数据挖掘常用算法总结
算法总结
个人博客:www.xiaobeigua.icu
第一章
(1)数据挖掘概念。
数据挖掘是在大型数据库中自动发现有用信息的过程
数据挖掘是数据库中知识发现(kdd)必不可少的部分
(2)数据库技术自然的演化, 有巨大的需求和广阔的应用。
知识发现的过程包含了数据清洗, 数据集成, 数据选择, 数据转换, 数据挖掘, 模式评估和知识表现。
数据挖掘功能: 特征, 区别, 关联, 分类, 聚类, 孤立点和趋势分析等.
(3)数据挖掘系统和体系架构:
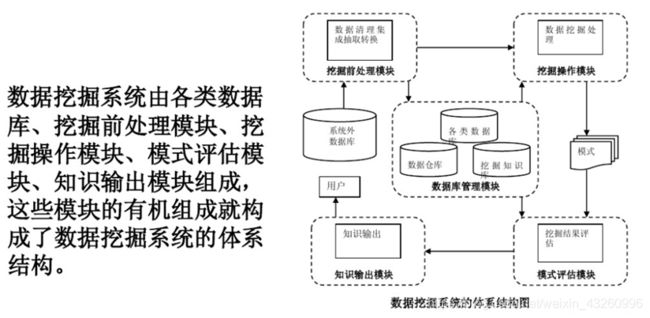
(4)数据挖掘主要问题
1、分类问题
分类问题属于预测性的问题,但是它跟普通预测问题的区别在于其预测的结果是类别(如A、B、C三类)而不是一个具体的数值(如55、65、75……)。
方法:决策树、Logistic回归、判别分析、神经网络、Chi-square、Gini等相关知识
2、聚类问题
聚类问题不属于预测性的问题,它主要解决的是把一群对象划分成若干个组的问题。划分的依据是聚类问题的核心。所谓“物以类聚,人以群分”,故得名聚类。
方法:聚类分析、系统聚类、K-means聚类、欧氏距离、马氏距离等知识。
3、关联问题
说起关联问题,可能要从“啤酒和尿布”说起了。有人说啤酒和尿布是沃尔玛超市的一个经典案例,也有人说,是为了宣传数据挖掘/数据仓库而编造出来的虚构的“托”。不管如何,“啤酒和尿布”给了我们一个启示:世界上的万事万物都有着千丝万缕的联系,我们要善于发现这种关联。
方法:关联规则、apriror算法中等相关知识
4、预测问题
a此处说的预测问题指的是狭义的预测,并不包含前面阐述的分类问题,因为分类问题也属于预测。一般来说我们谈预测问题主要指预测变量的取值为连续数值型的情况。
例如天气预报预测明天的气温、国家预测下一年度的GDP增长率、电信运营商预测下一年的收入、用户数等?
方法:一元线性回归分析、多元线性回归分析、最小二乘法等相关知识。
第二章
数据预处理对数据仓库和数据挖掘来说都是大问题。
描述性数据汇总是预处理对数据质量的要求。
数据预处理:数据清洗、数据集成、数据规约、特征提取、离散化处理
第三章
(1)关联规则挖掘相关基本概念和路线图
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现事情之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系。
关联规则挖掘的定义:给定一个交易数据集T,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的关联规则。
(2)有效的和可伸缩的频繁项集挖掘方法
FP-growth算法
(3)Apriori算法思想、步骤、优缺点
Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集的 算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的。它使用一种称作逐层搜索的迭代方法,k- 项集用于探索(k+1)- 项集。首先,找出频繁 1- 项集的集合。该集合记作L1。L1 用于找频繁2- 项集的集合 L2,而L2 用于找L2,如此下去,直到不能找到 k- 项集。每找一个 Lk 需要一次数据库扫描。为提高频繁项集逐层产生的效率,一种称作Apriori 性质的重 要性质 用于压缩搜索空间。其运行定理在于一是频繁项集的所有非空子集都必须也是频繁的,二是非频繁项集的所有父集都是非频繁的。
Apriori算法过程分为两个步骤:
第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小信任度的规则。
具体做法就是:
首先找出频繁1-项集,记为L1;然后利用L1来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。
Apriori算法的优点:简单、易理解、数据要求低,
Apriori算法的缺点:
(1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据库D中的全部记录进行了一遍扫描比较,如果是一个大型的数据库的话,这种扫描比较会大大增加计算机系统的I/O开销。而这种代价是随着数据库的记录的增加呈现出几何级数的增加。因此人们开始寻求更好性能的算法。
第四章
(1)分类和预测概念
分类是用于预测数据对象的离散类别的,需要预测的属性值是离散的、无序的。
预测则是用于预测数据对象的连续取值的,需要预测的属性值是连续的、有序的。
(2)基于决策树归纳的分类,ID3,C4.5算法思想、步骤、优缺点
1(决策树归纳算法)
决策树(Decision Tree,DT)分类法是一个简单且广泛使用的分类技术。
决策树是一个树状预测模型,它是由结点和有向边组成的层次结构。树中包含3种结点:根结点、内部结点和叶子结点。决策树只有一个根结点,是全体训练数据的集合。
树中的一个内部结点表示一个特征属性上的测试,对应的分支表示这个特征属性在某个值域上的输出。一个叶子结点存放一个类别,也就是说,带有分类标签的数据集合即为实例所属的分类。ID)
2(ID3算法)
ID3基本思想:
ID3算法需要解决的问题是如何选择特征作为划分数据集的标准。在ID3算法中,选择信息增益最大的属性作为当前的特征对数据集分类。信息增益的概念将在下面介绍,通过不断的选择特征对数据集不断划分;
Id3基本步骤:
1. 计算类别信息熵
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越大,不确定性就越大,把事情搞清楚所需要的信息量就越多。
2. 计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示这个属性中拥有的样本类别越不“纯”。
3. 计算信息增益
信息增益的 = 熵 - 条件熵,在这里就是 类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果一个属性的信息增益越大,就表示用这个属性进行样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类目标。
信息增益就是ID3算法的特征选择指标。
ID3算法优缺点:
优点:
1.假设空间包含所有的决策树,搜索空间完整。
2.健壮性好,不受噪声影响。
3.可以训练缺少属性值的实例。
缺点:
1.ID3只考虑分类型的特征,没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
2.ID3算法对于缺失值没有进行考虑。
3.没有考虑过拟合的问题。
ID3例子:
.
1.系统信息熵:(是,否为好瓜的两个属性)

