05古诗生成项目(pytorch)(观看b站视频的笔记,代码即将实现)
项目来源:B站上的up主
jucheng《基于pytorch_LSTM古诗生成》 https://www.bilibili.com/video/BV1G54y177iw真的是一个宝藏up主,讲解很详细,而且声音跟我的很像?有那么一瞬间我感觉我听见了回声,也许是错觉,也是立即点了一个关注。代码、数据可以去他的网站上领取:http://www.zifuture.com:8090/archives/jiyu-lstm-gushi-cangtoushi)
下面是学习笔记,但是说实话up主在视频中手写的过程才是最大的精华。本文手写图片都来自视频的截图!!
处理流程:
- 字向量训练(word2vec)
- 封装数据
- 组合模型(LSTM+Linear、GRU+Linear)
- 训练
- 生成与测试
字向量训练(word2vec)
调用gensim
字向量简介:
举头望明月,低头思故乡。
对应词库:举/头/望/明/月/,/低/ 思/故/乡/。/
第二个头没了,因为词库需要“唯一”、“不重复”。

词库大小:word_size:11(词库中字的数量)
词向量维度:embedding_num:128
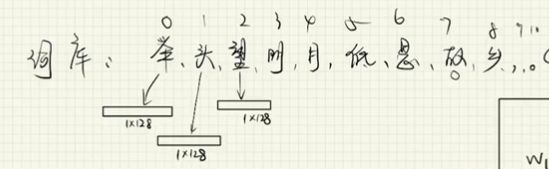
index2word: 比如0对应”举“的1128这个向量,1对应着”头“这个1128向量
word2index:反之亦然。
最终得到三个矩阵:
- 11*128的那个词向量矩阵
- word2index字找索引
- index2word索引找字
封装数据(将数据处理成需要的样子)
原始数据:
古诗一行一行的(共3000首左右);
batch_size = 5:每次放5首古诗;
word_size = 3542 词库大小(up主的训练集一共有3542个不同的字);
embedding_num = 128 一般在100-300之间;
x = ‘一首诗,结尾的字省去’
y = ‘x对应下一个字’
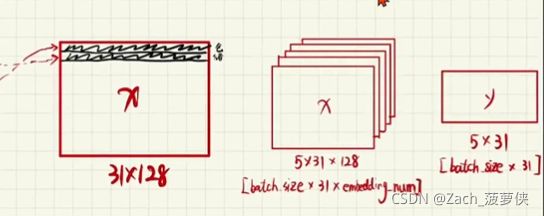
将x每个字变成索引,再转化为对应数字(word2index),y同理;
形成向量:将句子表示出来31个字*128每个字的
x 5首古诗(5行古诗)31个字128个向量(与字一一对应)
y 5首诗 5 * 31对应字库索引(y不用构建向量)
组合模型(LSTM+Linear、GRU+Linear)
使用已有pytorch框架
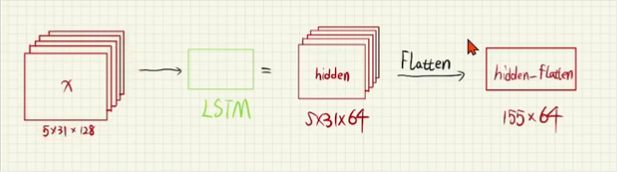
- LSTM前的步骤完成后
- 将数据集输入到LSTM中,设置其hidden_num(隐层数) = 64 隐层大小结果为:生成531hudden_num;实际上将X变短了或者拉长了
- 再进行flatten(压平)变成二维的:155 * hidden_num (将五首诗看作一首长诗,一共315个字)
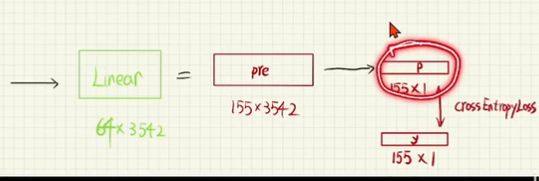
再进行Linear(映射)得到64 3542(进行矩阵相乘得到pre)(3542是字库大小,目标是选出3542个字中,下一个可能性最大的那个,即为p) - 最后p(155* 1)与 y(155* 1)进行对比(交叉损失函数进行比较)
训练
略
生成与测试
- 输入11128 (一个字)
- 经过LSTM继续变成隐层维度1164,经过flatten164,经过linear层13542,即在3542个字中选出可能性最大的那个索引,最后index2word,得到对应字。
- 对应字重新作为输入,再进行循环。
项目展示(有时间补坑,粗略看了up主的代码,
最后代码没来得及写,但是对函数做了个分析:
Word2Vec的参数详细研究:

Word2Vec(=sentences=None=, # 在本项目中是一首诗(经过"加空格"处理)
corpus_file=None, # 语料库文件:str,可选语料库文件的路径:class:~gensim.models.word2vec.LineSequence格式。您可以使用此参数而不是“句子”来提高性能。只有一个“句子”或需要传递corpus_file参数(或者不传递任何参数,在这种情况下,模型保持未初始化状态)。
vector_size=100, # 向量大小:int,可选词向量的维数。
alpha=0.025, # alpha:float,可选初始学习率。
window=5, # int,可选句子中当前单词和预测单词之间的最大距离。
min_count=5, # 最小计数:整数,可选忽略总频率低于此值的所有单词。因为古诗很稀疏,所以一定要设置为1!!
