Spark SQL优化之路——Hive篇
文章目录
- 前言
- 优化方向
-
- 数据存储结构优化
-
- 分区设计
- 分桶设计
- 数据压缩
- 存储格式
- 数据生产者应注意的事项
- 优化场景
-
- 个别Task运行缓慢
-
- 源端数据倾斜
- 处理过程中的数据倾斜
-
- 不合理的哈系分布
- 大小表Join
- Task数量多
-
- 源数据小文件多
- 写入时小文件多
- 集群带宽以及磁盘I/O压力
-
- 选择压缩算法
- 缓存表
- 写在后面
- 优化原理和手段
-
- Spark运行机制
- Stage和Task分别是如何划分的?
- 为什么是这三个优化方向?
- 为什么小文件快速增长会影响Hadoop的性能和扩展性?
- 为什么小文件多,task也多?
- 怎么确认当前Stage是否在读取数据?
- 怎么查看Task数据分布情况?
- REPARTITION/COALESCE
-
- REPARTITION/COALESCE的区别
- DISTRIBUTE BY/CLUSTER BY
-
- 分析DISTRIBUTE BY的物理执行计划
- 分析CLUSTER BY的物理执行计划
- DISTRIBUTE BY和CLUSTER BY的区别
- 缓存有什么级别?
前言
工作原因,时常接到一些用户关于Spark SQL运行缓慢的问题,总体是上游数据存储不规范,SQL优化不合理,Spark框架优化参数不到位。用户时常问出令我们一时语塞的问题,为什么就几百万条数据,用了(1C4G) * 30的资源量处理了两个小时呢?为什么会内存溢出呢?显然需要具体问题具体分析,但是没给出原因之前,用户只会将责任抛给我们。
大部分问题是用户自身的问题,奈何用户不断向上投诉,不得不解。这也就是总结本文的主要动机。很遗憾,我原只想总结出一些优化建议让用户做些什么,不建议做什么,但最终发现出现性能问题的往往是复杂SQL,而复杂SQL优化是一个系统性的工程,不了解Spark以及Spark SQL原理是无法作出合适的优化决策的,但如果事事俱细,文章又会大且杂,因此本文先抛出结论,如果对原理感兴趣,可以点击各个结论右侧的链接。有些链接是我阅读过认为很棒的文章,以及Spark官网介绍,有些是发现网上文章存在一些模糊的表述,自己阅读源码的总结。
本文基于3.1.2版本的Spark源码。 数仓用户更倾向使用SQL,因此文章更偏向从SQL角度优化(有些可以通过代码优化的方式没有体现),本文针对的是Hive数据源。一些观点是个人总结,比如优化思路,未必能覆盖所有场景,考虑不周,还请指出。
优化方向
Spark SQL性能调优总体区分为三个方向(为什么是这三个优化方向?):
- 数据存储结构优化;
- Spark框架优化;
- SQL优化。
数据存储结构优化
数据存储结构影响了读写的效率,并很大程度上影响整体运行效率。比如Hive不合理的分区,导致读取时数据倾斜,让少部分Spark task承担了大部分数据;小文件数量过多,甚至会出现数十万task的场景(为什么小文件多,task也多?)。在不合理的存储结构定下来后,Spark框架和SQL的调优就变得复杂,且提升空间较少,甚至有可能出现为了调优,使得集群带宽成为瓶颈,因此优先需要考虑数据存储结构。
数据存储结构设计的最终目的是减少大量的目录,以及尽可能地避免产生大量小文件,数据应当尽可能均匀分布,在允许条件下选择合适压缩算法,尽可能使得文件可分割。
分区设计
数据存储结构中,分区设计是相当重要的环节。它应当根据业务查询和处理来设计分区键,理想的分区设计在数据持续增长的情况下,不应该产生太多分区和目录,并且每个目录下的文件应当足够大,一般是文件系统中块大小的数倍,每个分区的数据量均匀分布。
常见解决方案是按天分区、二级分区。常见的二级分区是第一级按天,第二级使用不同的维度,取决于预期的频繁查询SQL。
分桶设计
当分区设计始终无法接近于理想分区时,应考虑分桶存储。考虑这种场景:一级分区按天,二级分区按userId,在用户较多的情况下,会出现很多二级分区。因此可以考虑将userId分桶,同个userId会存到同个桶内,若干个userId会在同个桶内,比如:
# 引用《Hive编程指南》9.6章节
CREATE TABLE demo (user_id STRING, source_ip STRING)
PARTITIONED BY (dt STRING)
CLUSTERED BY (user_id) INTO 96 BUCKETS;
分桶键的值需要足够多且均匀,避免出现hive分桶时哈希取模数据倾斜到若干个桶里。
当我们使用Spark以分桶键进行聚合和连接时,经常出现Shuffle,只要Shuffle不发生明显数据倾斜,运行效率还是会比不分桶造成大量小文件的情况快(一般)。当然,当业务频繁地需要以分桶键进行聚合和连接,并且发生了Shuffle,且处理的数据量较大,就意味着可能会有大量数据在网络上传输,也会导致运行缓慢,当集群带宽已经成为瓶颈,那就应当小心。
数据压缩
压缩和解压自然需要时间,会影响计算效率,但在大数据场景下,也需要重视集群带宽和存储能力,因此需要选择合适的压缩算法。