2.每个特征的信息熵:(以色泽为例)(先计算出3 个属性的信息熵,依次为:青绿,乌黑,浅白)
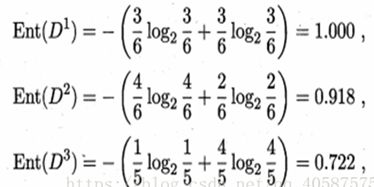
然后,结合3 个属性,计算出特征为色泽的信息熵:
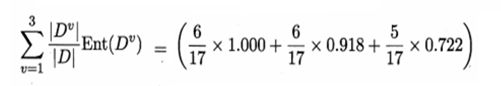

信息增益大,代表着熵小,所以确定性较高。
3得出决策结果

但是,当我们使用ID编号作为一个特征量的时候
´得到信息熵:
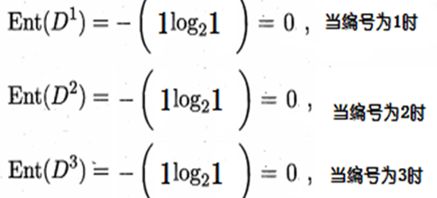
´信息增益为:
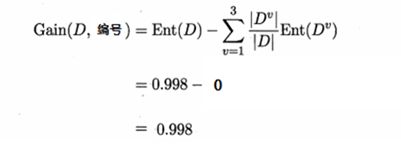
所以需要使用编号作为根节点吗?显然不可能。
3(C45算法)
C45主要思想:
用信息增益比来选择属性,克服了用信息增益选择属性是偏向选择去之多的属性的不足
在数的构造过程中进行剪枝
能够对连续的属性进行离散化处理
能够对不完整的数据进行处理
C45算法步骤(比id3多两步)
- 计算类别信息熵
- 计算每个属性的信息熵
- 计算信息增益
- 计算属性信息分裂度量
- 计算信息增益率
C4.5优点与缺点:
优点:产生的分类规则易于理解,准确率较高。
缺点:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
C4.5例子
1 计算类别信息熵

