深度学习中的超参数以及两个重要的超参数——学习率和batch_size
前言
在深度学习中有很多参数是我们在训练模型之前自己设定的,我们把这些参数就称为——超参数。其中主要超参数包括了:学习率、batch_size、梯度下降法循环的数量、隐藏层数目、隐藏层单元数目、激活函数的选择等。
1.超参数
2.学习率
3.batch_size
1.超参数
1.1 超参数的选择
如何选择最优的超参数对模型的性能起着非常重要的作用,下面提供了一些常用的选择超参数的方法:
1.猜测和检查:根据经验或直觉,选择参数,一直迭代。
2.网格搜索:让计算机尝试在一定范围内均匀分布的一组值。这是获得良好超参数的最简单方法。它实际上就是暴力解决。
算法:从一组给定的超参数中尝试一堆超参数,看看哪种方法效果最好。
优点:五年级学生都很容易实现,而且可以轻松并行化。
缺点:正如你可能猜到的那样,它的计算成本非常高(因为所有暴力算法都是如此)。
我是否应该使用它:可能不会。网格搜索非常低效。即使你想保持简单,你也最好使用随机搜索。
3.随机搜索:让计算机随机挑选一组值。
正如它的本意,随机搜索。完全随机化。
算法:在一些超参数空间上从均匀分布中尝试一堆随机超参数,看看哪种方法效果最好.
优点:可以轻松并行化。就像网格搜索一样简单,但性能稍好一点,如下图1所示: 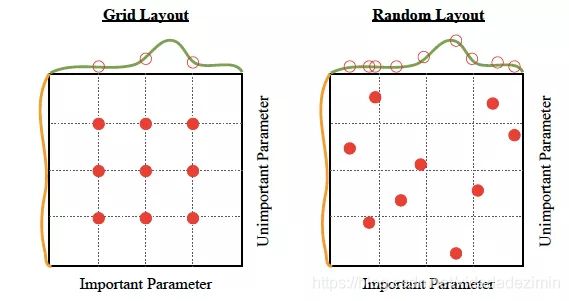
我是否应该使用它:如果琐碎的并行化和简单性是最重要的,那就去吧。但是,如果你愿意花费时间和精力,那么通过使用贝叶斯优化,你的模型效果将大大提升。
4.贝叶斯优化:使用贝叶斯优化超参数,会遇到贝叶斯优化算法本身就需要很多的参数的困难。与我们迄今为止看到的其他方法不同,贝叶斯优化使用了算法的先前迭代的知识。使用网格搜索和随机搜索,每个超参数猜测都是独立的。但是,使用贝叶斯方法,每次我们选择并尝试不同的超参数时,表现都在一点点提升。
算法:贝叶斯方法试图建立一个函数(更准确地说,是关于可能函数的概率分布),用于估计模型对于某个超参数选择的好坏程度。通过使用这种近似函数(也称为代理函数),您不必在设置、训练、评估的循环上花费太多时间,因为你可以优化代理函数的超参数。
优点:贝叶斯优化比网格搜索和随机搜索提供更好的结果。
缺点:并行化并不容易。
我应该使用它吗:在大多数情况下,是的!但是,下列情况例外:
你是一个深度学习专家,你不需要一个微不足道的近似算法帮忙。
你拥有庞大的计算资源,并可以大规模并行化网格搜索和随机搜索。
如果你是一个频率论者/反贝叶斯统计书呆子。
5.在良好初始猜测的前提下进行局部优化:这就是MITIE 的方法,它使用BOBYQA 算法,并有一个精心选择的起始点。
6.论文提出了一种新的LIPO 的全局优化方法。这个方法没有参数,而且经验证比随机搜索方法好。
2.学习率
可以这么说学习率是所有超参数中最重要的一个,选择一个好的学习率不仅可以加快模型的收敛,避免陷入局部最优,减少迭代的次数,同时可以提高模型的进度。下面我们就来说说 学习率。学习率是最重要的超参数,因为它以一种复杂的方式控制着模型的有效容量。如果在有限时间内,想提高模型性能,那么就调它。调其他的超参数需要监视训练和测试误差来判断模型是欠拟合还是过拟合。
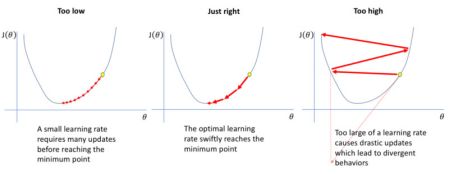
学习率通常高于前 100 次迭代后产生最佳性能的学习率。监视前几次迭代,选择一个比表现最好的学习率更高的学习率,同时注意避免不稳定的情况。如果学习率太高,我们的损失函数将开始在某点来回震荡,不会收敛。如果学习率太小,模型将花费太长时间来收敛,如图2所述。
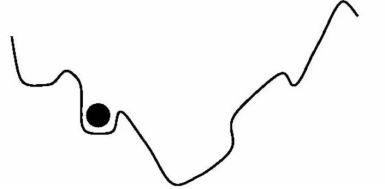
β \beta β。动量:简而言之,动量常数可以被认为是在损失函数表面滚动的球的质量。球越重,下落越快。但如果它太重,它可能会卡住或超过目标。如图3所示。
2.1学习率的设定和选择
选择一个好的学习率在模型的训练中起着非常重要的作用,下面就来说说如何选择和调整一个好的学习率。
越大的网络需要越多的训练,反之亦然。如果你添加了太多的神经元和层数,适当提升你的学习速率。同时学习率需要和训练周期,batch size 大小以及优化方法联系在一起考虑。
