DEEPXDE
论文信息
题目:DEEPXDE: A DEEP LEARNING LIBRARY FOR SOL VING DIFFERENTIAL EQUATIONS
作者:LU LU, XUHUI MENG, ZHIPING MAO, AND GEORGE EM KARNIADAKIS
期刊会议: Computational Physics,Machine Learning
年份:19
论文地址:代码:
基础补充
内容
动机
动机:
- 近年来在深度学习在计算机视觉,自然语言等方面得到了广泛应用,尽管在这些和相关领域取得了显著的成功,但深度学习还没有广泛应用于科学计算领域;
- 然而,最近,通过深度学习求解偏微分方程(PDEs),如标准微分形式或积分形式,已经成为科学机器学习下一个潜在的新的子领域;
- 特别的,用一种近似于PDE解的神经网络来代替传统的数值离散方法
问题定义:求解微分方程
f ( x ; ∂ u ∂ x 1 , … , ∂ u ∂ x d ; ∂ 2 u ∂ x 1 ∂ x 1 , … , ∂ 2 u ∂ x 1 ∂ x d ; … ; λ ) = 0 , x ∈ Ω f\left(\mathbf{x} ; \frac{\partial u}{\partial x_{1}}, \ldots, \frac{\partial u}{\partial x_{d}} ; \frac{\partial^{2} u}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} u}{\partial x_{1} \partial x_{d}} ; \ldots ; \lambda\right)=0, \quad \mathbf{x} \in \Omega f(x;∂x1∂u,…,∂xd∂u;∂x1∂x1∂2u,…,∂x1∂xd∂2u;…;λ)=0,x∈Ω
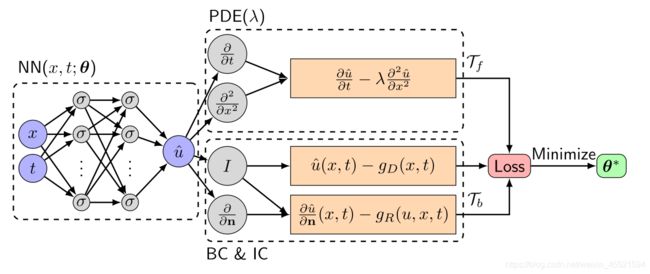
PINN
PPINN求解: L ( θ ; T ) = w f L f ( θ ; T f ) + w b L b ( θ ; T b ) \mathcal{L}(\boldsymbol{\theta} ; \mathcal{T})=w_{f} \mathcal{L}_{f}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right)+w_{b} \mathcal{L}_{b}\left(\boldsymbol{\theta} ; \mathcal{T}_{b}\right) L(θ;T)=wfLf(θ;Tf)+wbLb(θ;Tb)其中: L f ( θ ; T f ) = 1 ∣ T f ∣ ∑ x ∈ T f ∥ f ( x ; ∂ u ^ ∂ x 1 , … , ∂ u ^ ∂ x d ; ∂ 2 u ^ ∂ x 1 ∂ x 1 , … , ∂ 2 u ^ ∂ x 1 ∂ x d ; … ; λ ) ∥ 2 2 L b ( θ ; T b ) = 1 ∣ T b ∣ ∑ x ∈ T b ∥ B ( u ^ , x ) ∥ 2 2 \begin{aligned} \mathcal{L}_{f}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right) &=\frac{1}{\left|\mathcal{T}_{f}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{f}}\left\|f\left(\mathbf{x} ; \frac{\partial \hat{u}}{\partial x_{1}}, \ldots, \frac{\partial \hat{u}}{\partial x_{d}} ; \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{d}} ; \ldots ; \boldsymbol{\lambda}\right)\right\|_{2}^{2} \\ \mathcal{L}_{b}\left(\boldsymbol{\theta} ; \mathcal{T}_{b}\right) &=\frac{1}{\left|\mathcal{T}_{b}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{b}}\|\mathcal{B}(\hat{u}, \mathbf{x})\|_{2}^{2} \end{aligned} Lf(θ;Tf)Lb(θ;Tb)=∣Tf∣1x∈Tf∑∥∥∥∥f(x;∂x1∂u^,…,∂xd∂u^;∂x1∂x1∂2u^,…,∂x1∂xd∂2u^;…;λ)∥∥∥∥22=∣Tb∣1x∈Tb∑∥B(u^,x)∥22
其中 L \mathcal{L} L为residual points,选择的策略可以为- 我们可以在训练开始时指定residual points,可以是格点上的网格点,也可以是随机点,训练过程中不改变它们;
- 在每次优化迭代中,我们可以随机选择不同的residual points;
- 我们可以在训练过程中自适应地改善residual points的位置(Residual-based adaptive refinement (RAR))。

特别注意:
- 因为L-BFGS使用损失函数的二阶导数,而Adam只依赖于一阶导数,所以L-BFGS可以找到比Adam迭代次数少的较好的解,但是对于 stiff solutions,L-BFGS更有可能被卡在一个糟糕的局部最小值上;
- 当residual points数目很大时,每一次迭代计算损失函数和梯度花费很大,可以考虑不使用所有residual points,把这些residual points分成一小批一小批,每次迭代只用一批,这种方法称为小批量梯度下降
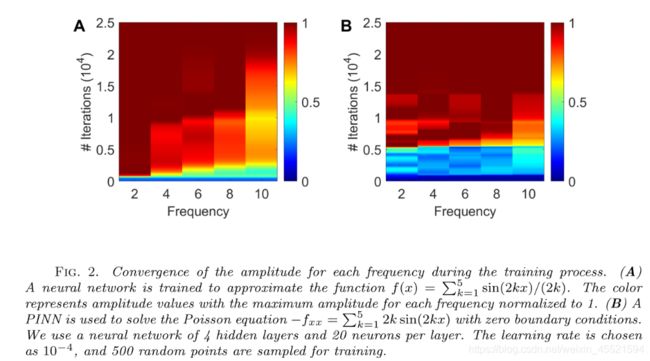
PINN与NN对比目标: f ( x ) = ∑ k = 1 5 sin ( 2 k x ) / ( 2 k ) in [ − π , π ] f(x)=\sum_{k=1}^{5} \sin (2 k x) /(2 k) \text { in }[-\pi, \pi] f(x)=k=1∑5sin(2kx)/(2k) in [−π,π]函数逼近:神经网络(NN)是低地频到高频学习目标函数的,但是PINNs的学习方式是所有频同时学习证明:使用PINN求解PDE比使用NN逼近函数要快
