图解Transformer 原理
1. 整体结构
Transformer整体结构:
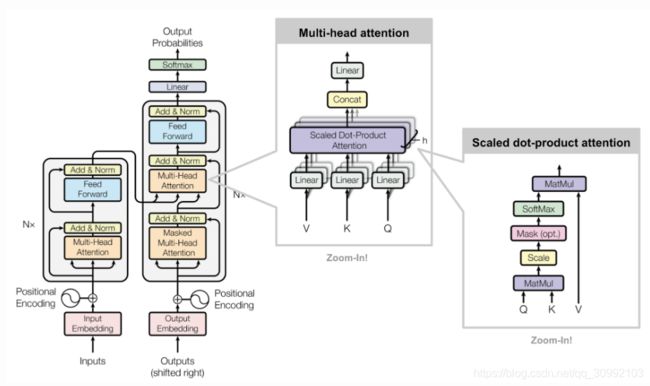
从图中可以看出,整体上Transformer由四部分组成:
1. Inputs : Inputs= WordEmbedding(Inputs) + PositionalEmbedding
2. Outputs: Ouputs=WordEmbedding(Outputs)+PositionalEmbedding
3. Encoders stack : 由六个相同的Encoder层组成,除了第一个Encoder层的输入为Inputs,其他Encoder层的输入为上一个Encoder层的输出
4. Decoders stack : 由六个相同的Decoder层组成,除了第一个Decoder层的输入为Outputs和最后一个Encoder层的输出,其他Decoder层的输入为上一个Decoder层的输出和最后一个Encoder层的输出
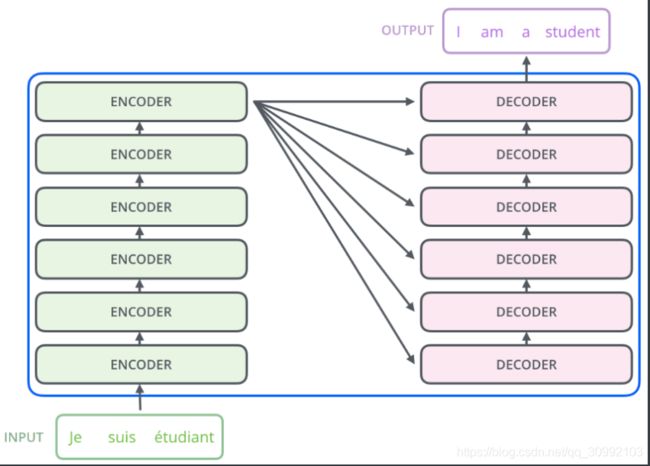
如下图所示,在更高的层级上来理解Encoder和Decoder层之间的输入和输出的关系,可以更直观。
而Encoder层和Decoder层的内部组成之间的差异如下图所示。每一个Encoder层都包含了一个Self-Attention子层和一个Feed Forward子层。每个Decoder层都包含了一个Self-Attention子层、一个Encoder-Decoder Attention子层和一个Feed Forward子层。Encoder层和Decoder层之间的差别在于Decoder中多了一个Encoder-Decoder Attention子层,而其他两个子层的结构在两者中是相同的。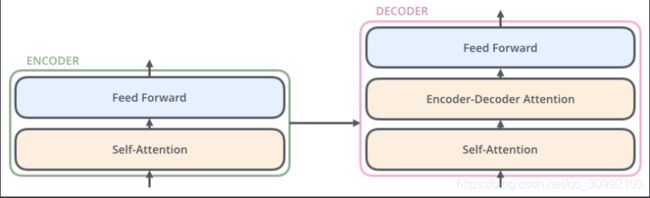
2. Self-Attention
2.1 为什么选择Self-Attention
首先通过一个简单的例子,来简单说明一下self-Attention这种机制较之传统的序列模型的优势所在。比如我们当前要翻译的句子为 The animal didn’t cross the street because it was too tired,在翻译it时,它究竟指代的是什么呢?要确定it指代的内容,毫无疑问我们需要同时关注到这个词的上下文语境中的所有词,在这句话中重点为animal, street, tired,然后根据常识,我们知道只有animal才会tired,所以确定了it指代的是animal。如果将tired改为narrow,那很显然it应该指的是street,因为只有street才能用narrow修饰。
