主要环节, 因此文献聚类结果可视分析框架也应当包含这些环节.
- 聚类结果可视化方法应当能够清晰地呈现各个类的大小、类之间的关系、类内结构和每个类的内容, 从而帮助用户洞察聚类结果的好坏.
- 对不符合预期的聚类结果进行调整, 快速逼近预期的效果,则能为用户提供很大帮助.
2.2 框架组成
文献聚类结果可视分析框架如图 1 所示, 主要分为数据预处理、文本表示、文本聚类和聚类结果可视化 4 个环节.
3 可视化设计
3.1 语料结构可视化
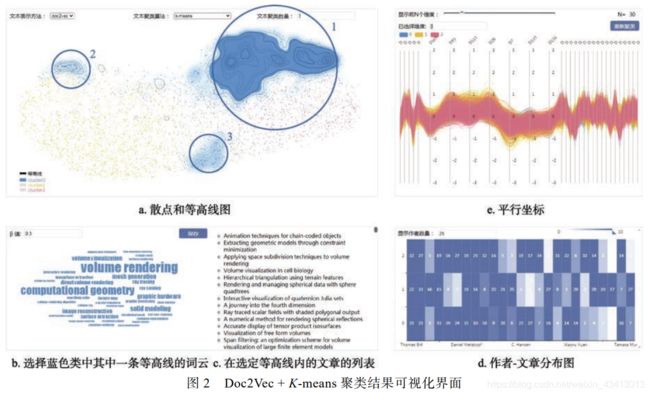
语料结构可视化如图 a 所示. 首先通过将高维的文本向量降至二维, 以圆点表示文献, 圆点的颜色表示文献的类别, 在二维平面上绘制文献地图. 文献地图可以表达文献之间的语义相关性, 相关性越大, 表示文献的圆点之间的距离越小, 圆点紧密的区域往往暗示着这是一群语义相似的文章, 可以归为一类.
为了清晰地展示各类文献之间的轮廓和每一类文献内部的结构, 本文在文献地图上叠加基于密度的等高线.通过各个类圆点的分布密度计算、绘制等高线, 并设置径向颜色渐变, 使密度越高的等高线内部具有更深的颜色, 以突出各个类的范围、每个类内部的结构特点以及是否具有若干个核心区域. 这些核心区域很可能是一个大类的子类, 这将对聚类数量的设置起到指导作用.
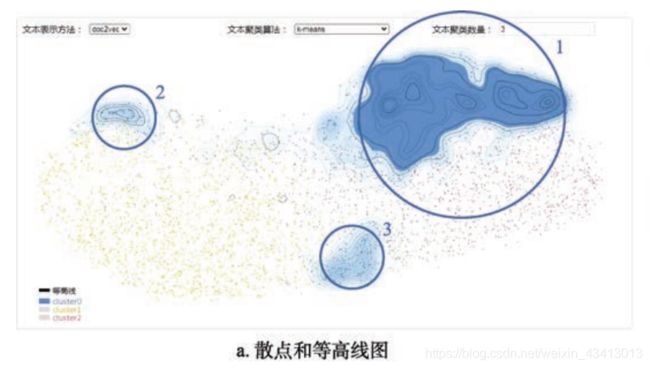 在此基础上, 本文设计了选择等高线的交互方式. 用户可以点击任意等高线, 选中相应类别中位于该等高线内部的文章集合; 该交互方式为语料内容可视化提供了很大的便利. 此外, 为了减少语料结构可视化时各类的点、线、面的视觉混杂, 本文通过图例的交互为用户提供等高线的显示与隐藏、各个类别的显示与隐藏等功能, 如图 2 左下角的图例所示.
在此基础上, 本文设计了选择等高线的交互方式. 用户可以点击任意等高线, 选中相应类别中位于该等高线内部的文章集合; 该交互方式为语料内容可视化提供了很大的便利. 此外, 为了减少语料结构可视化时各类的点、线、面的视觉混杂, 本文通过图例的交互为用户提供等高线的显示与隐藏、各个类别的显示与隐藏等功能, 如图 2 左下角的图例所示.
