2020李宏毅机器学习笔记——19. Transformer(全自注意力网络)
摘要: 本章主要是介绍了Transformer(全自注意力网络),首先通过sequence-to-sequence模型中的RNN存在问题——不能并行计算,CNN替换可以解决一部分问题,但也存在缺陷。是便引入了Self-Attention Layer来替代RNN的sequence-to-sequence模型——Transformer,之后讲解Self-Attention的基本原理与具体过程。接着增加了一种叫做“多头”注意力(“multi-headed” attention)的机制,进一步完善了自注意力层。以及为了解决在Self-Attention中词的顺序信息是不重要的问题,而提出Position Encoding操作。再其次重点是Transformer的整体架构,Transformer采用了Encoder-Decoder框架,以机器翻译为具体实例做了过程讲解;最后是Attention visualization(可视化)与Transformer的实际应用和变形。
文章目录
- 1. Transformer的引入
- 2. Self-Attention
-
- 2.1 Self-attention 的具体过程
- 2.2 Self-attention是如何并行计算的?( 矩阵运算)
- 2.3 Multi-head Self-attention
- 2.4 Position Encoding(位置嵌入)
- 2.5 Seq2Seq with Attention
- 3. Transformer(架构)
- 4. Attention visualization
- 5. transformer的应用
- 6. 总结与展望
1. Transformer的引入
一般的sequence-to-sequence模型是用RNN(单方向或者双向)来做,RNN输入是一串sequence,输出是另外一串sequence。RNN常被用于input是一个序列的情况,但是有一个问题——不容易平行化(并行化计算)。
例如下图中左边的模型就是RNN结构的sequence-to-sequence模型,(假设是单向RNN)想要求出b4就得先从a1输入开始一步一步往后求,直到求出b4,而不能对a1,a2,a3,a4一起计算。如下图左侧:
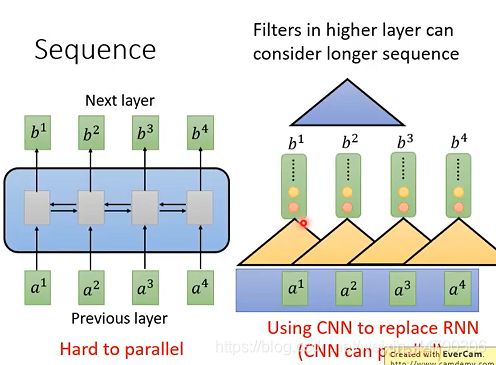
解决方法:为了能够进行并行计算,于是提出了使用CNN代替RNN的方法,如上图右侧基于CNN的sequence-to-sequence模型:
- 将三个vector的内容串起来与filter内部的参数做内积,得到一个数值,将filter扫过sequence,产生一排不同的数值。
- 会有多个不同(颜色不同)的filter,产生另外一排不同的数值。
用CNN也可以做到和RNN类似的效果:输入一个sequence,输出一个sequence,表面上CNN和RNN都可以有同样的输入输出。但是每个CNN只能考虑很有限的内容(三个vector),而RNN是考虑了整个句子再决定输出。
其实CNN也可以考虑更长的信息,只要叠加多层CNN,上层的filter就可以考虑更加多的信息。
使用CNN的优点:可以并行化计算,全部的filter可以同时进行计算。
使用CNN的缺陷:是必须叠加多层filter,才可以看到长时间的信息,如果要在第一层filter就要看到长时间的信息,那是无法做到的。
那要怎么解决使用CNN的缺陷呢?
于是,我们引入了 一个新的想法:Self-Attention!
