TensorFlow构建模型二
概要
本文利用tensorflow构建文本分类模型,数据集使用的是IMDB电影评论文本【数据集地址】,模型主要有四层:

模型构建
导入所需要的库,以及下载数据集。
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras import preprocessing
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir) # ['imdbEr.txt', 'imdb.vocab', 'test', 'README', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir) # ['unsupBow.feat', 'unsup', 'pos', 'urls_unsup.txt', 'neg', 'urls_neg.txt', 'urls_pos.txt', 'labeledBow.feat']
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
上述代码可以详细的查看数据的文件目录结构,其中train_dir路径下有pos和neg两个文件,分别是积极评论和消极评论。
数据集处理,首先需要使用tf.keras.preprocessing.text_dataset_from_directory处理数据,而该api对数据的目录结构有要求:
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
api的参数说明:

# 删除不相干的文件夹
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
# 获取训练集 其中batch_size=32
batch_size = 32
seed = 42
# 训练集
raw_train_ds = tf.keras.preprocessing.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
# 验证集
raw_val_ds = tf.keras.preprocessing.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
# 测试集
raw_test_ds = tf.keras.preprocessing.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
# 查看获取的数据集的具体内容
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
# 通过下面的代码可以查看数据的标签值对应的label。
print("Label 0 corresponds to", raw_train_ds.class_names[0]) # Label 0 corresponds to neg
print("Label 1 corresponds to", raw_train_ds.class_names[1]) # Label 1 corresponds to pos
通过tf.keras.preprocessing.text_dataset_from_directory将磁盘上的数据加载成我们需要的训练集、验证集、测试集。但是,在数据文本中通常包含其他的字符。如在本数据集中有标点符号、HTML代码,如:
。我们需要使用TextVectorization进行处理,对数据进行标准化(对文本进行预处理,通常是移除标点符号或 HTML 元素以简化数据集)、词例化(将字符串分割成词例,例如:通过空格将句子分割成单个单词)、向量化(将词例转换为数字,以便将它们输入神经网络),该处理操作可以嵌入到模型中。
# 自定义数据处理标准
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '
', ' ')
return tf.strings.regex_replace(stripped_html, '[%s]' % re.escape(string.punctuation), '')
# 创建vectorize层
max_features = 10000
sequence_length = 250
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
# 构建好了TextVectorization层需要利用训练集生成字符串到整数的索引。这里只能利用训练集,并且去掉样本的标签。
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
# 查看每个整数对应的词
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287]) # 1287 ---> silent
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313]) # 313 ---> night
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary()))) # Vocabulary size: 10000
# 构造可以用于训练的数据集
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
# 在数据集配置时,为了确保I/O不会阻塞,可以使用.cache()方法将数据保存在内存中,这样可以确保数据集在训练模型时不会成为瓶颈。如果数据集太大而无法放入内存中,也可以使用此方法创建高性能的磁盘缓存,这比许多小文件的读取效率更高。
# prefetch()会在训练时将数据预处理和模型执行重叠。
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
模型创建
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
# 优化器使用adam,loss使用二分类交叉熵,评估标准使用accuracy。
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy'])
模型训练和评估
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss) # Loss: 0.42885157465934753
print("Accuracy: ", accuracy) # Accuracy: 0.8742799758911133
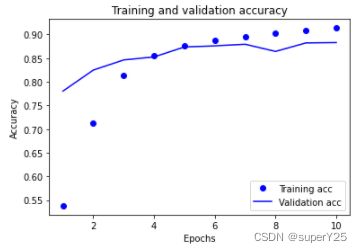
可以查看模型训练时准确率和损失的变化
history_dict = history.history
history_dict.keys() # dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()

导出模型,在导出模型时,可以将TextVectorization层嵌入到模型中,这样可以在应用预测时可以直接对模型输入原始数据,不用先对数据进行预处理操作。但是在模型训练时,将TextVectorization放在模型外,是为了使它可以让模型在GPU上训练时进行异步CPU处理和数据缓冲。
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
# 对新样本的预测
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
根据上面的模型构建过程,修改成一个多分类模型,使用 Stack Overflow 数据集,该数据集包含4个分类:Python、CSharp、JavaScript 或 Java。
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras import preprocessing
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
# 更改数据集地址
url = "http://storage.googleapis.com/download.tensorflow.org/data/stack_overflow_16k.tar.gz"
dataset = tf.keras.utils.get_file("stack_overflow_16k", url,
untar=True, cache_dir='.',
cache_subdir='')
train_dir = os.path.join(os.path.dirname(dataset),"train")
