从0基础到全国亚军,自学机器学习如何挺进Kaggle前20%
前半部分是各种碎碎念,介绍自己0基础入门机器学习的经历,不喜欢可以跳过
后半部分介绍自己的比赛方案
双非文科出身,0基础完全靠自学入门【机器学习】,在一场练习赛中Sole,成绩从第1661名达到了全球第362名(总共1728支队伍,前20.9%)。
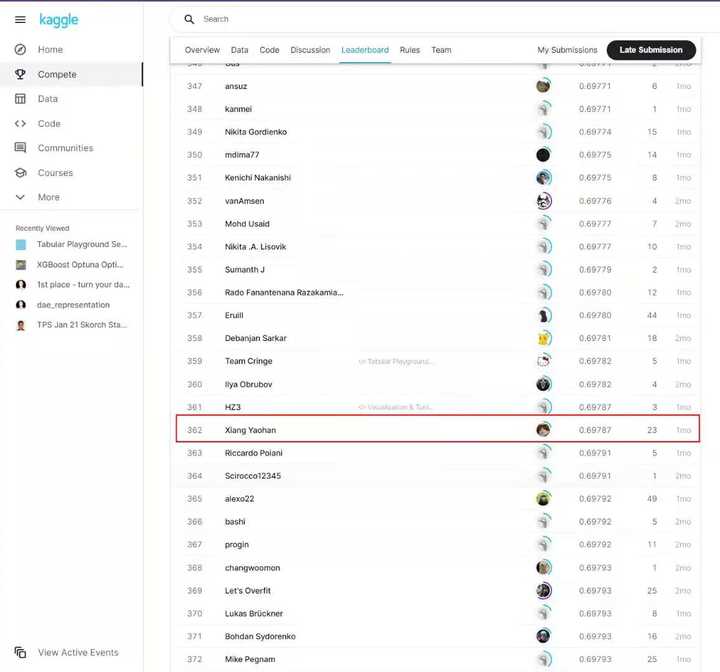
成绩是真实的,排行榜是我用HTML代码改的,因为提交不上去
最开始的参赛的时候成绩是1661名,提交了23次,成绩才一点点上去了,如果我继续调参的话,成绩应该还有优化的空间。

备注里面全都是XGboost参数
虽然名次不怎么好,但我总体感觉还是很快乐的,毕竟是生命中第一次参加全球级的赛事,我也只是个0基础的文科生,能进前50%我就已经非常满足了。
原来自己是做产品经理的,走上自学机器学习的道路完全是出于机缘巧合,大概是在2020年7月的时候,我正巧在自学数据分析,报名参加了【2020中国Datathon数据分析大赛】,有幸拿到了一个亚军,赚了1.5W奖金。

之后自己就着了道,心想:“要是每个月都能靠参加比赛拿奖金,我是不是就不用参加工作了。”
于是便在10月份转行当了数据分析师,虽然目前只是个SQL Boy,但好在下班时间我还是会花1-2小时自学【机器学习】。
当时也是按照别人推荐的学习路线,看吴恩达的《机器学习》视频课,买了周志华的《西瓜书》,但发现自己老是学不进,总感觉代码太少了,学的都是一些理论知识。
后来看到一些关于【高中生参加Kaggle拿金牌】的文章,给了我很大的启发,里面有一句话彻底改变了自己的学习路线:
很多机器学习算法都是黑盒子,你不一定需要了解支撑它们运作的数学原理,只要会用就行。
正因如此,我改变了学习方式,不再看《机器学习》相关的理论知识和数学推导,直接开始上手【Sklearn官方文档】(英文版和中文版交替看)。
我发现很多机器学习算法真的如他们所说:“都是封装好的代码,就算不会调参,只要学会fit和train两段代码,就能够很好地运用。”
**正因如此,我在简单学习了Sklearn、Keras、XGboost的官方文档后,就直接开始了自己的Kaggle赛事第二站——**Tabular Playground Series - Jan 2021
比赛链接:
Tabular Playground Series - Jan 2021www.kaggle.com
比赛方案简介:
我算是一边比赛一边学习了,整理出了属于自己的【机器学习步骤】,我的比赛过程大致遵循如下图所示的笔记目录:

内容很乱,见谅
前期数据学习和EDA
整场比赛所有的特征都是匿名的,也没有啥业务背景的介绍文档。
EDA一开始是傻傻地用data.info()等dataframe方法,后面有一个数据科学社群大佬推荐我用一键式EDA库:sweetviz,结果发现整个数据可能是因为比赛是练习赛的缘故,没有任何缺失值、异常值……
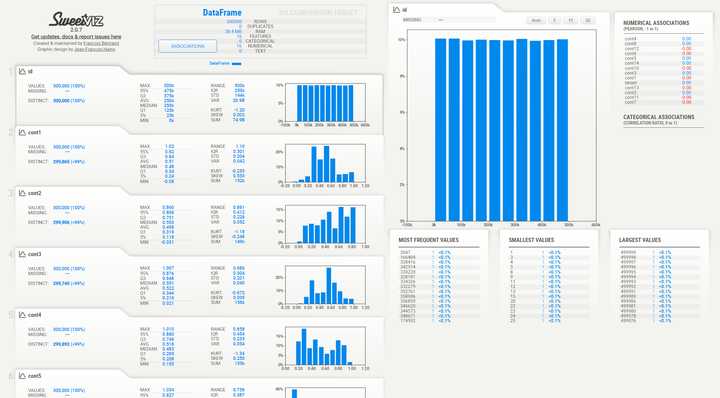
怎么样,效果是不是比data.info()好很多?
当然,自己也没能从这些EDA图标中看出啥结论,于是,我第一次的模型在没有做任何数据预处理和特征工程的情况下,直接用带着默认参数的LinearRegression():
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, Y_train)
y_predict = lr.predict(X_test)
这样做的结果很不理想,我第一次比赛成绩大概1728支队伍中排第1661名,用来评分的RMSE高达0.72703……

第一次提交还报错了……
特征缩放
后面在学Sklearn的过程中,了解到了Sklearn.preprocessing(数据预处理)这个库,还接触了标准化、归一化、PCA等一系列特征缩放操作。
反正看到1天能提交5次,就抱着“试一试”的态度,尝试对数据集进行了“标准化”:
from sklearn.preprocessing import StandardScaler #通过去除均值并缩放到单位方差来标准化特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 训练并转换
X_test = scaler.transform(X_test) ## 直接使用在模型构建数据上进行一个数据标准化操作
还有“正则化”:
from sklearn.preprocessing import Normalizer
normalizer = Normalizer().fit(X_train)
X_train = normalizer.transform(X_train)
X_test = normalizer.transform(X_test)
当然,少不了老生常谈的PCA:
import sklearn.decomposition as sk_decomposition
pca = sk_decomposition.PCA(n_components='mle',whiten=False,svd_solver='auto')
pca.fit(X_train)
X_train = pca.transform(X_train)
X_test = pca.transform(X_test)
#reduced_X为降维后的数据
print('PCA:')
print ('降维后的各主成分的方差值占总方差值的比例',pca.explained_variance_ratio_)
print ('降维后的各主成分的方差值',pca.explained_variance_)
print ('降维后的特征数',pca.n_components_)
当然,模型还是那个熟悉的线性回归。
本以为经过一番“骚操作”之后,自己的模型能有显著提升,结果发现处理后的数据RMSE更高了,排名反而还不如之前第一次提交……