Self-Attention机制在对一个词进行编码时,会考虑这个词上下文中的所有词和这些词对最终编码的贡献,再根据得到的信息对当前词进行编码,这就保证了在翻译it时,在它上下文中的animal, street, tired都会被考虑进来,从而将it正确的翻译成animal
那么如果我们采用传统的像LSTM这样的序列模型来进行翻译呢?由于LSTM模型是单向的(前向或者后向),显然它无法同时考虑到it的上下文信息,这会造成翻译的错误。以前向LSTM为例,当翻译it时,能考虑的信息只有The animal didn't cross the street because,而无法考虑was too tired,这使得模型无法确定it到底指代的是street还是animal。当然我们可以采用多层的LSTM结构,但这种结构并非像Self-Attention一样是真正意义上的双向,而是通过拼接前向LSTM和后向LSTM的输出实现的,这会使得模型的复杂度会远远高于Self-Attention。
下图是模型的最上一层(下标0是第一层,5是第六层)Encoder的Attention可视化图。这是tensor2tensor这个工具输出的内容。我们可以看到,在编码 it 的时候有一个Attention Head(后面会讲到)注意到了Animal,因此编码后的 it 有 Animal 的语义。

Self-Attention的优势不仅仅在于对词语进行编码时能充分考虑到词语上下文中的所有信息,还在于这种机制能够实现模型训练过程中的并行,这使得模型的训练时间能够较传统的序列模型大大缩短。传统的序列模型由于t时刻的状态会受到t−1时刻状态的影响,所以在训练的过程中是无法实现并行的,只能串行。而Self-Attention模型中,整个操作可以通过矩阵运算很容易的实现并行。
2.2 Self-Attention结构
为了能更好的理解Self-Attention的结构,首先介绍向量形式的Self-Attention的实现,再从向量形式推广到矩阵形式。
对于模型中的每一个输入向量(第一层的输入为词语对应的Embedding向量,如果有多层则其它层的输入为上一层的输出向量),首先我们需要根据输入向量生成三个新的向量:Q(Query)、K(Key)、V(Value),其中Query向量表示为了编码当前词需要去注意(attend to)的其他词(包括当前词语本身),Key向量表示当前词用于被检索的关键信息,而Value向量是真正的内容。三个向量都是以当前词的Embedding向量为输入,经过不同的线性层变换得到的。