3.2 语料内容可视化
语料内容可视化如图 2b~图 2d 所示, 包括作者-文章热力图、词云和文章列表.
 采用作者-文章热力图主要是基于如下假设: 在一个研究领域中, 顶级会议论文数量最多的作者往往是该领域内贡献较多的学者, 其研究方向通常具有多样性; 学科交叉程度越高的研究领域, 顶级会议论文数量最多的作者的研究方向全都一致的概率越小.
采用作者-文章热力图主要是基于如下假设: 在一个研究领域中, 顶级会议论文数量最多的作者往往是该领域内贡献较多的学者, 其研究方向通常具有多样性; 学科交叉程度越高的研究领域, 顶级会议论文数量最多的作者的研究方向全都一致的概率越小.
作者-文章热力图的横轴为作者, 纵轴为文章类别, 中间的每一个矩形的颜色表示作者各类论文的数量, 颜色越深, 表示数量越多. 通过热力图中作者论文数量的分布, 可以快速、直观地判断是否产生了不好的聚类结果. 此外, 为了便于查看作者信息, 作者-文章热力图提供了一定的交互: 当鼠标移至矩形上方, 会生成一个信息框用于展示作者的信息.
词云主要用于展示所选文章的内容摘要. 通过语料结构可视化中选择等高线的交互方式, 可以获取相应类别位于该等高线内部的文章集合. 词云展示的就是这部分文章的关键词, 即主题. 通常, 一个好的聚类结果中, 属于同一类的文献的主题应当相近, 主题差别大的文献不应该属于同一类. 通过查看各个类别、每个类别内部核心区域的主题, 可以得知聚类结果的好坏; 通过每个类别内部核心区域的主题和数量, 能大致估计出数据集可以分成多少类. 如果需要查看更详细的内容, 可以通过文章列表查看相应文献. 此外, 由于空间有限, 需要筛选用于展示的关键词. 本文采用 Sievert等[17]定义的显著性公式, 来选择具有显著代表性的关键词.通过该公式, 可以避免使用词频筛选出词频很高且很大众的关键词. 筛选出具有代表性的关键词后, 将关键词的词频映射到词云的大小, 即可直观地看到所选文献集合所涉及的主题.
3.3 聚类结果调整和优化
对聚类结果进行调整和优化, 一方面是调整聚类粒度, 以获得符合预期的结果; 另一方面是对不符合预期的聚类结果的文本向量进行维度筛选并重新聚类, 以获得一定的优化.
聚类粒度 K 是指期望获得的类别数量, 对其调整将影响聚类算法的参数. 当 K 值改变时, 将对文本向量重新聚类, 文档地图、等高线、平行坐标和作者-文章热力图均会更新成重新聚类后的结果.
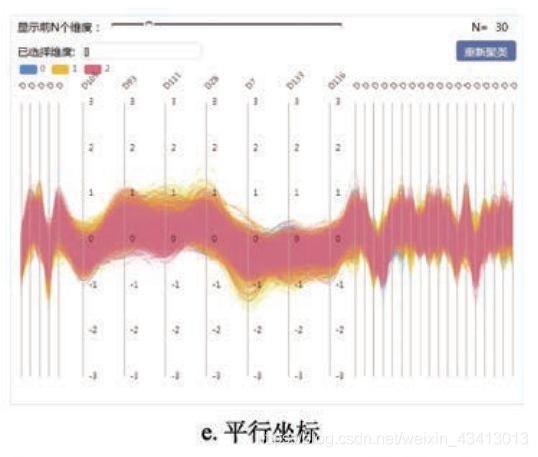
在维度筛选方面, Ji 等[13]的研究证明了文本向量的特定维度的组合能表达特定的语义信息. 本文采用平行坐标来展示文本向量各个维度上的数值分布, 每一个轴表示文本向量的一个维度, 每一条折线代表一篇文章, 每一条线在各个轴上的刻度表示对应文本在各个维度上的值, 颜色代表该文本的类别, 如图 2e 所示. 平行坐标的维度按有效度从大到小排序, 通过图 2e 顶部的滑块可以选择显示的维度数量.
