李宏毅《Speech Recognition》学习笔记2 - LAS
最近在学习语音识别的知识,发现李宏毅老师今年也出了相应的视频,相应的课件可以从下面的位置获取:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
Youtube视频:
https://youtu.be/AIKu43goh-8
https://youtu.be/BdUeBa6NbXA
https://youtu.be/CGuLuBaLIeI
课件:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/DLHLP20/ASR%20%28v12%29.pdf
Listen, Attend, and Spell (LAS)

Framework
Listen
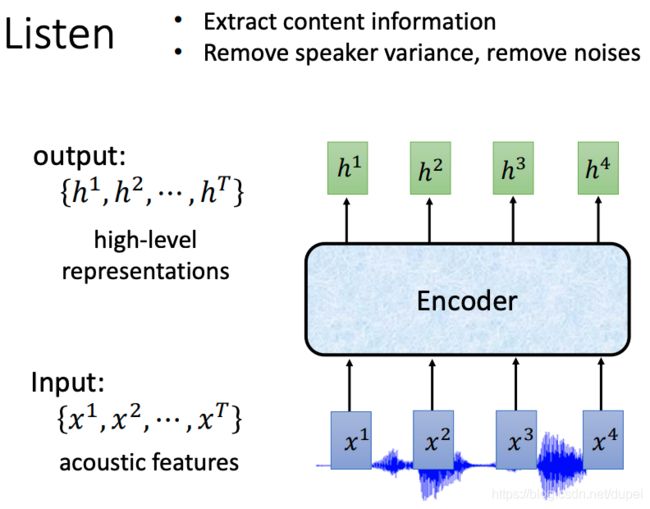
Encoder的实现方式一:RNN
单向、双向 RNN都可以
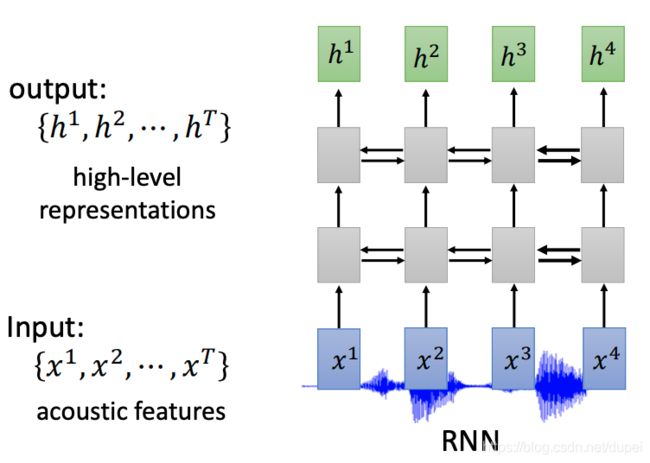
Encoder的实现方式二:CNN

Encoder的实现方式三:Self-attention

Self-attention的介绍:https://www.youtube.com/watch?v=ugWDIIOHtPA
提升训练效率
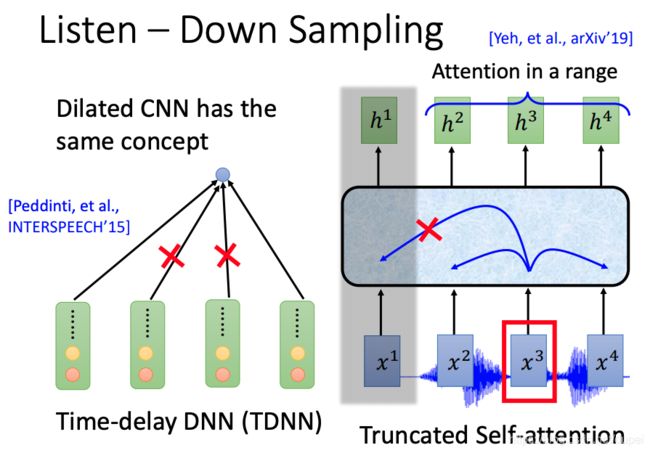
Down Sampling有助提升训练的效率
下面是对RNN的down sampling

下面是对CNN和self-attention的down sampling
truncated self-attention,是通过控制attention的宽带来实现。
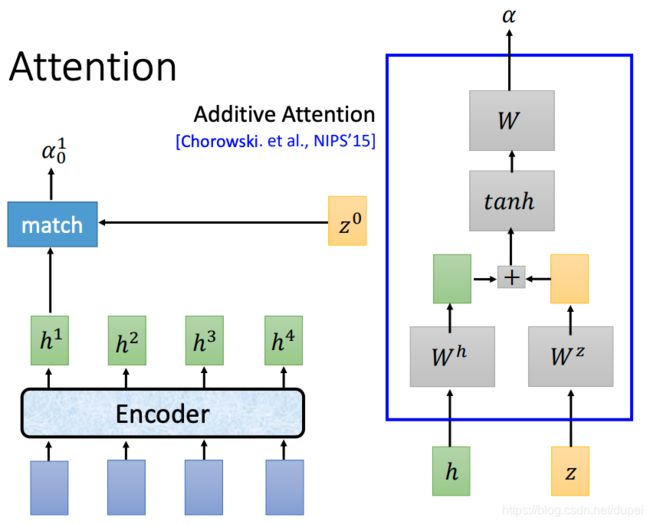
Attention