下面以具体实例来理解Self-Attention机制。比如当我们的输入为thinking和machines时,首先我们需要对它们做Word Embedding,得到对应的词向量表示 x1, x2,再将对应的词向量分别通过三个不同的矩阵进行线性变换,得到对应的向量q1,k1,v1和q2,k2,v2。为了使得Query和Key向量能够做内积,模型要求WK、WQ的大小是一样的,而对WV的大小并没有要求。
q1=x1∗WQ1,k1=x1∗WK1,v1=x1∗WV1
q1=x1∗W1Q,k1=x1∗W1K,v1=x1∗W1V
q2=x2∗WQ2,k2=x2∗WK2,v2=x2∗WV2
q2=x2∗W2Q,k2=x2∗W2K,v2=x2∗W2V
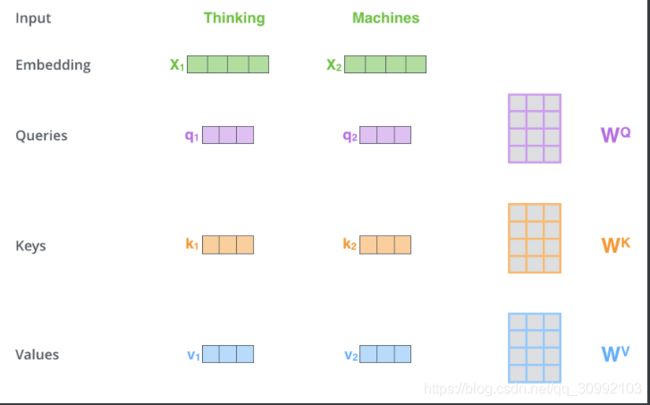
图中给出了上述过程的可视化,在得到所有的输入对应的qi、ki、vi
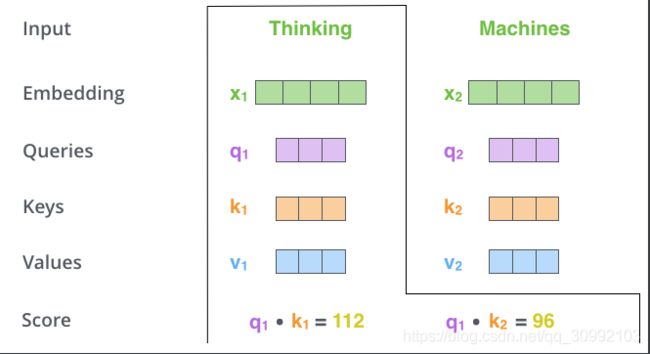
qi、ki、vi向量后,就可以进行Self-Attention向量的计算了。如下图所示,当我们需要计算thinking对应的attention向量时,首先将q1和所有输入对应的ki做点积,分别得到不同的Score
Score:
Score1=q1∗k1 Score2=q1∗k2
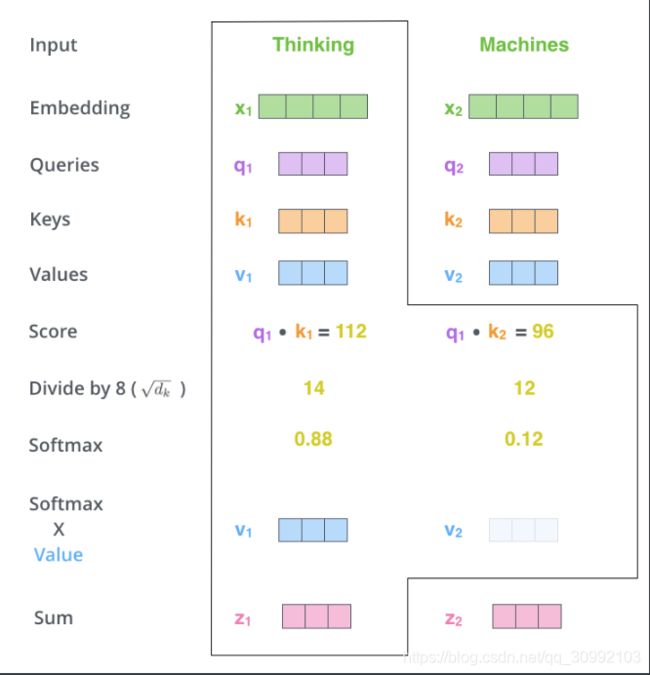
如下图所示,再对Score值做scale操作,通过除以√dk将score值缩小,这样能使得score值更平滑,在做梯度下降时更稳定,有利于模型的训练。再对得到的新的Score值做Softmax,利用Softmax操作得到的概率分布对所有的操作得到的概率分布对所有的v_{i}进行加权平均,得到当前词语的最终表示
进行加权平均,得到当前词语的最终表示z_{1}。对machines的编码和上述过程一样。
z1=Softmax(Score1,Socre2)∗[v1v2]T
z1=Softmax(Score1,Socre2)∗[v1v2]T
如果我们以向量形式循环输入所有词语的Embedding向量得到它们的最终编码,这种方式依然是串行的,而如果我们把上面的向量计算变为矩阵的运算,则可以实现一次计算出所有词语对应的最终编码,这样的矩阵运算可以充分的利用电脑的硬件和软件资源,从而使程序更高效的执行。
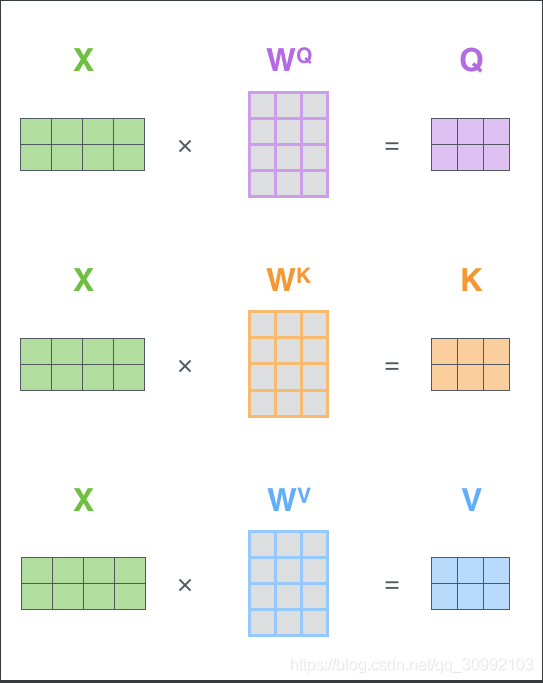