学习率的设定:模型训练时另一关键设定便是模型学习率(learning rate),一个理想的学习率会促进模型收敛,而不理想的学习率甚至会直接导致模型直接目标函数损失值“爆炸”无法完成训练。学习率设定时可遵循下列两项原则:
1.模型训练开始时的初始学习率不宜过大,以0.01和0.001为宜;如发现刚开始训练没几个批次(mini-batch)模型目标函数损失值就急剧上升,这便说明模型训练的学习率过大,此时应减小学习率从头训练;
2.模型训练过程中,学习率应随轮数增加而减缓。减缓机制可有不同,一般为如下三种方式:a)轮数减缓(step decay)。如五轮训练后学习率减半. b)指数减缓. c)分数减缓(1/t decay)。
调整学习率:调整学习率很多时候也是行之有效的时段。以下是可供探索的一些想法:
1.实验很大和很小的学习率
2.文献里常见的学习速率值,考察你能学习多深的网络。
3.尝试随周期递减的学习率
4.尝试经过固定周期数后按比例减小的学习率。
5.尝试增加一个动量项(momentum term),然后对学习速率和动量同时进行格点搜索。
3.batch_size
batch_size是超参数中比较重要的参数之一。下面我们将从三个方面来进行叙述。
3.1.为什么需要Batch Size
首先Batch Size决定的是下降的方向。
如果数据集比较小,可采用全数据集的形式,好处是:
1、由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。
2、由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。Full Batch Learning 可以使用Rprop 只基于梯度符号并且针对性单独更新各权值。对于更大的数据集,采用全数据集的形式,坏处是:
1、随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。
2、以Rprop 的方式迭代,会由于各个Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来RMSProp 的妥协方案。
下面来谈谈Batch_size对实验的影响。
3.2调节Batch Size对实验效果的影响
1、Batch_Size 太小,可能导致算法不收敛。
2、随着Batch_Size 增大,处理相同数据量的速度越快。
3、随着Batch_Size 增大,达到相同精度所需要的epoch 数量越来越多。
4、由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5、由于最终收敛精度会陷入不同的局部极值,因此Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
因此batch_size的值不能太大也不能太小,当batch_size慢慢增大到某一个值的时候,模型的性能也会慢慢的增强达到一个峰值,但是,当batch_size在继续增大的时候模型的性能会逐渐下降。并且内存也不能加载那么大的batch_size值。但是,如果batch_size调小的话,就不能充分利用电脑内存,并且小批量的batch_size其下降的方向不能很好代表样本下降的方向。因此,我们要在合理的范围内增加Btach_size的值。
3.3.在合理范围内增大Batch Size的好处
1、内存利用率提高了,大矩阵乘法的并行化效率提高。
2、跑完一次epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
3、在一定范围内,一般来说Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
3.4.Batch_size的设置
batch_size翻译为样本批次容量:影响模型的优化程度和收敛速度,需要参考你的数据集大小来设置,具体问题具体分析;较小的batch_size值让学习过程收敛更快,但是产生更多噪声。较大的值让学习过程收敛较慢,但是准确的估计误差梯度。下面是给出的两个建议:
建议1:batch size 的默认值最好是32或者说是2的幂次方(其实具体的大小可以根据自己的数据量、硬件的好坏来决定。比如:60、80…)。
建议2:调节batch size时,最好观察模型在不同batch size 下的训练时间和验证误差的学习曲线。