Attention的工作类似seq-to-seq,输入是Encoder的输出和关键词z,通过函数match进行处理,得到输出。下图的右侧是常用的match function,也就是dot-product attaction。W是transform函数。

另一种match function,见下图右侧。
经过上面的处理以后,我们得到了一系列的 α 0 1 , α 0 2 , α 0 3 , . . . \alpha_0^1,\alpha_0^2,\alpha_0^3,... α01,α02,α03,...,然后,做softmax处理,得到 α ^ 0 1 , α ^ 0 2 , α ^ 0 3 , . . . \hat{\alpha}_0^1,\hat{\alpha}_0^2,\hat{\alpha}_0^3,... α^01,α^02,α^03,...,使得他们的和为1。再将其与 h i h^i hi做dot-production,即 c 0 = ∑ α ^ 0 i h i c^{0}=\sum \hat{\alpha}_{0}^{i} h^{i} c0=∑α^0ihi
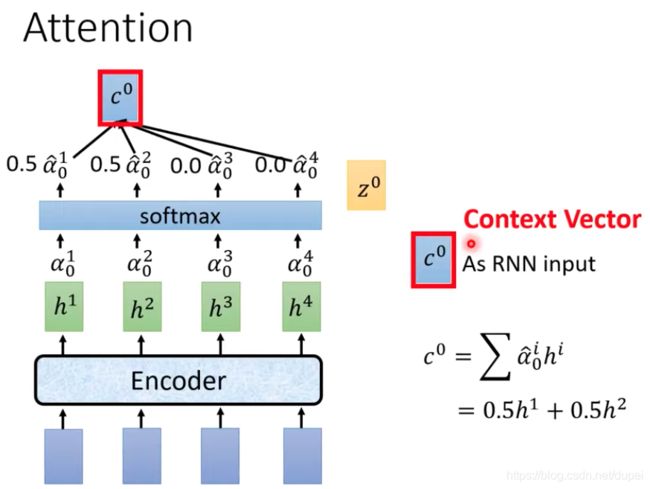
其中,产生的 c 0 c^{0} c0将会用于后续decoder的输入,也被称为Context Vector。
Spell
有了 c 0 c^0 c0以后,就可以通过self-attention,生成 z 1 z^1 z1,再做transform+softmax,生成token的distribution,其中,最大的就是预测的结果 c c c
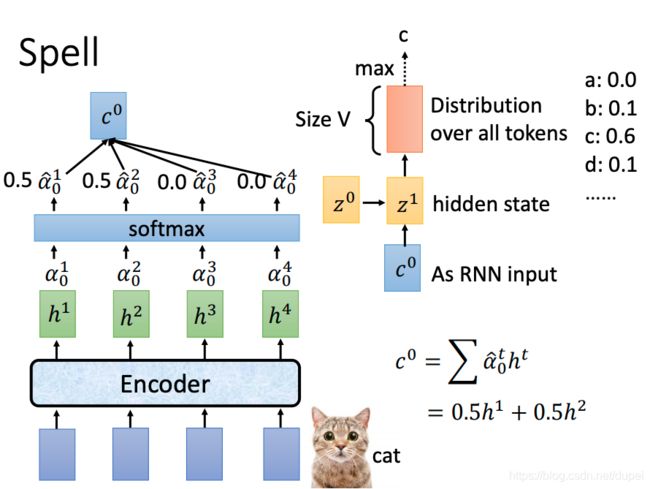
有了 z 1 z^1 z1以后,可以重复上面的 z 0 z^0 z0过程,生成 α 1 1 , α 1 2 , α 1 3 , . . . \alpha_1^1,\alpha_1^2,\alpha_1^3,... α11,α12,α13,...