下图所示为矩阵运算的形式。其中X为输入对应的词向量矩阵,WQ、WK、WV为相应的线性变换矩阵,Q、K、V为X经过线性变换得到的Query向量矩阵、Key向量矩阵和Value向量矩阵
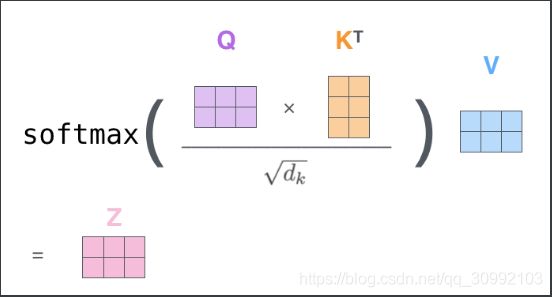
接下来再利用Q、K、V
Q、K、V计算ScoreScore矩阵,通过将ScoreScore矩阵除以dk−−√dk进行ScaleScale操作,再对结果按行进行Softmax
Softmax,利用得到的概率分布得到最后的编码矩阵,具体过程的可视化如下图所示。
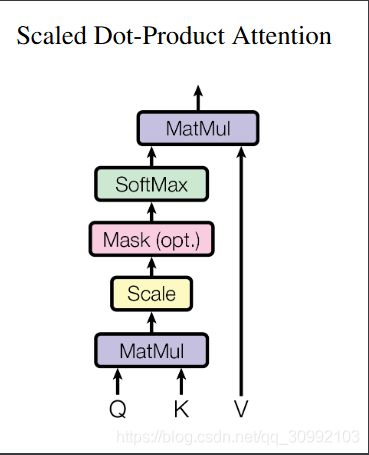
2.3 Scaled Dot-Production Attetntion
__Scaled Dot-Product Attention__其实是在上一节的attention的基础上加入了__scale__和__mask__操作进行优化,具体结构如下图所示。首先对于__scale__操作,缩放因子的加入是考虑到Q∗K
Q∗K的结果矩阵中的值可能会很大,除以一个缩放因子可以使值变小,这样模型在做梯度下降时可以更加稳定。__mask__操作主要是为了屏蔽掉输入中没有意义的部分(padding mask)和针对特定任务需要屏蔽的部分(sequence mask),从而降低其对最后结果的影响。这两种不同的mask方法在后面会详细说明。
2.4 Multi-Head Attention
Scaled dot-product attention只通过一组线性变换矩阵WQ、WK、WV
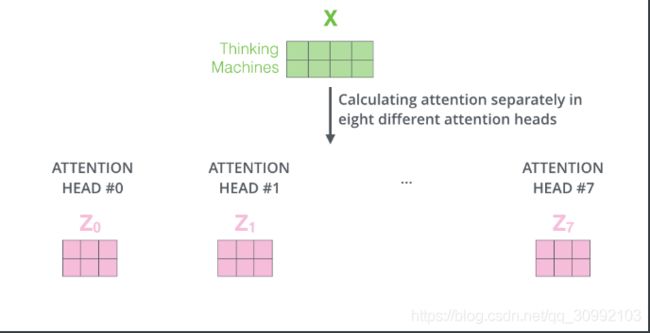
WQ、WK、WV得到一组Q、K、V,来实现对词语上下文信息的关注。而Multi-Head Attention提出,我们可以通过定义多组线性变换矩阵(WQi,WKi,WVi),得到多组(Qi,Ki,Vi),它们分别关注输入的不同部分的上下文信息,这样使得最后的编码中关注的信息能够更多。换句话说,multi-head attention就是针对输入的不同部分分别做scaled dot-product attention,再将得到的多个输出拼接成最终的输出矩阵。值得注意的一点是,在Multi-head Attention中,每个head的输入都只是模型的输入词向量矩阵的一部分。在Transformer中,每个head的输入都是从词向量矩阵的最后一维进行切分出来的一部分,例如模型输入的词向量矩阵大小为N∗dmodelN∗dmodel,Transformer中Multi-head Attention中head的数量设置为8,则每个head的输入矩阵大小为N∗(dmodel/8)