选择压缩格式需要综合考虑:
- 支持并行计算,如GZIP和Snappy不支持Split,不利于发挥出Spark的并行计算能力;
- 压缩/解压效率,写文件时,期望压缩越快越好;读文件时,期望解压越快越好。各种格式的压缩/解压效率参考这篇文章;
- 压缩比,一般在兼顾上面两点的情况下,选择压缩比高的,一般压缩比为:Snappy
主要根据数据本身的场景选择,比如大文件归档场景,极少用来计算,那么可以考虑采用GZIP和BZIP2;热点数据场景,可以选择不压缩,但当文件比较大的时候,建议压缩,考虑使用LZO。
文章主要面向ETL场景,因此建议使用LZO,但非绝对,要根据实际场景选择压缩算法。
存储格式
Spark针对TextFile没有特别的优化,当小文件过多时,相应地,Task也会多,当无法避免大量小文件时,后续又需要Spark进行处理,那么TextFile不是一个良好的选择(源码分析TextFile格式小文件数量与Task的关系)。
Spark针对ORC和Parquet文件有一定优化。需要根据业务场景选择存储格式。实测读取ORC文件时Task的数量,源码分析Spark读取Parquet格式文件生成的Task数量。
这里做一个小结:
数据生产者应注意的事项
我们处理数据需要与上下游业务制定数据存储规范:
- 不要使用过多的分区:如果指定表分区增长较快,一天增长数百个分区,那么一天就可能增长数万个小文件,影响Hadoop的性能和扩展性(为什么?),Spark不适合处理小文件;
- 数据分区应均匀:数据倾斜影响下游处理效率,小部分Spark task处理大部分的数据;
- 应避免大量小文件:尤其是上游是流计算相关业务时,又或者不合理的join(Spark SQL),可能会输出大量小文件,小文件多会直接导致Spark task数量多,时间耗费在创建和销毁task上;
- 合理的压缩算法,尽可能选择可分割、压缩/解压效率高的,归档大文件场景则使用压缩比高的;
- 合适的存储格式,Spark针对ORC/Parquet格式有优化,能一定程度上避免小文件过多带来的调度开销。
当然,数仓用户了解的优化措施更多,此处只是给出会影响到Spark处理的优化思路。
如果小文件多是既定事实,建议优先通过Hive原生支持合并小文件,再使用Spark处理,或者确认是否能够将数据存储格式转换为ORC/Parquet,Spark针对这两种格式有RDD分区合并上的优化;如果源数据倾斜是既定事实,那么只好从Spark调优参数和SQL去优化。
Spark框架调优和SQL往往是无法分割的,因此这两个优化方向应按整体来看,通过问题场景来分析:
优化场景
优化前的信息收集是关键手段,因此建议不要关闭Spark UI(spark-submit … --conf spark.ui.enabled=true,默认开启),以及开启history server(start-history-server.sh)。
Spark提供了一些调优参数,建议在使用参数时优先查看官网参数说明,目前最新版本是3.1.2,可以看到历史版本的参数。官方文档提供了语法示例,必要时参考。
个别Task运行缓慢
现象很明显,大部分task早已结束,少数task仍在运行。如果是纯SQL的情况,一般是数据倾斜导致的,需要检查源端数据分布情况,以及处理过程中是否造成了数据倾斜;如果是结合业务处理编写代码的情况,那首先要排除掉数据倾斜,再分析业务逻辑中可能出现阻塞/运行缓慢的点,排查这种场景就是具体问题具体分析了。
源端数据倾斜
可以检查读取数据的Stage(怎么确认当前Stage是否在读取数据?)中的Task数据分布情况(怎么查看?),是否出现了明显的倾斜,少部分Task处理了大部分数据,或存在部分Task中处理的数据量过少。
如果源端供数尚能调整,建议调整,调整时应当注意选择的压缩格式应是可分割的,这样在读取大文件场景下,也可以更加合理的分区;如果无法调整,那么就需要采取REPARTITION/COALESCE Hint、DISRTIBUTE BY/CLUSTER BY的方式重分布数据,让数据均匀分布到各个RDD分区上,但要注意不是每个转换都能确保均匀分布,要注意各个转换的区别,合理选择。
如果不采用SQL方式,可以主动对RDD/DataFrame调用repartition/coalesce。
处理过程中的数据倾斜
主要表现在Shuffle时分布不均,根据Stage中的Summer Metrics以及各个Task中的Shuffle Read字段分析(怎么查看?)。
不合理的哈系分布
当数据倾斜到一个分区时,有可能是选择的分布键不合理,尤其是使用HashPartition的转换(有GROUP BY, DISTRIBUTE BY, CLUSTER BY等),Spark通过对分布键哈系取模的方式将数据分发到不同RDD分区。那么此时的优化手段有四种:
- 增加Reduce Task的并行度:SET spark.default.parallelism = 200 (默认值200)以及SET spark.sql.shuffle.partitions = 200;代码方式更直接,如groupByKey(200);