更换线性回归模型
既然特征缩放没有效果,那该怎么办呢?
后面看了下Discussion,发现别人用的都是啥【MLP神经网络】、【随机森林】、【XGboost】……我当时在想,是不是自己的LinearRegression整个模型不行,导致分数上不去?
于是便考虑换模型。
一开始先是自学TensorFlow,发现啃不动,后面自学了Pytorch,发现这玩意儿对数学要求挺高的,Keras虽说是最友好的,但学起来还是有些一知半解。
后面惊喜的发现Sklearn中竟然有sklearn.neural_network这个库。
话不多说,直接用Sklearn的【多层感知机回归】:
#神经网络回归:
from sklearn.neural_network import MLPRegressor
model_mlp = MLPRegressor(hidden_layer_sizes=(6,2), activation='relu', solver='adam', alpha=0.0001, batch_size='auto',learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=5000, shuffle=True,random_state=1, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True,early_stopping=False,beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model_mlp.fit(X_train,Y_train)
y_predict = model_mlp.predict(X_test)
成绩终于有了比较大的提升,直接到了约1400多名。

后面发现Sklearn也能做【随机森林】:
## 随机森林回归
from sklearn.ensemble import RandomForestRegressor
rfr=RandomForestRegressor()
rfr.fit(X_train,Y_train)
y_predict = rfr.predict(X_test)
直接套用随机森林,发现提升更大,现在自己的成绩也算是挺进了1200多名。

XGboost
说实话,在我当时的理解中,【神经网络】是要比【随机森林】高级的,但我这边用随机森林的效果竟然比神经网络算法要好,这令我非常困惑。
好在当时为了能够在比赛中拿到好名次,看了许多比赛经验,发现了一个比较重要的观点:
“神经网络虽然泛用性强,但调参不恰当的神经网络在线性数据中的处理可能会不及许多树模型。”
“相较于随机森林,XGboost这种梯度提升树已经成为了Kaggle等众多比赛中的大杀器。”
为了让模型进一步提升,我便自学了XGboost,发现这个模型也能够直接fit后再train,太好了:
import xgboost as xgb
model = xgb.XGBRegressor()
model.fit(X_train,Y_train)
y_predict = model.predict(X_test)
XGboost使我的RMSE直接降低了0.01,我的成绩也算是挺进了前1000名。