上图给出了在不同head中的attention操作,由图中可知,每个head中都存在一组WQi,WKi,WVi
WiQ,WiK,WiV,通过与输入进行矩阵相乘运算,可以得到一组对应的(Qi,Ki,Vi),并由此得到head的输出zi。在单个head中进行的attention操作,与上一节所讲的完全相同。最后多个head得到的结果如下图所示。
而最后我们所需要的输出不是多个矩阵,而是单个矩阵,所以最后多个head的输出都在矩阵的最后一个维度上进行拼接,再将得到的矩阵与一个矩阵WO
WO相乘,这一次线性变换的目的是对拼接得到的矩阵进行压缩,以得到最理想的输出矩阵。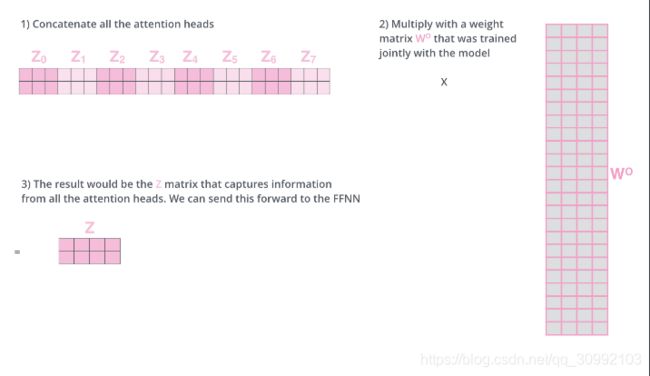
下图所示,为完整的Multi-head Attention过程,

那么我们如何来理解多个head分别注意到的内容呢?下面给出两个图来举例说明。第一个图给出了在翻译it时两个head分别注意到的内容,从中可以很明显的看到,第一个head注意到了animal,而第二个head注意到了tired,这就保证了翻译的正确性。
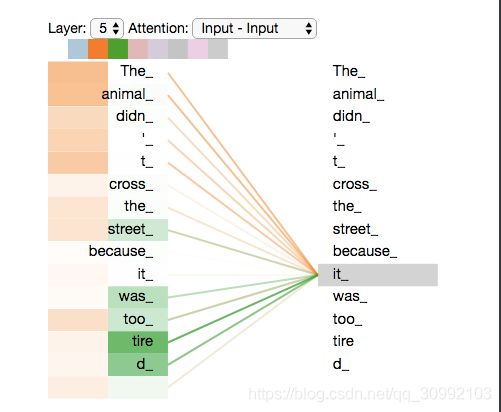
第二个图中给出了所以head分别注意到的内容,这时候attention究竟能否抓取到最需要被获取的信息变得不再那么直观。

3. The Residual Connection 残差连接
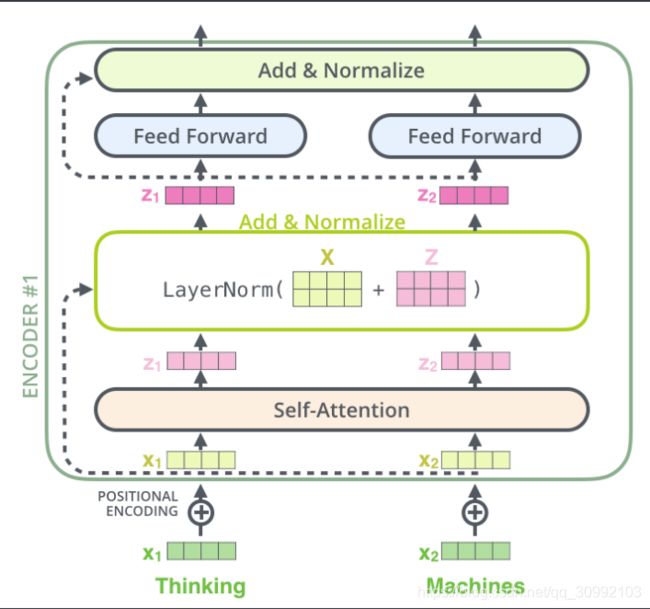
在Transformer中,每个Multi-Head Attention层和Feed Forward层都会有一个残差连接,然后再接一个Layer Norm层。残差连接在Encoder和Decoder中都存在,且结构完全相同。如下图所示,一个Encoder中Self-Attention层的输出z1,z2和输入(x1,x2)相加,作为LayerNorm层的输入。残差连接本身有很多好处,但并不是Transformer结构的重点,这里不做详述。
4. Positional Encoding
