概率论与数理统计学习:数字特征(一)——知识总结与C语言实现案例
hello,大家好
这里是第十期的概率论与数理统计的学习,我将用这篇博客去总结知识点和用C语言实现案例的过程。

本期知识点——期望
- 离散型随机变量的期望
- 连续型随机变量的期望
- 随机变量函数的期望
- 期望的性质
期望的引入
随机变量的分布函数是对随机变量概率性质的完整的刻画,描述了随机变量的统计规律性。
但在实际问题中有时不容易确定随机变量的分布,也没那个必要,而我们只需要知道它的某些特征就行了。这些特征就是随机变量的数字特征,是由随机变量的分布所决定的常数。
例如,对一射手进行技术评定时,经常考察射击命中环数的平均值;检查一批棉花的质量时,所关心的是棉花纤维的平均长度等。也就是我们不需要了解一批东西全部的情况,那样太费时间,效率不高,而通过平均值就能看出一个整体的大概情况。这个平均值就是数学期望,简称为期望
下面开始知识总结
知识总结
☁️ 离散型随机变量的期望
定义:设离散型随机变量的概率分布为 P { X = x i } = p i i = 1 , 2 , . . . P\{X=x_{i}\}=p_{i}~~~~~~~~i=1,2,... P{X=xi}=pi i=1,2,...
若级数 ∑ i x i p i \displaystyle\sum_{i}x_{i}p_{i} i∑xipi绝对收敛,即 ∑ i ∣ x i ∣ p i \displaystyle\sum_{i}|x_{i}|p_{i} i∑∣xi∣pi收敛,则称 ∑ i x i p i \displaystyle\sum_{i}x_{i}p_{i} i∑xipi为随机变量 X X X的期望,记为 E ( X ) E(X) E(X)。即 E ( X ) = ∑ i x i p i E(X)=\displaystyle\sum_{i}x_{i}p_{i} E(X)=i∑xipi
为什么要保证那个级数绝对收敛?
在 X X X可列无限个值时,级数 ∑ i x i p i \displaystyle\sum_{i}x_{i}p_{i} i∑xipi绝对收敛可以保证级数之值不因级数各项次序的改排而变化,这样 E ( X ) E(X) E(X)与 X X X取的值的人为排列次序无关。
如何理解期望和均值?
期望的定义就是随机变量 X X X的值乘上它表示的事件发生的概率。所以将 E ( X ) E(X) E(X)成为 X X X的均值更能反应这个概念的本质。
下面介绍几种常用的离散型随机变量的期望,后续都会用C语言实现
☀️ 两点分布
| X | 1 | 0 |
|---|---|---|
| P | p | 1-p |
E ( X ) = 1 × p + 0 × ( 1 − p ) = p E(X)=1\times p+0\times (1-p)=p E(X)=1×p+0×(1−p)=p
☀️ 二项分布
设 X X X~ B ( n , p ) B(n,p) B(n,p),概率分布为 P { X = k } = C n k p k ( 1 − p ) n − k k = 0 , 1 , 2 , . . . , n P\{X=k\}=C_{n}^kp^k(1-p)^{n-k}~~~~~~~~~k=0,1,2,...,n P{X=k}=Cnkpk(1−p)n−k k=0,1,2,...,n
E ( X ) = n p E(X)=np E(X)=np
☀️ 泊松分布
设 X X X~ P ( λ ) P(\lambda) P(λ),概率分布为 P { X = k } = λ k k ! e − λ k = 0 , 1 , 2 , . . . P\{X=k\}=\frac{\lambda^{k}}{k!}e^{-\lambda}~~~~~~~k=0,1,2,... P{X=k}=k!λke−λ k=0,1,2,...