test_dir = os.path.join(os.path.dirname(dataset),"test")
# 同样的逻辑处理数据集
# 获取训练集 其中batch_size=32
batch_size = 32
seed = 42
# 训练集
raw_train_ds = tf.keras.preprocessing.text_dataset_from_directory(
train_dir,
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
# 验证集
raw_val_ds = tf.keras.preprocessing.text_dataset_from_directory(
train_dir,
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
# 测试集
raw_test_ds = tf.keras.preprocessing.text_dataset_from_directory(
test_dir,
batch_size=batch_size)
# 通过下面的代码可以查看数据的标签值对应的label。
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
print("Label 2 corresponds to", raw_train_ds.class_names[2])
print("Label 3 corresponds to", raw_train_ds.class_names[3])
"""
Label 0 corresponds to csharp
Label 1 corresponds to java
Label 2 corresponds to javascript
Label 3 corresponds to python
"""
# 自定义数据处理标准 这个标准有点不对,因为没有仔细研究数据文本,所以不清楚有什么特殊字符。
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '
', ' ')
return tf.strings.regex_replace(stripped_html, '[%s]' % re.escape(string.punctuation), '')
# 创建vectorize层
max_features = 10000
sequence_length = 250
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
# 构建好了TextVectorization层需要利用训练集生成字符串到整数的索引。这里只能利用训练集,并且去掉样本的标签。
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# 构造可以用于训练的数据集
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
# 在数据集配置时,为了确保I/O不会阻塞,可以使用.cache()方法将数据保存在内存中,这样可以确保数据集在训练模型时不会成为瓶颈。如果数据集太大而无法放入内存中,也可以使用此方法创建高性能的磁盘缓存,这比许多小文件的读取效率更高。
# prefetch()会在训练时将数据预处理和模型执行重叠。
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(4)]) # 最后一层节点数和类别数对齐,属于多分类。
# 优化器使用adam,loss使用多分类交叉熵【不再是二分类】,评估标准使用accuracy。
model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
loss, accuracy = model.evaluate(test_ds)
export_model = tf.keras.Sequential([
vectorize_layer,
model,
tf.keras.layers.Softmax() # 最后一层添加的不再是sigmoid函数,而是softmax函数。
])
export_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
# 对新样本的预测 1,3,1
examples = [
"my tester is going to the wrong constructor i am new to programming so if i ask a question that can be easily fixed, please forgive me. my program has a tester class with a main. when i send that to my regularpolygon class, it sends it to the wrong constructor. i have two constructors. 1 without perameters..public regularpolygon(). {. mynumsides = 5;. mysidelength = 30;. }//end default constructor...and my second, with perameters. ..public regularpolygon(int numsides, double sidelength). {. mynumsides = numsides;. mysidelength = sidelength;. }// end constructor...in my tester class i have these two lines:..regularpolygon shape = new regularpolygon(numsides, sidelength);. shape.menu();...numsides and sidelength were declared and initialized earlier in the testing class...so what i want to happen, is the tester class sends numsides and sidelength to the second constructor and use it in that class. but it only uses the default constructor, which therefor ruins the whole rest of the program. can somebody help me?..for those of you who want to see more of my code: here you go..public double vertexangle(). {. system.out.println(""the vertex angle method: "" + mynumsides);// prints out 5. system.out.println(""the vertex angle method: "" + mysidelength); // prints out 30.. double vertexangle;. vertexangle = ((mynumsides - 2.0) / mynumsides) * 180.0;. return vertexangle;. }//end method vertexangle..public void menu().{. system.out.println(mynumsides); // prints out what the user puts in. system.out.println(mysidelength); // prints out what the user puts in. gotographic();. calcr(mynumsides, mysidelength);. calcr(mynumsides, mysidelength);. print(); .}// end menu...this is my entire tester class:..public static void main(string[] arg).{. int numsides;. double sidelength;. scanner keyboard = new scanner(system.in);.. system.out.println(""welcome to the regular polygon program!"");. system.out.println();.. system.out.print(""enter the number of sides of the polygon ==> "");. numsides = keyboard.nextint();. system.out.println();.. system.out.print(""enter the side length of each side ==> "");. sidelength = keyboard.nextdouble();. system.out.println();.. regularpolygon shape = new regularpolygon(numsides, sidelength);. shape.menu();.}//end main...for testing it i sent it numsides 4 and sidelength 100.",