我们在Transformer中使用Self-Attention的目的是用它来代替RNN。RNN只能关注到过去的信息,而Self-Attention通过矩阵运算可以同时关注到当前时刻的上下文中所有的信息,这使得其可以实现和RNN等价甚至更好的效果。同时,RNN作为一种串行的序列模型还有一个很重要的特征,就是它能够考虑到单词的顺序(位置)关系。在同一个句子中,即使所有的词都相同但词序的变化也可能导致句子的语义完全不同,比如”北京到上海的机票”与”上海到北京的机票”,它们的语义就有很大的差别。而Self-Attention结构是不考虑词的顺序的,如果不引入位置信息,前一个例子两句话中中的"北京"会被编码成相同的向量,但实际上我们希望两者的编码向量是不同的,前一句中的"北京"需要编码出发城市的语义,而后一句中的"北京"则为目的城市。换言之,如果没有位置信息,Self-Attention只是一个结构更复杂的词袋模型。所以,在词向量编码中引入位置信息是必要的。
为了解决这个问题,我们需要引入位置编码,也就是t时刻的输入,除了Embedding之外(这是与位置无关的),我们还引入一个向量,这个向量是与t有关的,我们把Embedding和位置编码向量加起来作为模型的输入。这样的话如果两个词在不同的位置出现了,虽然它们的Embedding是相同的,但是由于位置编码不同,最终得到的向量也是不同的。
位置编码有很多方法,其中需要考虑的一个重要因素就是需要它编码的是相对位置的关系。比如两个句子:”北京到上海的机票”和”你好,我们要一张北京到上海的机票”。显然加入位置编码之后,两个北京的向量是不同的了,两个上海的向量也是不同的了,但是我们期望Query(北京1)∗Key(上海1)却是等于Query(北京2)∗Key(上海2)的。
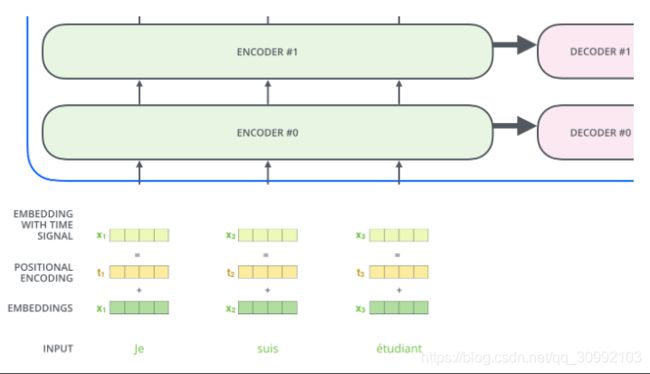
由上图可知,位置编码其实是以加法的形式将词语的Embedding向量加上其位置向量作为最后的输出,这保证了当同一个词出现在句子的不同位置时,其对应的词向量表示是不同的。在Transformer中的positional 具体实现上,首先要明确的是,在Transformer中的的positional encoding矩阵是固定的,当每个输入样本的大小为maxlen∗dmodel时,则我们需要的positional enccoding矩阵的大小同样为maxlen∗dmodel,且这个位置编码矩阵被应用于和所有输入样本做加法,以此将位置信息编码进样本的词向量表示。接下来说一下如何得到这个positional encoding矩阵。
当我们需要的positional encoding矩阵PE的大小为maxlen∗dmodel时,首先根据矩阵中每个位置的下标(i,j)
(i,j)按下面的公式确定该位置的值:
PE(i,j)=i10000(j−j%2)/dmodel
PE(i,j)=10000(j−j%2)/dmodeli
