Reinforcement learning-强化学习基础
1. 基本定义
RL与有监督学习、无监督学习的比较:
(1)有监督的学习是从一个已经标记的训练集中进行学习,训练集中每一个样本的特征可以视为是对该situation的描述,而其label可以视为是应该执行的正确的action,但是有监督的学习不能学习交互的情景,因为在交互的问题中获得期望行为的样例是非常不实际的,agent只能从自己的经历(experience)中进行学习,而experience中采取的行为并一定是最优的。这时利用RL就非常合适,因为RL不是利用正确的行为来指导,而是利用已有的训练信息来对行为进行评价。
(2)因为RL利用的并不是采取正确行动的experience,从这一点来看和无监督的学习确实有点像,但是还是不一样的,无监督的学习的目的可以说是从一堆未标记样本中发现隐藏的结构,而RL的目的是最大化reward signal。
(3)总的来说,RL与其他机器学习算法不同的地方在于:其中没有监督者,只有一个reward信号;反馈是延迟的,不是立即生成的;时间在RL中具有重要的意义;agent的行为会影响之后一系列的data。
强化学习的关键要素有:environment,reward,action 和 state。有了这些要素我们就能建立一个强化学习模型。
强化学习解决的问题是,针对一个具体问题得到一个最优的policy,使得在该策略下获得的reward最大。所谓的policy其实就是一系列action,也就是sequential data。
强化学习可用下图来刻画,都是要先从要完成的任务提取一个环境,从中抽象出状态(state) 、动作(action)、以及执行该动作所接受的瞬时奖赏(reward)。
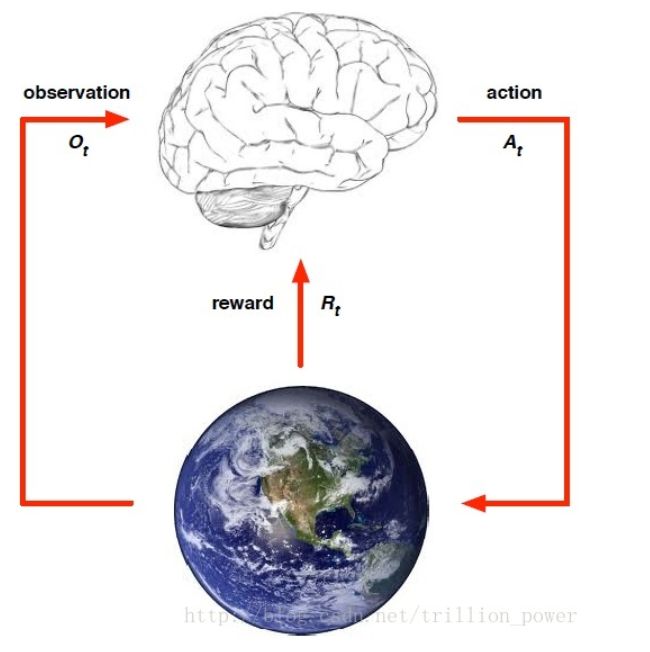
- reward
reward通常都被记作,表示第t个time step的返回奖赏值。所有强化学习都是基于reward假设的,reward是一个scalar。 - action
action是来自于动作空间,agent对每次所处的state用以及上一状态的reward确定当前要执行什么action。执行action要达到最大化期望reward,直到最终算法收敛,所得的policy就是一系列action的sequential data。 - state
就是指当前agent所处的状态 - policy
policy就是只agent的行为,是从state到action的映射,分为确定策略和与随机策略,确定策略就是某一状态下的确定动作, 随机策略以概率来描述,即某一状态下执行这一动作的概率。
- value function
因为强化学习今本上可以总结为通过最大化reward来得到一个最优策略。但是如果只是瞬时reward最大会导致每次都只会从动作空间选择reward最大的那个动作,这样就变成了最简单的贪心策略(Greedy policy),所以为了很好地刻画是包括未来的当前reward值最大(即使从当前时刻开始一直到状态达到目标的总reward最大)。因此就构造了值函数(value function)来描述这一变量。表达式如下
KaTeX parse error: {equation} can be used only in display mode.
是折扣系数,就是为了减少未来的reward对当前动作的影响,然后就通过选取合适的policy使value function最大。著名的bellman方程是强化学习各大算法(e.g. 值迭代,策略迭代,Q-learning)的源头。
- model
model就是用来预测环境接下来会干什么,即在这一状态的情况下执行某一动作会达到什么样的状态,这一个动作会得到什么reward。所以描述一个模型就是用动作转移概率与动作状态reward。具体公式如下:
在强化学习中,智能体(agent)被置于某一环境(environment)中。对应围棋的例子,棋手是agent,环境是棋盘。在任何时候,环境总是处于某种状态(state),该状态来自一组可能的状态之一,对于围棋,状态指的是棋盘的布局状态。决策者可以做一组可能的动作(棋子的合法移动)。一旦选择并做了某一动作,状态就随之改变。问题的解决需要执行一系列的动作,之后才得到反馈,反馈以极少发生的奖励(reward)的形式给出,通常只有在完整的动作序列执行完毕才发生。
2. Finite Markov Decision Processes
MDPs 简单说就是一个智能体(Agent)采取行动(Action),从而改变自己的状态(State)获得奖励(Reward),与环境(Environment)发生交互的循环过程。
MDP 的策略完全取决于当前状态(Only present matters),这也是马尔可夫性质的体现。
2.1. The Agent–Environment Interface
强化学习问题是一个从交互中学习,以达到预期目标的简单框架。学习者和决策者被称为agent,与agent相交互的称为环境environment。交互不断进行着,agent选择执行的动作(action),环境对agent执行的动作作出反应,使得agent处于另一个新的环境中。同时,环境也会产生回报,agent试图在一段时间内最大化这些回报。
在时刻,agent观测到环境信息,其中是所有可能状态的集合。在该环境下,agent选择一个action ,表示在状态下所有可以执行动作的集合。在下一个时刻,由于action的作用,agent获得一个数值奖励,同时,agent处于一个新的状态。下图展示了agent和environment的交互过程。
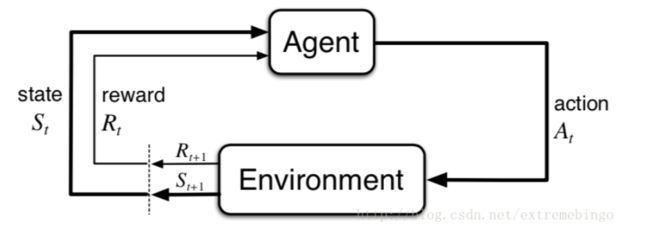
在MDP和agent的共同作用下,产生了一个序列,也被称为轨迹
KaTeX parse error: {equation} can be used only in display mode.
在时刻,给定状态和动作,则时刻的状态和奖励出现的概率为
KaTeX parse error: {equation} can be used only in display mode.
状态转移概率为
KaTeX parse error: {equation} can be used only in display mode.
state–action的期望奖励为
KaTeX parse error: {equation} can be used only in display mode.
state-action-next_state元组的期望值
KaTeX parse error: {equation} can be used only in display mode.
例子:
回收机器人,用于在办公室收集汽水罐,它运行在可充电的电池上,并且包含探测罐子的传感器和捡起并收集罐子的夹子。如何搜寻罐子的策略是由强化学习的agent基于当前的电量做出的。agent可以让机器人做以下几件事
- (1)积极搜寻一段时间;
- (2)等待一段时间,等待有人把罐子拿过来;
- (3)回去充电。因此,agent有三种action。状态由电池的状态决定。当机器人拿到罐子,则获得正的奖励,当电池用完时,获得一个大的负的奖励。假设状态的变化规律为:最好的拿到罐子的方式是主动搜寻,但是这会消耗电量,但是原地等待不会消耗电量。当是低电量的时候,执行搜索可能会耗尽电池,这种情况下,机器人必须关闭电源,等待救援。
agent执行动作仅仅依赖于电量,因此,状态集为,agent的动作有wait, serach, recharge。因此,agent的动作集合为:如果电量是高的,则一次搜索一般不会耗尽电池,搜索完成后还是高电量的概率为 α \alpha α,是低电量的概率为 1 − α 1-\alpha 1−α。当电池处于低电量时,执行一次搜索后还是低电量的概率为 1 − β 1-\beta 1−β,耗尽电池的概率为 β \beta β,然后需要对机器人进行充电,所以状态将转化为high。每次主动搜索会得到奖励,等待则会获得奖励, r w a i t r_{wait} rwait。当机器人需要救援的时候,则奖励为, r s e a r c h r_{search} rsearch。
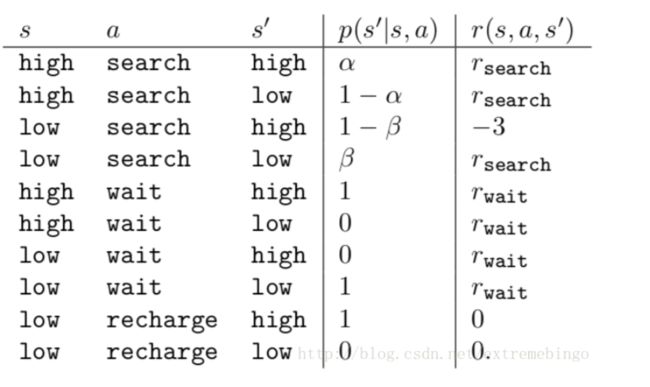
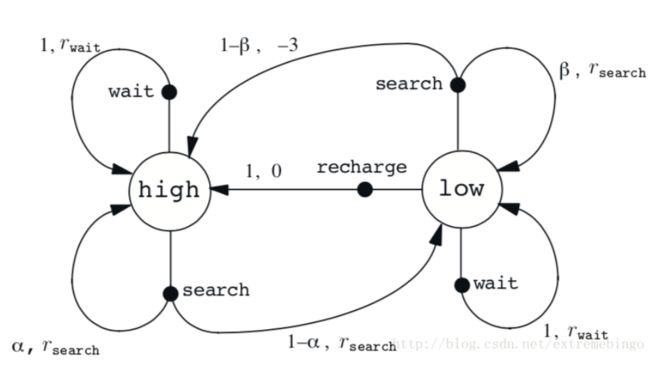
2.2. Goals and Rewards
在强化学习中,agent的目标是获得由环境传给它的奖励reward。在每一时刻,奖励reward是一个具体的数值,agent的目标是最大化它获得的奖励的期望。这意味着不是最大化即时奖励,而是最大化一段时间内的累积奖励。
2.3. Returns and Episodes
2.2 描述了强化学习的目标,下面用数学的形式来表示。在时刻之后,获得的奖励序列为 G t G_{t} Gt。通常情况下,我们寻找期望回报的最大值。可以将回报看成是奖励序列的函数,回报最简单的形式是直接将奖励相加
G t ≐ R t + 1 + R t + 2 + R t + 3 + ⋯ + R T G_{t} \doteq R_{t+1}+R_{t+2}+R_{t+3}+\cdots+R_{T} Gt≐Rt+1+Rt+2+Rt+3+⋯+RT
其中, T T T为最终停止的时刻。特别地,我们将一次有限步数的实验称作一个单独的episodes,也就是经过有限步数后最终会进入一个终止状态,这一类的任务也叫做episodic tasks,如打游戏。
有些情况下,agent和environment之间的交互将不会停止,这一类的任务叫做continuing tasks,如control task。此时,这种情况下,回报有可能趋向于无穷大。如在每一步,agent获得的奖励都是+1。
此时,出现了 折扣 这一概念。agent选择一系列的动作使未来获得的折扣奖励之和最大。即,选择,最大化折扣回报的期望
G t ≐ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_{t} \doteq R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\cdots=\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} Gt≐Rt+1+γRt+2+γ2Rt+3+⋯=∑k=0∞γkRt+k+1
2.4.Policies and Value Functions
几乎所有的强化学习都要计算价值函数——关于状态的函数或关于状态-动作的函数,来估算agent在某个状态(或者在某个状态下执行某个动作)的价值,即未来的奖励。显然,未来的奖励依赖于执行的动作,因此,value functions是针对特定的策略定义的,同一个强化学习问题,不能的策略,会有不同的价值函数
用途:强化学习做解动态规划,极限学习机的理论(选测点调研),强化学习作为特征选择方法。