2. Self-Attention
首先我们知道Transformer是用Self-Attention Layer来替代RNN的sequence-to-sequence模型。Transformer模型在质量上更优越,同时更具可并行性,并且需要的训练时间更少。
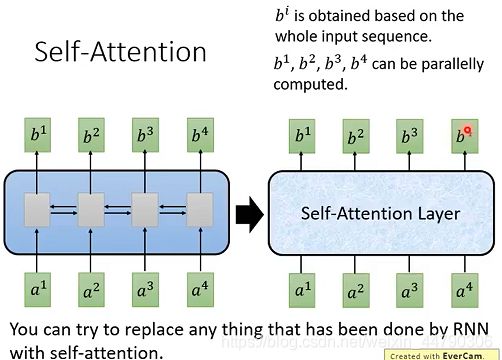
Self-Attention做的事情就是取代RNN原本要做的事情,Self-Attention Layer 与双向RNN有同样的能力,每一个输出都是看过整个input sequence,并且 b1,b2, b3, b4 是可以同时算出来的,可以并行计算!如下图:
2.1 Self-attention 的具体过程
Self-attention is all you need
第一步:
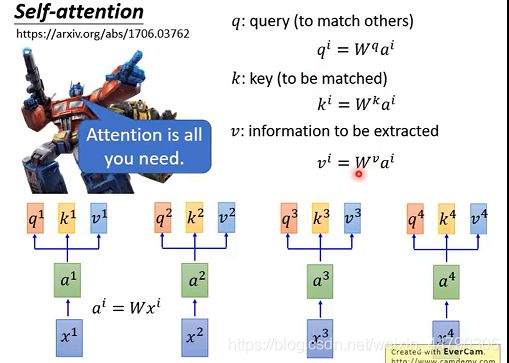
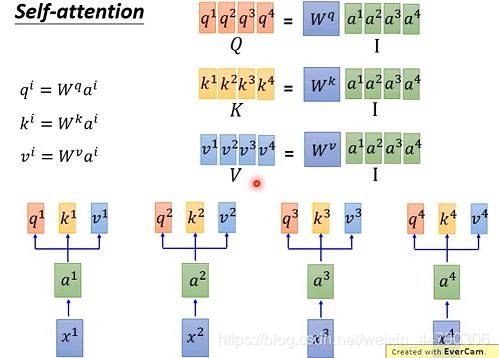
输入sequence x1~x4,通过乘上一个W matrix来得到embedding a1~a4,丢入Self-attention,每一个输入都分别乘上三个不同的transformation matrix,产生三个不同的vector q,k,v。其中vector q,k,v分别代表:(如下图:)
- q代表query,用来match其他人
- k代表key,用来被query匹配的
- v代表要被抽取出来的information
第二步:
拿每个query q去对每个key k 做attention,我们这里用到的计算attention的方法是scaled dot-product Attention ,attention本质就是输入两个向量,输出一个分数。(做attention的方法有很多)
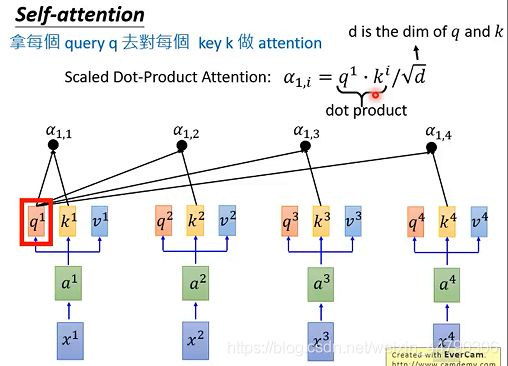
除以 d \sqrt{d} d 的原因:d是q和k的维度,q和k做inner product,所以q和k的维度是一样的为d。除以 d \sqrt{d} d 的直观解释为q和k做内积/点乘的数值会随着维度增大 ,它的variance越大,所以除以来 d \sqrt{d} d 平衡。
第三步:
通过一个softmax函数(下图右上角),将α11—α14变形得到一个新的α^ (11-14),然后用变形α^(11-14)分别乘以Vi 然后求和计算得到b1 。
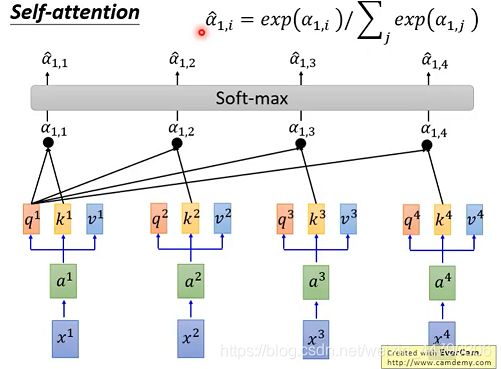
下图是计算b1的过程,其中是考虑了全部的sequence:
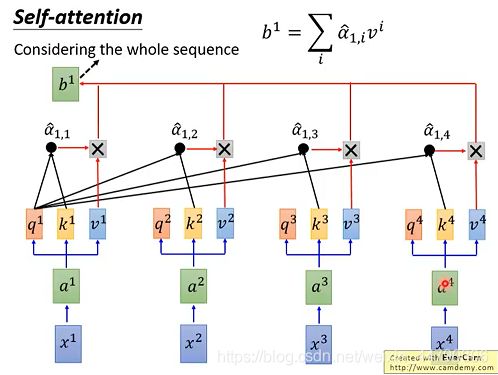
并且可以同时计算b2,b3,b4,同理可得:

self-attention做的和双向RNN的事情是一样的,只不过self-attention是可以平行计算的!整体流程如下图:
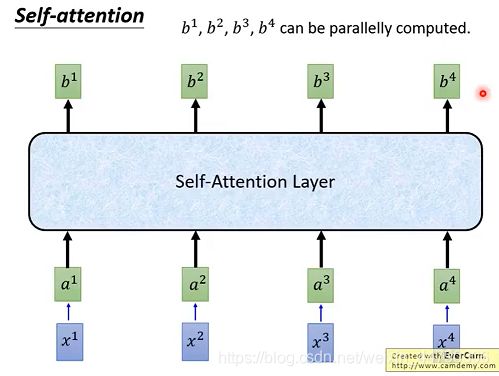
self-attention和全连接有什么区别?