"blank code slow skin detection this code changes the color space to lab and using a threshold finds the skin area of an image. but it\'s ridiculously slow. i don\'t know how to make it faster ? ..from colormath.color_objects import *..def skindetection(img, treshold=80, color=[255,20,147]):.. print img.shape. res=img.copy(). for x in range(img.shape[0]):. for y in range(img.shape[1]):. rgbimg=rgbcolor(img[x,y,0],img[x,y,1],img[x,y,2]). labimg=rgbimg.convert_to(\'lab\', debug=false). if (labimg.lab_l > treshold):. res[x,y,:]=color. else: . res[x,y,:]=img[x,y,:].. return res",
"option and validation in blank i want to add a new option on my system where i want to add two text files, both rental.txt and customer.txt. inside each text are id numbers of the customer, the videotape they need and the price...i want to place it as an option on my code. right now i have:...add customer.rent return.view list.search.exit...i want to add this as my sixth option. say for example i ordered a video, it would display the price and would let me confirm the price and if i am going to buy it or not...here is my current code:.. import blank.io.*;. import blank.util.arraylist;. import static blank.lang.system.out;.. public class rentalsystem{. static bufferedreader input = new bufferedreader(new inputstreamreader(system.in));. static file file = new file(""file.txt"");. static arraylist<string> list = new arraylist<string>();. static int rows;.. public static void main(string[] args) throws exception{. introduction();. system.out.print(""nn"");. login();. system.out.print(""nnnnnnnnnnnnnnnnnnnnnn"");. introduction();. string repeat;. do{. loadfile();. system.out.print(""nwhat do you want to do?nn"");. system.out.print(""n - - - - - - - - - - - - - - - - - - - - - - -"");. system.out.print(""nn | 1. add customer | 2. rent return |n"");. system.out.print(""n - - - - - - - - - - - - - - - - - - - - - - -"");. system.out.print(""nn | 3. view list | 4. search |n"");. system.out.print(""n - - - - - - - - - - - - - - - - - - - - - - -"");. system.out.print(""nn | 5. exit |n"");. system.out.print(""n - - - - - - - - - -"");. system.out.print(""nnchoice:"");. int choice = integer.parseint(input.readline());. switch(choice){. case 1:. writedata();. break;. case 2:. rentdata();. break;. case 3:. viewlist();. break;. case 4:. search();. break;. case 5:. system.out.println(""goodbye!"");. system.exit(0);. default:. system.out.print(""invalid choice: "");. break;. }. system.out.print(""ndo another task? [y/n] "");. repeat = input.readline();. }while(repeat.equals(""y""));.. if(repeat!=""y"") system.out.println(""ngoodbye!"");.. }.. public static void writedata() throws exception{. system.out.print(""nname: "");. string cname = input.readline();. system.out.print(""address: "");. string add = input.readline();. system.out.print(""phone no.: "");. string pno = input.readline();. system.out.print(""rental amount: "");. string ramount = input.readline();. system.out.print(""tapenumber: "");. string tno = input.readline();. system.out.print(""title: "");. string title = input.readline();. system.out.print(""date borrowed: "");. string dborrowed = input.readline();. system.out.print(""due date: "");. string ddate = input.readline();. createline(cname, add, pno, ramount,tno, title, dborrowed, ddate);. rentdata();. }.. public static