文献学习02-Effective Modeling of Encoder-Decoder Architcture for Joint Entity and Relation Extraction
论文信息
(1)题目:Effective Modeling of Encoder-Decoder Architecture for Joint Entity and Relation Extraction (用于联合实体和关系提取的编码器-解码器架构的有效建模)
(2)文章下载地址:https://ojs.aaai.org//index.php/AAAI/article/view/6374
(3)相关代码:https://github.com/nusnlp/PtrNetDecoding4JERE
(4)作者信息:Tapas Nayak, Hwee Tou Ng
Department of Computer Science National University of Singapore
[email protected], [email protected]
目录
Abstract
Introduction
Task Description
Encoder-Decoder Architecture
Embedding Layer & Encoder
Word-level Decoder & Copy Mechanism
Pointer Network-based Decoder
Relation Tuple Extraction
Attention Modeling
Loss Function
Experiments
Datasets
Parameter Settings
Baseline and Evaluation Metrics
Experimental Results
Analysis and Discussion
Ablation Studies
Performance Analysis
Error Analysis
Related Work
Conclusion
Abstract
A relation tuple consists of two entities and the relation between them, and often such tuples are found in unstructured text. There may be multiple relation tuples present in a text and they may share one or both entities among them. Extracting such relation tuples from a sentence is a difficult task and sharing of entities or overlapping entities among the tuples makes it more challenging. Most prior work adopted a pipeline approach where entities were identified first followed by finding the relations among them, thus missing the interaction among the relation tuples in a sentence. In this paper, we propose two approaches to use encoder-decoder architecture for jointly extracting entities and relations. In the first approach, we propose a representation scheme for relation tuples which enables the decoder to generate one word at a time like machine translation models and still finds all the tuples present in a sentence with full entity names of different length and with overlapping entities. Next, we propose a pointer network-based decoding approach where an entire tuple is generated at every time step. Experiments on the publicly available New York Times corpus show that our proposed approaches outperform previous work and achieve significantly higher F1 scores.
关系元组由两个实体以及它们之间的关系组成,并且经常在非结构化文本中找到这样的元组。在文本中可能存在多个关系元组,并且它们共享一个或两个实体。从一个句子中抽取这样的关系元组是一项困难的工作,并且在共享的实体和重叠的实体之间抽取这样的关系元组更是具有挑战性。以前的大多数工作都是采用管道方法,首先确定实体,然后再找出它们之间的关系,因此在句子中缺少关系元组之间的交互。在本文中,我们提出两种使用encoder-decoder体系结构用于联合抽取实体和关系。
第一种方法,我们提出了一种用于关系元组的表示方案,是的解码器能够向机器翻译模型一样一次生成一个单词,并且仍然能找到一个句子中所有的元组,即使这些实体名长度不同,和重叠实体。第二种方法,我们提出了一种基于指针网络的解码方法,在每一个时间步中生成一个完整的元组。实验是基于公开可获得的纽约时报语料库进行的,并且实验表面了本文提出的方法优于前人的工作,并获得了显著更高的F1分数。
Introduction
Distantly-supervised information extraction systems extract relation tuples with a set of pre-defined relations form text.
参考文献
Traditionally, researchers ((Mintz et al. 2009; Riedel, Yao, and McCallum 2010; Hoffmann et al. 2011) use pipeline approaches where a named entity recognition (NER) system is used to identify the entities in a sentence and the a classifier is used to find the relation (or no relation) between them.However, due to the complete separation of entity detection and relation calssifcation, these models miss the interaction between multiple relation tuples present in a sentence.
参考文献
Recently, several neural network-based models (Katiyar and Cardie 2016; Miwa and Bansal 2016) were proposed to jointly extract entities and relations from a sentence. These models used a parameter-sharing mechanism to extract the entities and relations in the same network. But they still find the relations after identifying all the entities and do not fully capture the interaction among multiple tuples.
参考文献
Zheng et al. (2017) proposed a joint extraction model based on neural sequence tagging scheme. But their model could not extract tuples with overlapping entities in a sentence as it could not assign more than one tag to a word.
参考文献
Zeng et al.(2018) proposed a neural encoder-decoder model for extracting relation tuples with overlapping entities. However, they used a copy mechanism to copy only the last token of the entities, thus this model could not extract the full entity names.
Also , their best performing model used a separate decoder to extract each tuple which limited the power of their model.This model was trained with a fixed number of decoders and could not extract tuples beyond that number during inference.此外,他们使用单独解码器去抽取每个元组的最优性能受限于模型的能力。该模型使用固定数量的解码器进行训练,并且在推理过程中无法提取超过该数量的元组。
Encoder-Decoder models are powerful models and they are successful in many NLP tasks such as machine translation, sentence generation from structured data, and open Information extraction.编码器-解码器模型是一种功能强大的模型,在机器翻译、结构化数据句子生成和开放信息提取等NLP任务中取得了成功。
In this paper, we explore how encoder-decoder models can be used effectively for extracting relation tuples from sentences. There are three major challenges in this task:(1)The model should be able to extract entities and relations together.(2)It should be able to extract multiple tuples with overlapping entities.(3) It Should be able to extract exactly two entities of a tuple with their full names.(i)该模型能够将实体和关系提取在一起。 (ii)能够提取具有重叠实体的多个元组。 (iii)能够准确地提取一个具有全名的元组实体。
To address these challenges, we propose two novel approaches using encoder-decoder architecture. We first propose a new representation scheme for relation tuples (Table 1) such that it can represnet multiple tuples with overlapping entities and different lengths of entities in a simple way. We employ an encoder-decoder model where the decoder extracts one word at a time like machine translation models.At the end of sequence generation , due to the unique representation of the tuples, we can extract the tuples from the sequence of words.
为了解决这些挑战,提出了两种使用编码器-解码器体系结构的新颖方法。首先提出一种用于关系元组的新表示方案(表1),以便它可以用简单的方式表示具有重叠实体和不同长度实体的多个元组。采用编码器-解码器模型,其中解码器像机器翻译模型一样一次提取一个单词。在序列生成的最后,由于元组的独特表示,可以从单词序列中提取元组。
although this model performs quite well, generating one word at a time is somewhat unnatural for this task. Each tuple has extractly two entities and one relation, and each entity appears as a continuous text span in a sentence.
尽管此模型执行得很好,但是一次生成一个单词对于此任务来说有点不自然。每个元组恰好具有两个实体和一个关系,并且每个实体在句子中显示为连续的文本范围。
The most effective way to identify them is to find their start and end location in the sentence.Each relation tuple can then be represented using five items:start and end location of the two entities and the relation between them (see Table 1).