全连接:可以看做特征映射,其权重表示的是特征的重要度
self-attention:并不是一种映射,其权重表示的是序列每个实体的重要度
2.2 Self-attention是如何并行计算的?( 矩阵运算)
self-attention中所有的运算都可以利用矩阵来进行运算,因此我们就可以使用GPU来进行加速,极大的加快了我们的运算速度。
用矩阵运算的形式来表现:
self-attention的第一步,矩阵运算就是将a1~a4拼起来作为一个matrix I I I,用 I 再乘以 W q W^q Wq ,一次得到matrix Q Q Q,里面的每一列代表一个q。同理,将matrix I乘以 W k W^k Wk 和 W v W^v Wv,可以得到相应的matrix K K K和marix V V V。如下图:
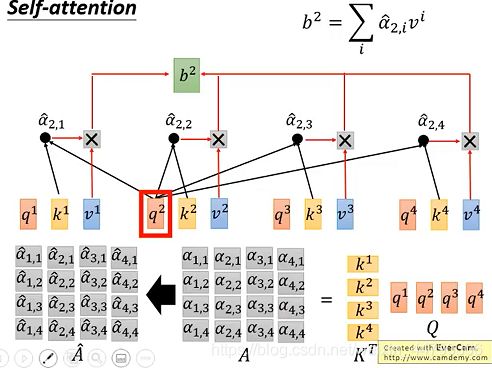
self-attention的第二步,拿query q去对每个key k做attention计算:将k1到k4串起来,组成矩阵K,之后转置为 K T K^T KT; 再将q1到q4串起来组成矩阵Q ,具体过程如下图:
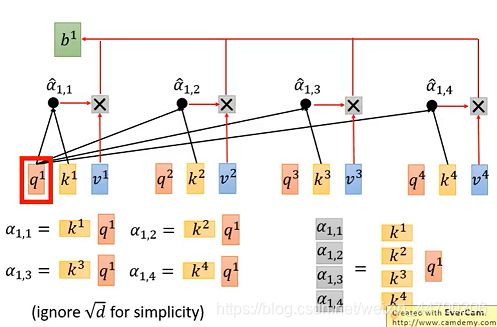
self-attention的第三步,将做矩阵运算 K T K^T KT* Q=A,将A按列softmax之后,就可得到新的A^,如下图:
self-attention的第四步,把v1到v4串成矩阵V,将矩阵A^ 每一列分别和矩阵V点乘得到矩阵O,从而得到我们的一个输出。如下图所示:
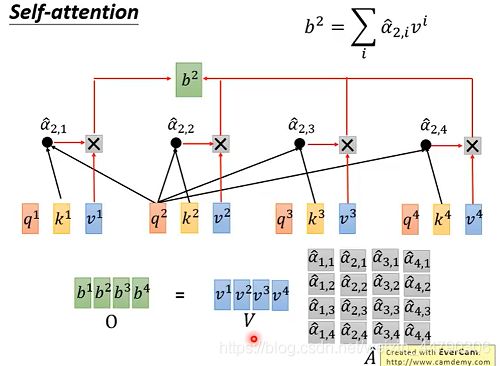
最后,我们将所有矩阵运算整合起来,来回顾一下整个流程:

整个过程就是输入序列I,输出序列O,可以看到从输入到输出是一堆矩阵乘法,所以GPU可以很容易加速!
