一:简述
本篇文章对java并发包工具CountDownLatch进行介绍,并且通过对CountDownLatch源码的分析来加深对CountDownLatch的理解。
二:什么是CountDownLatch
CountDownLatch是java并发包中提供的一个工具类,CountDownLatch的作用很简单,它可以让一个或者一组线程在开始执行操作之前,必须要等到其他线程执行完才执行,它是基于AQS的共享锁来实现的。
三:CountDownLatch的使用
简单介绍下CountDownLatch的使用
CountDownLatch的主要方法有三个:
1.构造函数
2.countDown()
3.await()
简单给大家写一个demo:
public class TestThread {
static CountDownLatch countDownLatch = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
System.out.println("线程等待");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程C被唤醒");
},"线程C").start();
new Thread(()->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("计数器减1");
countDownLatch.countDown();
},"线程A").start();
new Thread(()->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("计数器减1");
countDownLatch.countDown();
},"线程B").start();
countDownLatch.await();
System.out.println("主线程被唤醒");
}
}
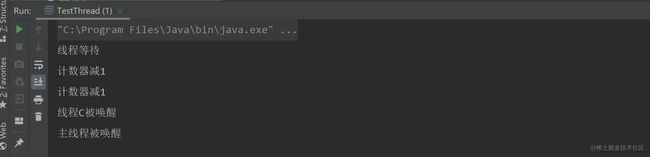
线程C和主线程调用await()方法后会进行阻塞,直到线程A和线程B调用countdown()方法将计数值减为0之后才会继续执行。
输出结果:
四:CountDownLatch原理分析
前面两个小节是为了帮助不知道没使用过CountDownLatch的同学。那么接下来进入正题,对CountDownLatch的原理分析。我们将以CountDownLatch的构造函数,countDown(),await()三个方法对CountDownLatch的源码进行解析。
构造函数
CountDownLatch只有一个有参的构造函数,我们需要传递一个大于0的整数,构造函数会初始化一个Sync的实例,而Sync正是继承了AbstractQueuedSynchronizer(简称AQS)。Sync初始化的时候会将我们设置的整数传递给AQS的成员变量state。
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
setState(count);
}
}
protected final void setState(int newState) {
state = newState;
}
接下来我们看await()方法
await()方法:
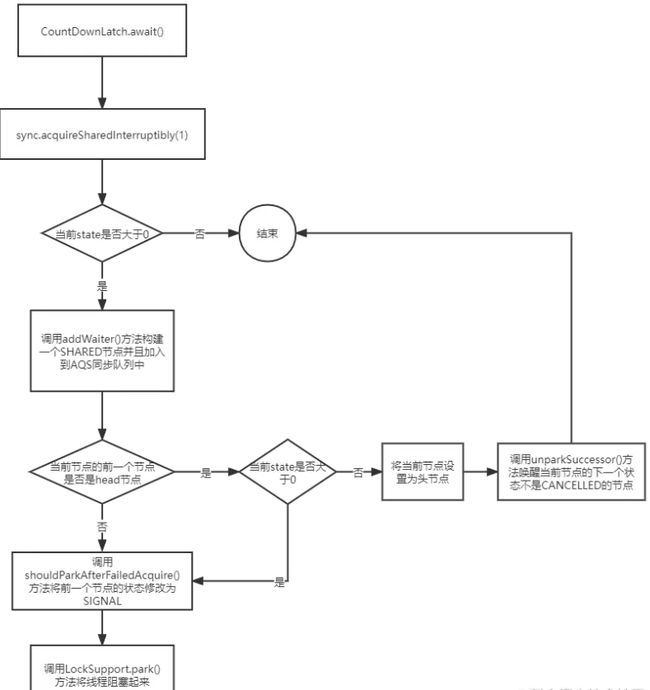
流程图:
源码分析:
首先线程调用await()方法后会去判断当前state是否大于0,如果不是大于0,那么直接就返回继续执行业务代码,如果大于0,那么就会调用doAcquireSharedInterruptibly()。所以重点是doAcquireSharedInterruptibly()方法。
public void await() throws InterruptedException {
//调用Sync的acquireSharedInterruptibly()方法
sync.acquireSharedInterruptibly(1);
}
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//判断当前的state的值是否等于0 如果等于0返回1 否则返回-1
if (tryAcquireShared(arg) < 0)
// 如果state等于0 那么什么都不做 直接返回,如果大于0 就执行doAcquireSharedInterruptibly()
doAcquireSharedInterruptibly(arg);
}
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
await()方法的核心在于doAcquireSharedInterruptibly()方法,所以接下来我们重点分析doAcquireSharedInterruptibly()方法。
doAcquireSharedInterruptibly()
首先通过addWaiter()方法将当前线程封装成一个类型为SHARED的Node节点,然后判断当前节点的前一个节点是否是head节点,分为两种情况:
1. 当前节点的前置节点是head节点
那么就会再次调用tryAcquireShared()判断一下state的值是等于0,又分为两种情况
a. state如果等于0
那么就调用setHeadAndPropagate()方法将当前节点设置为头节点,并且调用唤醒下一个状态不为CANCELLED的节点。
b. 如果state不等于0
那么就调用shouldParkAfterFailedAcquire()方法将前一个节点的状态修改为SIGNAL,并且调用parkAndCheckInterrupt()方法将当前线程阻塞起来。
2. 当前节点的前置节点不是head节点
