DL2: A Deep Learning-Driven Scheduler for Deep Learning Clusters(论文笔记)
文章目录
- 问题
- 概述
-
- 深度学习集群
- DL2调度器
- 学习
-
- 策略神经网络
-
- 状态State
- 动作Action
- NN架构
- 离线监督学习
- 在线强化学习
-
- 奖励Reward
- Policy Gradient-Based Learning
- Actor-Critic
- Job-Aware Exporation
- 经历重放
- 弹性缩放
-
- 加入PS
- 加入worker
问题
在一个共享深度学习集群中,会有许多训练任务同时执行。此时,为了更好的利用昂贵的资源和加速训练过程,高效的资源调度是至关重要的。
这篇文章提出了一种基于深度强化学习(DRL)的集群调度器,自动化学习调度策略,弹性地调整训练任务的资源分配,以适应工作负载的变化和机器学习框架的不同实现。
概述
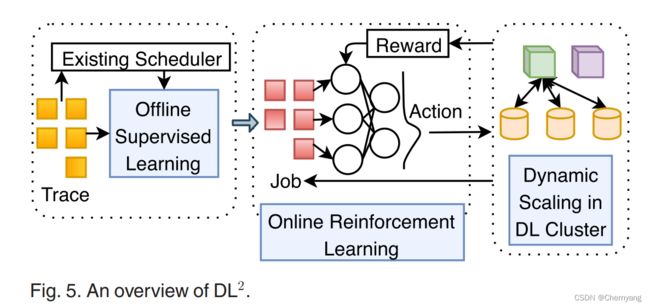
DL2目标是找到最佳的资源调度策略,最小化所有并发任务的平均完成时间。
深度学习集群
在具有多个GPU服务器的DL集群中,DL训练作业是随着时间的推移而提交的。在提交作业时,用户,即作业所有者,提供运行worker和PS的资源需求,以及要运行的训练回合的总数量。例如,一个worker通常需要至少1个GPU,而一个PS需要许多CPU核。实现模型收敛的总训练回合数可以根据专家知识或历史数据来估计。
根据资源的可用性和训练速度,每项任务可以在不同的时间片运行不同数量的worker和PS(由调度器决定)。
DL2调度器
- 离线监督学习:在热身阶段,使用监督学习来训练策略神经网络(NN),以初始化调度策略。从集群中收集到的历史任务运行轨迹被用来训练NN,使其产生与现有调度器类似的决策。由于直接应用在线RL的性能不佳,这一步是必须的。
- 在线强化学习:在线RL以划分时间片的方式工作;每个时间片是一个调度间隔,例如1小时。在一个调度区间的开始,策略NN将所有并发作业的信息作为输入状态,并产生每个作业的worker和PS的数量。在每个时间片结束时观察任务的训练进度,并将其作为奖励来改进策略网络。
- 动态调整:每个任务可能需要根据每个时间片中的策略NN的决定来调整资源。为了支持在训练过程中动态地添加或删除PS/workers,在一个ML框架(MXNet)中设计并实现了动态缩放。它在保证训练正确性的同时,最大限度地减少了资源扩展的开销。
学习
策略神经网络
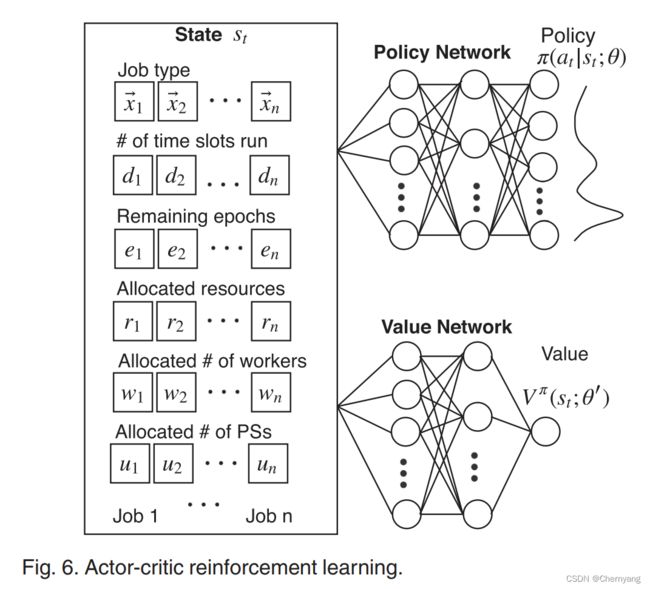
状态State
输入状态是一个矩阵 s = ( x , d → , e → , r → , w → , u → ) s=(\bold x, \overrightarrow{d}, \overrightarrow{e}, \overrightarrow{r}, \overrightarrow{w}, \overrightarrow{u}) s=(x,d,e,r,w,u)。
- x \bold x x是一个 J × L J\times L J×L的矩阵,代表训练的深度学习模型。J是在一个时间片中运行并发任务数量的上界,L是集群中训练任务类型的最大数量。具有相似DNN架构的深度学习任务被认为是同样的类型。每个行向量,表示这个任务的类型编码。
- d → \overrightarrow{d} d是一个J维的向量,表示每个任务已经运行的时间片的数量。
- e → \overrightarrow{e} e是一个J维的向量,表示每个任务需要的剩余训练回合数。它是用户指定的总的训练回合数与目前已经训练的回合数的差值。
- r → \overrightarrow{r} r是一个J维的向量,代表在当前时间片中已经分配给每个任务的主导资源比例。(在此时间片,通过模型推断得出)