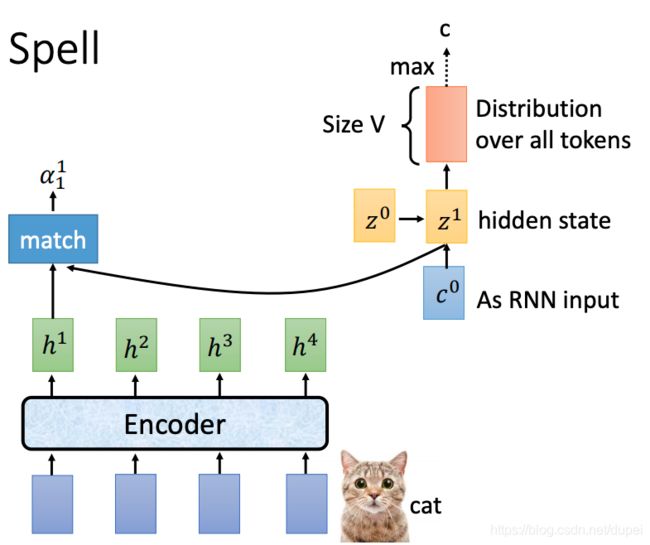
进一步计算出 c 1 c^1 c1,有了 c 1 c^1 c1以后,配合之前预测的c,生成 z 1 z^1 z1,然后,预测出新的输出a。
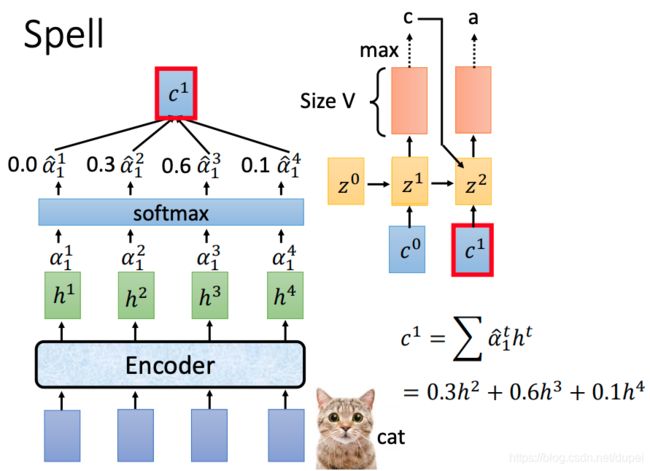
一直到最后的
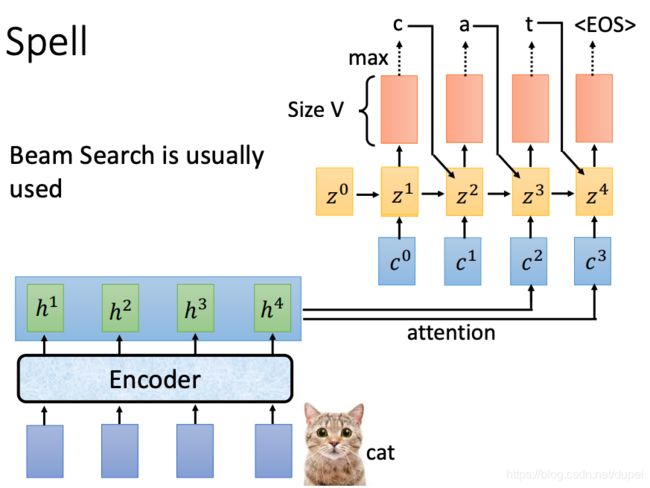
当然,上面所说的步骤,都是建立在decoder的参数是已经确定下来的基础上,并且,在过程中,会使用到beam search的技术,这个可以参见下面一篇文章的介绍。
接下来,我们就来介绍训练过程
Train