E ( X ) = λ E(X)=\lambda E(X)=λ
☁️ 连续型随机变量的期望
定义:设连续型随机变量 X X X的概率密度函数为 f ( x ) f(x) f(x),若积分 ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty}xf(x)dx ∫−∞+∞xf(x)dx绝对收敛,即 ∫ − ∞ + ∞ ∣ x ∣ f ( x ) d x \int_{-\infty}^{+\infty}|x|f(x)dx ∫−∞+∞∣x∣f(x)dx收敛,则称积分 ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty}xf(x)dx ∫−∞+∞xf(x)dx的值为随机变量 X X X的期望,记为 E ( X ) E(X) E(X),即 E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x E(X)=\int_{-\infty}^{+\infty}xf(x)dx E(X)=∫−∞+∞xf(x)dx
下面介绍几种常用的连续型随机变量的期望
☀️ 均匀分布
设 X X X~ U [ a , b ] U[a,b] U[a,b],概率密度函数为 f ( x ) = { 1 b − a a ≤ x ≤ b 0 其它 f(x)=\begin{cases} \frac{1}{b-a}~~~~~~a\leq x\leq b\\ 0~~~~~~~~~其它\\ \end{cases} f(x)={b−a1 a≤x≤b0 其它
E ( X ) = ∫ a b x b − a d x = 1 2 ( a + b ) E(X)=\int_{a}^b\frac{x}{b-a}dx=\frac12(a+b) E(X)=∫abb−axdx=21(a+b)
☀️ 指数分布
设 X X X服从参数为 λ \lambda λ的指数分布,概率密度函数为 f ( x ) = { λ e − λ x x ≥ 0 0 x < 0 λ > 0 f(x)=\begin{cases} \lambda e^{-\lambda x}~~~~x\geq 0\\ 0~~~~~~~~~~~~x<0\\ \end{cases}~~~~~~~\lambda>0 f(x)={λe−λx x≥00 x<0 λ>0
E ( X ) = ∫ 0 + ∞ λ x e − λ x d x = 1 λ E(X)=\int_{0}^{+\infty}\lambda xe^{-\lambda x}dx=\frac1\lambda E(X)=∫0+∞λxe−λxdx=λ1
☀️ 正态分布
设 X X X~ N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),概率密度函数为 f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}},-\infty
E ( X ) = ∫ − ∞ + ∞ x 2 π σ e − ( x − μ ) 2 2 σ 2 d x E(X)=\int_{-\infty}^{+\infty}\frac{x}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}dx E(X)=∫−∞+∞2πσxe−2σ2(x−μ)2dx
令 t = x − μ σ t=\frac{x-\mu}{\sigma} t=σx−μ,可得 ∫ − ∞ + ∞ x 2 π σ e − ( x − μ ) 2 2 σ 2 d x = 1 2 π ∫ − ∞ + ∞ ( μ + σ t ) e − t 2 2 d t = μ \int_{-\infty}^{+\infty}\frac{x}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}dx=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{+\infty}(\mu+\sigma t)e^{-\frac{t^2}{2}}dt=\mu ∫−∞+∞2πσxe−2σ2(x−μ)2dx=2π1∫−∞+∞(μ+σt)e−2t2dt=μ