类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越大,不确定性就越大,把事情搞清楚所需要的信息量就越多。
![]()
2. 计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示这个属性中拥有的样本类别越不“纯”。

3. 计算信息增益
信息增益的 = 熵 - 条件熵,在这里就是 类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果一个属性的信息增益越大,就表示用这个属性进行样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类目标。

信息增益就是ID3算法的特征选择指标。
但是我们假设这样的情况,每个属性中每种类别都只有一个样本,那这样属性信息熵就等于零,根据信息增益就无法选择出有效分类特征。所以,C4.5选择使用信息增益率对ID3进行改进。
4.计算属性分裂信息度量
用分裂信息度量来考虑某种属性进行分裂时分支的数量信息和尺寸信息,我们把这些信息称为属性的内在信息(instrisic information)。信息增益率用信息增益 / 内在信息,会导致属性的重要性随着内在信息的增大而减小(也就是说,如果这个属性本身不确定性就很大,那我就越不倾向于选取它),这样算是对单纯用信息增益有所补偿。

5. 计算信息增益率

天气的信息增益率最高,选择天气为分裂属性。发现分裂了之后,天气是“阴”的条件下,类别是”纯“的,所以把它定义为叶子节点,选择不“纯”的结点继续分裂。
在子结点当中重复过程1~5。
至此,这个数据集上C4.5的计算过程就算完成了,一棵树也构建出来了。
(3)贝叶斯分类算法思想、步骤、优缺点
公式:

步骤:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集
2、统计得到在各类别下各个特征属性的条件概率估计。即
![]()
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
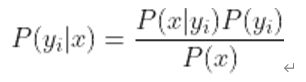
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:

优点:接受大量数据训练和查询时所具备的高速度,支持增量式训练;对分类器实际学习的解释相对简单
缺点:无法处理基于特征组合所产生的变化结果
例子:
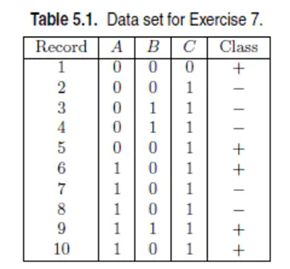
(1)估计条件概率P(A|+),P(B|+),P(C|+),P(A|-),P(B|-),P(C|-)。
P(A=1|+)=P(A=1,+)/P(+)=0.3/0.5=0.6
P(A = 1|−) = 2/5 = 0.4, P(B = 1|−) = 2/5 = 0.4,
P(C = 1|−) = 1, P(A = 0|−) = 3/5 = 0.6,
P(B = 0|−) = 3/5 = 0.6, P(C = 0|−) = 0;
P(B = 1|+) = 1/5 = 0.2, P(C = 1|+) = 2/5 = 0.4,
P(A = 0|+) = 2/5 = 0.4, P(B = 0|+) = 4/5 = 0.8,
P(C = 0|+) = 3/5 = 0.6.
(2)根据(1)中条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号。
设P(A=0,B=1,C=0)=K
P(+|A=0,B=1,C=0)=P(A=0,B=1,C=0,+)/P(A=0,B=1,C=0)
=P(A=0,B=1,C=0|+)P(+)/K
=P(A=0|+)P(B=1|+)P(C=0|+)P(+)/K
=0.4*0.2*0.6*0.5/K=0.024/K
P(-|A=0,B=1,C=0|)=P(A=0,B=1,C=0|-)P(-)/K
=0
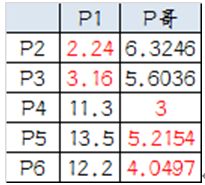
由于P(-|A=0,B=1,C=0) (3)使用m估计方法(p=1/2且m=4)估计条件概率。 P(A=1|+)=(3+4*1/2)/(5+4)=5/9 P(A = 0|+) = (2 + 2)/(5 + 4) = 4/9, P(A = 0|−) = (3+2)/(5 + 4) = 5/9, P(B = 1|+) = (1 + 2)/(5 + 4) = 3/9, P(B = 1|−) = (2+2)/(5 + 4) = 4/9, P(C = 0|+) = (3 + 2)/(5 + 4) = 5/9, P(C = 0|−) = (0+2)/(5 + 4) = 2/9. (4)同(b),使用(c)中条件概率。 Let P(A = 0,B = 1, C = 0) = K P(+|A = 0,B = 1, C = 0) = P(A = 0,B = 1, C = 0|+) × P(+)/P(A = 0,B = 1, C = 0) =P(A = 0|+)P(B = 1|+)P(C = 0|+) × P(+)/K =(4/9) × (3/9) × (5/9) × 0.5/K = 0.0412/K P(−|A = 0,B = 1, C = 0)= 0.0274/K 类标号是+ (5)比较两种方法,哪种好? 当其中一个条件概率为零时,使用m-估计概率方法对条件概率的估计更好,因为我们不希望整个表达式变成零。 自己看书,或者上网查资料 聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。 聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很 3.重新计算已经得到的各个类的质心。 4.迭代二、三步直至新的质心与原质心相等或小于指定阈值,算法结束。 优点:(1)KMeans算法擅长处理球状分布的数据 缺点:(1)k的取值需要根据经验,没有可借鉴性 我搞了6个点,从图上看应该分成两推儿,前三个点一堆儿,后三个点是另一堆儿。 现在手工执行K-Means,体会一下过程,同时看看结果是不是和预期一致。 1.选择初始大哥: 我们就选P1和P2 2.计算小弟和大哥的距离: P3到P1的距离从图上也能看出来(勾股定理),是√10 = 3.16;P3到P2的距离√((3-1)^2+(1-2)^2 = √5 = 2.24,所以P3离P2更近,P3就跟P2混。同理,P4、P5、P6也这么算,如下: P3到P6都跟P2更近,所以第一次站队的结果是: 组A:P1 组B:P2、P3、P4、P5、P6 3.人民代表大会: 组A没啥可选的,大哥还是P1自己 组B有五个人,需要选新大哥,这里要注意选大哥的方法是每个人X坐标的平均值和Y坐标的平均值组成的新的点,为新大哥,也就是说这个大哥是“虚拟的”。 因此,B组选出新大哥的坐标为:P哥((1+3+8+9+10)/5,(2+1+8+10+7)/5)=(6.2,5.6)。 综合两组,新大哥为P1(0,0),P哥(6.2,5.6),而P2-P6重新成为小弟 4.再次计算小弟到大哥的距离: 这时可以看到P2、P3离P1更近,P4、P5、P6离P哥更近,所以第二次站队的结果是: 组A:P1、P2、P3 组B:P4、P5、P6(虚拟大哥这时候消失) 5.第二届人民代表大会: 按照上一届大会的方法选出两个新的虚拟大哥:P哥1(1.33,1) P哥2(9,8.33),P1-P6都成为小弟 6.第三次计算小弟到大哥的距离: 这时可以看到P1、P2、P3离P哥1更近,P4、P5、P6离P哥2更近,所以第二次站队的结果是: 组A:P1、P2、P3 组B:P4、P5、P6 我们发现,这次站队的结果和上次没有任何变化了,说明已经收敛,聚类结束,聚类结果和我们最开始设想的结果完全一致。 