todo
token表示为one-hot vector,训练的目标就是将cross entropy loss越小越好。
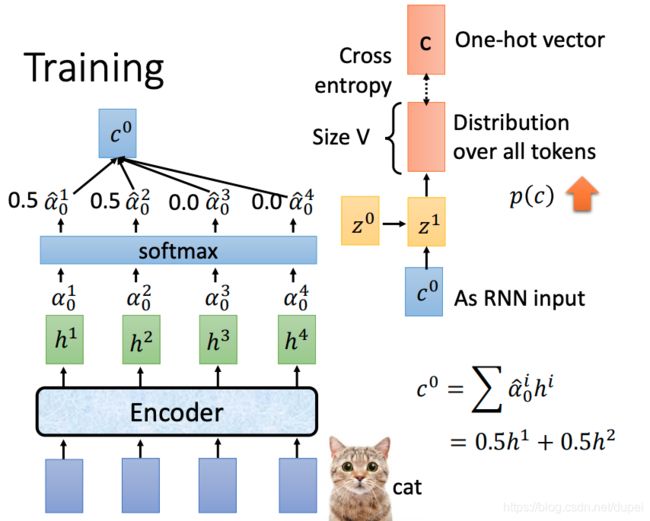
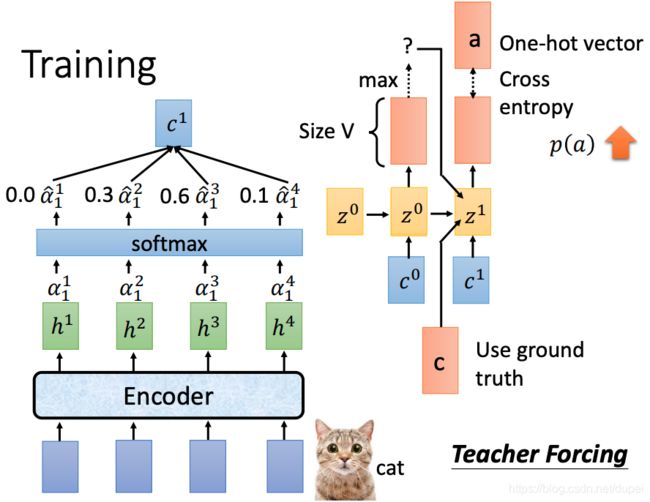
训练过程中,与使用过程中有一个不一样的地方:**后续的预测使用真实的结果(ground truth),而不是预测的结果。**这个过程叫teacher forcing.
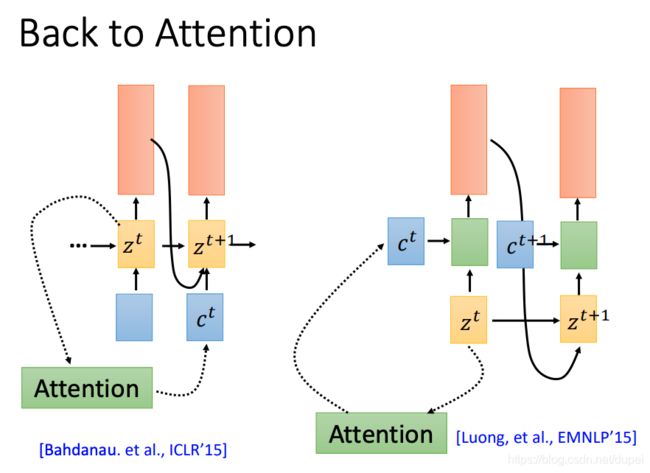
Decoder中是如何使用attention的,有下面两种。
LAS的局限
