【GAN】基础原理讲解及代码实践
首先什么是GAN:





GAN的模型结构

设计GAN模型的关键:



GAN的算法原理:


这里输入噪声的随机性就可以带来生成图像的多样性


GAN公式讲解:



D(x)表示判别器对真实图片的判别,取对数函数后我们希望其值趋于0,也就是D(x)趋于1,也就是放大损失。











GAN代码实践(基于jupyter,顺序执行即可):
导包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
torch.__version__数据准备
# 对数据做归一化 (-1, 1)对gan的输入数据全部规范化到(-1,1)之间
transform = transforms.Compose([ #transform做变形
transforms.ToTensor(), # ToTensor会将图像像素值转换为0-1; channel, high, witch,
transforms.Normalize(0.5, 0.5) #然后我们通过均值为0.5,方差为0.5将数据规范化到(-1,1)
])
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=transform,
download=True)#定义MNIST数据集
dataloader = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)#加载数据集,打乱,batch_size设置为64
#%%
imgs, _ = next(iter(dataloader))#加载一个批次的图片(64张)
#%%
imgs.shape
定义生成器
# 输入是长度为 100 的 噪声(符合正态分布的随机数)
# 输出为(1, 28, 28)的图片
#linear 1 : 100----256
#linear 2: 256----512
#linear 2: 512----28*28
#reshape: 28*28----(1, 28, 28)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28*28),
nn.Tanh() # 对于-1, 1之间的数据分布,Tanh效果最好。输出的取值范围是-1,1之间
)
def forward(self, x): # 前向传播,x 表示长度为100 的noise输入
img = self.main(x)#将x输入到main模型中 得到img
img = img.view(-1, 28, 28)#通过view函数reshape成(-1,28,28,1)
return img
定义判别器
## 输入为(1, 28, 28)的图片 输出为二分类的概率值,输出使用sigmoid激活 0-1
# BCEloss计算交叉熵损失
# nn.LeakyReLU f(x) : x>0 输出 x, 如果x<0 ,输出 a*x a表示一个很小的斜率,比如0.1
# 判别器中一般推荐使用 LeakyReLU,RELU激活函数在小于0没有任何梯度,会非常难以训练
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()#继承父类的属性
self.main = nn.Sequential(
nn.Linear(28*28, 512),#输入一张图片28,8,然后展平成28*28,再卷积到256
nn.LeakyReLU(),
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):#x输入的是28,28的图片
x = x.view(-1, 28*28)#展平
x = self.main(x)
return x初始化模型、优化器及损失计算函数
device = 'cuda' if torch.cuda.is_available() else 'cpu'#默认使用cuda,否则cpu
#%%
gen = Generator().to(device)#初始化Generator模型
dis = Discriminator().to(device)#初始化Discriminator模型
#%%
d_optim = torch.optim.Adam(dis.parameters(), lr=0.0001)#定义优化器,学习率
g_optim = torch.optim.Adam(gen.parameters(), lr=0.0001)
#%%
loss_fn = torch.nn.BCELoss()#二分类判别模型绘图函数
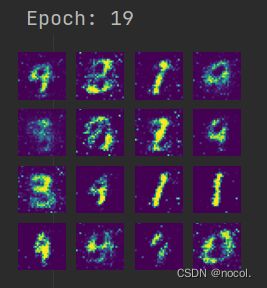
def gen_img_plot(model, test_input):#每次都给一个同样的test_input正态分布随机数
prediction = np.squeeze(model(test_input).detach().cpu().numpy())#detach用来截断梯度,放到cpu上,转换为numpy,squeeze用于去掉维度为一的值,鲁棒性更高===>28*28的数组
fig = plt.figure(figsize=(4, 4))#绘制16张图片
for i in range(16):#循环
plt.subplot(4, 4, i+1)#四行四列的第一张
plt.imshow((prediction[i] + 1)/2)#转换成0,1之间的数值(预测的结果恢复到0,1之间
plt.axis('off')#关闭
plt.show()
#%%
test_input = torch.randn(16, 100, device=device)#生成长度为100的一个批次16张的随机噪声输入
GAN的训练
D_loss = []
G_loss = []#定义空列表用来放两个模型生成的loss
#%%
# 训练循环
for epoch in range(20):#训练20轮
d_epoch_loss = 0
g_epoch_loss = 0#初始化损失函数为0
count = len(dataloader)#返回批次数,len(dataset)返回样本数
for step, (img, _) in enumerate(dataloader):#_表示标签,这里生成模型用不到,enumerate用于对dataloader迭代
img = img.to(device)#将照片上传到设备上
size = img.size(0)#获批次大小根据这个大小来输入我们随机噪声的输入大小
random_noise = torch.randn(size, 100, device=device)#生成噪声随机数,大小个数是size
d_optim.zero_grad()#将梯度归0
real_output = dis(img) # 判别器输入真实的图片,real_output对真实图片的预测结果 真实图片为1,假图片为0
d_real_loss = loss_fn(real_output,
torch.ones_like(real_output)) # 得到判别器在真实图像上的损失 ones_like:全1数组
d_real_loss.backward()#反向传播,计算梯度
gen_img = gen(random_noise)
# 判别器输入生成的图片,fake_output对生成图片的预测
fake_output = dis(gen_img.detach()) #这里阶段梯度是因为,这里通过对判别器输入生成图片去计算损失是用来优化判别器的。对生成器的参数暂时不做优化。所以梯度不用再传递到生成器模型当中了,我们希望fake_output被判定为0
d_fake_loss = loss_fn(fake_output,
torch.zeros_like(fake_output)) # 得到判别器在生成图像上的损失,zeros_like:全0数组
d_fake_loss.backward()#同样计算梯度
#以上是用来优化判别器
d_loss = d_real_loss + d_fake_loss#判别器的总损失(两部分)
d_optim.step()#进行优化
g_optim.zero_grad()#梯度归零
fake_output = dis(gen_img)#将生成图片放到判别器当中--不要梯度截断
g_loss = loss_fn(fake_output, #我们这里就希望fake_output被判定为1用来优化生成器
torch.ones_like(fake_output)) # 生成器的损失
g_loss.backward()#计算梯度
g_optim.step()#权重优化
with torch.no_grad():#两个模型的损失函数做累加(不需要计算梯度)---每个批次累加==一个epoch
d_epoch_loss += d_loss
g_epoch_loss += g_loss
with torch.no_grad():#得到平均loss
d_epoch_loss /= count
g_epoch_loss /= count
D_loss.append(d_epoch_loss.item())
G_loss.append(g_epoch_loss.item())#这样列表当中会保存每个epoch的平均loss
print('Epoch:', epoch)#打印当前epoch
gen_img_plot(gen, test_input)#绘图运行效果