2.3 Multi-head Self-attention
增加一种叫做“多头”注意力(“multi-headed” attention)的机制,进一步完善了自注意力层,并在两方面提高了注意力层的性能:
- 扩展了模型专注于不同位置的能力
- 给出了注意力层的多个“表示子空间”(representation subspaces)
多头注意力相当于多个不同的自注意力的集成。通过矩阵运算,原本的q,k,v实际进行了降维。
多头注意力机制允许模型在不同的表示子空间(representation subspaces里学习到相关的信息,每个head关注的地方不同,各司其职。如下图:
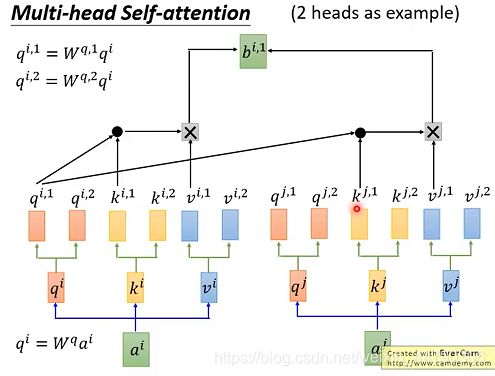
注意:每个头只能和对应的头进行运算。比如: q i , 2 q^{i,2} qi,2, 只能和对应的 k i , 2 k^{i,2} ki,2, 以及 k j , 2 k^{j,2} kj,2进行运算。
多头计算的结果可以矩阵拼接起来,经过矩阵运算,保持和单头的运算结果维度相同。如下图:
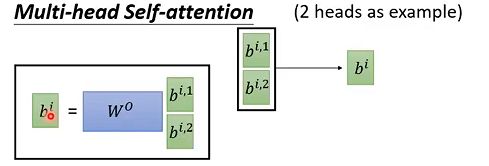
总的来说,多头注意力机制在保持参数总量不变的情况下,将同样的query, key和value映射到原来的高维空间(Q,K,V)的不同子空间( Q 0 Q^0 Q0, K 0 K^0 K0, V 0 V^0 V0$等)中进行自注意力的计算,最后再合并不同子空间中的注意力信息。
2.4 Position Encoding(位置嵌入)
self-attention的局限性
在注意力机制中,词的顺序信息是不重要的,其思想是:思想是天涯若比邻。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
具体做法:
在原始paper中, e i e^i ei是人手设置的,不是学习出来的。 e i e^i ei代表了位置信息,每个位置 e i e^i ei不同。paper中将 e i e^i ei 加上得到一个 a i a^i ai 新的vector,之后和Self-attention操作一样。如下图所示:

用one-hot编码解释加上 e i e^i ei的这个操作的合理性:
将 x i x^i xi append一个one-hot向量 p i p^i pi,其运算结果就相当于上述过程(加上 e i e^i ei)。如下图:

2.5 Seq2Seq with Attention
首先一般的seq2seq model 包含两个RNN,分别是encoder和decoder,之后将RNN用self-attention替换,其他的操作与之前是一样的。如下图:

3. Transformer(架构)
基本框架(Encoder-Decoder):用中译英的一个seq2sqe模型框架举例
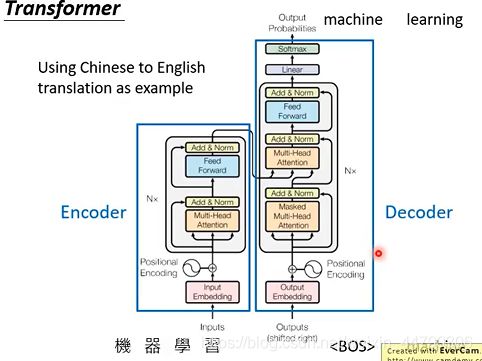
更加具体一步的过程:
Encoder编码器
在 Encoder 中,Input 经过 embedding 后,要做 positional encodings
Encoder由N层相同的层组成,每一层包括2个sub-layers:
- 第一部分是 multi-head self-attention,然后是做Add &Norm
- 第二部分是 position-wise feed-forward network,是一个全连接层,接着也是做Add &Norm
注意:Add &Norm操作是残差连接(输入和输出加起来)与Layer Normalization
Decoder解码器
操作与encoder 类似,decoder 也是由N个相同的层组成,但每一个层包括以下3个sub-layers:
- 第一个部分是 masked multi-head attention(表示attention时会注意到已经产生的sequence)
- 第二部分是 multi-head attention (表示attend 到之前encoder的输出)
- 第三部分是一个 position-wise feed-forward network
注意:
- 上面三个部分的每一个部分,都有一个Add &Norm(残差连接,后接一个 Layer Normalization)。
- decoder 和 encoder 不同的地方在 masked multi-head attention
在上述机器翻译任务中,编码器(Encoder)对输入句子进行编码,将输入句子通过非线性变换转化为中间语义表示。解码器(Decoder)的任务是根据中间语义表示和之前已经生成的历史信息来预测未来时刻要生成的单词。最终,解码的特征向量经过一层激活函数为Softmax的全连接层之后得到表示每个单词概率的输出向量。
4. Attention visualization
如下图attention的weight越大,线条越粗,attention的weight越小,线条越细,图上两两word之间都会有attention。
下图上部分可以发现it和animal的attention很大,因为这个it是指animal。下部分当把tired改成wide后,it表示street,这时候it和street的attention变成最大的了。
多头注意力机制的可视化,不同的头捕捉到了不同的句法。在multi-head attention中,每一组Q、K、V,它们的作用都不一样,不同组Q、K、V的attention的可视化结果也不同。

如上图红色那组Q、K、V,表示attention下一个(或下几个)word,绿色那组Q、K、V,表示attention一个时间段的word。
5. transformer的应用
基本上原来可以做seq2seq的,都可以换成transformer!