- 选择更合理的分布键(根据数据处理过程来调整);
- REPARTITION到更多分区上,同时注意增大相应的并行度:SET spark.default.parallelism = 200 以及SET spark.sql.shuffle.partitions = 200;
- 通过TableSample确定倾斜的Key,单独取出处理,最后UNION原流程生成的RDD/DataFrame:
/*
TABLESAMPLE ({ integer_expression | decimal_expression } PERCENT)
| TABLESAMPLE ( integer_expression ROWS )
| TABLESAMPLE ( BUCKET integer_expression OUT OF integer_expression )
*/
CACHE TABLE (
SELECT id, COUNT(id) AS count
// 这里我取id计数至少一千
FROM test_table TABLESAMPLE(10 PERCENT)
WHERE count > 1000
GROUP BY id
ORDER BY count
AS sampled
LIMIT 100
) AS sampled;
// 取出倾斜的数据进行单独处理...上边介绍了许多避免倾斜的方式都可以使用了
// 数据处理的语法根据应用场景补充,这里只做个查询演示
// 假设处理完的倾斜数据DataFrame被命名为skew_data
SELECT * FROM test_table JOIN sampled
WHERE test_table.id IN (
SELECT id FROM sampled
);
// 取出没有倾斜的数据进行处理
// 数据处理的语法根据应用场景补充,这里只做个查询演示
// 假设处理完的倾斜数据DataFrame被命名为even_data
SELECT * FROM test_tableWHERE test_table.id NOT IN (
SELECT id FROM sampled
);
INSERT INTO destination
SELECT * FROM even_data
UNION ALL
SELECT * FROM skew_data;
针对代码方式,还可以自定义分区器来自行控制:
val myPartitioner = new Partitioner() {
override def numPartitions: Int = {/*定义分区数*/}
override def getPartition(key: Any): Int = {/*定义分区算法*/}
}
// df.groupByKey(myPartitioner)
// df.partitionBy(myPartitioner)
// ...
还有一种常见的Shuffle数据倾斜的场景是大小表的Join:
大小表Join
大小表Join时,通常会Shuffle把相应Key的打散到不同分区,如果出现小表中某些Key值在大表中占比较大,那么Shuffle就会出现倾斜。最简单的方法是将小表的数据广播到各个计算节点上,避免了Shuffle:
// 当小于该值,那么小表会被广播到各个计算节点上,默认10MB,这里调到了100MB
SET spark.sql.autoBroadcastJoinThreshold = 100
这种方式适用两张表数据量相差较大的情况,以及小表需要足够小,能放入计算节点的内存中,同时出现了数据倾斜才适用。
Task数量多
Task数量较多目前没有发现一个统一的量化标准,所有stage中最多的task数量≈数据总量/HDFS BLOCK SIZE 是最优的,个人认为当出现所有stage中最多的task数量远大于该值(>=2个数量级)的便视作不合理,又或Task调度的总开销占比很高时,也是不合理的。比如数据量仅20+G,但task数量有80+万,这显然不合理。
task数量过多,一般是小文件多或处理过程中不合理的分区。
源数据小文件多
如果表结构是TextFile格式通过Hive原生的小文件合并规避后,再用Spark处理。Spark没有可以调优的参数。
如果表结构是ORC/Parquet格式,那么通过是可以通过参数来优化的:
// 打开小文件的估计成本,文件大小低于该值时,将合并到同个RDD分区,因此可以适当提高该值来合并小文件
SET spark.files.openCostInBytes = 4194304
// 单RDD分区的最大字节数,一般不做调整,这里是默认值128MB
SET spark.files.maxPartitionBytes = 134217728
// 使用Spark内建的reader和writer读写ORC,这里是默认值
SET spark.sql.hive.convertMetastoreOrc = true
// 使用Spark内建的reader和writer读写Parquet,这里是默认值
SET spark.sql.hive.convertMetastoreParquet = true