- w → , u → \overrightarrow{w}, \overrightarrow{u} w,u也是J维的向量,分别代表分配的worker和PS的数量。
动作Action
NN产生策略 π : π ( a ∣ s ; θ → ) → [ 0 , 1 ] \pi:\pi(a|s;\overrightarrow{\theta})\rightarrow[0,1] π:π(a∣s;θ)→[0,1],是动作空间的概率分布。其中a表示动作, θ → \overrightarrow{\theta} θ是NN的目前的参数集合(即隐藏层的权重)。
动作共有 3 × J + 1 3\times J+1 3×J+1个,分成四类:
- (i, 0),意思是给任务i分配一个worker
- (i, 1),意思是给任务i分配一个PS
- (i, 2),意思是给任务i分配一个worker和PS
- void,即停止分配资源(分配更多的资源不一定会加速训练)
由于每次推断只增加一个PS或worker,此文在每个时间片允许执行多次推断来产生完整的资源分配策略。具体流程是:在产生一个动作后,更新状态s,然后使用NN继续产生下一个动作,直到资源被用尽或void动作被产生。
NN架构
输入的状态矩阵s被连接到一个全连接层,用ReLU函数进行激活。连接到的隐藏层大小与状态矩阵s大小成正比。然后隐藏层再连接到一个全连接层,使用softmax作为激活函数得到最终的策略结果。
离线监督学习
在离线监督学习中,使用随机梯度下降法(SGD)来更新策略NN的参数 θ → \overrightarrow{\theta} θ,以最小化损失函数,该函数是NN做出的资源分配决定和现有调度器的决定的交叉熵[35]。使用跟踪数据反复训练NN,例如在我们的实验中,重复训练数百次,这样NN产生的策略就会收敛到现有调度器的策略。
在线强化学习
奖励Reward
每个时间片获得一个奖励。奖励为,在此时间片上,所有任务被训练的标准回合数。其中,任务i的标准回合数是指这个时间片上任务i训练的回合数( t i t_i ti)除以总的回合数( E i E_i Ei)。下图表示t时间片的奖励:

Policy Gradient-Based Learning
由离线监督学习得到的策略NN,需要继续使用强化学习算法进行训练,以最大化期望累计折扣奖励( E [ ∑ t = 0 ∞ γ t r t ] E[\sum_{t=0}^{\infin}\gamma ^t r_t] E[∑t=0∞γtrt]),其中 γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ∈(0,1)是折扣因子。算法对 E [ ∑ t = 0 ∞ − γ t r t ] E[\sum_{t=0}^{\infin}-\gamma ^t r_t] E[∑t=0∞−γtrt]执行SGD,更新策略网络的参数 θ → \overrightarrow{\theta} θ。梯度是:

其中,Q值是RL奖励反馈,即在特定状态s下按照政策 π \pi π采取的行动a的“质量”,即为在状态s下按照 π \pi π选择行动a后获得的预期累积折现奖励。
在一个时间片上,所有的推断都被执行后,再观察奖励,更新NN。
Actor-Critic
使用Actor-Critic算法提升Policy Gradient-Based Learning,加快收敛速度。
基本思想是替换公式(2)中Q值为一个advantage: Q ( a , s ; θ → ) − V π ( s , θ → ) Q(a,s;\overrightarrow{\theta})-V^{\pi}(s, \overrightarrow{\theta}) Q(a,s;θ)−Vπ(s,θ)。其中 V π ( s , θ → ) V^{\pi}(s, \overrightarrow{\theta}) Vπ(s,θ)是一个value函数,表示策略 π \pi π产生的动作上的期望奖励。