*本文所指的维度有效度是指一个维度对不同类别文本的区分能力, 即有效度高的维度应当使不同类的文本在该维度上的值的方差较大、同类的文本在该维度上的值的方差较小. 在计算有效度之前, 需要对每个维度进行归一化, 避免过大的值对计算结果产生影响.
4 系统实现及案例分析
基于文献聚类结果可视分析框架, 本文实现了文献聚类结果可视分析系统, 如图 2 所示.
 系统采用隐含狄利克雷分布(latent Dirichlet allocation, LDA)[6]和 Doc2Vec[8]生成文本向量, 用K-means和Agglomerative Clustering进行文本聚类.
系统采用隐含狄利克雷分布(latent Dirichlet allocation, LDA)[6]和 Doc2Vec[8]生成文本向量, 用K-means和Agglomerative Clustering进行文本聚类.
LDA 主题模型是一个 3 层贝叶斯模型, 该模型认为文档是由若干主题构成, 主题是由若干词构成. 通过 LDA 主题模型可以获得文档的主题分布和主题的词分布; 其生成的文本向量的每一个维度即为 LDA 主题模型挖掘到的潜在的主题.
Doc2Vec是基于神经网络的文本表示方法, 它可以接受不固定长度的文本, 通过上下文学习得到固定长度的文本向量.
K-means 是一种基于划分的聚类算法, 该算法认为距离越近的 2 个对象越相似, 并且以得到独立且紧凑的簇为目标进行聚类.
Agglomerative Clustering 是一种自底向上的层次聚类算法, 它有ward, average 和 complete 这 3 种合并策略. 对于非欧几里得度量方式, average 合并策略是一个很好的选择. 本文采用余弦距离作为相似度度量方法, 因此, 采用 average 策略进行簇之间的合并.
使用的降维方法有TSNE和UMAP,其中 UMAP速度较快。
系统数据使用微软学术数据中可视化领域的论文, 包括 3 个国际顶级会议 IEEE VIS,EuroVis和 PacificVis 的论文, 去除了缺少摘要、作者等关键信息的论文数据后, 共有 4 197 篇文章。
4.1 选择聚类方法
文献聚类结果可视分析系统使用户可以通过控制变量研究各环节采用不同方法产生的聚类结果的不同, 并且可以通过可视化图表直观地看出聚类结果是否符合预期.
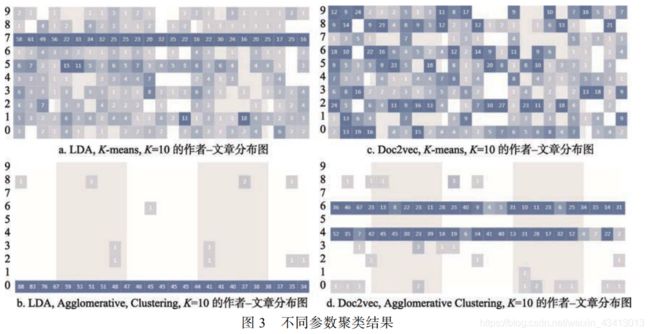
图 3 所示为根据系统中 2种文本表示方法、2 种文本聚类算法两两组合产生的聚类结果绘制的作者-文章热力图; 横轴是作者, 纵轴是类别. 图 3a、图 3b 和图 3d 中, 论文数量最多的前 25 位学者的论文大多集中在一个或 2 个类中, 而图 3c 中论文数量最多的前 25 位学者的论文分布在较多的类别中. 对于正在对可视化领域的研究方向进行分类的用户而言, 更希望得到如图3c 所示的结果. 因此, 选择 Doc2vec 生成文本向量, 并用 K-means 进行聚类是较好的选择.