写入时小文件多
写入前RDD有分区数量为M,每个分区下Task的数量为N,那么 输 出 小 文 件 数 量 = ∑ i = 0 M N 输出小文件数量=\sum_{i=0}^MN 输出小文件数量=i=0∑MN
此时如果源数据源小文件本就多,那输出的小文件数量也就多了,因此需要在读取源数据源后做个重分区,见上一小节。
如果在处理过程中,RDD分区变得较多,那么可以尝试通过REPARTITION/COALESCE Hint、DISRTIBUTE BY/CLUSTER BY的方式重分布数据,减少RDD数量。
集群带宽以及磁盘I/O压力
Shuffle以及Broadcast是有网络和磁盘I/O开销的, 不论带宽还是磁盘I/O效率成为瓶颈是可预见性的还是已成为事实,在大数据场景,带宽和磁盘读写效率是不易调整的资源,我们都要有意识地避免不必要的Shuffle和过多的Broadcast。这是需要读者了解各个转换的原理,具体问题具体分析,比如调整SQL或代码,将一些转换置换下顺序,减少Shuffle。
选择压缩算法
还有一个有效的手段,那就是开启Shuffle读写的压缩,针对不同格式,可选的压缩算法不同:
- JSON: none(默认), bzip2, gzip, lz4, snappy, deflate;
- Parquet: none, snappy(默认), gzip, lzo
- ORC: none, snappy(默认), zlib, lzo
- TEXT: none(默认), bzip2, gzip, lz4, snappy , deflate
一般选择压缩/解压效率高的。如果是归档大文件,考虑使用压缩比高的:
// 以下均为默认值
SET spark.shuffle.compress = true
SET spark.broadcast.compress = true
SET spark.io.compression.codec = lz4
缓存表
当针对同个数据源有多个转换操作,那么在最后的ACTION时,就会生成多个Job,每个Job又从源DataFrame/RDD上重新计算一遍。为了避免读取数据源时带来的不必要重复开销,可以对重复处理的结果进行缓存:
/* CACHE [ LAZY ] TABLE table_identifier
[ OPTIONS ( 'storageLevel' [ = ] value ) ] [ [ AS ] query ]
*/
CACHE TABLE SELECT * FROM test;
但要注意避免缓存大表。
写在后面
优化是阶段,不是结果,没有绝对一劳永逸的优化。在日常跑批的过程中,一些优化手法适用,但在特定场景,这些手法反而是负优化也时常有之。考虑这种场景:按天分区,在日常可能是适用的,双十一数据激增,此前的优化又是否适用呢?
到这里,本文就完了,后面的优化原理选读。
优化原理和手段
选读。
Spark运行机制
优化的前提是理解Spark运行机制(如果是第一次接触Spark,建议优先阅读
子雨大数据之Spark入门教程(Scala版))。回忆一下Spark运行时的架构分为:
- Driver: 指Driver节点,运行在客户端中或者集群中,控制应用的执行,SparkContext负责与集群管理器进行交互,集群管理器可以是Spark自带的standalong集群管理器,也可以是Spark官方推荐的Mesos,也可以是YARN。SparkContext负责将用户程序转换为多个物理执行的单元,即Task。
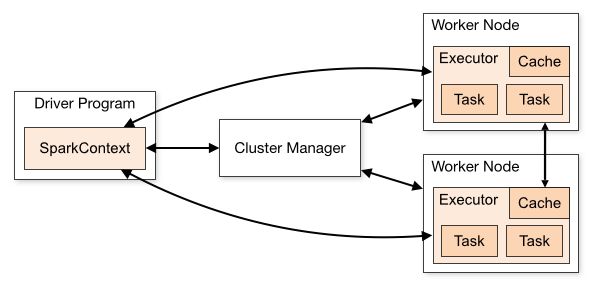
- Application: 应用,也就是我们需要提交执行的计算程序。每个提交的应用是相互隔离的,互不影响的。
- Job: Job是一组Stage的集合,当程序中出现一次Action操作时,就会提交一个Job,一个Job会有若干个Stage。
- Stage: 一个Job会有若干个Stage(Stage是如何划分的?),Stage的划分依据即有无出现shuffle,常见的可能出现shuffle的有groupByKey等聚合操作和join连接(不是所有join都会shuffle)操作等,不存在依赖的Stage可并行执行,存在依赖的Stage按序串行执行。
- Task: 发送给Executor的运行单元,是真正执行数据处理的单元,同个Stage内的Task可以并行执行(Task是如何划分的?)。
- Worker: 实际是集群管理器的概念,可以运行任意应用的节点。
- Executor: 执行Task的进程,运行在Worker上。
做一个小结,SparkContext负责提交的Application分解出若干个Job,Application中每个Action操作都会触发生成一个Job,每个Job中有若干个的Stage(网上有些文章将Job表述为多组Task的集合,忽略了Stage,这么表述可以但不准确,应该加上说明各组Task之间在什么情况下可以并行计算),Stage由Task组成,Stage中的Task是可并行计算的。
Stage和Task分别是如何划分的?