K-中心点算法也是一种常用的聚类算法,K-中心点聚类的基本思想和K-Means的思想相同,实质上是对K-means算法的优化和改进。在K-means中,异常数据对其的算法过程会有较大的影响。在K-means算法执行过程中,可以通过随机的方式选择初始质心,也只有初始时通过随机方式产生的质心才是实际需要聚簇集合的中心点,而后面通过不断迭代产生的新的质心很可能并不是在聚簇中的点。如果某些异常点距离质心相对较大时,很可能导致重新计算得到的质心偏离了聚簇的真实中心。 算法步骤: (1)确定聚类的个数K。 (2)在所有数据集合中选择K个点作为各个聚簇的中心点。 (3)计算其余所有点到K个中心点的距离,并把每个点到K个中心点最短的聚簇作为自己所属的聚簇。 (4)在每个聚簇中按照顺序依次选取点,计算该点到当前聚簇中所有点距离之和,最终距离之后最小的点,则视为新的中心点。 (5)重复(2),(3)步骤,直到各个聚簇的中心点不再改变。 如果以样本数据{A,B,C,D,E,F}为例,期望聚类的K值为2,则步骤如下: (1)在样本数据中随机选择B、E作为中心点。 (2)如果通过计算得到D,F到B的距离最近,A,C到E的距离最近,则B,D,F为聚簇C1,A,C,E为聚簇C2。 (3)在C1和C2两个聚类集合中,计算一个点到其他店的距离之和的最小值作为新的中心点,假如分别计算出D到C1中其他所有点的距离之和最小,E到C2中其他所有点的距离之和最小。 (4)再以D,E作为聚簇的中心点,重复上述步骤,知道中心点不再改变。 优缺点: K-中心聚类算法计算的是某点到其它所有点的距离之后最小的点,通过距离之和最短的计算方式可以减少某些孤立数据对聚类过程的影响。从而使得最终效果更接近真实划分,但是由于上述过程的计算量会相对杜宇K-means,大约增加O(n)的计算量,因此一般情况下K-中心算法更加适合小规模数据运算。 层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。层次聚类算法相比划分聚类算法的优点之一是可以在不同的尺度上(层次)展示数据集的聚类情况。 根据创建聚类树有的两种方式:自下而上合并和自上而下。基于层次的聚类算法可以分为:凝聚的(Agglomerative)或者分裂的(Divisive)。 自下而上法就是一开始每个个体(object)都是一个类,然后根据linkage寻找同类,最后形成一个“类”。 自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。 这两种路方法没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类”的方法就是最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。为弥补分解与合并的不足,层次合并经常要与其它聚类方法相结合,如循环定位。 层次聚类方法中比较新的算法有BIRCH(Balanced Iterative Reducingand Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化;ROCK(A Hierarchical ClusteringAlgorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering AlgorithmUsing Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。 二、自底向上的层次算法 层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树。 绝大多数层次聚类属于凝聚型层次聚类, 它的算法流程如下: (1) 将每个对象看作一类,计算两两之间的距离; (2) 将距离最小的两个类合并成一个新类; (3) 重新计算新类与所有类之间的距离; (4) 重复(2)、(3),直到所有类最后合并成一类。 整个过程就是建立一棵树,在建立的过程中,可以在步骤四设置所需分类的类别个数,作为迭代的终止条件,毕竟都归为一类并不实际。 (1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类; (2)与K-MEANS比较起来,不需要输入要划分的聚类个数; (3)聚类簇的形状没有偏倚; (4)可以在需要时输入过滤噪声的参数。 (1)当数据量增大时,要求较大的内存支持I/O消耗也很大; (2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难。 (3)算法聚类效果依赖与距离公式选取,实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
(4)神经网络分类算法思想、步骤,优缺点
(5)过拟合、欠拟合问题,十折交叉
第五章
(1)聚类分析概念
(2)划分方法(K-means、K-medoide中心算法)算法思想、步骤、优缺点
(1)K值均步骤:
(2)例题:

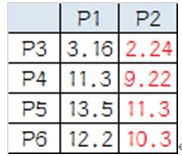

(2)K中心点算法:


(3)层次方法算法思想、步骤、优缺点
(4)基于密度的方法 DBSCAN算法思想、步骤、优缺点
优点:
缺点: