【飞桨PaddleSpeech语音技术课程】— 语音识别-定制化识别
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
定制化语音识别
1. 背景
在一些特定场景下,要求ASR系统对某些固定句式的关键词准确识别。
- 打车报销单场景,要求日期,时间,地点,金额精准识别。
- 定制化的唤醒词以及命令词,如在车机放音乐场景,那么只需要高精度的识别下一首,上一首,音量调大,音量调小等命令词。
- 还有语音助手打电话的场景,需要根据用户通讯录,完成联系人的识别等等。
为满足此种需求,本文展示一种定制化识别的方案。
第二节介绍相关的基础知识。
第三节已一个 Demo 展示如何实际操作。
PaddleSpeech SpeechX 已上线更详细的操作脚本和教程,欢迎大家关注。

来自电影《钢铁侠》
2. WFST 解码器相关概念:
2.1 WFST 介绍
WFST是加权有限状态机(weighted finite-state transducers)的简称【2】。在语音识别中,基于 WFST 生成的解码图,配合声学模型进行 viterbi 解码是语音识别中一种基础的解码方法。
这种有限状态机有一个有限的状态集合以及状态之间的跳转,其中每个跳转至少有一个标签。
如果存在一条从初始状态到终止状态的路径,使得路径上的标签序列正好等于输入符号序列,那么则输出一个新的序列和权值。
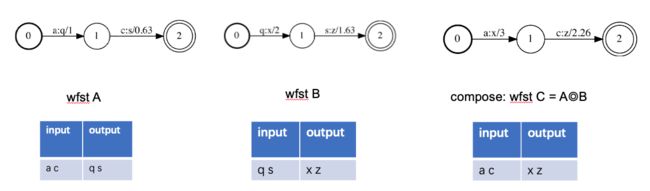
如下图WFST,输入’ac’串,匹配到0-1,1-2这个路径,输出’qs’, 权重1.63。

OpenFST【1】实现了 WFST【2】的相关算法,后续的算法解释以及解码图的构建与操作,都是基于 OpenFST 来完成。
相关 OpenFST 以及 WFST 的介绍可以参考如下链接:
openfst官方教程
2.2 WFST Compose 概念
下图中WFST C是有WFST A,B Compose而成,可以看做为A,B的级联,A的输出是B的输出,所以组成C后,C的输入为A的输入,B的输出为C的输出。
2.3 WFST Decoder TLG 解码图
PaddleSpeech SpeechX 中 WFST 的解码图是由T,L,G构成,用于kaldi中的解码图是由HCLG构成。下面以TLG为例说明解码构图。
| 缩写 | 名称 | 输入序列 | 输出序列 |
|---|---|---|---|
| T | Token | 建模单元 | 字 |
| L | Lexicon | 字 | 词 |
| G | Grammar | 词 | 词 |
其中 T 可以是音素,也可以是字符,PaddleSpeech Speechx中建模使用的是字符。 下面以提出TLG的论文【3】中的实例来说明构图。
- T 是以音素来构图的,IH 为【3】中声学模型神经网络的建模单元英文音素。下图就是 ‘is’ 中 /i/ 的发音表示。

T 的构图
- L 是发音词典,下图为‘is’的发音/iz/的表示。

L 的构图
- 论文【3】中简单的语言模型的构图如下。用于识别how are you,how is it。
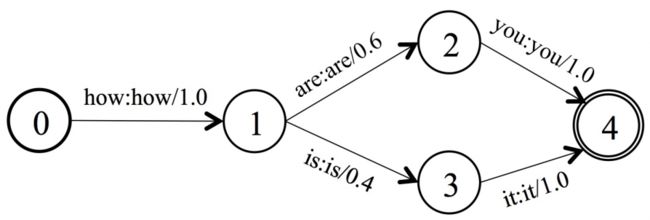
G 的构图
通过TLG的Compose,把声学建模单元,词典,语言模型糅合在一起,产生一个静态的解码网络。在解码过程中采用搜索策略,得到输入语音的最优解码结果。
2.4 WFST Replace 概念
- 下图是带slot的G,表示的识别语句是打车到xxx。

- 下图为地址的Slot WFST,可以定制添加所需识别的地点。

- 下图为slot WFST替换到G中的address slot后的WFST(使用 fstreplace 操作)。

画图以及操作脚本见 draw_address_g_slot.sh 可以在终端中执行。(需要安装dot,画出图保存为pdf.)
Openfst replace操作 官方教程
3 打车报销单场景介绍
本节会通过定制地点来说明操作。打车报销单识别场景,一个需要定制化识别的是地点,精细化的地点识别,如在北京,可导入北京的地点包,在上海,可导入上海的地点包,以此来满足一些精细化识别(稀有特有地名)。脚本中会以对”海淀黄庄“的识别来简单示例。
3.1 脚本代码解析
- 编译出一个带slot的G:
cat > $lang/g_with_slot.txt <
4
EOF
fstcompile --isymbols=$lang/words.txt --osymbols=$lang/words.txt \
$lang/g_with_slot.txt $lang/g_with_slot.fst
- 编译出address slot的fst:
cat > $lang/address_slot.txt <- 替换掉G中的address slot。
fstreplace --epsilon_on_replace $lang/g_with_slot.fst $root_label \
$lang/address_slot.fst $address_slot_label $lang/g.fst
- compose T,L,G为TLG成最终的解码图。
fsttablecompose $lang/L.fst $lang/g.fst | fstdeterminizestar --use-log=true | \
fstminimizeencoded | fstarcsort --sort_type=ilabel > $lang/lg.fst || exit 1;
fsttablecompose $lang/T.fst $lang/lg.fst > $lang/tlg.fst || exit 1;
3.2 操作
3.2.1 构图,测试识别
打开终端,执行以下命令:
!test -f model.tar.gz || (wget -nc https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/model.tar.gz && tar xzvf model.tar.gz)
!test -d model || tar xzvf model.tar.gz
!test -f resource.tar.gz || wget -nc https://paddlespeech.bj.bcebos.com/s2t/paddle_asr_online/resource.tar.gz
!test -d resource || tar xzvf resource.tar.gz
! mv resource/* .
!cd ./resource
!bash ./mk_graph.sh
!ls ./graph
!ls ./graph/tlg.fst
# 测试生成解码图:
!bash ./demo_test.sh
会从log中发现:如下识别结果
rec_ais1 打车到家
rec_ais2 打车到机场
rec_ais3 打车到苏州街
所以从wave/class_demo.trans可以看出第一句话识别错误。把’海淀黄庄’识别成了’家’。
3.2.1 修改address slot,构图,测试识别
修改 mk_graph.sh 中 address_slot 部分为:
cat > $lang/address_slot.txt <见脚本 mk_graph2.sh
!bash ./mk_graph2.sh
!ls ./graph/tlg.fst
#然后测试:
!bash ./demo_test.sh
可以发现正确识别了。
rec_ais1 打车到海淀黄庄
rec_ais2 打车到机场
rec_ais3 打车到苏州街
具体脚本已经上传到github speechx的example,可以参见:https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/speechx/examples/custom_asr
4 Reference
【1】https://www.openfst.org/twiki/bin/view/FST/FstQuickTour
【2】Mohri M, Pereira F, Riley M. Speech recognition with weighted finite-state transducers[M]//Springer Handbook of Speech Processing. Springer, Berlin, Heidelberg, 2008: 559-584.
【3】Miao Y, Gowayyed M, Metze F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding[C]//2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015: 167-174.
P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。