Keeping this in mind, we propose a pointer network-based decoding framework.基于这一点我们提出了一种基于指针网络的解码框架。This decoder consists of two pointer networks which find the start and end location of the two entities in a sentence, and a classification network which identifies the relation between them.这个解码器由两个指针网络和一个分类网络组成,两个指针网络能够从一个句子中发现两个实体的起始和结束位置,分类网络则能够识别两个实体关系。At every time step of the decoding, this decoder extracts an entire relation tuple, not just a word.Experiments on the New York Times(NYT) datasets show that our approaches work effectively for this task and achieve state-of-the-art performance. To summarize, the contributions of this paper are as follows:(1)We propose a new representation scheme for relation tuples such that an encoder-decoder model, which extracts one word at each time step, can still find multiple tuples with overlapping entities and tuples with multi-token entities form sentences.在解码的每一步,该解码器都提取一个完整的关系元组,而不仅仅是一个单词。在纽约时报(NYT)数据集上的实验表明,我们的方法有效地完成了这项任务,并实现了最先进的性能。综上所述,本文的贡献如下:(1)我们提出了一种新的关系元组表示方法,使得在每个时间步提取一个单词的编码器-解码器模型仍然可以找到多个实体重叠的元组,并且多标记实体的元组形成句子.We also propose a masking-based copy mechanism to extract the entities from the source sentence only.
(2)We propose a modification in the decoding framework with pointer networks to make the encoder-decoder model more suitable for this task. At every time step, this decoder extracts an entire relation tuple, not just a word. This new decoding framework helps in speeding up the training process and uses less resources (GPU memory).This will be an important factor when we move from sentence-level tuple extraction to document-level extraction.我们提出了一个修改的解码框架与指针网络,使编码器-解码器模型更适合这项任务。每一步,这个解码器提取一个完整的关系元组,而不仅仅是一个单词。这种新的解码框架有助于加快训练过程,并使用更少的资源(GPU内存)。这将是我们从句子级元组提取转移到文档级提取时的一个重要因素。
(3)Experiments on the NYT datasets show that our approaches outperform all the previous state-of-the-art models significantly and set a new benchmark on these datasets.在NYT数据集上的实验表明,我们的方法显著优于所有以前的最新模型,并在这些数据集上建立了一个新的基准。
Task Description
A relation tuple consists of two entities and a relation. Such tuples can be found in sentences where an entity is a text span in a sentence and a relation comes from a pre-defined set R.These tuples may share one or both entities among them. Based on this, we divide the sentences into three classes:(1)No Entity Overlap(NEO):A sentence in this class has one or more tuples, but they do not share any entities.(2)Entity pair overlap(EPO) : A sentence in this class has more than one tuple, and at least two tuples share both the entities in the same or reverse order.(3)Single Entity Overlap(SEO): A sentence in this class has more than one tuple and at least two tuples share exactly one entity. It should be noted that a sentence can belong to both EPO and SEO classes. Our task is to extract all relation tuples present in a sentence.
关系元组由两个实体和一个关系组成。 这样的元组可以在句子中找到,其中实体是句子中的文本范围,并且关系来自预定义的集合R。这些元组可以在其中共享一个或两个实体。基于这些,我们将句子分为三类:
(1)无实体重叠(NEO):此类中一个句子包含一个或多个元组,但它们不共享任何实体。
(2)实体对重叠(EPO):此类中一个句子有多个元组,并且至少两个元组以相同或相反的顺序共享两个实体。
(3)单实体重叠(SEO):此类中一个句子包含一个以上的元组,并且至少两个元组正好共享一个实体。
一个句子可以同时属于EPO和SEO类,任务是提取句子中存在的所有关系元组。我们的任务是提取句子中的所有关系元组。
Encoder-Decoder Architecture
In this task, input to the system is a sequence of words, and output is a set of relation tuples. In our first approach, we represent each tuple as entity1; entity2; relation. We use ';'as a separator token to separate the tuple components. Multiple tuples are separated using the '|' token. We have included one example of such representation in Table 1. Multiple relation tuples with overlapping entities and different lengths of entities can be represented in a simple way using these special tokens (; and | ).此任务中输入是单词序列,输出是一组关系元组。第一种方法中,表示每个元组的实体1;实体2;关系,使用“;”作为分隔符来分隔元组各部分,多行元组使用“ |”分隔。使用这些特殊标记,可以用一种简单的方式表示具有重叠实体和不同长度实体的多个关系元组。
During inference, after the end of sequence generation , relation tuples can be extracted easily using these special tokens. Due to this uniform representation scheme, where entity tokens, relation tokens, and special tokens are treated similarly, we use a shared vocabulary between the encoder and decoder which includes all of these tokens.The input sentence contains clue words for every relation which can help generate the relation tokens.We use two special tokens so that the model can distinguish between the beginning of a relation tuple and the beginning of a tuple component.To extract the relation tuples from a sentence suing the encoder-decoder model, the model has to generate the entity tokens, find relation clue words and map them to the relation tokens, and generate the special tokens at appropriate time.Our experiments show that the encoder-decoder models can achieve this quite effectively.在推理过程中,序列生成结束后,可以使用这些特殊标记轻松提取关系元组。由于采用了这种统一的表示方案,对实体,关系和特殊标记的处理类似,因此编码器和解码器之间使用了包含所有这些标记的共享词汇。输入句子包含每个关系的线索词,可以帮助生成关系标记。其次使用两个特殊标记,以便模型可以区分关系元组的开头和元组组件的开头。为了使用编码器-解码器模型从句子中提取关系元组,该模型必须生成实体标记,找到关系线索词并将其映射到关系标记,并在适当的时间生成特殊标记。我们的实验显示E-D模型非常有效的实现这些。
Embedding Layer & Encoder