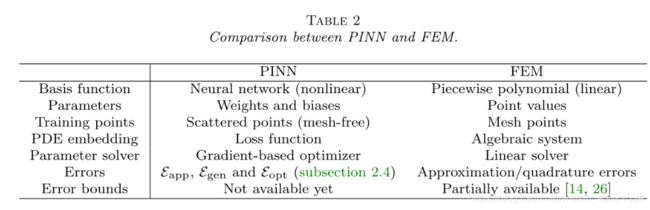
PINN与FEM比较
PINN逼近理论
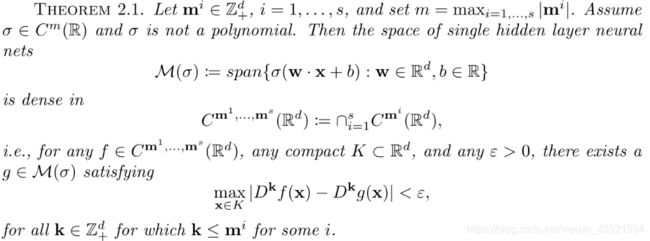
说明:定理主要表明,具有足够神经元的前馈神经网络可以同时一致地逼近任意函数及其偏导数,就是存在可以求解PDE的神经网络
PINN误差分析
E : = ∥ u ~ T − u ∥ ≤ ∥ u ~ T − u T ∥ ⏟ E o p t + ∥ u T − u F ∥ ⏟ E g e n + ∥ u F − u ∥ ⏟ E a p p \mathcal{E}:=\left\|\tilde{u}_{\mathcal{T}}-u\right\| \leq \underbrace{\left\|\tilde{u}_{\mathcal{T}}-u_{\mathcal{T}}\right\|}_{\mathcal{E}_{\mathrm{opt}}}+\underbrace{\left\|u_{\mathcal{T}}-u_{\mathcal{F}}\right\|}_{\mathcal{E}_{\mathrm{gen}}}+\underbrace{\left\|u_{\mathcal{F}}-u\right\|}_{\mathcal{E}_{\mathrm{app}}} E:=∥u~T−u∥≤Eopt ∥u~T−uT∥+Egen ∥uT−uF∥+Eapp ∥uF−u∥
其中: F \mathcal{F} F表示可以由我们选择的神经网络结构表示的所有函数的族
u u u是PDE的解
u F u_{\mathcal{F}} uF是 F \mathcal{F} F中最接近 u u u的函数
u T u_{\mathcal{T}} uT,因为训练是在 T \mathcal{T} T上
u ~ T \tilde{u}_{\mathcal{T}} u~T,优化器中求出的逼近解
u F − u u_{\mathcal{F}}-u uF−u是逼近误差
u T − u F u_{\mathcal{T}}-u_{\mathcal{F}} uT−uF是泛化误差
u ~ T − u T \tilde{u}_{\mathcal{T}}-u_{\mathcal{T}} u~T−uT是优化误差

PINN求解积分微分方程利用经典方法估计积分例如 Gaussian quadrature等方法,就在PINN中加入了一个新的discretization error E d i s \mathcal{E}_{dis} Edis例如使用Gaussian quadratur方法: d y d x + y ( x ) = ∫ 0 x e t − x y ( t ) d t \frac{d y}{d x}+y(x)=\int_{0}^{x} e^{t-x} y(t) d t dxdy+y(x)=∫0xet−xy(t)dt变换 ∫ 0 x e t − x y ( t ) d