GridSearchCV调参
在确定了XGboost是当前我的最佳选择后,我继续开始了“瞎折腾”:
用F得分函数剔除掉不显著特征,成绩下降 标准化和PCA依然没有起到太大的作用
一筹莫展的时候接触到了GridSearchCV这个神奇的自动超参数优化库,便开始了自己的调参之旅:
## GridSearch超参数优化
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
# from tune_sklearn import TuneGridSearchCV
cv_params = {'seed': [2750 ,2770, 2800 ,2820 ,2850]}
other_params = {'learning_rate': 0.1, 'n_estimators': 480, 'max_depth': 6, 'min_child_weight': 4, 'seed': 2800,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBRegressor(**other_params) ##model = xgb.XGBRegressor(**other_params) 双星号是把字典解包传参
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=8)
optimized_GBM.fit(X_train, Y_train)
evalute_result = optimized_GBM.score
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
调参一点一点提升了我的成绩。
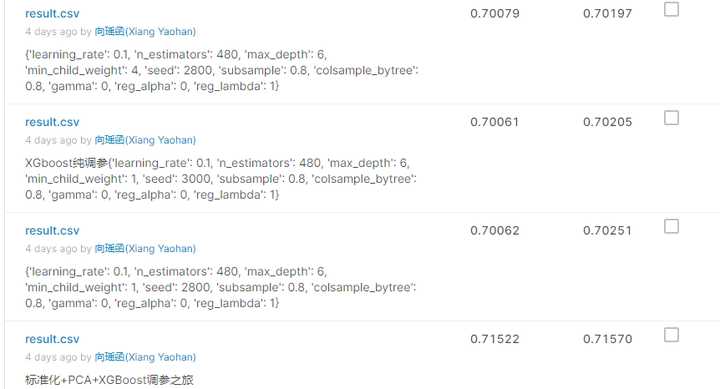
但GridSearchCV的短板也十分明显,因为sklearn不支持GPU加速,并且每次GridSearchCV只能够搜索一个参数,加上一个参数要搜索好几次,我的CPU经常100%负载,每一个参数都要搜索一天……
optuna调参
当时只好又翻了下Discussion,好在有个人发了篇关于【XGboost调参】的文章,我才了解到了有一个叫做“optuna”的神奇GPU加速超参数优化PIP库,我几乎把XGboost所有的参数都输入了进去:
import optuna
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
def objective(trial,data=X_train,target=Y_train):
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.15,random_state=42)
param = {
'tree_method':'gpu_hist', # Use GPU acceleration
'lambda': trial.suggest_loguniform(
'lambda', 10, 15.0
),
'alpha': trial.suggest_loguniform(
'alpha', 2e-3, 3e-3
),
'colsample_bytree': trial.suggest_loguniform(
'colsample_bytree', 0.45 , 0.65
),
'subsample': trial.suggest_loguniform(
'subsample', 0.5,0.7
),
'learning_rate': trial.suggest_loguniform(
'learning_rate', 0.0075,0.0095
),
'n_estimators': trial.suggest_int(
"n_estimators", 2900, 3100
),
'max_depth': trial.suggest_int(
'max_depth', 10,15
),
'random_state': 42,
'min_child_weight': trial.suggest_int(
'min_child_weight', 200, 400
),
'seed': trial.suggest_int(
'seed', 2600,2900
),
'gamma': trial.suggest_loguniform(
'gamma', 8e-3, 1e-2
)
}
model = xgb.XGBRegressor(**param)
model.fit(train_x,train_y,eval_set=[(test_x,test_y)],early_stopping_rounds=100,verbose=False)
preds = model.predict(test_x)
rmse = mean_squared_error(test_y, preds,squared=False)
return rmse
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=17)
print('Number of finished trials:', len(study.trials))
print('Best trial:', study.best_trial.params)
改善是明显的,因为GPU加速,我一天就能调试完几乎全部的参数,RMSE终于挺进了0.69!
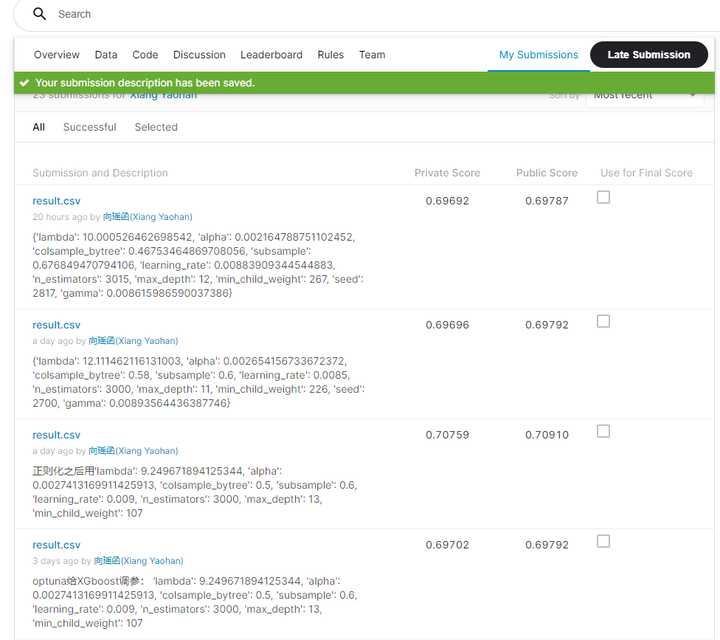
后面如果还接着调参的话,也许成绩会有更大的提升,不过一场比赛下来,自己实在是筋疲力尽了,就让名次止步于第362名吧。
第一次写机器学习的文章,难免有纰漏,如果有大神愿意指导的话,请添加在下的私人微信:a112901528(微信名:向瑶函),请备注【Kaggle】,感谢您的帮助。