在此之前,起码得了解RDD的概念。总结下来,RDD(resilient distributed dataset )是一种可并行计算的、只读的内存模型。RDD中存在分区,每个分区就是一组可被并行计算的数据,即一个RDD分区就对应了一个Task。
RDD被设计为只读,因此在计算过程中不会修改原来的RDD,而是基于原RDD创建出一个新的RDD。从原RDD创建新RDD的过程被称为转换(Transform)过程,转换是懒加载的,并不是代码执行到转换时,就立即触发计算,它是在构建RDD的血缘关系,构建出一个血缘的有向无环图(DAG),只有在触发Action时,才会根据RDD血缘关系真正地触发计算。基于这种血缘设计,RDD具有良好的容错性,在处理过程中意外丢失某些分区数据时,可以根据RDD的血缘关系重新计算丢失分区的数据,而不是重新计算所有数据。
所有的Transformer和Action见官网说明。
讲了这么多,主要是要引入RDD的转换机制。RDD的不同转换操作会在RDD上构建两类血缘关系,一个是窄依赖,一个是宽依赖。
判别宽窄依赖的依据是:
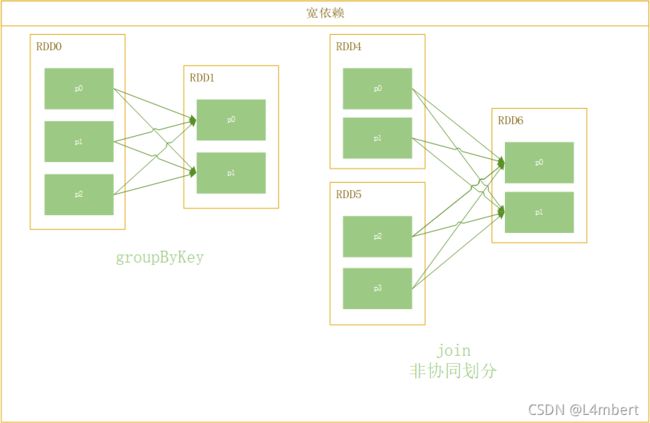
- 宽依赖(Wide Dependency): 父RDD的一个分区分布到子RDD的多个分区上:
- 窄依赖(Narrow Dependency): 父RDD的一个分区只会分布到子RDD的一个分区上:
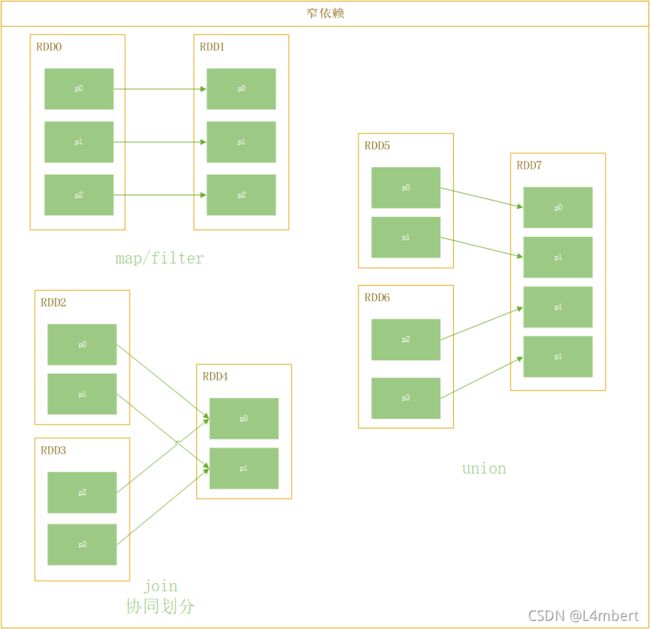
上面两张图中,join可以出现宽依赖也可以出现窄依赖,区别就在于join是否在协同划分。协同划分也就是多个父RDD的某一分区的所有分区键落在子RDD的同一个分区内。
Stage的划分依据就是出现了宽依赖。当发生宽依赖时,父RDD一个分区内的数据需要shuffle到子RDD的多个分区内,而我们知道RDD一个分区对应一个Task,Task是并行计算的,因此这里子RDD的各个分区需要等待来自父RDD不同分区的数据完全处理并传输中间结果到子RDD目标分区,才能继续向下执行该子RDD的计算。
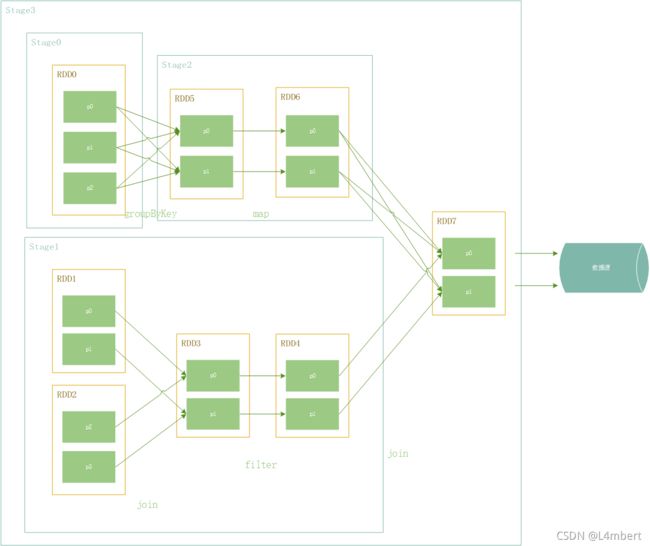
Spark通过血缘关系的DAG图反向解析出Stage,出现宽依赖就分Stage,存在依赖的Stage之间串行执行,不存在依赖的Stage可以并行执行,如下图的Stage0和Stage2串行执行,Stage3和Stage1/2串行执行,Stage0和Stage1可以并行执行。