t ≈ ∑ i = 1 n w i e t i ( x ) − x y ( t i ( x ) ) \int_{0}^{x} e^{t-x} y(t) d t \approx \sum_{i=1}^{n} w_{i} e^{t_{i}(x)-x} y\left(t_{i}(x)\right) ∫0xet−xy(t)dt≈i=1∑nwieti(x)−xy(ti(x))得到: d y d x + y ( x ) ≈ ∑ i = 1 n w i e t i ( x ) − x y ( t i ( x ) ) \frac{d y}{d x}+y(x) \approx \sum_{i=1}^{n} w_{i} e^{t_{i}(x)-x} y\left(t_{i}(x)\right) dxdy+y(x)≈i=1∑nwieti(x)−xy(ti(x))
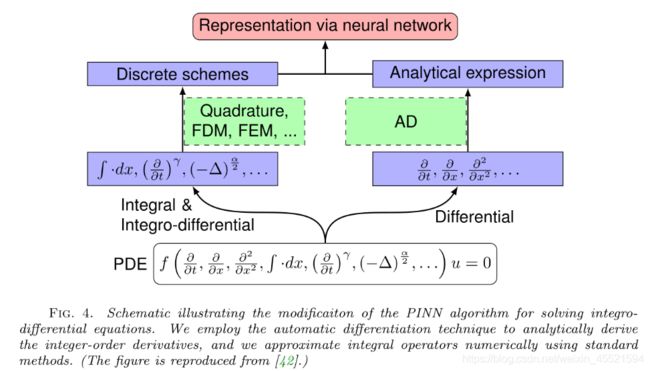
PINNs求解逆问题相比于forward增加了 L ( θ , λ ; T ) = w f L f ( θ , λ ; T f ) + w b L b ( θ , λ ; T b ) + w i L i ( θ , λ ; T i ) \mathcal{L}(\boldsymbol{\theta}, \boldsymbol{\lambda} ; \mathcal{T})=w_{f} \mathcal{L}_{f}\left(\boldsymbol{\theta}, \boldsymbol{\lambda} ; \mathcal{T}_{f}\right)+w_{b} \mathcal{L}_{b}\left(\boldsymbol{\theta}, \boldsymbol{\lambda} ; \mathcal{T}_{b}\right)+w_{i} \mathcal{L}_{i}\left(\boldsymbol{\theta}, \boldsymbol{\lambda} ; \mathcal{T}_{i}\right) L(θ,λ;T)=wfLf(θ,λ;Tf)+wbLb(θ,λ;Tb)+wiLi(θ,λ;Ti)其中: L i ( θ , λ ; T i ) = 1 ∣ T i ∣ ∑ x ∈ T i ∥ I ( u ^ , x ) ∥ 2 2 \mathcal{L}_{i}\left(\boldsymbol{\theta}, \boldsymbol{\lambda} ; \mathcal{T}_{i}\right)=\frac{1}{\left|\mathcal{T}_{i}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{i}}\|\mathcal{I}(\hat{u}, \mathbf{x})\|_{2}^{2} Li(θ,λ;Ti)=∣Ti∣1x∈Ti∑∥I(u^,x)∥22
RAR(Residual-based adaptive refinement 基于残差的自适应细化)
问题:residual points通常是在域里面随机选择的,在大多数情况下都能表现得很好,但是,对于某些具有陡峭(steep)梯度的解的偏微分方程,它可能不是有效的,为了设计好residual point的分布,提出了RAR。

