机器学习(周志华) 第十四章概率图模型
关于周志华老师的《机器学习》这本书的学习笔记
记录学习过程
本博客记录Chapter14
文章目录
- 1 隐马尔可夫模型
- 2 马尔可夫随机场
- 3 条件随机场
- 4 学习与推断
- 5 近似推断
- 6 话题模型
1 隐马尔可夫模型
概率图模型(probabilistic graphical model):用图来表达变量相关关系的概率模型。最常见的是用一个结点表示一个或一组随机变量,节点之间的边表示变量间的概率相关关系,即变量关系图。概率图模型大概可以分类为:
- 有向无环图(有向图模型或贝叶斯网)
- 无向图(无向图模型或马尔可夫网)
隐马尔可夫模型(HMM):是结构最简单的动态贝叶斯网,是一种著名的有向图模型。主要应用于时间序列数据建模。隐马尔可夫模型中有两类变量:
- 状态变量(隐变量):表示第 i i i时刻的系统状态 { y 1 , y 2 , ⋯ , y n } \{y_1,y_2,\cdots,y_n\} {y1,y2,⋯,yn},一般是隐藏的、不可被观测的。
- 观测变量: { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,\cdots, x_n\} {x1,x2,⋯,xn},表示第 i i i时刻的观测值。
在隐马尔可夫模型中,系统通常在多个状态 { s 1 , s 2 , ⋯ , s N } \{s_1,s_2,\cdots,s_N\} {s1,s2,⋯,sN}之间转换,因此状态变量 y i y_i yi的取值范围通常是有 N N N个可能取值的离散空间,因此状态变量 y i y_i yi的取值范围 Y Y Y通常是有 N N N个可能取值的离散空间( Y ⊂ S Y \subset S Y⊂S)。观测变量可以是离散型也可以是连续型。为便于讨论,我们假定其取值范围 X = { o 1 , o 2 , ⋯ , o M } X=\{o_1,o_2,\cdots,o_M\} X={o1,o2,⋯,oM}。

在任一时刻,观测变量的取值 x t x_t xt仅由状态变量 y t y_t yt确定,与其他状态变量以及观测变量的取值无关。同时 t t t时刻的状态 y t y_t yt仅依赖于 t − 1 t-1 t−1时刻的状态 y t − 1 y_{t-1} yt−1,与其余 n − 2 n-2 n−2个状态无关,这就是所谓的 “马尔可夫链”:系统下一时刻的状态仅有当前状态决定,不依赖于以往的任何状态。 所有变量的联合概率分布定义为:
P ( x 1 , y 1 , ⋯ , x n , y n ) = P ( y 1 ) P ( x 1 ∣ y 1 ) ∏ i = 2 n P ( y i ∣ y i − 1 ) P ( x i ∣ y i ) P(x_1,y_1,\cdots,x_n,y_n)=P(y_1)P(x_1|y_1)\prod_{i=2}^nP(y_i|y_{i-1})P(x_i|y_i) P(x1,y1,⋯,xn,yn)=P(y1)P(x1∣y1)i=2∏nP(yi∣yi−1)P(xi∣yi)
除了结构信息,欲确定一个隐马尔可夫模型还需要以下三组参数:
-
状态转移概率:
a i j = P ( y t + 1 = s j ∣ y t = s i ) , 1 ≤ i , j ≤ N a_{ij}=P(y_{t+1}=s_j|y_t=s_i),\ \ \ \ \ 1\le i,j\le N aij=P(yt+1=sj∣yt=si), 1≤i,j≤N -
输出观测概率:
b i j = P ( x t = o j ∣ y t = s i ) b_{ij}=P(x_t=o_j|y_t=s_i) bij=P(xt=oj∣yt=si) -
初始状态概率:
π i = P ( y 1 = s i ) \pi_i=P(y_1=s_i) πi=P(y1=si)
2 马尔可夫随机场
马尔可夫随机场(MRF):典型的马尔可夫网,是一种著名的无向图模型:
- 结点:一个或一组变量
- 边:变量之间的依赖关系
马尔可夫随机场有一组势函数(potential functions),也叫做“因子”,即定义在变量子集上的非负实函数,主要用于定义概率分布函数。
马尔可夫随机场中,对于图中结点的一个子集,如果其中任意两个结点都有边连接,则称该结点子集为一个“团”,若团中再加入一个结点,则无法构成团,则称为“极大团”。