- 做summarization(摘要)
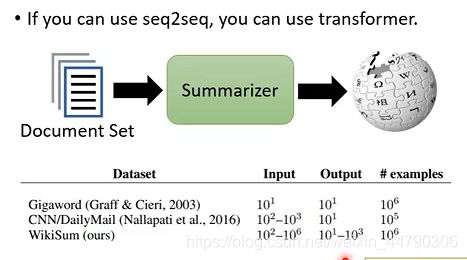
训练一个summarizer,input是一堆文章,output是一篇具有维基百科风格的文章。如果没有transformer,没有self-attention,很难用RNN产生 1 0 3 10^3 103长的sequence,而有了transformer以后就可以实现。 - 另外的一个版本Universal transformer
简单的概念是说,本来transformer每一层都是不一样,现在在深度上做RNN,每一层都是一样的transformer,同一个transformer的block不断的被反复使用。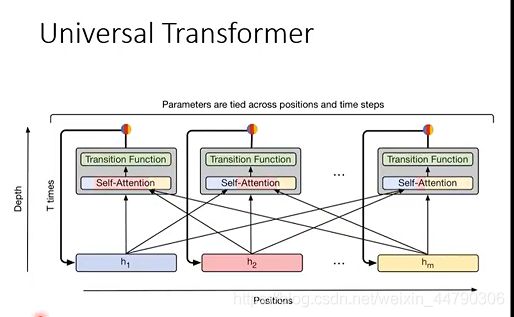
- 影像self-attention GAN
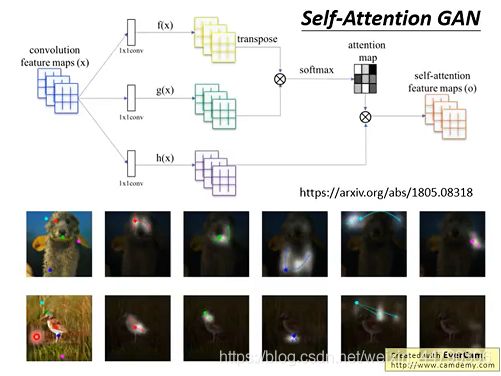
让每一个pixel都attend到其他的pixel,可以考虑比较全面的信息。
6. 总结与展望
本章围绕Self-Attention,其基本思想是计算不同部分的权重后进行加权求和,最后的效果是对attend的不同部分予以不同程度的关注。self-attention的基本计算基本都是矩阵计算,其最大的优点是不包含任何RNN、CNN结构,可以解决序列的长程依赖问题,同时矩阵计算可以因为并行化而非常快速。Transformer的(整体架构)Encoder和Decoder的结构详解,需要注意的是:
- Add&Norm环节,使用了残差网络和Layer Normalization;
- 解码器中第一处注意力机制叫Masked 多头注意力,因为在机器翻译中,解码过程是一个顺序操作的过程,当解码第k个特征向量时,我们只能看到第k-1及其之前的解码结果。
- 解码器中第二处注意力机制计算是Encoder-Decoder Attention,是用编码器的最终输出和解码器自注意力输出作attention。
由于RNN系列的模型,无法并行计算;并且Transformer的特征抽取能力比RNN系列的模型要好。之后是Transformer的实际应用,基本上是可以使用seq2seq的都可以使用Transformer。在文章集摘要上表现得十分强大,以及会在影像Self-attention GAN 结合,会有很好的效果!