了解了Stage的划分,就会发现对shuffle的调优是需要重点关注的,比如:
- 避免不合理的shuffle让数据处理尽可能以管道的方式进行,减少数据在I/0上消耗;
- 当资源足够时,可以主动地将数据shuffle到更多分区,获得更大的并行度,提高运行效率。
为什么是这三个优化方向?
数据从源到目标,就是读取、加工和写入这三个步骤。
影响读取和写入的因素有:
- 本身数据源的读写上限——不考虑
- 磁盘和网络I/O——不考虑
- 数据的存储结构:直接影响读写效率,以及会影响task的数量
影响加工的则有:
- Spark框架处理效率,框架调优参数
- SQL优化:不合理的SQL,会导致出现大量的stage/task,甚至输出大量的小文件,影响下游业务;
- 数据的存储结构:数据分布不合理,导致数据倾斜,小部分task承担大部分数据
因此从这三个优化方向出发。
为什么小文件快速增长会影响Hadoop的性能和扩展性?
Hadoop NameNode必须将所有的系统文件的元数据存储在内存中,小文件快速增长会将内存用尽。更多的文件,可能会带来更多的读取请求,导致NameNode的高负载。详情参考这篇文章。
为什么小文件多,task也多?
Spark读取Hive文件时会针对文件进行分片,分片逻辑只会对文件越分越细,分片对应着RDD分区,而RDD分区又和task一一对应,因此小文件多,task也多。从目前实践上看,一个小文件对应一个task。源码分析见这篇文章。
TextFile格式的小文件多没有有效的优化手法,因为读取数据源的task是无法优化减少的!尽管通过repartition,也只能减少下个stage中task数量!
但是Spark针对ORC和Parquet格式的分区有一定优化。我验证了ORC格式的,见这篇文章,针对Parquet格式的源码分析见这篇文章
怎么确认当前Stage是否在读取数据?
在Spark UI/History Server上查看该应用特定Job下的Stage,如果Stage很多的情况,根据SQL/代码初步确认stage应该在第几个,依次点进Stage查看其DAG图,一般DAG图的右上角会提示如Scan hive $schema $tablename。也可以通过DAG图根节点为HadoopRDD或FileScanRDD(如果代码指定jdbc方式连接,那么为JdbcRDD)确认。
HadoopRDD示例:
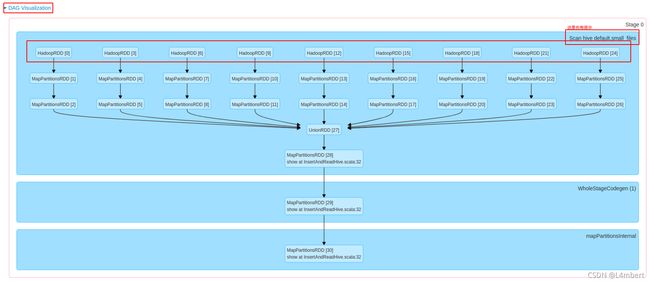
FileScanRDD示例:

怎么查看Task数据分布情况?