那么就掉用shouldParkAfterFailedAcquire()方法将前一个节点的状态修改为SIGNAL,并且调用parkAndCheckInterrupt()方法将当前线程阻塞起来。
(需要注意的是线程被唤醒之后继续执行这里的代码)
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
//调用addWaiter()方法将线程封装成Node并且放入到AQS队列的尾部
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
//获取当前节点的前一个节点
final Node p = node.predecessor();
//如果前一个节点是head节点
if (p == head) {
//再次判断state的值是否为0
int r = tryAcquireShared(arg);
// tryAcquireShared()返回1代表state为0
if (r >= 0) {
//将当前节点设置为头节点 并且唤醒下一个正常的节点
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
//shouldParkAfterFailedAcquire()方法将当前节点的前一个节点的状态设置为SIGNAL,
//parkAndCheckInterrupt()方法将当前线程阻塞
//线程被唤醒之后继续从这里开始执行
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
addWaiter()
addWaiter()作用是将当前线程封装成Node节点,并且加入到AQS队列中。
private Node addWaiter(Node mode) {
//将没有获得锁的线程封装成一个node
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
//如果AQS尾结点不为null 代表AQS链表已经初始化 尝试将构建好的节点添加到链表的尾部
if (pred != null) {
node.prev = pred;
//cas替换AQS的尾结点
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//没有初始化调用enq()方法
enq(node);
return node;
}
private Node enq(final Node node) {
//自旋
for (;;) {
Node t = tail;
//尾结点为空 说明AQS链表还没有初始化 那么进行初始化
if (t == null) { // Must initialize
//cas 将AQS的head节点 初始化 成功初始化head之后,将尾结点也初始化
//注意 这里我们可以看到head节点是不存储线程信息的 也就是说head节点相当于是一个虚拟节点
if (compareAndSetHead(new Node()))
tail = head;
} else {
//尾结点不为空 那么直接添加到链表的尾部即可
//加入链表的时候先指定prev 然后cas成功 再指定next
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
setHeadAndPropagate()
setHeadAndPropagate()的作用就是将当前节点设置为头结点,并且调用doReleaseShared()方法唤醒当前节点的下一个正常节点。doReleaseShared()方法我们在下面分析countDown()方法的时候在进行仔细的分析。
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
//将当前节点设置为头结点
setHead(node);
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
//唤醒头结点的下一个节点
//其实也就是当前节点的下一个节点,因为前面已经将当前节点设置为新的头结点了
doReleaseShared();
}
}
shouldParkAfterFailedAcquire()
shouldParkAfterFailedAcquire()方法会将传入的节点(传进来的是当前节点的前置节点)的状态设置为SIGNAL状态。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
//如果节点是SIGNAL状态 不需要处理 直接返回
return true;
if (ws > 0) {
//如果节点状态>0 说明节点是取消状态 这种状态的节点需要被清除 用do while循环顺便清除一下前面的连续的、状态为取消的节点
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//正常的情况下 利用cas将前一个节点的状态替换为 SIGNAL状态 也就是-1
//注意 这样队列中节点的状态 除了最后一个都是-1 包括head节点
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt()
parkAndCheckInterrupt()方法的作用就是调用 LockSupport.park()方法将线程阻塞,并且返回线程的中断标志。
private final boolean parkAndCheckInterrupt() {
//挂起当前线程 并且返回中断标志 LockSupport.park(thread) 会调用UNSAFE.park()方法将线程阻塞起来(是一个native方法)
LockSupport.park(this);
return Thread.interrupted();
}
到这里await()方法也就分析完了 接下来我们分析countDown()方法
countDown()