接着,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码:
PE(i,2j)=sin(PE(i,2j))
PE(i,2j+1)=cos(PE(i,2j+1))
为什么这样编码就能引入词语的位置信息呢?如果只按照第一个公式那样根据输入矩阵的下标值进行编码的话,显然编码的是词汇的绝对位置信息,即__绝对位置编码__。但词语的相对位置也是非常重要的,这也是Transformer中引入正弦函数的原因进行__相对位置编码__的原因。正弦函数能够表示词语的相对位置信息,主要是基于以下两个公式,这表明位置k+p
k+p的位置向量可以表示为位置k
k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
sin(α+β)=sinαcosβ+cosαsinβ
cos(α+β)=cosαcosβ−sinαsinβ
5. Layer Norm
假设我们的输入是一个向量,这个向量中的每个元素都代表了输入的一个不同特征,而LayerNorm要做的就是对一个样本向量的所有特征进行Normalization,这也表明LayNorm的输入可以只有一个样本。
假设一个样本向量为X=x1,x2,…,xn
X=x1,x2,…,xn,则对其做Layer Normalization的过程如下所示。先求不同特征的均值和方差,再利用均值和方差对样本的各个特征值进行Normalization操作。
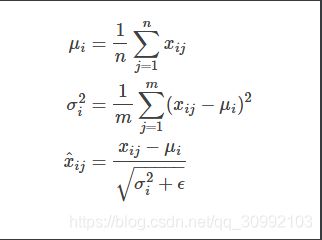
下图给出一个对不同样本做Layer Normalization的实例。
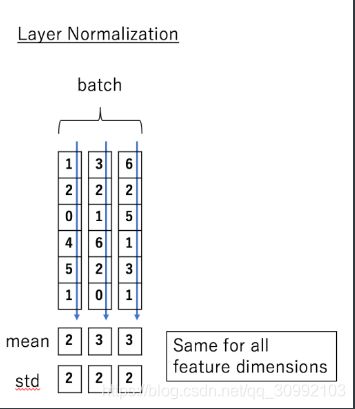
Layer Normalization的方法可以和Batch Normalization对比着进行理解,因为Batch Normalization不是Transformer中的结构,这里不做详解。
6. Mask
Mask,顾名思义就是掩码,可以理解为对输入的向量或者矩阵中的一些特征值进行掩盖,使其不发挥作用,这些被掩盖的特征值可能是本身并没有意义(比如为了对齐而填充的’0’)或者是针对当前任务为了做特殊处理而特意进行掩盖。
在Transformer中有两种mask方法,分别为__padding mask__和__sequence mask__,这两种mask方法在Transformer中的作用并不一样。__padding mask__在Encoder和Decoder中都会用到,而__sequence mask__只在Decoder中使用。
