自动写诗APP项目、基于python+Android实现(技术:LSTM+Fasttext分类+word2vec+Flask+mysql)第四节
三、LSTM模型 搭建
生成诗歌模型主要是基于隐马尔可夫原理,从时间序列的随机事件中,统计前后状态转化的概率。在此模型当中,就是根据给定的第一个字(即前一阶段已选择出来的与主题词最相似的候选词集合),来生成它后面出现的最大概率的字。
1、 诗句到向量的转换
因为诗歌是古人智慧的结晶,文学的高度凝练。在此,并不能像普通文本那样简单的做分词处理。而是以字为单位,来做诗句到向量的转化。首先统计近30万首诗歌中(只包括诗句),各字出现的频率,按照字频从高到低排序。
总共要搭建5个LSTM的生成诗模型。以其中一个为例,首先是加载整个训练集数据,并统计每个字出现的频率,按照频率从高到低映射成id(0--maxSize),在训练时使用每首诗各各字对应的id值输入,进行训练。
依照此对应关系,整个训练数据,都可以以诗中每个字对应的id值来输入。
例如,训练数据: 训练时,模型实际的输入数据:
单车欲问边,属国过居延。 [ 897 203 63 188 142 0 891 173 214 238 1150 1
征蓬出汉塞,归雁入胡天。 367 546 52 182 357 0 35 436 107 222 8 1
大漠孤烟直,长河落日圆。 66 1077 269 179 346 0 39 191 112 10 1240 1
萧关逢候骑,都护在燕然 298 206 303 1310 314 0 304 1187 91 429 121 1 ]
2、 LSTM模型原理
本文使用的是一种特殊的循环神经网络模型LSTM(长短期记忆网络)。LSTM是一种具有记忆能力的循环神经网络,能够在输入当前新数据的同时,对以往数据保持一定的记忆。这样便可以保证诗歌的整体性,防止前后句生成的诗歌毫不相关。
LSTM网络模型,能很有效的解决简单循环神经网络中的梯度爆炸和梯度消失问题。LSTM网络引入了一个新的内部状态Ct专门进行线性的循环信息传递,同时非线性的输出信息给隐藏层的外部状态Ht。LSTM网络中的门是一种软门,取值在(0,1)之间,表示以一定的比例运行信息通过,下图为LSTM的时间维度展开图:
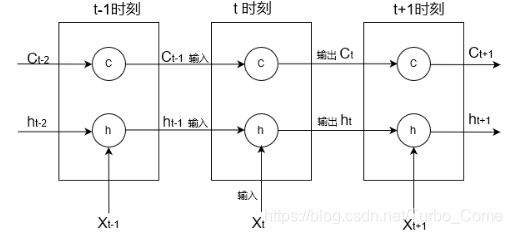
每个神经元都是有3个输入状态:
Ct-1上一时刻内部状态
ht-1上一时刻外部状态
Xt 当前时刻的输入
2个输出状态:
Ct当前时刻内部状态
ht 当前时刻外部状态
各个LSTM神经元彼此通过当前时刻内部状态Ct,当前时刻外部状态Ht来连接,由Xt来不断为当前时刻注入新的信息,共同构成LSTM的网络模型。项目中设置了2层LSTM神经网络,每层128个神经元。
LSTM模型单个神经元结构如下图:

LSTM模型的单个神经元的信息传递计算公式:
![]()
遗忘门Ft,控制上一时刻的内部状态Ct-1需要遗忘多少信息
输入门It,控制当前时刻的候选状态Ct有多少信息需要保存
输出门Ot,控制当前时刻的内部状态Ct有多少信息需要输出给外部状态Ht
![]() 非线性函数得到的候选状态:
非线性函数得到的候选状态:
![]()
每个时刻,LSTM模型的内部状态Ct 记录了到当前时刻为止的历史信息.