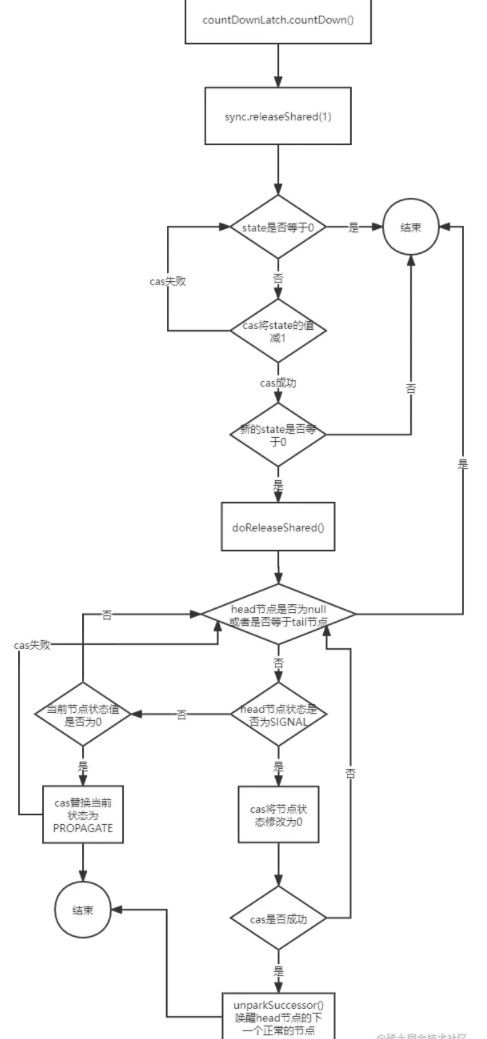
流程图:
源码:
countDown()方法首先查看state的值是否是0,分为两种情况
1. 如果state为0
说明没有线程需要被唤醒,那么直接返回。
2. 如果state不为0
那么将利用cas将state的值减1,判断新的state是否为0 ,如果不为0,说明还不能唤醒阻塞的线程,直接返回,如果新的state为0,那么调用doReleaseShared()方法唤醒阻塞的线程。
public void countDown() {
sync.releaseShared(1);
}
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
//自旋+cas保证线程安全
for (;;) {
//获取state的值
int c = getState();
//如果state为0 说明没有需要唤醒的线程 直接返回
if (c == 0)
return false;
int nextc = c-1;
//利用cas将state减一 如果新的state为0 说明需要唤醒阻塞的线程,否则不需要唤醒
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
countDown()方法核心是doReleaseShared()方法 所以我们重点分析doReleaseShared()。
doReleaseShared()
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
//如果头结点的状态是SIGNAL
if (ws == Node.SIGNAL) {
//cas修改节点的状态为0 失败的话继续自旋
// 成功的话调用unparkSuccessor唤醒头结点的下一个正常节点
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
//如果节点状态为0 那么cas替换为PROPAGATE 失败进入下一次自旋
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
unparkSuccessor()
unparkSuccessor()方法的作用是唤醒头节点后第一个不为null且状态不为cancelled的节点。
private void unparkSuccessor(Node node) {
//获取头结点的状态 将头结点状态设置为0 代表现在正在有线程被唤醒 如果head状态为0 就不会进入这个方法了
int ws = node.waitStatus;
if (ws < 0)
//将头结点状态设置为0
compareAndSetWaitStatus(node, ws, 0);
//唤醒头结点的下一个状态不是cancelled的节点 (因为头结点是不存储阻塞线程的)
Node s = node.next;
//当前节点是null 或者是cancelled状态
if (s == null || s.waitStatus > 0) {
s = null;
//从aqs链表的尾部开始遍历 找到离头结点最近的 不为空的 状态不是cancelled的节点 赋值给s
//这里为什么从尾结点开始遍历而不是头结点 是因为添加结点的时候是先初始化结点的prev的, 从尾结点开始遍历 不会出现prve没有赋值的情况
//如果从头结点进行遍历 next为null 并不能保证链表遍历完了
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
//调用LockSupport.unpark()唤醒指定的线程
LockSupport.unpark(s.thread);
}
线程被唤醒之后,我们需要回到线程阻塞的地方继续分析线程被唤醒之后的操作。
前文我们分析await()方法之后已经知道了线程阻塞在doAcquireSharedInterruptibly()方法中。如果线程没有被中断过,会判断state的值,这里线程是被调用countDown方法唤醒的,所以state一定是0,所以会调用setHeadAndPropagate()方法更新头结点并继续唤醒之后的线程。这样就会把依次将所有阻塞的阻塞线程都唤醒。(因为countDownLatch的计数器为0之后需要将所有调用await()阻塞的线程唤醒)
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
//
for (;;) {
//获取当前节点的前一个节点
final Node p = node.predecessor();
//如果前一个节点是head节点
if (p == head) {
//再次判断state的值是否为0
int r = tryAcquireShared(arg);
// tryAcquireShared()返回1代表state为0
if (r >= 0) {
//将当前节点设置为头节点 并且唤醒下一个正常的节点
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
//线程被唤醒之后继续从这里开始执行 如果线程没有被中断过 会进入都下次for循环
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
五:最后
本篇文章主要介绍了CountDownLatch的使用并且通过分析其源码对CountDownLatch的原理进行了分析。
注:其实像addWaiter(),unparkSuccessor(),shouldParkAfterFailedAcquire()等一些AQS公用的方法在我的另外一篇文章里分析过,原文地址:ReentrantLock源码分析
更多关于java并发包CountDownLatch的资料请关注脚本之家其它相关文章!