(1)关系集合R;
(2)特殊分割符标记:“;”,“|”
(3)start-of-target-sequence (SOS), end-of-target-sequence(EOS),unkonwn work token(UNK)
(4)词级嵌入由两部分组成:①预训练词向量;②基于字符嵌入的特征向量;
(5)词嵌入层![]() ,字符级嵌入
,字符级嵌入![]()
其中,![]() 是词向量的维数;A是输入句子标记的字母字符,
是词向量的维数;A是输入句子标记的字母字符,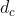 是字符嵌入向量的维数;
是字符嵌入向量的维数;
(6)使用具有最大池化的卷积神经网络为每个单词提取维度为![]() 的特征向量。
的特征向量。
(7)Word embeddings and character embedding-based feature vectors are concatenated(||) to obtain the representation of the input tokens. (此处的“||”理解为连接,有两个向量连接成为一个向量)
(8)S 被表示成:X1,X2,... ... ,Xn, 其中![]() 表示的是第i个词,n表示S的长度。
表示的是第i个词,n表示S的长度。
(9)Xi被传递到Bi-LSTM中,获取隐藏层的表示![]() ,Bi-LSTM的前向和后向LSTM的隐藏维度设置为
,Bi-LSTM的前向和后向LSTM的隐藏维度设置为![]() ,
,![]() ;
;
(10)![]() 是后面描述的解码器的序列生成器LSTM的隐藏维度。
是后面描述的解码器的序列生成器LSTM的隐藏维度。
Word-level Decoder & Copy Mechanism
(1)目标序列T被表示成:![]() ,m是目标序列的长度。
,m是目标序列的长度。

(1)目标序列T仅由标记y0; y1; ::::; ym的词嵌入向量表示,其中![]() 是第i个标记的嵌入向量,m是目标序列的长度。
是第i个标记的嵌入向量,m是目标序列的长度。
(2)y0和ym分别代表SOS和EOS标记的嵌入向量。解码器一次生成一个标记,并在生成EOS时停止。
(3)使用LSTM作为解码器,在t步时间,解码器将源语句编码(![]() )和先前的目标词嵌入(
)和先前的目标词嵌入( )作为输入,并生成当前标记的隐藏表示(
)作为输入,并生成当前标记的隐藏表示(![]() )。
)。
(4)使用注意力机制获得句子编码向量![]() ,使用具有权重矩阵
,使用具有权重矩阵![]() 和偏差矢量
和偏差矢量![]() 的线性层将
的线性层将![]() 投影到词汇表V。
投影到词汇表V。
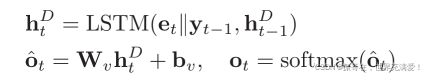
(5)![]() 表示词汇表中所有单词在t步时间上的标准得分。
表示词汇表中所有单词在t步时间上的标准得分。![]() 表示LSTM的前隐藏状态。
表示LSTM的前隐藏状态。
The projection layer of the decoder maps the decoder output to the entire vocabulary. During training, we use the gold label target tokens directly. However, during inference, the decoder may predict a token from the vocabullary which is not present in the current sentence or the set of relations or the special tokens. 解码器的映射层映射解码器的输出到整个词汇表上,在训练过程中用gold label直接标记目标记号。然而在推断中,解码器可以从词汇表中预测在当前句子或关系集或特殊标记中不存在的标记。
To prevent this, we use a masking technique (屏蔽技术)while applying the softmax operation at the projection layer.We mask (exclude) all words of the vocabulary except the current source sentence tokens, relation tokens, separator tokens(';', '|') ,UNK, and EOS tokens in the softmax operation.To mask (exculde) some word from softmax, we set the corresponding value in ![]() at
at 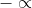 and the corresponding softmax score will be zero.(相对应的softmax分数将为0)This ensures the copying of entities from the source sentence only.(确保从原子句中复制实体)
and the corresponding softmax score will be zero.(相对应的softmax分数将为0)This ensures the copying of entities from the source sentence only.(确保从原子句中复制实体)
We include the UNK token in the softmax operation to make sure that the model generates new entities during inference. If the decoder predicts an UNK token, we replace it with the corresponding source word which has the highest attention score.(如果解码器预测的是UNK符号,则将其替换为具有最高注意得分的原词)。
During inference, after decoding is finished, we extract all tuples based on the special tokens, remove duplicate tuples and tuples in which both entities are the same or tuples where the relation token is not from the relation set. This model is referred to as WordDecoding (WDec) henceforth.(在推理过程中,解码器完成了解码后,我们抽取了基于特殊标记提取的元组,移除掉复制的元组、实体相同的元组,关系标记不在关系集合中的元组)
Pointer Network-based Decoder