6.1 padding mask
在自然语言处理的相关任务中,输入样本一般为句子,而不同的句子中包含的词汇数目变化很大,但机器学习模型一般要求输入的大小是一致的,一般解决这个问题的方法是对输入的单词序列根据最大长度进行__对齐__,即在长度小于最大长度的输入后面填’0’。举个例子,当maxlen=20
maxlen=20,而我们输入的矩阵大小为12∗dmodel12∗dmodel时,这是我们对输入进行对齐,就需要在输入的后面拼接一个大小为8∗dmodel8∗dmodel的零矩阵,使输入的大小变为maxlen∗dmodel
maxlen∗dmodel。但显然,这些填充的’0’并没有意义,它的作用只是实现输入的对齐。在做attention时,为了使attention向量不将注意力放在这些没有意义的值上,我们需要对这些值做__padding mask__。
具体来说,做__padding mask__的方法是,将这些没有意义的位置上的值置为一个很小的数,这样在做softmax
softmax时,这些位置上对应的概率值会非常小接近于0,其对最终结果的影响也会降低到最小。
6.2 sequence mask
前面已经说过,在Transformer中,__sequence mask__只用在Decoder中,它的作用是使得Decoder在进行解码时不能看到当前时刻之后的的信息。也就是说,对于一个输入序列,当我们要对t
t时刻进行解码时,我们只能考虑(1,2,…,t−1)时刻的信息,而不能考虑之后的(t+1,…,n)时刻的信息。
具体做法,是产生一个下三角矩阵,这个矩阵的上三角的值全为0,下三角的值全为输入矩阵对应位置的值,这样就实现了在每个时刻对未来信息的掩盖。
7. Encoder and Decoder stacks
上面几节中已经介绍了Transformer的主要结构,这一节将在此基础上,从整体上再次理解一下Tranformer的结构
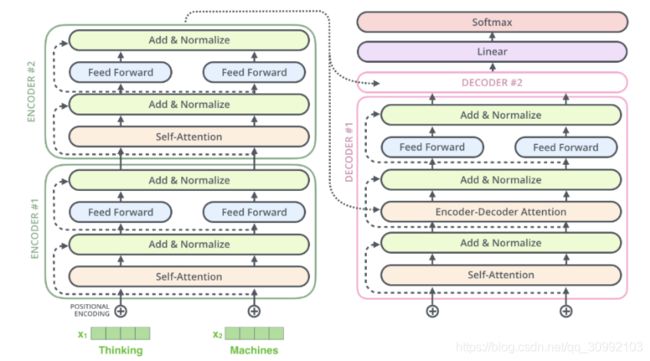
如上图所示,Transformer由6个Encoder层和6个Decoder层组成,其中各个Encoder层的结构完全相同,各个Decoder层的结构也是完全一样的。而Decoder层和Encoder层之间的差别在于Decoder层中多了一个Encoder-Decoder Attention子层和Add & Normalize子层,这一层的输入为Decoder层的上一个子层的输出和Encoder层的最终输出,其中Encoder层的最终输出作为K和V,Decoder层中上一个子层的输出作为Q。