KDD2022 | MUVCOG:多模态搜索会话下的用户意图刻画
丨目录:
· 摘要
· 背景
· 方法
· 实验
· 总结
· 关于我们
· 总结
摘要
在搜索会话中对上下文信息进行建模是一项重要工作。然而,用户在使用手机淘宝的过程中,会交替通过搜索框使用文本关键词进行查询、通过拍照搜索使用实拍图进行查询、通过相似搜索使用商品图片和标题进行查询。在以往的电商搜索工作中,只对搜索会话中的文本查询进行建模,无法捕捉到多个不同模态查询之间的关联性。针对以上问题,本文提出了一种用异质图神经网络来学习用户多模态多Query搜索会话(Multi-modal Multi-query Search Session,简称MM搜索会话)的方法。在该方法中,我们提出了一种多视图对比学习框架用于异质图神经网络的预训练,引入两种视图来建模MM搜索会话中不同查询内、查询间和模态间的信息传播。大量实验表明,预训练的会话表征可以使多种下游任务相比基线获得明显提升,例如:个性化点击率预估、Query推荐和Query意图分类。
该项工作由阿里妈妈搜索广告算法团队和厦门大学林琛教授课题组合作完成,基于该项工作整理的论文已被KDD 2022接收,欢迎阅读交流。
论文:Pretraining Representations of Multi-modal Multi-query E-commerce Search
链接:https://github.com/XMUDM/MMsession/blob/main/KDD2022.pdf
背景
为了提供更好的搜索体验,当下手机淘宝支持用户以多种形式来进行组合搜索。除了常用的文本搜索、拍照搜索之外,还可以在文本搜索结果中长按商品进行相似商品搜索。其中,文本搜索以输入的关键词作为Query,拍照搜索以实拍图作为Query,相似商品搜索以商品信息作为Query(包括商品标题、商品图片等)。在用户的浏览购物过程中,会交替使用这些不同模态的搜索形式。因此,上述搜索行为就构成了一个多模态多Query的搜索会话(MM搜索会话),如图1所示:
 图1
图1
由于相似商品搜索是在文本搜索结果上触发,因此这两种搜索形式的关系更为紧密,本文也主要研究这两种搜索形式构成的MM搜索问题。与传统的文本搜索相比,MM搜索更容易提升用户的参与度。我们以同一个用户前后2次搜索间隔不超过30分钟作为窗口来构建搜索会话。如图2(a)所示,统计发现超过55%的文本搜索会话只包含1个Query,而MM搜索会话的Query个数明显更长,甚至有9%的搜索会话包含10个以上Query。另一方面,如图2(b)所示,分类目统计,MM搜索会话下平均每个Query的点击次数明显小于文本搜索会话。意味着MM搜索下用户的行为和购物意图更复杂,其需求更难以被满足。

图2
过往已经有较多的工作进行搜索会话表示学习的研究,主要有两个特点:1是任务导向的,比如结合特定任务对搜索会话进行显式编码,这种编码的表征通用性比较弱。2是关注文本搜索下多Query建模,或者研究单个多模态Query的建模,对多模态多Query的搜索会话研究的比较少。因此,我们想探究的是针对多模态多Query的搜索会话,能否通过预训练的方式学到更通用的表征,来增强多种下游任务的效果?