(1)在第二中方法中,使用实体在句子中的开始和结束位置来识别实体。
(2)从单词词汇表中删除特殊标记和关系名称,并且单词嵌入仅在编码器侧与字符嵌入一起使用。在模型的解码器端使用附加的关系嵌入矩阵![]() ;
;
(3)y0是一个虚拟元组,表示序列的起始元组。而ym充当序列的结束元组,该序列具有EOS作为关系(该元组将忽略实体)。

(1)解码器由一个LSTM(具有隐藏维dh来生成元组序列)、两个指针网络(用于查找两个实体)以及分类网络(用于查找元组的关系)组成。
(2)在时间步骤t,解码器将源语句编码和所有先前生成的元组的表示 ![]() 作为输入,并生成当前元组的隐藏表示。 (当前隐藏层计算的输入是原语句et和前一层元组的表示yprev做为输入)
作为输入,并生成当前元组的隐藏表示。 (当前隐藏层计算的输入是原语句et和前一层元组的表示yprev做为输入)
(3)句子编码向量et是通过使用Attention mechanism获得的;
(4)关系元组是一个集合,为了防止解码器再次生成相同的元组,在解码的每个时间步传递有关所有的元组的信息。
(5)yj表示的是时间步长j![]() 是时间t-1处LSTM的隐藏状态。
是时间t-1处LSTM的隐藏状态。
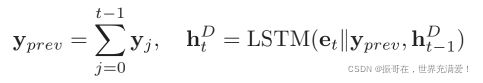
Relation Tuple Extraction

在获得当前元组![]() 的隐藏表示之后,首先在源语句中找到两个实体的开始和结束指针。将向量
的隐藏表示之后,首先在源语句中找到两个实体的开始和结束指针。将向量![]() 与编码器的隐藏向量
与编码器的隐藏向量![]() 连接起来,然后将它们传递给具有dp隐藏维度的Bi-LSTM层,以实现向前和向后LSTM。 该Bi-LSTM层的隐藏向量
连接起来,然后将它们传递给具有dp隐藏维度的Bi-LSTM层,以实现向前和向后LSTM。 该Bi-LSTM层的隐藏向量![]() 被传递到具有softmax的两个前馈网络(FFN),以将每个隐藏向量转换为介于0和1之间的两个标量值,Softmax操作应用于输入句子中的所有单词。这两个标量值表示相应的源句子标记成为第一个实体的开始和结束位置的概率。带有两个前向层的Bi LSTM层是标识当前关系元组的第一个实体的第一个指针网络。
被传递到具有softmax的两个前馈网络(FFN),以将每个隐藏向量转换为介于0和1之间的两个标量值,Softmax操作应用于输入句子中的所有单词。这两个标量值表示相应的源句子标记成为第一个实体的开始和结束位置的概率。带有两个前向层的Bi LSTM层是标识当前关系元组的第一个实体的第一个指针网络。


![]() 表示的是标准化概率,是第i个源词的预测元组的第一个实体的开始和结束的概率。然后使用第二个指针网络来提取第二个元组,将
表示的是标准化概率,是第i个源词的预测元组的第一个实体的开始和结束的概率。然后使用第二个指针网络来提取第二个元组,将![]() 这三个向量连接起来,传输到第二个指针网络中获得第i个源词的第二个实体的开始和结束的概率
这三个向量连接起来,传输到第二个指针网络中获得第i个源词的第二个实体的开始和结束的概率 ![]() 。利用标准化后的概率来计算两个实体的向量,表示如下:
。利用标准化后的概率来计算两个实体的向量,表示如下:


将 三者进行连接,并乘以权重矩阵
三者进行连接,并乘以权重矩阵 ,利用一个偏置向量br修正。
,利用一个偏置向量br修正。

(1) 表示时间步 t 时的预测关系的标准化概率,
表示时间步 t 时的预测关系的标准化概率,![]() 是argmax 函数、和Er 计算得到,
是argmax 函数、和Er 计算得到, 是时间步 t 预测元组的的向量表示。
是时间步 t 预测元组的的向量表示。
(2)在训练过程中,我们通过金标关系(?)的嵌入向量代替预测关系。因此,argmax函数不会影响训练期间的反向传播。
(3)当预测关系为EOS是解码器停止序列生成过程,这就是解码器的分类网络。

(1)在推理过程中,选择两个实体的开始和结束的位置,求四个指针概率乘积最大值,同时保持两个实体不相互重叠,且1<=b<=e<=n的约束条件,其中b和e是对应实体的开始和结束的位置。
(2)首先选择基于对应的开始和结束的指针概率的乘积求实体1的起点和终点。然后类似的方法找到实体2,排除实体1的span,避免重叠。
(3)重复相同的过程,但是,先找到实体2,在找实体1。
(4)选择该对实体,在两个选择之间给出了四个指针概率的较高乘积。此后,这个模型被称为PtrNetDecoding(PNDec)(土话解释:选项1:先找实体1,再找实体2,求四个概率的乘积;选项2:先找实体2,再找实体1,求四个概率的乘积。 从这两个选项中找一个概率乘积较高的作为最后的选择模型条件。)
Attention Modeling
We experimented with three different attention mechanisms for our word-level decoding model to obtain the source context vector 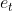 :
:
(1)Avg:上下文向量是通过平均编码的隐藏向量来获得的:
![]()
(2)N-gram:上下文向量是通过N-gram注意机制来获得的,其中N=3

(3)Single:上下文向量的获得是通过Bahdanau,Cho and Bengio(2015) 提出的注意机制。这种注意机制给出了词级解码模型最优的性能。

(*)本文的注意模型(Attention Modeling)工作:

对于基于指针网络的解码模型使用single注意模型的三个变体。首先,使用![]() 在注意力机制中计算
在注意力机制中计算![]() ,其次,使用
,其次,使用![]() 计算
计算![]() ;最后,用
;最后,用![]() 和
和![]() 获得的两个注意向量进行级联来获得注意上下文向量。通过基于指针网络的解码模型,可以提供最佳性能。
获得的两个注意向量进行级联来获得注意上下文向量。通过基于指针网络的解码模型,可以提供最佳性能。

Loss Function
We minimize the negative log-likelihood loss of the generated words for word-level decoding (Lword) and minimize the sum of negative log-likelihood loss of relation classification and the four pointer locations for pointer network-based decoding (Lptr).

(1)![]() 是单词级解码中时间步t处目标单词的softmax得分;
是单词级解码中时间步t处目标单词的softmax得分;
(2) r/s/e 是实体相应的真实关系标签、真实start和end指针位置的softmax得分;
(3) b/t/r 是第b个训练实例、解码时间步t和一个元组的两个实体;
(4)B/T分别是batch size和解码器的最大时间步。
Experiments
Datasets
对于实验数据集的选择,选取的是NYT的语料库。该数据集有多个版本,本文选取了两个该数据集的两个版本分别如下:
(1)Zeng et al(2018), 命名为NYT24。 里面包含了24个关系;
(2)Takanobu et al (2019),密码为NYT29。里面包含了29个关系。
本文选择10%的原始训练数据作为验证数据集,剩余90%用于训练,表2给出了训练和测试的数据集的统计数据。