void createline(string name, string address, string phone , string rental, string tapenumber, string title, string borrowed, string due) throws exception{. filewriter fw = new filewriter(file, true);. fw.write(""nname: ""+name + ""naddress: "" + address +""nphone no.: ""+ phone+""nrentalamount: ""+rental+""ntape no.: ""+ tapenumber+""ntitle: ""+ title+""ndate borrowed: ""+borrowed +""ndue date: ""+ due+"":rn"");. fw.close();. }.. public static void loadfile() throws exception{. try{. list.clear();. fileinputstream fstream = new fileinputstream(file);. bufferedreader br = new bufferedreader(new inputstreamreader(fstream));. rows = 0;. while( br.ready()). {. list.add(br.readline());. rows++;. }. br.close();. } catch(exception e){. system.out.println(""list not yet loaded."");. }. }.. public static void viewlist(){. system.out.print(""n~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. system.out.print("" |list of all costumers|"");. system.out.print(""~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. for(int i = 0; i <rows; i++){. system.out.println(list.get(i));. }. }. public static void rentdata()throws exception. { system.out.print(""n~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. system.out.print("" |rent data list|"");. system.out.print(""~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. system.out.print(""nenter customer name: "");. string cname = input.readline();. system.out.print(""date borrowed: "");. string dborrowed = input.readline();. system.out.print(""due date: "");. string ddate = input.readline();. system.out.print(""return date: "");. string rdate = input.readline();. system.out.print(""rent amount: "");. string ramount = input.readline();.. system.out.print(""you pay:""+ramount);... }. public static void search()throws exception. { system.out.print(""n~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. system.out.print("" |search costumers|"");. system.out.print(""~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~"");. system.out.print(""nenter costumer name: "");. string cname = input.readline();. boolean found = false;.. for(int i=0; i < rows; i++){. string temp[] = list.get(i).split("","");.. if(cname.equals(temp[0])){. system.out.println(""search result:nyou are "" + temp[0] + "" from "" + temp[1] + "".""+ temp[2] + "".""+ temp[3] + "".""+ temp[4] + "".""+ temp[5] + "" is "" + temp[6] + "".""+ temp[7] + "" is "" + temp[8] + ""."");. found = true;. }. }.. if(!found){. system.out.print(""no results."");. }.. }.. public static boolean evaluate(string uname, string pass){. if (uname.equals(""admin"")&&pass.equals(""12345"")) return true;. else return false;. }.. public static string login()throws exception{. bufferedreader input=new bufferedreader(new inputstreamreader(system.in));. int counter=0;. do{. system.out.print(""username:"");. string uname =input.readline();. system.out.print(""password:"");. string pass =input.readline();.. boolean accept= evaluate(uname,pass);.. if(accept){. break;. }else{. system.out.println(""incorrect username or password!"");. counter ++;. }. }while(counter<3);.. if(counter !=3) return ""login successful"";. else return ""login failed"";. }. public static void introduction() throws exception{.. system.out.println("" - - - - - - - - - - - - - - - - - - - - - - - - -"");. system.out.println("" ! r e n t a l !"");. system.out.println("" ! ~ ~ ~ ~ ~ ! ================= ! ~ ~ ~ ~ ~ !"");. system.out.println("" ! s y s t e m !"");. system.out.println("" - - - - - - - - - - - - - - - - - - - - - - - - -"");. }..}"
]
export_model.predict(examples)
最后,我们对新样本的预测结果,从结果可以看出第一个样本属于1分类,第二个样本属于3分类,第三个样本属于1分类。
array([[0.07681431, 0.9145267 , 0.00168446, 0.0069745 ],
[0.15425545, 0.15177086, 0.22145462, 0.47251904],
[0.12295637, 0.8690966 , 0.0015018 , 0.00644527]], dtype=float32)