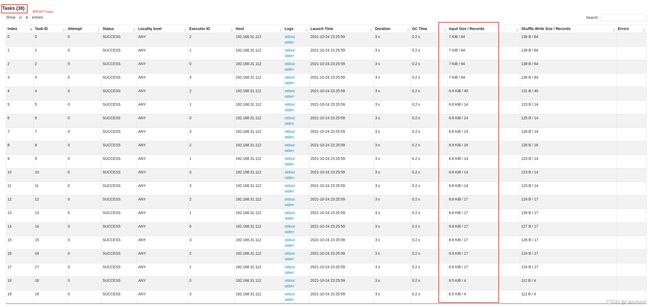
应注意,查看的字段并不是每个阶段都有,比如在读取数据阶段时才有Input Size/Records:
- 查看Summary Metrics,Input Size/Records中Max-Min的差值,如果差值大,则说明出现了数据倾斜。同时要结合75分位的数值,这说明有75%Task读取的最小数据量,如果它和Max很接近,那说明只有少部分Task没有合理分配:

- 查看各Task的Input SIze/Records,很直观地确认数据倾斜情况的:
- 查看Task的Shuffle Read情况,可以在Summary Metrics上对比Max-Min的差值,也可以查看各Task的Shuffle Read值,图表位置和判断方法与上述两点一致。
REPARTITION/COALESCE
SELECT /*+ REPARTITION(2) */ * from small_files;
# INSERT ... SELECT /*+ COALESCE(numPartitions) */ ...
# INSERT ... SELECT /*+ REPARTITION(numPartitions) */ ...
查看上述SQL的物理计划可知,REPARTITION分布实现是Exchange RoundRobinPartition(2),轮询分布到两个分区上,因此REPARTITION是可以保证数据均匀分布:
+- Exchange RoundRobinPartitioning(2), REPARTITION_WITH_NUM, [id=#17]
+- *(1) ColumnarToRow
+- FileScan orc default.small_files_orc[id#0,name#1,addr#2,date#3] Batched: true, DataFilters: [], Format: ORC, Location: CatalogFileIndex[hdfs://lambert:9000/user/hive/warehouse/small_files_orc], PartitionFilters: [], PushedFilters: [], ReadSchema: struct
REPARTITION/COALESCE Hint更多详见SPARK-24940,这个特性在Spark2.4.0开始支持。
REPARTITION/COALESCE的区别
在源码层面就可以看出,二者区别只是是否Shuffle。COALESCE实现是不会Shuffle的,就意味着数据不会再分布到更多的计算节点上:
def coalesce(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = false, logicalPlan)
}
def repartition(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = true, logicalPlan)
}
如果COALESCE的指定分区数量<计算节点的数量,根据Spark调度的本地性,那么就很有可能出现部分计算节点(Executor)空跑的情况,有或者数据分布到少数RDD分区上,导致OOM问题;如果选择REPARTITION,允许Shuffle,是可以让所有的计算节点在跑,最终Shuffle到同个节点上。
但在并不意味着,我们只能使用REPARTITION,REPARTITION在Shuffle时是有I/O开销的,当I/O开销较大时,可以考虑COALESCE。
使用COALESCE是需要考虑节点数量的,如果RDD分区数量为M,需要重分区/合并到N个分区上,当:
- M <= N时,不开启Shuffle的COALESCE是无效的,因为它只会合并分区,无法将数据再分发到其他分区上,REPARTITION则会将数据均匀分布到N个分区上,这能有效解决数据倾斜问题;
- N < M时,此时应当关注节点数量与N的关系,如果节点数量<=N,那么不Shuffle的COALESCE一般效率会更高些;如果N < 节点数量,那么COALESCE会导致(节点数量 - N)个节点空跑,应使用REPARTITION。
DISTRIBUTE BY/CLUSTER BY
还有别的方式吗?当然有,Spark SQL有DISTRIBUTE BY/CLUSTER BY的特性,同样可以用来优化读取小文件问题。
# 分区数量
SET spark.sql.shuffle.partitions = 2
SELECT * FROM small_files_orc DISTRIBUTE BY id
SELECT * FROM small_files_orc CLUSTER BY id
选择的分布键应当遵循以下两点:
- 保证数据均匀分布;