三个门的计算公式如下:
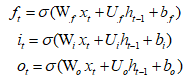


通过LSTM循环单元,整个网络可以建立较长距离的时序依赖关系,简洁的描述为:

循环神经网络中的隐状态h存储了历史信息,可以看作是一种记忆。在简单循环网络中,隐状态每个时刻都会被重写,因此能够被看作是一种短期记忆。在神经网络中,长期记忆可以看作是网络参数,隐含了从训练数据中学到的经验,且更新周期要远远慢于短期记忆。而在LSTM网络中,记忆单元c,可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。记忆单元c中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆。
3、应用的LSTM模型具体结构:
具体LSTM框架
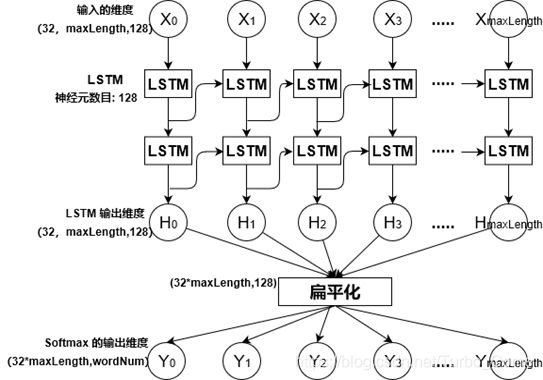
输入维度是[32,maxLength,128]的三维矩阵,bitchSize=32,即一批次同时训练的样本数量为32首诗。maxLength为一批次中,最长的那首诗的长度,不足长度的诗由空格补充,这是因TensorFlow的语法规定,一批次中的每个样本长度必须一致。128为一层LSTM神经网络的神经元数目。
经过2层LSTM的神经网络训练后,输出仍是一个[32,maxLength,128]的三维矩阵。然后再做扁平化处理,改变输出形状为(batch_size * maxLength, hidden_units)。之后计算logits序列的交叉熵(Cross-Entropy)的损失,logits 是 Logistic Regression模型(线性方程: y = W * x + b )计算的结果。得到logits值之后,用 softmax激活层来转成百分比概率,取最大概率的那个值作为预测值,再进行预测值与真实值的对比,计算梯度列表,实现误差的反向传递,最后更新学习率,再进行下一次的学习训练。
本项目中使用TensorFlow搭建LSTM网络模型时,设置具体参数如下:
batchSize = 32 :批次样本数目
epochNum =30 :训练轮次
hidden_units=128:一层LSTM网络模型的神经元数目,也是词向量的维度
layers=2 :LSTM网络模型的层数num_steps= maxLength:LSTM 展开的步(step)数,相当于每个批次输入一个样本中数据的数目,这里为每batchSize首诗中最长的诗的字数。
learningRateBase = 0.001 :初始学习率
learningRateDecayStep = 1000 每隔 1000 步学习率下降
learningRateDecayRate = 0.95 在过了每个learningRateDecayStep步之后,学习率的衰减率
init_scale=0.05:权重参数的初始取值跨度
dropout=0.5:在Dropout层的留存率,这里只对隐藏层进行Dropout处理
4、《诗学含英》概率权重计算对比
在LSTM模型依次生成候选字时,本文并不是单单选择其后生成的最大概率的字。为了提高诗句的通顺性,与主题词的相关性,使得生成的诗文有一定的意境和含义,在候选字中,考虑了2方面:
- 候选的生成字本身的概率
- 是否在《诗学含英》中
应用概率权重公式:

《诗学含英》是清朝乾隆年间,由山阴刘文蔚编辑。此书是按韵分部,包罗天文地理,花木鸟兽,人物器物等的虚实应对。从单字到双字,三字对,五字对,七字对到十一字对,节奏明快琅琅上口,从中可得语音,修辞的训练。
因为《诗学含英》是按类别划分的,包括天文地理,花木鸟兽等。考虑到《诗学含英》中词汇范围较广,为判别与主题词最相似的类别,便选用维基百科的word2vec模型,来计算主题词与《诗学含英》中所有的类别标题词汇的相似度。选取其中最相近的6类(为了保证候选字集合较为充足),统计这6类包含的词汇。通过判断每次生成的字是否在这6类词汇中,给予其权重值为0.15(即1-λ![]() 的值,通过多次调试后选取),来进行候选字选取的概率计算。
的值,通过多次调试后选取),来进行候选字选取的概率计算。
对于候选生成字本身的预测概率,在此只是选取了概率最高的前6个字,然后做的归一化处理。得到p1 p2…p6 的值,代入公式计算,其中给予生成字本身的预测概率权重λ=0.85,计算最终的概率Pi值,选择其中最大者作为生成的下一个字。
是否使用《诗学含英》进行概率权重计算来生成诗歌前后对比:
秋思 秋思
秋声被病来有俎, 秋风一度一千里,
风流菊到春宵客。 怀子相思不可前。
独阑吹迸落花子, 乡路不知春事好,
悲风满窥忽无鬣。 苦向江头空自归。
(左)在不使用《诗学含英》进行概率权重计算时,生成的诗歌偶尔会出现生僻字,这不仅影响人们的阅读,也影响诗句的通顺性。本项目中给与了《诗学含英》一定的权重,使得生成诗歌的候选字尽可能为本类诗歌的常见字,这样便可在一定程度上提高生成诗歌的通顺性,整体感情基调也与主题词更加贴近。
5、项目中LSTM模型的代码实现:
数据预处理代码(data.py):
LSTM模型输入数据的预处理,去除诗歌中的特殊符号,停用词,并将“字”转成词向量,返回模型指定格式的输入向量 X
"""
LSTM模型写诗前的数据处理,返回模型的输入量 X
"""
from config import *
class POEMS():
erase = []
"poem class"
def __init__(self,filename):
"""pretreatment"""
poems = []
file = open(filename, "r",encoding='utf-8')
for line in file: #every line is a poem