4.2 调整聚类数量
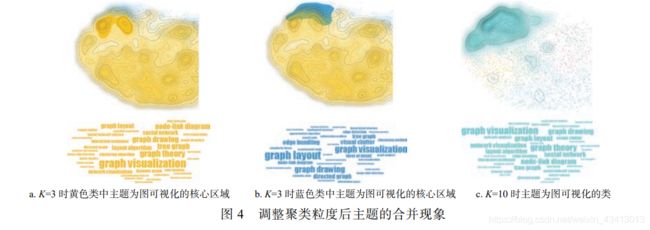
文本表示方法选择 Doc2Vec 算法(默认设置200 维), 聚类算法选择 K-means, 设置粒度系数K=3, 聚类结果如图 2 所示, 每个类的前 5 个关键词如表 2 所示. 通过图 2a 的散点图和等高线, 可以看到蓝色类具有 3 个明显的核心区域, 每个核心区域的前 5 个关键词如表 3 所示. 同理, 黄色类具有4 个明显的核心区域, 红色类具有 2 个明显的核心区域. 因此, 这些文献数据应该至少可以分成 9类. 通过调整 K 值, 观察各个类及其核心区域, 最终设置 K=10 时得到一个比较符合预期聚类结果, 各个类的前 5 个关键词如表 4 所示. 值得注意的是, 通过该可视分析方法可以清楚地看到, 原先在 K=3 时, 黄色类和蓝色类中具有主题极其相似的核心区域; 在 K=10 时, 它们被聚合成一个类, 如图 4 所示. 由此可见, 通过可视分析方法来解释并调整聚类具有评价指标不可比拟的优势.
4.3 优化和诊断聚类结果
文本表示方法选择 LDA 算法(默认设置 12 维), 聚类算法选择 K-means, 设置粒度系数 K=10, 聚类结果如图 5a 所示.
其中, 散点图中类似于蓝色框内的散点簇都有 2 种颜色, 而一个语义相近的散点簇应当分到同一类里. 平行坐标中有一个维度(D1), 所有类别的文献在该维度上的值都很高, 绝大部分都大于 0.5. 由于 LDA 生成的文本向量的维度为潜在的主题, 这意味着绝大多数文献都属于D1 维度代表的潜在主题. 该结论从作者-文章热力图中也可以得到验证——论文数量最多的前 25 位学者的论文集中在第 1 类. 由此可知, 该文献聚类结果并不好.
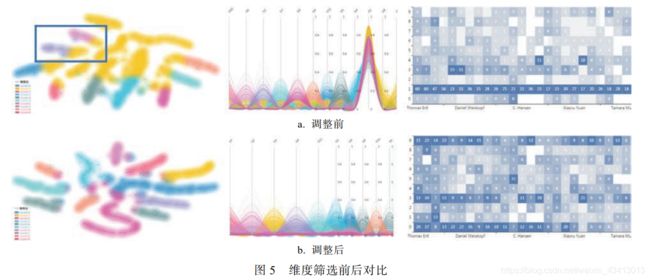 通过筛选维度, 去掉 D1 维度, 重新聚类得到如图 5b 所示的结果. 散点图中散点簇的着色有了明显的改善, 热力图中作者论文的主题分布变得更均匀. 由此可见, 聚类结果得到了改善.
通过筛选维度, 去掉 D1 维度, 重新聚类得到如图 5b 所示的结果. 散点图中散点簇的着色有了明显的改善, 热力图中作者论文的主题分布变得更均匀. 由此可见, 聚类结果得到了改善.
然而, 通过仔细观察热力图可以发现, 作者的文章较多地集中在 3 个类别, 其编号分别为 0, 3, 9. 分别查看维度调整前的论文数量较多的类别 1(前1), 3(前 3), 4(前 4); 维度调整后论文数量较多的类别 0(后 0), 3(后 3), 9(后 9)的主题词云; 发现前 1 后9(表 5 第 1 行)、前 3 后 0(表 5 第 2 行)以及前 4 后3(表 5 第 3 行)的主题分别较相近, 而剩余主题五花八门. 从表 5 中的主题可以发现, 前 3 行的主题主要是科学可视化的, 可以在调整前后找到对应的类别; 而剩余行各类的主题多是信息可视化和可视分析研究方向的. 由此可以得知, 采用 LDA 作为文本表示方法的聚类效果不佳的主要原因是: LDA 生成的文本向量不能很好地区分信息可视化和可视分析研究方向的文献.