Parameter Settings

相关参数说明如上标记。为了防止过拟合,设置dropout reate为0.3
Baseline and Evaluation Metrics
本文比较了如下最新的实体和关系联合抽取的模型:
(1)SPTree;参考文献:(Miwa and Bansal 2016):This is an end-to-end neural entity and relaiton extraction model using sequence LSTM and Tree LSTM. Sequence LSTM is used to identify all the entities first and then Tree LSTM is used to find the relation between all pairs of entites.
这是一个使用序列LSTM和树LSTM的端到端神经实体和关系提取模型。首先使用序列LSTM识别所有实体,然后使用树LSTM查找所有实体对之间的关系。
(2)Tagging;参考文献:(Zheng et al. 2017):This is a neural sequence tagging model which jointly extract the entities and relaitons using an LSTM encoder and an LSTM decoder. They used a Cartesian product (笛卡尔积) of entity tags and relation tags to encoder the entity and relation information together. This model does not work when tuples have overlapping entities.
这是一个神经序列标记模型,使用LSTM编码器和LSTM解码器联合提取实体和关系。他们使用笛卡尔积用于将实体和关系信息编码在一起的实体标记和关系标记。当元组具有重叠实体时,此模型不起作用。
(3)CopyR;参考文献:(Zeng et al. 2018):This model uses an encoder-decoder approach for joint extraction of entities and relations. It copies only the last token of an entity from the source sentence. Their best performing multi-decoder model is trained with a fixed number of decoders where each decoder extracts one tuple.
该模型使用编码器-解码器方法联合提取实体和关系。它只从源语句复制实体的最后一个标记。最佳性能多解码器模型使用固定数量的解码器进行训练,其中每个解码器提取一个元组。
(4)HRL;参考文献:(Takanobu et al. 2019):This model uses a reinforcement learning(RL) algorithm with two levels of hierarchy for tuple extraction. A high-level RL finds the relation and a low-level RL identities the two entities using a sequence tagging approach. This sequence tagging approach cannot always ensure extraction of exactly two entities.
该模型采用两层结构的强化学习(RL)算法进行元组提取。高级RL查找关系,低级RL使用序列标记方法标识两个实体。这种序列标记方法不能始终确保只提取两个实体。
(5)GraphR;参考文献:(Fu, Li, and Ma 2019):This model considers each token in a sentence as a node in a graph, and edges connecting the nodes as relations between them. They use graph convolution network (GCN) to predict the relations of every edge and then filter out some of the relaitons.
该模型将句子中的每个标记视为图中的一个节点,将连接节点的边视为它们之间的关系。使用图卷积网络(GCN)预测每条边的关系,然后过滤掉一些关系。
(6)N-gram Attention; 参考文献:(Trisedya et al. 2019):This model uses an encoder-decoder approach with N-gram attention mechanism for knowledge-base completion using distantly supervised data. The encoder uses the entire Wikidata (参考文献) entity IDs and relation IDs as its vocabulary. The encoder takes the source sentence as input and the decoder outputs the two entity IDs and relation ID for every tuple.该模型采用了一种具有N-gram注意机制的编码-解码方法,用于使用远程监督数据完成知识库。编码器使用整个Wikidata实体ID和关系ID作为其词汇表。编码器将源语句作为输入,解码器输出每个元组的两个实体ID和关系ID。
During training, it uses the mapping of entity names and wikidata IDs of the entire wikidata for proper alignment. Our task of extracting relation tuples with the raw entity names from a sentence is more challenging since entity names are not of fixed length.在训练期间,它使用整个wikidata的实体名称和wikidata ID的映射进行适当的对齐。我们从句子中提取具有原始实体名称的关系元组的任务更具挑战性,因为实体名称不是固定长度的。
Our more generic approach is also helpful for extracting new entities which are not present in the existing knowledge bases such as Wikidata. We use their N-gram attention mechanism in our model to compare its performance with other attention models (Table 4).我们更通用的方法也有助于提取现有知识库(如Wikidata)中不存在的新实体。在我们的模型中,使用他们的N-gram注意机制来比较其与其他注意模型的性能(表4)。
We use the same evaluation method used by Takanobu et al. (2019) in their experiments. We consider the extracted tuples as a set and remove the duplicate tuples. An extracted tuple is considered as correct if the corresponding full entity names are correct and the relation is also correct. We report precision, recall, and F1 score for comparison.
Experimental Results