title, author, poem = line.strip().split("::") #get title and poem
poem = poem.replace(' ','') # 去空格
if len(poem) < 10 or len(poem) > 512: #去 过长过短诗
continue
if '_' in poem or '《' in poem or '[' in poem or '(' in poem or '(' in poem:
continue
poem = '[' + poem + ']' #add start and end signs
poems.append(poem)
#counting words
# wordFreq Counter type, {'字',字频 。。。} 从 高-->低
wordFreq = collections.Counter()
for poem in poems:
wordFreq.update(poem)
# print (wordFreq) #
# erase words 生僻字
for key in wordFreq:
if wordFreq[key] < 2:
POEMS.erase.append(key)
wordFreq[" "] = -1
wordPairs = sorted(wordFreq.items(), key=lambda x: -x[1])
self.words, freq = zip(*wordPairs)
self.wordNum = len(self.words) # 整个诗歌训练集中字的总个数
# print(self.words)
# print(freq)
# print(self.wordNum)
# wordToID {'字','字频' 。。。} 按字频从高-->低
self.wordToID = dict(zip(self.words, range(self.wordNum)))
# poem to vector ,诗中每个字 对应的 id
poemsVector = [([self.wordToID[word] for word in poem]) for poem in poems]
# print(poemsVector)
# 分析训练词向量,测试词向量
self.trainVector = poemsVector
self.testVector = []
print("训练样本总数: %d" % len(self.trainVector))
# print("测试样本总数: %d" % len(self.testVector))
def generateBatch(self, isTrain=True):
"""
每轮仅输入 batchSize 个样本数据,
:param isTrain:
:return:
"""
if isTrain:
poemsVector = self.trainVector # 训练数据所对应的 id ,一维
else:
poemsVector = self.testVector
# 将词向量打乱
random.shuffle(poemsVector)
# batchSize 同时运行的一批样本数量,较小时,有利于模型找到最优解,
# 较大时,缩短训练时间, 与内存大小有关
batchNum = (len(poemsVector) - 1) // batchSize
# batchNum 表示 一个epoch下,所需计算的迭代次数,一次迭代可运算batchSize个样本
X = []
Y = []
for i in range(batchNum):
batch = poemsVector[i * batchSize : (i + 1) * batchSize]
# 每个 batch 批次中的向量,都计算其长度,在这些长度中找到最长的那个
maxLength = max([len(vector) for vector in batch])
# 添加空格,将所有不足最长向量的vector(矩阵:batchSize , maxLength) 补齐为最长向量
# 定义全空格-id, 再赋值给定 诗-id,
temp = np.full((batchSize, maxLength), self.wordToID[" "], np.int32)
for j in range(batchSize):
temp[j, :len(batch[j])] = batch[j]
X.append(temp)
temp2 = np.copy(temp)
temp2[:, :-1] = temp[:, 1:] # Y 错开一个字,
Y.append(temp2)
print(X)
print(Y)
return X, Y
LSTM模型代码(model.py):
model.py文件:
"""
LSTM模型搭建 进行写诗
train --> 训练 model
testHead --> 根据每一句的开头字,进行预测写诗
每一句的开头字 为 word2vec 模型生成的相似词,提取去除的结果
LSTM 模型参数
batchSize = 32 批次(样本)数目。一次迭代(Forword 运算(用于得到损失函数)以及 BackPropagation 运算(用于更新神经网络参数))所用的样本数目
learningRateBase = 0.001 # 学习率
learningRateDecayStep = 1000 # 每隔 1000 步学习率下降
learningRateDecayRate = 0.95 在过了 max_lr_epoch 之后每一个 Epoch 的学习率的衰减率,让学习率逐渐衰减是提高训练效率的有效方法
epochNum = 30 # 轮次
hidden_units=128,