在马尔可夫随机场中,多个变量之间的联合概率分布能基于团分解为多个因子的乘积,每个因子仅与一个团相关。具体来说,对于 n n n个变量 X = { x 1 , x 2 , ⋯ , x n } X=\{x_1,x_2,\cdots, x_n\} X={x1,x2,⋯,xn} , 所有团构成的集合为 C C C,与团 Q ∈ C Q\in C Q∈C对应的变量集合记为 X Q X_Q XQ ,则联合概率 P ( X ) P(X) P(X)定义为
P ( X ) = 1 Z ∏ Q ∈ C ψ ( X Q ) P(X)=\frac{1}{Z}\prod_{Q\in C} \psi(X_Q) P(X)=Z1Q∈C∏ψ(XQ)
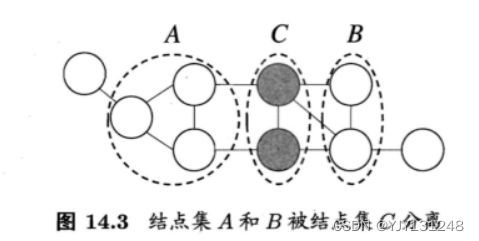
在马尔可夫随机场中如何得到“条件独立性”呢?同样借助分离的概念。如下图所示,若从结点集A中的结点到B中的结点都必须经过结点集C中的结点,则称结点集A和B被结点集C分离, C称为"分离集" (separating set)。
对马尔可夫随机场,有 “全局马尔可夫性” (global Markov property):给定两个变量子集的分离集,则这两个变量子集条件独立。也就是说,图中若令 A, B和C对应的变量集分别为 X A , X B , X C X_A,X_B, X_C XA,XB,XC, 则 X A X_A XA 和 X B X_B XB 在给定 X C X_C XC的条件下独立,记为 X A ⊥ X B ∣ X C XA\perp XB|X_C XA⊥XB∣XC。
由全局马尔可夫性,可以得到两个有用的推论:
- 局部马尔科夫性: 给定某变量的邻接变量,则该变量条件独立于其他变量。
- 成对马尔可夫性: 给定所有其他变量,两个非邻接变量条件独立。
下面来考察马尔可夫随机场中的势函数,其作用是定量刻画变量集 X Q X_Q XQ中变量的相关关系 (非负函数),且在所偏好的变量取值上有较大的函数值。
为了满足非负性,指数函数常被定义势函数:
ψ Q ( X Q ) = e − H Q ( X Q ) \psi_Q(X_Q)=e^{-H_Q(X_Q)} ψQ(XQ)=e−HQ(XQ)
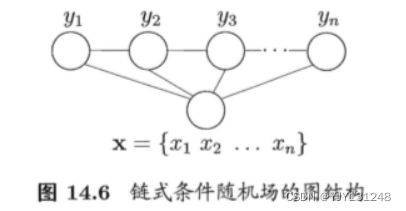
3 条件随机场
条件随机场(Conditional Random Field,简称 CRF) 是一种判别式无向图模型,是判别式模型。条件随机场试图对多个变量在给定观测值后的条件概率进行建模。
令 G = ( V , E ) G=(V,E) G=(V,E)表示结点与标记变量 y y y中元素一一对应的无向图, y v y_v yv表示与结点 v v v对应的标记变量, n ( v ) n(v) n(v)表示结点 v v v的邻接结点, 若图 G G G的每个变量 y v y_v yv都满足马尔可夫性,即
P ( y v ∣ x , y V \ { v } ) = P ( y v ∣ x , y n ( v ) ) P(y_v|x,y_{V\backslash \{v\}})=P(y_v|x,y_{n(v)}) P(yv∣x,yV\{v})=P(yv∣x,yn(v))
则 ( y , x ) (y,x) (y,x)构成一个条件随机场。
4 学习与推断
- 变量消去

- 信念传播

5 近似推断
- MCMC采样:关键在于通过构造"平稳分布为 p p p的马尔同夫链" 来产生样本。
- 变分推断:通过使用己知简单分布来逼近需推断的复杂分布,并通过限制近似分布的类型,从而得到一种局部最优、但具有确定解的近似后验分布。
6 话题模型
话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用。隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA) 是话题模型的典型代表。
话题模型中的基本概念:
- 词(word):最基本离散单元
- 文档(document):不计顺序(词袋)
- 话题(topic):一系列相关的词,以及它们在该概率下出现的概率
不妨假定数据集中一共包含 K K K个话题和 T T T篇文档,文档中的词来自一个包含 N N N个词的词典。我们用 T T T个 N N N维向量 w = { w 1 , w 2 , ⋯ , w T } w=\{w_1,w_2,\cdots,w_T\} w={w1,w2,⋯,wT}表示数据集(即文档集合), K K K个 N N N维向量 β k ( k = 1 , 2 , ⋯ , K ) \beta_k\ \ (k=1 ,2,\cdots, K) βk (k=1,2,⋯,K)表示话题,其中 w T ∈ R N w_T\in \mathbb R^N wT∈RN的第 n n n个分量 w t , n w_{t,n} wt,n表示文档 t t t中词 n n n的词频, β k ∈ R N \beta_k\in \mathbb R^N βk∈RN的第 n n n个分量 β k , n \beta_{k,n} βk,n表示话题 k k k中词 n n n的词频。
LDA从生成式模型的角度来看待文档和话题。具体来说,LDA认为每篇文档包含多个话题,不妨用向量 θ t ∈ R N \theta_t\in \mathbb R^N θt∈RN表示文档 t t t中所包含的每个话题的比例, θ t , k \theta_{t,k} θt,k表示文档 t t t中包含话题 k k k的比例,进而通过下面的步骤由话题"生成"文档 t t t:
- 根据参数 α \alpha α的迪利克雷分布随机采样一个话题分布 θ t \theta_t θt
- 按如下步骤生成文档中的 N N N个词
- 根据 θ t \theta_t θt进行话题指派,得到文档 t t t中词 n n n的话题 z t , n z_{t,n} zt,n
- 根据指派的话题所对应的词频分布 β k \beta_k βk随机采样生成词