最后可得 E ( X ) = μ E(X)=\mu E(X)=μ
☁️ 随机变量的期望总结
- 离散型
- 两点分布: E ( X ) = p E(X)=p E(X)=p
- 二项分布: E ( X ) = n p E(X)=np E(X)=np
- 泊松分布: E ( X ) = λ E(X)=\lambda E(X)=λ
- 连续型
- 均匀分布: E ( X ) = 1 2 ( a + b ) E(X)=\frac{1}{2}(a+b) E(X)=21(a+b)
- 指数分布: E ( X ) = 1 λ E(X)=\frac1\lambda E(X)=λ1
- 正态分布: E ( X ) = μ E(X)=\mu E(X)=μ
☁️ 随机变量函数的期望
定义:设 g ( x ) g(x) g(x)是连续函数, Y Y Y是随机变量 X X X的函数: Y = g ( X ) Y=g(X) Y=g(X)。
- 设 X X X是离散型随机变量,概率分布为 P { X = x i } = p i i = 1 , 2... P\{X=x_{i}\}=p_{i}~~~~~i=1,2... P{X=xi}=pi i=1,2...,若 ∑ ∣ g ( x i ) ∣ p i \sum|g(x_{i})|p_{i} ∑∣g(xi)∣pi收敛,则有 E ( Y ) = E [ g ( X ) ] = ∑ g ( x i ) p i E(Y)=E[g(X)]=\sum g(x_{i})p_{i} E(Y)=E[g(X)]=∑g(xi)pi
- 设 X X X是连续型随机变量,概率密度函数为 f ( x ) f(x) f(x),若积分 ∫ − ∞ + ∞ ∣ g ( x ) ∣ f ( x ) d x \int_{-\infty}^{+\infty}|g(x)|f(x)dx ∫−∞+∞∣g(x)∣f(x)dx收敛,则有 E ( Y ) = E [ g ( x ) ] = ∫ − ∞ + ∞ g ( x ) f ( x ) d x E(Y)=E[g(x)]=\int_{-\infty}^{+\infty}g(x)f(x)dx E(Y)=E[g(x)]=∫−∞+∞g(x)f(x)dx
根据上面的结论,我们可以推广到两个随机变量函数 Z = g ( X , Y ) Z=g(X,Y) Z=g(X,Y)的情形:
- 对离散型,设 P { X = x i , Y = y i } = p i j i = 1 , 2... j = 1 , 2... P\{X=x_{i},Y=y_{i}\}=p_{ij}~~~~~~~~i=1,2...~~~~j=1,2... P{X=xi,Y=yi}=pij i=1,2... j=1,2...,则有 E ( Z ) = E [ g ( X , Y ) ] = ∑ i ∑ j g ( x i , y i ) p i j E(Z)=E[g(X,Y)]=\sum_{i}\sum_{j}g(x_{i},y_{i})p_{ij} E(Z)=E[g(X,Y)]=i∑j∑g(xi,yi)pij
- 对连续型,设 f ( x , y ) f(x,y) f(x,y)是 ( X , Y ) (X,Y) (X,Y)的概率密度函数,则 E ( Z ) = E [ g ( X , Y ) ] = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x , y ) f ( x , y ) d x d y E(Z)=E[g(X,Y)]=\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty}g(x,y)f(x,y)dxdy E(Z)=E[g(X,Y)]=∫−∞+∞∫−∞+∞g(x,y)f(x,y)dxdy
☁️ 期望的性质
- 设 c c c是常数,则 E ( c ) = c E(c)=c E(c)=c
- 设 k k k是常数,则 E ( k X ) = k E ( X ) E(kX)=kE(X) E(kX)=kE(X)
- E ( X + Y ) = E ( X ) + E ( Y ) E(X+Y)=E(X)+E(Y) E(X+Y)=E(X)+E(Y)