layers=2 # LSTM 层数 2
"""
from config import *
import config
import data
import word2vec_demo
import Flask_server
from word2vec_demo import Word2vec_similar
class MODEL():
Imbalance_words='' # 记录生僻字(由word2vec模型返回的)
def __init__(self, trainData):
self.trainData = trainData
def buildModel(self, wordNum, gtX, hidden_units=128, layers=2):
"""build rnn
wordNum 整个诗歌训练集中字的总个数
"""
# 搭建一个LSTM模型,后接softmax,输出为每一个字出现的概率。
# 这里对着LSTM模板,改改参数。
with tf.variable_scope ("embedding"): # embedding
# 创建 词向量(Word Embedding),Embedding 表示 Dense Vector(密集向量)
# 词向量本质上是一种单词聚类(Clustering)的方法
# wordNum 全体训练集合 字的总数
embedding = tf.get_variable ("embedding", [wordNum, hidden_units], dtype=tf.float32)
# embedding_lookup 返回词向量, gtX= {batchNum首诗对应的 id}
# inputbatch = [wordNum, hidden_units, batchSize]
inputbatch = tf.nn.embedding_lookup (embedding, gtX)
# 创建一个 LSTM 层,其中的神经元数目是 hidden_units = 128
basicCell = tf.contrib.rnn.BasicLSTMCell (hidden_units, state_is_tuple=True)
# 这里只给 输出 加了 Dropout 操作,留存率(output_keep_prob)是 0.5
# 保存上一层0.5*信息量
# 输入则是默认的 1,所以相当于输入没有做 Dropout 操作
# basicCell = tf.contrib.rnn.DropoutWrapper (basicCell, output_keep_prob=dropout)
# 如果 LSTM 的层数大于 1, 则总计创建 layers 个 LSTM 层
# 并将所有的 LSTM 层包装进 MultiRNNCell 这样的序列化层级模型中
stackCell = tf.contrib.rnn.MultiRNNCell ([basicCell] * layers)
initState = stackCell.zero_state (np.shape (gtX)[0], tf.float32)
# dynamic_rnn(动态 RNN)可以让不同迭代传入的 Batch 可以是长度不同的数据
# 但同一次迭代中一个 Batch 内部的所有数据长度仍然是固定的
# dynamic_rnn 能更好处理 padding(补零)的情况,节约计算资源
# 返回两个变量:
# 第一个是一个 Batch 里在时间维度(默认是 35)上展开的所有 LSTM 单元的输出,形状默认为 [batch_size ,num_steps, hidden_size],之后会经过扁平层处理
# 第二个是最终的 state(状态),包含 当前时刻 LSTM 的输出 h(t) 和 当前时刻的单元状态 C(t)
# outputs =[1,?,128]
outputs, finalState = tf.nn.dynamic_rnn (stackCell, inputbatch, initial_state=initState)
# 扁平化处理,改变输出形状为 (batch_size * num_steps, hidden_size),# -1 表示 自动推导维度大小
outputs = tf.reshape (outputs, [-1, hidden_units])
with tf.variable_scope ("softmax"):
w = tf.get_variable ("w", [hidden_units, wordNum])
b = tf.get_variable ("b", [wordNum])
# logits 是 Logistic Regression(用于分类)模型(线性方程: y = W * x + b )计算的结果(分值)
# 这个 logits(分值)之后会用 Softmax 来转成百分比概率
# output 是输入(x), softmax_w 是 权重(W),softmax_b 是偏置(b)
# 返回 W * x + b 结果
logits = tf.matmul (outputs, w) + b
# Softmax 算出来的概率
probs = tf.nn.softmax (logits)
# logits Logistic模型计算结果, probs 概率值,stackCell序列化层级模型, initState初始状态, finalState最终状态
return logits, probs, stackCell, initState, finalState
# 训练自己的 LSTM模型
def train(self,checkpointsPath,reload=True):
"""train model"""
print("training...")