这个advantage表示了,与期望奖励相比,一个特定的动作有多好。使用advantage的目的是减少梯度方差,使策略学习更加稳定。
value函数的值通过一个value网络评估,其和策略网络的结构一样,除了最后的输出层没有任何激活函数,而是产生 V π ( s , θ → ) V^{\pi}(s, \overrightarrow{\theta}) Vπ(s,θ)的估计。
Job-Aware Exporation
为了通过RL获得一个好的策略,我们需要确保行动空间得到充分的探索(即可以充分产生导致好的奖励的行动);否则,RL很可能收敛到差的局部最优策略。我们首先采用一种常用的熵探索方法,在梯度计算中加入熵正则化项( β ▽ θ → H ( π ( ⋅ ∣ s ; θ → ) ) \beta\triangledown_{\overrightarrow{\theta}}H(\pi(\cdot|s;\overrightarrow{\theta})) β▽θH(π(⋅∣s;θ)))来更新策略网络。通过这种方式,策略网络的参数被向更高熵的方向更新(意味着探索更多的行动空间)。
经历重放
为了缓解观察到的样本序列中的相关性,我们在actor-critic框架中采用了经历重放[38]。具体来说,我们维护一个重放缓冲区来存储从大时间跨度中收集的样本。在每个时间片结束时,我们从重放缓冲区中选择一小批样本来计算梯度更新,而不是使用在这个时间片内收集的所有样本。训练的样本可能来自以前的多个时间段。
弹性缩放
一般的checkpoint方法非常耗时,需要停止训练,然后重新开始训练,通常需要几分钟的时间。另一种方法就是在不停止训练的情况下,调整资源。
此文添加了一个协调器,处理worker和PS的加入和删除。
加入PS
加入一个PS的具体过程如下:
注册:
当一个新的PS被启动时,它通过发送 “INC_SERVER”请求消息向协调器注册自己。然后,PS将收到它在任务中的ID,它负责维护的全局参数,以及当前要建立连接的工作者和PS的列表。之后,PS开始运作,等待worker的参数更新和协调者的进一步指示(例如,参数迁移)。
参数分配:
收到注册请求后,协调器会更新其worker和PS的列表,并计算分配给新的PS的参数。采用最佳匹配算法:将每个现有PS上的部分参数移到新的PS上,使所有PS保持几乎相同的参数数量,同时尽量减少参数在PS间的移动。为了在PS之间迁移参数时,保持全局模型参数拷贝的正确和一致(即参数的数量和值不受缩放的影响),我们为参数保持一个版本计数器。对于PS来说,版本计数器是参数更新的数量;对于worker来说,版本计数器是在拉回更新参数时从PS那里收到的。为了决定PS何时应该迁移参数,我们根据当前的版本计数器和协调器与PS/worker之间的往返时间计算出一个缩放时钟。
协调器向所有PS和worker发送缩放时钟和新的参数分配方案。
参数迁移:
在每个PS上,当参数的版本计数器达到来自协调器的缩放时钟时,PS根据收到的参数分配决定,将其参数转移到新的PS。一旦所有PS之间的参数迁移完成,协调者就会通知所有worker恢复训练。
worker更新信息:
对于每个worker,一旦其版本计数器等于从协调者那里收到的缩放时钟,工作者就会暂停其参数更新,等待参数迁移完成的通知。在收到协调器的通知后,工作者更新其参数-PS映射,与新的PS建立连接,并恢复训练。
流程图如下:
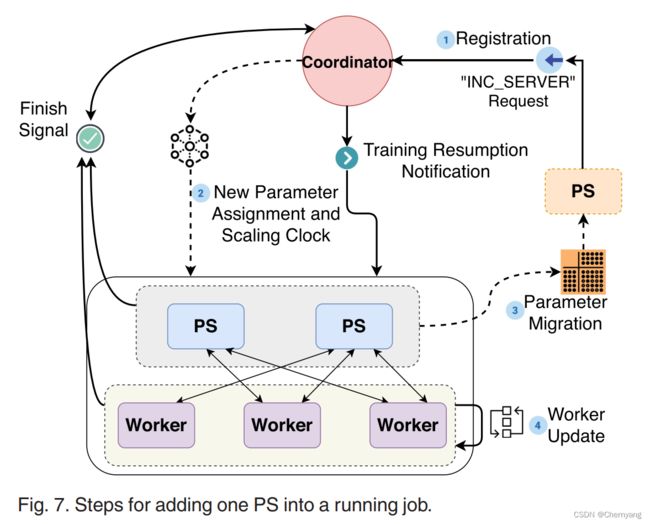
移除PS的过程与之相似。
加入worker
要在现有任务中添加一个新的worker,协调器在响应worker的注册消息时,会发送当前参数-PS映射。它还通知所有的PS以建立连接。训练数据集被复制后,worker开始操作。
移除worker的过程与之相似。