但针对MM搜索会话学习更加有效的预训练表征并非易事,主要存在以下两个挑战:
挑战一:如何建模MM搜索会话中不同模态之间的关系
MM搜索会话包含多种不同模态的Query,比如文本搜索关键词Query属于文本模态、相似商品搜索商品Query包含商品标题和图片属于图文模态。同一Query内部、不同模态Query之间都存在模态上和时序上的复杂关系。举例,如图1所示关键词Query主要描述了海螺这种商品,没有具体描述海螺的属性信息。而当用户对其中某一个海螺商品发起相似搜索时,商品Query尤其是图片就包含了丰富的外观信息。因此,前后Query就形成了很好的意图互补。然而这种复杂的模态关系不好捕捉,现有的大多数工作是从时序模型的角度来建模会话的,比如RNN、LSTM等。这些方法无法从模态的角度来捕捉相关性,因此这块的研究还是相对较少。
挑战二:如何让自监督预训练任务更加有效
受对比学习最新工作的启发,我们采用对比学习来学习MM搜索会话的表示。对比学习的有效性依赖于正负样本的信息量和置信度,目前大多数的对比学习任务都是针对视觉和NLP任务设计的,其正负样本的定义不一定适合搜索任务。另外,对MM搜索会话来说,可以从不同的视角来理解,例如,图1的搜索会话可以从用户如何调整优化Query的角度来理解,也可以从整个会话中不同模态Query如何互补的角度来理解,只考虑一种视角无法完整刻画MM搜索会话中的信息。
方法
我们的解决方法是构建一个多视图的图神经网络对比学习框架(MUVCOG),如下图3所示。我们将一个MM搜索会话建模成一个异质图,其中不同模态的Query会用不同类型的节点表示。对于图像模态的输入,每一张图像会用一个节点表示,对于文本模态的输入,将切分后的每一个词用一个节点表示,需要注意的是,这里会把文本搜索的词和相似商品搜索的词当做不同类型的节点,原因是前者是用户主动输入的,后者是用户被动输入的,我们认为其中包含的用户意图是有差异的。在图构建完成后,我们用图神经网络(Graph Neural Network,简称GNN)来对图进行编码。与其他异质图神经网络不同,我们使用了两种不同的视图来表达MM搜索会话。
第一种视图是基于注意力机制的全局视图(Attention Global View,简称AGV),该视图先将不同模态的Query分别做Attention聚合,得到每一种模态的表示,再对不同模态之间进行聚合,得到整个图的表示。由于同一种模态输入可能包含在搜索会话的多个Query中,因此这种视图的感知范围是全局的。
第二种视图是层次化的局部视图(Hierarchical Local View ,简称HLV),该视图先将每一个Query下的节点进行聚合,得到每一个Query的表示,再对不同的Query之间进行聚合,得到整个图的表示。由于第一层先得到局部的Query表示,第二层得到全局的图表示,因此这种视图是局部并且层次化的。
这两种视图分别从不同的视角来理解MM搜索会话,可以完整的刻画不同模态Query内部和Query之间的关系,因此相比RNN、LSTM等序列方法能更好的解决挑战一的跨模态特征融合问题。
针对挑战二,为了提升预训练对比学习任务的效果,我们针对MM搜索任务设计了正样本和难负样本的采样策略,来提升学习任务的难度。结合多视图表征提取方法,正负样本的表征会以不同的视图来做对比学习,从而提升表征的有效性和鲁棒性。最终预训练得到的MM搜索会话表征应用到多种下游任务中,包括个性化点击率预估、Query推荐和Query意图分类任务等。
 图3
图3
下面对图的结构、两种视图、正负样本的采样和学习过程进行描述。完整的MM搜索会话用一个有向图表示,其中表示节点集合,每个节点最终用一个D维的向量表示,表示边的集合,表示节点类型,表示节点到节点类型的映射,表示边的类型,表示边到边类型的映射。
基于注意力机制的全局视图(AGV):