# 先定义输入输出,构建模型,然后设置损失函数、学习率等参数
gtX = tf.placeholder(tf.int32, shape=[batchSize, None]) # input
gtY = tf.placeholder(tf.int32, shape=[batchSize, None]) # output
logits, probs, a, b, c = self.buildModel(self.trainData.wordNum, gtX)
targets = tf.reshape(gtY, [-1])
# loss
# logits =[batch_size , num_steps, vocab_size]
# targets = [batch_size , num_steps]
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example ([logits], [targets],
[tf.ones_like(targets, dtype=tf.float32)])
globalStep = tf.Variable (0, trainable=False)
# addGlobalStep = globalStep.assign_add (1)
# 更新代价(cost)
cost = tf.reduce_mean(loss)
# 返回所有可被训练(trainable=True。如果不设定 trainable=False,默认的 Variable 都是可以被训练的)
# 也就是除了不可被训练的 学习率 之外的其他变量
trainableVariables = tf.trainable_variables()
# tf.clip_by_global_norm(实现 Gradient Clipping(梯度裁剪))是为了防止梯度爆炸
# tf.gradients 计算 self.cost 对于 tvars 的梯度(求导),返回一个梯度的列表
# grads 梯度列表
grads, a = tf.clip_by_global_norm (tf.gradients (cost, trainableVariables),5)
# 更新 学习率
learningRate = tf.train.exponential_decay(learningRateBase, global_step=globalStep,
decay_steps=learningRateDecayStep,
decay_rate=learningRateDecayRate)
# 优化器
optimizer = tf.train.AdamOptimizer(learningRate)
# apply_gradients(应用梯度)将之前用(Gradient Clipping)梯度裁剪过的梯度 应用到可被训练的变量上去,做梯度下降
# apply_gradients 其实是 minimize 方法里面的第二步,第一步是 计算梯度
trainOP = optimizer.apply_gradients(zip(grads, trainableVariables))
globalStep = 0
# 然后开始训练,训练时先寻找能否找到检查点,找到则还原,否则重新训练。
# 然后按照batchSize一步步读入数据训练,学习率逐渐递减,每隔几个step保存一下模型。
with tf.Session () as sess:
sess.run (tf.global_variables_initializer())
saver = tf.train.Saver ()
if not os.path.exists( checkpointsPath):
os.mkdir(checkpointsPath)
if reload:
checkPoint = tf.train.get_checkpoint_state(checkpointsPath)
# if have checkPoint, restore checkPoint
if checkPoint and checkPoint.model_checkpoint_path:
saver.restore(sess, checkPoint.model_checkpoint_path)
# print("restored %s" % checkPoint.model_checkpoint_path)
else:
print("no checkpoint found!")