4.4 用户反馈
本文邀请了正在做文本分类的博士研究生来使用这个系统, 并得到了一些积极的反馈和意见.
反馈 1. 该系统对我了解文本表示方法、文本聚类算法很有帮助, 它能够让我快速地看到不同算法产生的不同结果. 此外, 通过简单的图表, 我可以看到聚类产生的各个类别的论文都涉及哪些主题. 当一个类别中出现 2 个或多个很不相似的主题, 当作者-文章热力图呈现出不符合常理的分布时, 通过切换各个环节的算法, 可以快速锁定问题所在. 这样很方便. 不过该系统目前支持的算法很少, 希望能增加更多的算法.
反馈 2. 数据标记一直是我头疼的问题. 每当有个新点子想通过实验验证一下, 但由于自身专业知识不足, 身边没有足够的领域专家可以帮忙标记数据, 想要获得较高质量的标记数据太难了. 而且数据标记本身带有一定的主观性, 不同专家对同一数据的标记也会不同. 聚类结果可视分析系统提供了一种不同于人工智能领域评价聚类结果的新方法, 它使得用户可以通过观察聚类结果中类别的分布、各类别主题的分布、各作者论文的类别分布, 及各维度的区分度来判断结果好坏. 这大大降低了文献聚类对专业背景的要求, 是一个很棒的想法.
反馈 3. 第一眼看到这个系统的界面时, 我就被吸引住了, 可视化的效果做得很漂亮. 通过这个系统, 我可以从不同的角度观察聚类结果, 这也让我看到了算法的局限性. 期待在人工智能领域研发出更好的算法的同时, 也期待作者后续能继续完善系统, 研究一下如何通过可视分析方法去提升算法性能.
5 结论
本文提出了文献聚类结果可视分析框架, 统一文献聚类各环节的输入输出, 使用户可以方便快捷地更换各个环节的算法; 同时, 通过可视化为用户提供直观、可交互的方法以更好地分析文献、优化文献聚类结果, 为实际应用中的文献聚类工作提供了新的思路. 此外, 本文基于该框架设计实现了文献聚类结果可视分析系统, 通过 3 个案例对该方法进行了评估.
当然, 本文工作也存在一些局限性.
首先, 本文提出的文献聚类结果可视分析框架需要先指定聚类数量, 这导致了无法采用不能预先确定聚类数量的算法.
其次, 该框架主要用于分析对比不同的算法组合产生的聚类结果的差异, 不能从根本上提升所采用算法的性能.
此外, 本文基于该框架实现的系统只加入了 2 种文本表示方法 2 种聚类算
法, 算法种类偏少, 且可视化多基于现有的方法. 后续将增加更多算法, 根据用户反馈逐步完善系统, 希望能更好地帮助用户测试对比不同的文献聚类方法, 获得更好的聚类结果, 甚至促进各个环节算法的改进.
6 收获
- 仅将降成二维后的点可视化的话,由于点的数量多点十分密集,用户无法直接分辨出各点附近密度大小,从而比较聚类的结果。使用基于密度的等高线,可以直观的探索出各类内部的架构和类间的区别。
- 词云可视化时,使用显著性公式,避免使用词频筛选出词频很高且很大众的关键词.,来选择具有显著代表性的关键词.
- 维度有效度指一个维度对不同类别文本的区分能力, 即有效度高的维度应当使不同类的文本在该维度上的值的方差较大、同类的文本在该维度上的值的方差较小. 在计算有效度之前, 需要对每个维度进行归一化, 避免过大的值对计算结果产生影响.
- 综合一个工作的所有环节,为用户提供一个可视化界面,不仅可以帮助用户理解整个过程中的各个环节,有科普作用;同时也为用户对自己结果的评估、优化、调整提供了一个交互式的界面,能更直观的评价不同方法之间的差异,从而完善工作,有实际意义。
- 是否可以考虑应用到新的领域?