使用:

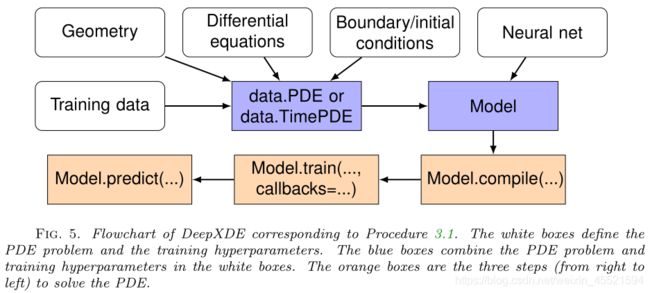
创新:提出RAR方法能够加速训练效率
实验
实验1:
− Δ u ( x , y ) = 1 , ( x , y ) ∈ Ω u ( x , y ) = 0 , ( x , y ) ∈ ∂ Ω \begin{aligned} -\Delta u(x, y) &=1, \quad(x, y) \in \Omega \\ u(x, y) &=0, \quad(x, y) \in \partial \Omega \end{aligned} −Δu(x,y)u(x,y)=1,(x,y)∈Ω=0,(x,y)∈∂Ω

实验2:
∂ u ∂ t + u ∂ u ∂ x = ν ∂ 2 u ∂ x 2 , x ∈ [ − 1 , 1 ] , t ∈ [ 0 , 1 ] u ( x , 0 ) = − sin ( π x ) , u ( − 1 , t ) = u ( 1 , t ) = 0 \begin{array}{ll} \frac{\partial u}{\partial t}+u \frac{\partial u}{\partial x}=\nu \frac{\partial^{2} u}{\partial x^{2}}, & x \in[-1,1], t \in[0,1] \\ u(x, 0)=-\sin (\pi x), & u(-1, t)=u(1, t)=0 \end{array} ∂t∂u+u∂x∂u=ν∂x2∂2u,u(x,0)=−sin(πx),x∈[−1,1],t∈[0,1]u(−1,t)=u(1,t)=0
采用PINN和PINN(RAR)方法训练数据2540 个样本
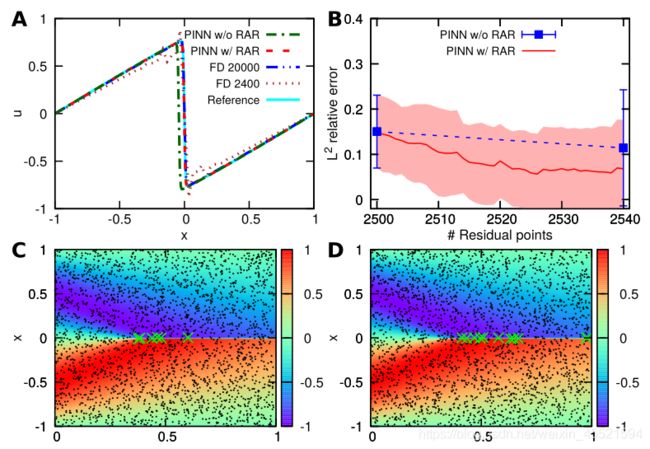
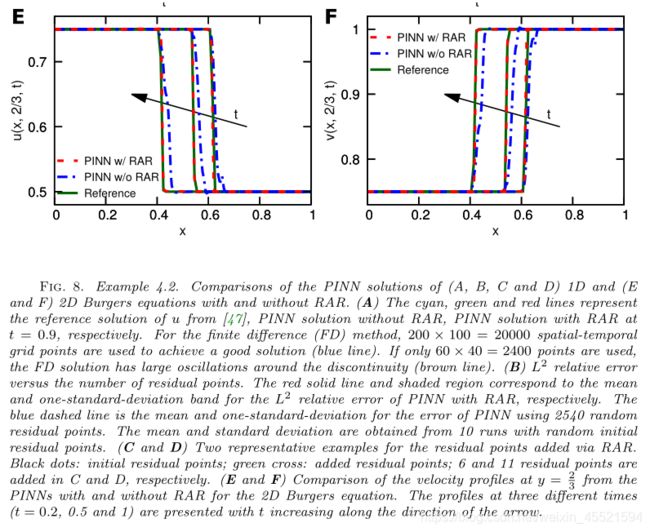
结论:- A和B看出相比于有限差分方法同样的数据点结果更好- 在C和D中可以看到,新加的点都在 sharp 接口
实验3:逆问题:
d x d t = ρ ( y − x ) , d y d t = x ( σ − z ) − y , d z d t = x y − β z \frac{d x}{d t}=\rho(y-x), \quad \frac{d y}{d t}=x(\sigma-z)-y, \quad \frac{d z}{d t}=x y-\beta z dtdx=ρ(y−x),dtdy=x(σ−z)−y,dtdz=xy−βz
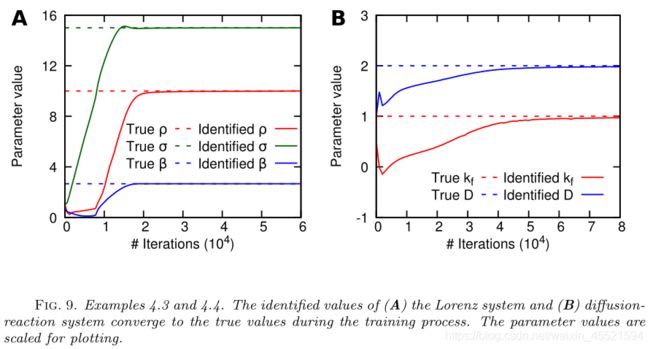
结论
介绍求解不同类型偏微分方程的物理神经网络(PINNs)的算法、近似理论和误差分析。与传统的数值方法相比,PINN采用了自动微分来处理微分算子而且是无网格的,提出一种基于残差的自适应细化(RAR)方法来改善训练过程中残差点的分布,从而提高训练效率
不懂
- 定理2.1实际证明过程不太清楚
可借鉴地方
- 提出RAR的方法提供训练效率,对于一些steep梯度的微分方程很适用