for epoch in range (epochNum):
X, Y = self.trainData.generateBatch()
if globalStep % learningRateDecayStep == 0: # 每隔 1000 步学习率下降
learningRate = learningRateBase * (0.95 ** epoch)
epochSteps = len(X) # equal to batch
for step, (x, y) in enumerate(zip(X, Y)):
""""
X,Y =[batchNum 行,[batchSize行,[一首诗 id]]] 三位向量
x,y = [batchSize,一首诗 id] ,x 为每次训练的输入 [ batchSize, maxLength] 二维向量
"""
globalStep = epoch * epochSteps + step + 1
# trainOp 操作:计算被修剪(clipping)过的梯度,并最小化 cost(误差)
# state 操作:返回时间维度上展开的最后 LSTM 单元的输出(C(t) 和 h(t)),作为下一个 Batch 的输入状态
a, loss = sess.run ([trainOP, cost], feed_dict={gtX: x, gtY: y})
print ("epoch: %d, steps: %d/%d, loss: %3f" % (epoch + 1, step + 1, epochSteps, loss))
if globalStep % 10000 == 0: # prevent save at the beginning
print ("save model")
saver.save(sess, os.path.join (checkpointsPath, type), global_step=globalStep)
# 判断 2个字是否押韵
def Judge_Twowords_Yayun(word1, word2):
Yayun = word1
f = open ("E:\Desk\MyProjects\Python/NLP_Demo1/Yayun_words.txt", 'r', encoding='utf-8')
array = []
count=0
while True:
line = f.readline()
if not line:
break;
count += 1 # 记录总共多少行
line = str (line)
array.append (line.replace (" ", "").replace (" ", ""))
f.close ()
for i in range(count):
if Yayun in array[i]:
index = i
break
flag = False
if word2 in array[index]:
flag = True
# print(index)
# print(array[index])
return flag
def Judge_word_in_Yayuntable(word):
with open ("E:\Desk\MyProjects\Python/NLP_Demo1/Yayun_words.txt", 'r', encoding='utf-8') as f:
content = f.read()
if word in content:
return True
else:
return False
def probsToWord(self,probs2, words, word_list):
"""在自动写诗之前,我们需要定义一个输出概率对应到单词的功能函数,
为了避免每次生成的诗都一样,需要引入一定的随机性。不选择输出概率最高的字,
而是将概率映射到一个区间上,在区间上随机采样,输出概率大的字对应的区间大,
被采样的概率也大,也有小概率会选择其他字。 因为每一个字都有这样的随机性,所以每次作出的诗都完全不一样
"""
k = 6 # 前 k 个最高概率值
probs2 = probs2.tolist() # np.array() --> list
probs2 = probs2[0]
arr = np.array(probs2)
top_k_idx = arr.argsort()[::-1][0:k]
top_k_prob = []
top_k_value =[]
for i in range(k):
id_index = top_k_idx[i]
top_k_prob.append(probs2[id_index])
top_k_value.append(words[id_index])
# 若在诗学含英中 0.15 + 概率值归一化后 * 0.85 ,选择最大值
num = [top_k_prob[i]/sum(top_k_prob) for i in range(k)]
# print(num)
num = 0.85 * np.array(num)
for i in range(k):
if top_k_value[i] in word_list:
num[i] = 0.15+ num[i]
num = list(num)
index = num.index(max(num))
word = top_k_value[index]
return word
def probsToWord2(self, weights, words,odd):
while True:
prefixSum = np.cumsum(weights) # 列表概率,一次迭代相加
ratio = np.random.rand(1) # 随机0-1 值
index = np.searchsorted(prefixSum ,ratio * prefixSum[-1]) # 确定映射区间
re_word = words[index[0]]
# y = [float(temp)/np.sum(weights) for temp in weights] # 按权重归一化处理
# r = np.random.rand(1) # 随机生成(0,1)之间的值
# prosum = np.cumsum(y) # 累加区间
# index = np.searchsorted (prosum, r)# 确定映射区间
# re_word= words[index[0]]
if odd ==1:
if MODEL.Judge_word_in_Yayuntable(re_word):
config.Yayun = re_word
config.Yayunlist.append(re_word)
print(config.Yayun)
return re_word
elif odd != 1 and MODEL.Judge_Twowords_Yayun(config.Yayun,re_word) and config.Yayun !=re_word: # 四六八 句
config.Yayunlist.append(re_word)
print(re_word)
return re_word
def testHead(self, characters,Imbalance_words,checkpointsPath,Num,JueLv):
"""write head poem
写藏头诗,前面的搭建模型,加载checkpoint等内容一样,作诗部分,每遇到标点符号,人为控制下一个输入的字
(此处是从候选集中挑选)为指定的字就可以了。
需要注意,在标点符号后,因为没有选择模型输出的字,所以需要将state往前滚动一下,直接跳过这个字的生成
"""
print ("generating...")