Analysis and Discussion
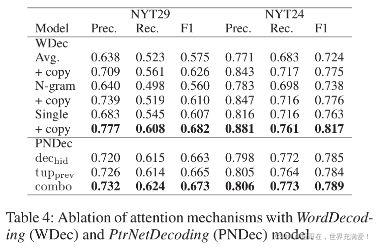
Ablation Studies
We include the performance of different attention mechanisms with our WordDecoding model, effects of our masking-based copy mechanism, and ablation results of three variants of the single attention mechanism with our PtrNetDecoding model in Table4.
我们在表4中包括了不同注意机制,包括我们的WordDecoding model的表现,基于屏蔽的复制机制的影响,以及单注意机制的三种变体在我们的PtrNetDecoding模型中的消融结果。
WordDecoding with single attention achieves the highest F1 score on both datasets. We also see that our copy mechanism improves F1 scores by around 4-7% in each attention mechanism with both datasets.
PtrNetDecoding achieves the highest F1 scores when we combine the two attention mechanisms with respect to the previous hidden vector of the decoder LSTM (![]() ) and representation of all previously extracted tuples (
) and representation of all previously extracted tuples (![]() ).
).
在两个数据集上,单注意力文字解码的F1得分最高。我们还发现,我们的复制机制在两个数据集的每个注意机制中提高F1分数约4-7%。
当我们结合两种注意机制时,PtrNetDecoding可以获得最高的F1分数,这两种注意机制涉及解码器LSTM的先前隐藏向量和所有先前提取的元组的表示。
Performance Analysis
From Table 3, we see that CopyR, HRL, and our models achieve significantly higher F1 scores on the NYT24 dataset than the NYT29 dataset. Both datasets have a similar set of relations and similar texts (NYT). So task-wise both datasets should pose a similar challenge. However, the F1 scores suggest that the NYT24 dataset is easier than NYT29. The reason is that NYT24 has around 72.0% of overlapping tuples between the training and test data (% of test tuples that appear in the training data with different source sentences). In contrast, NYT29 has only 41.7% of overlapping tuples. Due to the memorization power of deep neural networks, it can achieve much higher F1 score on NYT24. The difference between the F1 scores of WordDecoding and PtrNetDecoding on NYT24 is marginally higher than NYT29, since WordDecoding has more trainable parameters (about 27 million) than PtrNetDecoding (about 24.5 million) and NYT24 has very high tuple overlap. However, their ensemble versions achieve closer F1 scores on both datasets.
从表3中,可以看到,CopyR、HRL和我们的模型在NYT24数据集上的F1得分显著高于NYT29数据集。两个数据集都有一组相似的关系和文本(NYT)。因此,就任务而言,这两个数据集应该会带来类似的挑战。然而,F1分数表明NYT24数据集比NYT29更容易。原因是NYT24在训练数据和测试数据之间有大约72.0%的重叠元组(占训练数据中不同源语句出现的测试元组的百分比)。相比之下,NYT29只有41.7%的重叠元组。由于深层神经网络的记忆能力,它可以在NYT24上获得更高的F1分数。NYT24上WordDecoding和PtrNetDecoding的F1分数之间的差异略高于NYT29,因为WordDecoding的可训练参数(约2700万)比PtrEntDecoding(约2450万)多,NYT24的元组重叠非常高。然而,他们的集成版本在两个数据集上都获得了更接近F1的分数。
Despite achieving marginally lower F1 scores, the pointer network-based model can be considered more intuitive and suitable for this task. WordDecoding may not extract the special tokens and relation tokens at the right time steps, which is critical for finding the tuples from the generated sequence of words. PtrNetDecoding always extracts two entities of varying length and a relation for every tuple. We also observe that PtrNetDecoding is more than two times faster and takes one-third of the GPU memory of WordDecoding during training and inference. This speedup and smaller memory consumption are achieved due to the fewer number of decoding steps of PtrNetDecoding compared to WordDecoding. PtrNetDecoding extracts an entire tuple at each time step, whereas WordDecoding extracts just one word at each time step and so requires eight time steps on average to extract a tuple (assuming that the average length of an entity is two). The softmax operation at the projection layer of WordDecoding is applied across the entire vocabulary and the vocabulary size can be large (more than 40,000 for our datasets). In case of PtrNetDecoding, the softmax operation is applied across the sentence length (maximum of 100 in our experiments) and across the relation set (24 and 29 for our datasets). The costly softmax operation and the higher number of decoding time steps significantly increase the training and inference time for WordDecoding. The encoderdecoder model proposed by Trisedya et al. (2019) faces a similar softmax-related problem as their target vocabulary contains the entire Wikidata entity IDs and relation IDs which is in the millions. HRL, which uses a deep reinforcement learning algorithm, takes around 8x more time to train than PtrNetDecoding with a similar GPU configuration. The speedup and smaller memory consumption will be useful when we move from sentence-level extraction to documentlevel extraction, since document length is much higher than sentence length and a document contains a higher number of tuples.
尽管F1成绩略低,但基于指针网络的模型更直观,更适合此任务。WordDecoding可能无法在正确的时间步提取特殊标记和关系标记,这对于从生成的单词序列中查找元组至关重要。PtrNetDecoding总是为每个元组提取两个不同长度的实体和一个关系。我们还观察到,在训练和推理期间,PtrNetDecoding的速度比GPU快两倍多,占用了GPU字解码内存的三分之一。与字解码相比,PtrNetDecoding的解码步骤更少,因此实现了这种加速和更小的内存消耗。PtrNetDecoding在每个时间步提取整个元组,而WordDecoding在每个时间步仅提取一个单词,因此提取元组平均需要八个时间步(假设实体的平均长度为两个)。WordDecoding投影层的softmax操作应用于整个词汇表,词汇表的大小可能很大(我们的数据集超过40000个)。在PtrNetDecoding的情况下,softmax操作应用于整个句子长度(在我们的实验中最大为100)和整个关系集(对于我们的数据集为24和29)。昂贵的softmax操作和较高的解码时间步数显著增加了字解码的训练和推理时间。Trisedya et al.(2019)提出的编码器-解码器模型面临类似的softmax相关问题,因为其目标词汇表包含数百万的整个Wikidata实体ID和关系ID。HRL使用深度强化学习算法,训练时间比使用类似GPU配置的PtrNetDecoding多8倍左右。当我们从句子级提取转移到文档级提取时,加速和较小的内存消耗将非常有用,因为文档长度远高于句子长度,并且文档包含更多的元组。
Error Analysis
The relation tuples extracted by a joint model can be erroneous for multiple reasons such as: (i) extracted entities are wrong; (ii) extracted relations are wrong; (iii) pairings of entities with relations are wrong. To see the effects of the first two reasons, we analyze the performance of HRL and our models on entity generation and relation generation separately. For entity generation, we only consider those entities which are part of some tuple. For relation generation, we only consider the relations of the tuples. We include the performance of our two models and HRL on entity generation and relation generation in Table 5. Our proposed models perform better than HRL on both tasks. Comparing our two models, PtrNetDecoding performs better than WordDecoding on both tasks, although WordDecoding achieves higher F1 scores in tuple extraction. This suggests that PtrNetDecoding makes more errors while pairing the entities with relations. We further analyze the outputs of our models and HRL to determine the errors due to ordering of entities (Order), mismatch of the first entity (Ent1), and mismatch of the second entity (Ent2) in Table 6. WordDecoding generates fewer errors than the other two models in all the categories and thus achieves the highest F1 scores on both datasets.
由联合模型提取的关系元组可能由于多种原因而错误,例如:(i)提取的实体错误;(ii)提取的关系是错误的;(iii)有关系实体的配对是错误的。为了了解前两个原因的影响,我们分别分析了HRL和我们的模型在实体生成和关系生成方面的表现。对于实体生成,我们只考虑那些是某元组的一部分的实体。对于关系的生成,我们只考虑元组之间的关系。我们在表5中包括了我们的两个模型和HRL在实体生成和关系生成方面的性能。我们提出的模型在这两项任务上都比HRL更好。比较我们的两个模型,PtrNetDecoding在两个任务上都比WordDecoding表现更好,尽管WordDecoding在元组提取中获得了更高的F1分数。这表明PtrNetDecoding在将实体与关系配对时会产生更多错误。我们进一步分析了我们的模型和HRL的输出,以确定表6中实体顺序(或 der)、第一个实体不匹配(Ent1)和第二个实体不匹配(Ent2)导致的错误。在所有类别中,单词解码产生的错误比其他两种模型都少,因此在两个数据集上都获得了最高的F1分数。