- 不会导致过多的RDD分区。
分析DISTRIBUTE BY的物理执行计划
查看上述SQL的物理执行计划可以发现,相比没有DISTRIBUTE BY,其计划多了hashpartitioning(id#0, 2)重分布,将数据根据id哈系取模分布到2个分区上:
== Physical Plan ==
Exchange hashpartitioning(id#0, 2), REPARTITION, [id=#12]
+- *(1) ColumnarToRow
+- FileScan orc default.small_files_orc[id#0,name#1,addr#2,date#3] Batched: true, DataFilters: [], Format: ORC, Location: CatalogFileIndex[hdfs://lambert:9000/user/hive/warehouse/small_files_orc], PartitionFilters: [], PushedFilters: [], ReadSchema: struct
重分布出现数据倾斜时,查看物理执行计划是看不出来问题的,需要在运行起来之后查看Spark UI/Spark history server,比如由于我造的数据的id全部为123,可以发现分布后的数据都分配到了1个RDD分区上,只有1个Task:
DAG图上只有1个RDD分区:
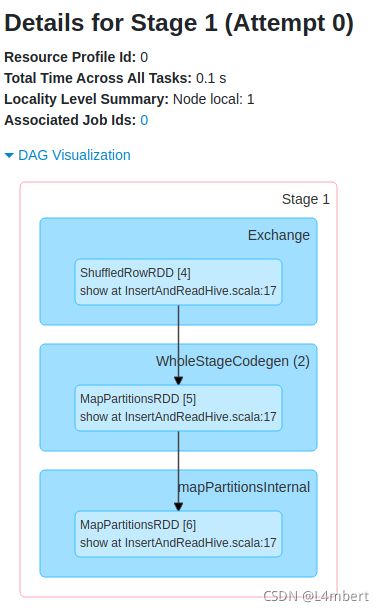
Task相应地也只有1个:

那有什么方法解决呢?有的,加上随机数作为分布键:
# 分区数量
SET spark.sql.shuffle.partitions = 2
SELECT * FROM small_files_orc DISTRIBUTE BY id, rand()
这种方式就像给id加了个随机后缀,那么哈系取模后数据自然会均匀分布。
分析CLUSTER BY的物理执行计划
可以看到,相比DISTRIBUTE BY而言,只是多了一个Sort的计划:
== Physical Plan ==
*(2) Sort [id#10 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#10, 2), REPARTITION, [id=#20]
+- *(1) ColumnarToRow
+- FileScan orc default.small_files_orc[id#10,name#11,addr#12,date#13] Batched: true, DataFilters: [], Format: ORC, Location: CatalogFileIndex[hdfs://lambert:9000/user/hive/warehouse/small_files_orc], PartitionFilters: [], PushedFilters: [], ReadSchema: struct
CLUSTER BY时出现数据倾斜的处理方法和DISTRIBUTE BY一样,不再赘述。
DISTRIBUTE BY和CLUSTER BY的区别
有个很简单的公式可以概括:CLUSTER BY = DISTRIBUTE BY + SORT BY。
当需要对数据进行重分布,并且在每个RDD分区内保证有序,那么可以使用DISTRIBUTE BY + SORT BY结合的方式:
SET spark.sql.shuffle.partitions = 2
SELECT * FROM small_files_orc DISTRIBUTE BY id SORT BY id
更简洁的方式是直接使用CLUSTER BY。但要注意SORT是有开销的,不要滥用CLUSTER BY。
缓存有什么级别?
- NONE: 不使用缓存;
- DISK_ONLY: 缓存到磁盘上;
- DISK_ONLY_2: 缓存到磁盘上,2备份;
- DISK_ONLY_3: 缓存在磁盘上,3备份;
- MEMORY_ONLY: 缓存在内存中;
- MEMORY_ONLY_2: 缓存在内存中,2备份;
- MEMORY_ONLY_SER: 缓存在内存中,数据序列化存储;
- MEMORY_ONLY_SER_2: 缓存在内存中,数据序列化存储,2备份;
- MEMORY_AND_DISK: 默认,缓存在内存和磁盘上,在内存无法存储时,则将超出部分写到磁盘;
- MEMORY_AND_DISK_2: 缓存在内存和磁盘上,各2备份;
- MEMORY_AND_DISK_SER: 缓存在内存和磁盘上,数据序列化存储;
- MEMORY_AND_DISK_SER_2: 缓存在内存和磁盘上,数据序列化存储,各2备份;
- OFF_HEAP: 类似MEMORY_ONLY,但使用的是堆外内存。
使用空间以及效率参考这篇文章。