Everywords_num = Num # 五七言
WORDS_NUM = JueLv # 绝句/律诗
WORDS_NUM = int(WORDS_NUM)
Everywords_num = int(Everywords_num)
word_list = Word2vec_similar.label_offen_words(characters)
gtX = tf.placeholder (tf.int32, shape=[1, None]) # input
# logits Logistic模型计算结果, probs 概率值,stackCell序列化层级模型, initState初始状态, finalState最终状态
logits, probs, stackCell, initState, finalState = self.buildModel(self.trainData.wordNum, gtX)
with tf.Session() as sess:
sess.run (tf.global_variables_initializer())
# 为了用 Saver 来恢复训练时生成的模型的变量
saver = tf.train.Saver ()
checkPoint = tf.train.get_checkpoint_state(checkpointsPath)
# if have checkPoint, restore checkPoint
if checkPoint and checkPoint.model_checkpoint_path:
print("restored %s" % checkPoint.model_checkpoint_path)
# 恢复被训练的模型的变量
saver.restore(sess, checkPoint.model_checkpoint_path)
else:
print("no checkpoint found! ")
exit(1)
flag= 1
endSign = {-1: "," , 1: "。"}
poem = ''
state = sess.run(stackCell.zero_state(1,tf.float32))
x = np.array([[self.trainData.wordToID['[']]])
probsl, state = sess.run([probs, finalState] , feed_dict={gtX: x, initState:state})
# 设置开头字
#### 修改开头字 imbalance_words 差额字 --> 补齐
l = WORDS_NUM-len(characters)
if l>0:
"""此处是以用户输入关键词来做前几句诗的开头字
也可以省略,不做藏头诗。而只用相关词来做开头字
"""
# 先是以关键词作为每句的开头字,后加入相似词(可修改)
line = characters
for i in range(0,len(Imbalance_words)):
line = str(line)
s = str(Imbalance_words[i])
line = line + s
# 备选字去重
repare_str = []
repare_str.append(line[0])
for i in range(1,len(line)):
if line[0:i-1].count(line[i])==0:
repare_str.append(line[i])
# characters 为所有备选字
# 根据用户给定的 WORDS_NUM 控制诗句数量,从候选词中挑选每句开头字
limit_str = ['' for i in range(WORDS_NUM)]
random.shuffle(repare_str) # 打乱候选字 列表中的顺序
repare_str = ''.join(repare_str)
for i in range(WORDS_NUM):
if repare_str[i] !=' ':
limit_str[i] = repare_str[i]
characters= limit_str
print(characters)
count = WORDS_NUM
odd = 0 # 标记偶数句,做押韵处理
for word in characters:
if self.trainData.wordToID.get(word) == None:
print("此字不在全唐诗中")
# exit(0)
flag = -flag
Everywords = 0
# 控制 七言诗/五言诗
while Everywords < Everywords_num:
if word not in [']', ',', '。', ' ', '?', '!']:
poem += word
before_word = word # 时刻记录前一个字,当遇到 ,。时
x = np.array([[self.trainData.wordToID[word]]])
probs2, state = sess.run([probs, finalState], feed_dict={gtX: x, initState: state})
# (二四六八)句最后一字押韵处理
if Everywords ==(Everywords_num-2) and odd%2 ==1:
word = self.probsToWord2(probs2,self.trainData.words,odd)
else:
word = self.probsToWord(probs2, self.trainData.words,word_list)
Everywords += 1
elif word in [']', ',', '。', ' ', '?', '!'] and Everywords < Everywords_num:
x = np.array([[self.trainData.wordToID[before_word]]])
probs2, state = sess.run ([probs, finalState], feed_dict={gtX: x, initState: state})
word = self.probsToWord(probs2, self.trainData.words,word_list)
poem += endSign[flag]
count = count -1
if endSign[flag] == '。':
odd +=1
probs2, state = sess.run([probs, finalState],
feed_dict={gtX:np.array([[self.trainData.wordToID["。"]]]), initState: state})
poem =poem + '\n'
else:
odd +=1
probs2, state = sess.run([probs, finalState],
feed_dict={gtX: np.array([[self.trainData.wordToID[","]]]), initState: state})
# print(characters)
# print(poem)
return 5、数据集:
在model.py文件中,包括了押韵字的处理,从《诗学含英》中挑选本类诗常用字处理。
整个LSTM模型应用tensorflow框架实现,共生成了5个LSTM模型,分别对应于5类诗。可以自己调用train函数尝试生成模型。
我已经生成好的模型:
链接:https://pan.baidu.com/s/14pGa3GSUSVvSHkMZYi0xkQ
提取码:roij