通过表5看出WDec的精确率是最高的,且错误率是各个维度和原因上的最低(同维度比较)
Related Work
Traditionally, researchers (
Mintz et al. 2009; Riedel,
Yao, and McCallum 2010;
Hoffmann et al. 2011;
Zeng et al.2014; 2015;
Shen and Huang 2016;
Ren et al. 2017;
Zhang et al. 2017;
Jat, Khandelwal, and Talukdar 2017;
Vashishth et al. 2018;
Ye and Ling 2019;
Guo, Zhang, and Lu 2019;
Nayak and Ng 2019) used a pipeline approach for relation tuple extraction where relations were identified using a classification network after all entities were detected.使用管道方法提取关系元组,在检测到所有实体后,使用分类网络识别关系。
Su et al.(2018) used an encoder-decoder model to extract multiple relations present between two given entities.Su等人(2018年)使用编码器-解码器模型提取两个给定实体之间存在的多个关系。
Recently, some researchers (
Katiyar and Cardie 2016;
Miwa and Bansal 2016;
Bekoulis et al. 2018;
Nguyen and Verspoor 2019) tried to bring these two tasks closer together by sharing their parameters and optimizing them together.最近,一些研究人员(;;;)试图通过共享其参数并对其进行优化,使这两项任务更接近。
Zheng et al. (2017) used a sequence tagging scheme to jointly extract the entities and relations.使用序列标记方案联合提取实体和关系
Zeng et al. (2018) proposed an encoder-decoder model with copy mechanism to extract relation tuples with overlapping entities.提出了一种具有复制机制的编码器-解码器模型,用于提取具有重叠实体的关系元组。
Takanobu et al. (2019) proposed a joint extraction model based on reinforcement learning (RL).提出了一种基于强化学习(RL)的联合提取模型。
Fu, Li, and Ma (2019) used a graph convolution network (GCN) where they treated each token in a sentence as a node in a graph and edges were considered as relations.使用了图卷积网络(GCN),他们将句子中的每个标记视为图中的一个节点,并将边视为关系。
Trisedya et al. (2019) used an N-gram attention mechanism with an encoder-decoder model for completion of knowledge bases using distant supervised data.使用N-gram注意机制和编码器-解码器模型,使用远程监督数据完成知识库
Encoder-decoder models have been used for many NLP applications such as neural machine translation (
Sutskever, Vinyals, and Le 2014;
Bahdanau, Cho, and Bengio 2015;
Luong, Pham, and Manning 2015), sentence generation from structured data (
Marcheggiani and Perez-Beltrachini 2018;
Trisedya et al. 2018), and open information extraction (
Zhang, Duh, and Van Durme 2017;
Cui, Wei, and Zhou 2018). Pointer networks (
Vinyals, Fortunato, and Jaitly 2015) have been used to extract a text span from text for tasks such as question answering (
Seo et al. 2017;
Kundu and Ng 2018). For the first time, we use pointer networks with an encoder-decoder model to extract relation tuples from sentences.
编码器解码器模型已被用于许多NLP应用,如神经机器翻译(SutsKyver,Viyales和LE 2014;BaDayAu,CHO和BunoIO 2015;Luong,Pham和Mun宁2015),从结构化数据生成句子(Marcheggiani和Perez Beltrachini 2018;TraseDyA等人2018),以及开放信息提取。(Zhang、Duh和Van Durme 2017;Cui、Wei和Zhou 2018)。指针网络(Vinyals、Fortunato和Jaitly 2015)已被用于从文本中提取文本跨度,用于问答等任务(Seo等人2017;Kundu和Ng 2018).我们首次使用带有编码器-解码器模型的指针网络从句子中提取关系元组。
Conclusion
Extracting relation tuples from sentences is a challenging task due to different length of entities, the presence of multiple tuples, and overlapping of entities among tuples. In this paper, we propose two novel approaches using encoder-decoder architecture to address this task. Experiments on the New York Times (NYT) corpus show that our proposed models achieve significantly improved new state-of-the-art F1 scores. As future work, we would like to explore our proposed models for a document-level tuple extraction task.
从句子中提取关系元组是一项具有挑战性的任务,因为实体的长度不同,存在多个元组,并且元组之间存在实体重叠。在本文中,我们提出了两种新的方法使用编码器-解码器架构来解决这一任务。在纽约时报(NYT)语料库上的实验表明,我们提出的模型显著提高了最新的F1成绩。作为未来的工作,我们将探索文档级元组提取任务提出的模型。
手画一遍可以帮助理解不少内容,来自文档Figure 1.