在AGV视图中,一共有三种不同的节点类型,分别表示文本搜索的关键词Query、相似商品搜索中的标题Query和图片Query,一共有两种不同类型的边,分别表示共现关系和改进关系,共现关系指的是两个节点属于同一个Query,改进关系表示两个节点分别属于两个相邻的Query。我们用预训练好的词向量和图像向量来初始化图节点,由于视觉模态和文本模态属于不同的表征空间,因此在初始化时,我们会先将不同模态的表征映射到相同空间中。然后对不同模态分别做Attention聚合,得到每一种模态下的表示,具体的,节点在模态下的隐向量计算公式为:
其中,表示Query类型,表示节点的邻居节点,表示非线性激活函数,权重的计算方式为:
其中,[ ]表示向量拼接,得到节点在模态p下的表示后,我们继续对不同模态之间进行聚合,得到AGV视图下每个节点的最终表示:
其中,表示每个模态的权重,表示节点在AGV视图下的最终表示。最后,通过对所有节点的表示取平均来得到整个搜索会话(图)的表示:
402 Payment Required
层次化的局部视图(HLV):
与AGV视图不同,层次化的局部视图HLV先学习每一个Query的表示,再学习不同Query间的关系。如图3所示,HLV视图共包含四种不同类型的节点,其中表示整个Query节点,HLV视图也包含两种边,我们为每个Query和它包含的词和图片添加一条CO边,为Query和它的下一个Query添加一条RF边。节点的初始化方式与AGV视图相同,其中VQ节点用零向量初始化。首先通过对Query做GCN卷积来得到Query的隐向量:
其中表示同一个Query内部所有词和图片节点,是Query的度,是节点的度,是可学习的权重矩阵。然后,通过第二层GCN来聚合得到最终HLV视图下每个节点的最终表示:
其中表示整个Query序列,是可学习的权重矩阵。最后,通过对所有节点的表示取平均来得到整个搜索会话(图)的表示:
402 Payment Required
正负样本挖掘和对比学习:
在获得MM搜索会话两种视图下的表示后,我们采用对比学习来预训练。对于每个会话,我们希望相似会话(正样本)在特征空间中与它更接近,不相似会话(负样本)在特征空间中与它更远离。正负样本的难度对于提升表征的有效性具有重要作用,我们正样本的构造方法为随机mask掉搜索会话中的某一个Query,包括这个Query下的所有词和图片。为了增加负样本的难度,我们首先计算每一对会话下公共的商品点击数,寻找与当前会话的公共点击数为0,但是相似度最大的会话作为s的难负样本。
为了让表征更具鲁棒性,我们将两种视图进行混合对比,对于AGV视图下的会话,采用HLV视图来编码它的正负样本,反之亦然。我们采用了多层感知机来预测一对会话的正负标签,训练过程中的损失函数为二元交叉熵损失:

其中是二元交叉熵损失。
实验
数据集:
我们收集了2021年11月中连续7天内在手机淘宝中关于服装、美妆和电子产品的搜索日志。使用30分钟作为阈值将这些搜索行为划分为不同会话,当同一个用户连续两次搜索行为的间隔时间小于30分钟时,这两次搜索就被划分到同一个会话中。然后,我们删除只有文本会话和只包含单个查询的会话。最后,为了方便点击率预估任务,我们收集了每个搜索会话的点击事件,以及相应的用户ID和商品ID,具体数据如表1所示:
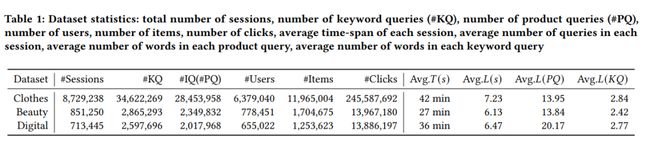 表1
表1
点击率预估任务:
我们使用不同的方法来对MM搜索会话进行表示,然后将得到的会话向量和其他由模型特征拼接到一起,送入点击率预估模型预测点击行为。实验结果如表2所示:
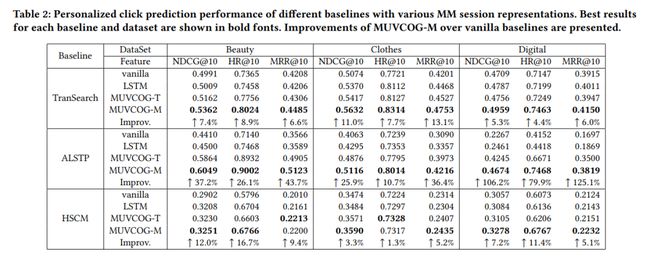 表2
表2
表2包括了多个不同版本MM搜索会话表示在多个不同基线模型中的结果。其中,MUVCOG-T表示只用文本模态的预训练会话表示,MUVCOG-M表示融合图文的多模态会话表示。我们的目的在于比较不同MM搜索会话表示效果的差异,结果如下:
(1)在所有数据集上,MUVCOG-M在NDCG@10、HR@10和MRR@10指标上都有明显提升,即使对比LSTM这种复杂的时序模型,也有明显的提升。因此,这验证了我们的假设,即将MM搜索会话表示引入点击率预估模型,有助于更好的刻画用户意图,提升点击预测的性能。
(2)在ALSTP和HSCM的基线模型中,已经包含了搜索会话的信息,而我们继续加入预训练的MM搜索会话表示仍然能继续获得提升。本质原因是这些方法只考虑了文本Query,而忽略了图像Query,图像Query对于文本Query是一个重要的补充,其背后是某些信息需求很难用语言表达。
(3)预训练的MUVCOG(没有针对特定任务微调)优于对MM搜索会话进行端到端学习的LSTM。这表明不同模态查询之间的复杂关系无法通过时序模型来捕捉,而异质图神经网络是更优的选择。
(4)在大多数情况下,MUVCOG-M比MUVCOG-T效果更好,这验证了MM搜索会话中编码视觉特征的重要性。
Query推荐任务:
Query推荐是给定MM搜索会话中前面N-1个Query,预测会话中的第N个Query,即用户最感兴趣的Query。实验中,我们只预测文本Query,结构如表3所示:
 表3
表3
如表3所示,在无论是否有图片模态Query的情况下,MUVCOG在所有评估指标上都由于LSTM和Transformer模型。这说明我们提出的异质图学习方法相比现有的时序方法,可以更有效的学习会话中Query之间的关系和变化趋势。同时,我们也发现,在Query推荐任务中加入图像模态后效果更好,再次印证了MM搜索会话中图像Query的重要性。
Query意图分类任务:
Query意图分类是预测MM搜索会话属于哪一个类别,我们用每个搜索会话下点击最多的商品类别表示会话的类别。实验结构如表4所示:
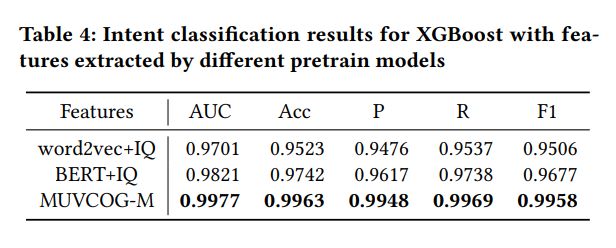 表4
表4
如表4所示,MUVCOG-M在所有指标上都超过了word2vec和BERT方法,表明预训练模型MUVCOG可以提取通用且有效的表征来编码用户搜索意图。
总结
本文研究了手机淘宝中多模态多Query搜索会话的建模问题。我们提出了一个多视图的图神经网络对比学习框架(MUVCOG)来预训练异质图神经网络,并学习MM搜索会话的特征表示。实验结果表明,这种通用的不针对特定任务微调的预训练会话表示对于多种电子商务下游任务,比如点击率预估、Query推荐和Query意图分类都有显著帮助。
关于我们
阿里妈妈搜索广告多模态团队主要负责多模态搜索业务场景(e.g. 淘宝拍照、相似搜索等)的商业化变现。我们持续在多模态预训练、多模态Query理解、多模态多任务知识融合等方向上探索和落地应用。欢迎对多模态算法以及计算广告感兴趣的同学和我们取得联系、互相交流。
联系邮箱:[email protected]
Reference
Multi-Modal Preference Modeling for Product Search,ACM MM 2018
Attentive Long Short-Term Preference Modeling for Personalized Product Search,TOIS Trans 2019
A Hybrid Framework for Session Context Modeling,TOIS Trans 2021
Web Search of Fashion Items with Multimodal Querying,WSDM 2018
Self-Supervised Heterogeneous Graph Neural Network with Co-Contrastive Learning,KDD 2021
END

也许你还想看
丨从二值检索到层次竞买图——让搜索广告关键词召回焕然新生
丨CIKM 2021 | 基于异质图学习的搜索广告关键词推荐
关注「阿里妈妈技术」,了解更多~


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