- 设 X X X与 Y Y Y相互独立,则 E ( X Y ) = E ( X ) E ( Y ) E(XY)=E(X)E(Y) E(XY)=E(X)E(Y)
C语言实现案例
- 某种产品的次品率是0.1,检验员每天检验4次,每次随机抽取10件产品进行检验,如果发现其中的次品数大于1,则应调整设备。设各件产品是否为次品是相互独立的,求一天中调整设备次数的期望。
题目分析:题目的要求是只要有一次检验,十件产品中次品数大于1,就需调整设备。而一天中又要检验4天,并且求的是一天中调整设备的次数。所以我们可以先求出每一次检验后需要调整设备的概率,然后就可以转化为二项分布 X X X~ B ( n , p ) B(n,p) B(n,p),求得一天中四次检验需要调整设备的期望。
#include 
代码分析:代码主要的难度就是在二项分布的那个公式上,需要结合组合公式的算法才行,其它的就按照做题的思路来就行了。
- 有4只盒子,编号为1,2,3,4,现有3个球,将球逐个独立地随机放入4只盒子中去。用 X X X表示其中至少有一个球的盒子的最小号码 ,求 E ( X ) E(X) E(X)。
题目分析: 先来理解最后一句话,当 X = 1 X=1 X=1时表示1号盒子中至少有一个球,此时1为四个盒子中号码最小的那一个,当 X = 2 X=2 X=2时表示2号盒子中至少有一个球,此时2“应该为”最小号码,也就是说1号盒里就不会有元素了,当 X = 3 X=3 X=3时表示3号盒子中至少有一个球,此时3“应该”为最小号码,也就是说1和2号盒子里都没有球…
理解了最后一句话后这个题就简单了,每个球有4种放法,一共有3个球,也就是总共有 4 3 4^3 43种方法,然后若 X = 1 X=1 X=1,则 P { X = 1 } = 1 − 3 3 4 3 = 4 3 − 3 3 4 3 P\{X=1\}=1-\frac{3^3}{4^3}=\frac{4^3-3^3}{4^3} P{X=1}=1−4333=4343−33…
#include 
代码分析:还是老样子,对于一个需要用分数来表示的题,我们用一个大小为2的一维数组来分别存储它的分子和分母,然后进行相关的运算即可。
那些啥组合公式的代码、约分代码我在这类专栏的前面博客中写过,所以这里就直接拿过来用了。
- 设二维离散型随机向量 ( X , Y ) (X,Y) (X,Y)的概率分布如下表所示,求 Z = X 2 + Y Z=X^2+Y Z=X2+Y的期望。
| X\Y | 1 | 2 |
|---|---|---|
| 1 | 0.125 | 0.25 |
| 2 | 0.5 | 0.125 |
题目分析:由题知,再结合前面总结的知识点,设 g ( x , y ) = x 2 + y g(x,y)=x^2+y g(x,y)=x2+y,那么有:
- X = 1 , Y = 1 X=1,Y=1 X=1,Y=1: Z = g ( 1 , 1 ) = 2 ~~~~~~Z=g(1,1)=2 Z=g(1,1)=2
- X = 1 , Y = 2 X=1,Y=2 X=1,Y=2: Z = g ( 1 , 2 ) = 3 ~~~~~~Z=g(1,2)=3 Z=g(1,2)=3
- X = 2 , Y = 1 X=2,Y=1 X=2,Y=1: Z = g ( 2 , 1 ) = 5 ~~~~~~Z=g(2,1)=5 Z=g(2,1)=5
- X = 2 , Y = 2 X=2,Y=2 X=2,Y=2: Z = g ( 2 , 2 ) = 6 ~~~~~~Z=g(2,2)=6 Z=g(2,2)=6
则 E ( Z ) = 2 × 0.125 + 3 × 0.25 + 5 × 0.5 + 6 × 0.125 = 4.25 E(Z)=2\times 0.125+3\times 0.25+5\times 0.5+6\times0.125=4.25 E(Z)=2×0.125+3×0.25+5×0.5+6×0.125=4.25
#include 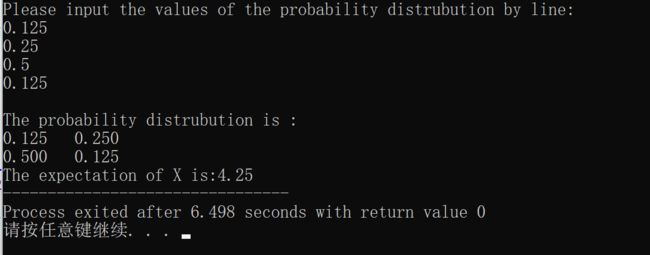
代码分析:这个题的代码也十分简单,实现一下数学公式就行了。
这一期的学习就到这里了,咱们下期再见~~![]()