max_vocab_size=None, # int,可选在词汇构建过程中限制RAM;如果有更独特的比这更多的词,然后删掉不常出现的词。每1000万字类型需要大约1GB的RAM。设置为“无”表示无限制。
sample=0.001, # 示例:float,可选配置随机下采样的高频字的阈值,有效范围为(0,1e-5)。
seed=1, # int,可选随机数生成器的种子。每个单词的初始向量都以哈希值作为种子
workers=3, # int,可选使用这些多个辅助线程来训练模型(使用多核机器进行更快的训练)。
min_alpha=0.0001, # float,可选随着培训的进行,学习率将线性下降至“最低阿尔法”。
sg=0, # sg:{0,1},可选训练算法:1为跳转图;否则CBOW。
hs=0, # hs:{0,1},可选如果为1,则分层softmax将用于模型训练。
negative=5, # int,可选如果>0,将使用负采样,负的int指定有多少个“噪声字”应绘制(通常在5-20之间)。如果设置为0,则不使用负采样。
ns_exponent=0.75, # float,可选用于塑造负采样分布的指数。完全按比例的1.0个样本的值
对于频率,0.0对所有单词进行同等采样,而负值对低频单词进行更多采样而不是高频词。常用的默认值0.75是由最初的Word2Vec论文选择的。最近,在https://arxiv.org/abs/1804.04212Caselles Dupré、Lesaint和Royo Letelier建议对于推荐应用程序,其他值的性能可能更好。
cbow_mean=1, # {0,1},可选如果为0,则使用上下文单词向量之和。如果1,则使用平均值,仅在使用cbow时适用。
hashfxn=, # function ,可选散列函数用于随机初始化权重,以提高训练的再现性。
epochs=5, # int,可选语料库上的迭代次数(历次)。(原名为“国际热核实验堆”)
null_word=0, # 未找到???
trim_rule=None, # function,可选,词汇修剪规则,指定是否应保留词汇表中的某些单词、是否应修剪掉或使用默认值(如果单词计数<最小计数,则放弃)。可以为None(将使用最小计数,请参阅:func:~gensim.utils.keep_vocab_item),或接受参数(单词、计数、最小计数)的可调用项并返回:attr:gensim.utils.RULE_DISCARD、:attr:gensim.utils.RULE_KEEP或:attr:gensim.utils.RULE_DEFAULT。如果给定了该规则,则该规则仅用于在构建过程中修剪词汇表,而不是作为模型的一部分存储。
sorted_vocab=1, # {0,1},可选如果为1,请在指定单词索引之前按降序对词汇表进行排序。请参阅:meth:~gensim.models.keyedvectors.keyedvectors.sort by_descending_frequency()。
batch_words=10000, # 批处理字:int,可选传递给工作线程的示例批的目标大小(大写)(和
因此,cython例程。)(如果单个文本长度超过10000个单词,但标准cython代码将截断到该最大值。)
compute_loss=False,# 计算损耗:布尔,可选如果为True,则计算并存储可以使用:方法:~gensim.models.word2vec.word2vec.get\u latest\u training\u loss。
callbacks=(), # 回调:iterable of:class:~gensim.models.callbacks.CallbackAny2Vec,可选,在培训期间特定阶段执行的回调顺序。收缩窗口:布尔,可选
comment=None, # ??未找到
max_final_vocab=None, # int,通过自动选取匹配的最小值计数,将vocab限制为目标vocab大小。如果指定最小计数大于计算的最小计数,将使用指定的最小计数。如果不需要,则设置为“无”。
shrink_windows=True # 收缩窗口:布尔,可选在4.1中新增。实验的如果为True,则从[1,window]中均匀采样有效窗口大小对于训练期间的每个目标单词,匹配原始word2vec算法的上下文词按距离的近似权重。否则,有效的窗口大小始终固定为两边的“窗口”字。
)
sentences就是给的这个数据集(当然是很多行就不截图了):
又留了个坑呢,哎,时间太珍贵了,等有空了一定补坑!!