我们准备如下两个表,并插入数据。
#分类 CREATE TABLE IF NOT EXISTS `type` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); #图书 CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`bookid`) );
左外连接
首先我们分析SQL如下,type为驱动表(内表),book为被驱动表(外表)。
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

每次从type中获取一条数据然后后book中的数据进行对比(全表扫描),这个过程要要重复20次(type 表有20条数据)。
这里可以看到,type均为all。另外还可以看到MySQL帮我们做了一个优化,使用了join buffer进行缓存。
我们为被驱动表 book.card 添加索引优化
CREATE INDEX Y ON book(card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

这里能够看到,虽然type表仍旧是要处理20次,但是拿着type的数据去book中寻找时,走的是索引。对于B+树来讲,其时间复杂度为logN,相比前面的全表扫描要快很多。
也就是对于左外连接来讲,如果只能添加一个索引,那么一定添加到被驱动表上。
当然,给type的card页创建索引也是可以的。
CREATE INDEX X ON `type`(card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

如果索引只加在了驱动表(左表)呢?
DROP INDEX Y ON book; EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

可以看到,同样使用了join buffer。而对于驱动表来讲,即使用到了索引也要做一个整体的遍历(无非这时走的是索引文件)。而被驱动表没有索引,那么性能会相对较慢。
如下图所示,从其查询成本我们也可以看到显著区别。
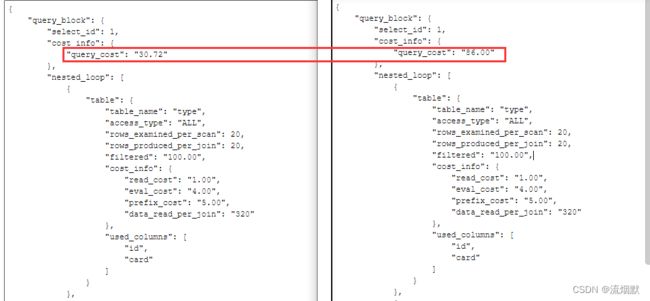
结论: 左(外)连接时,索引加在右表的连接字段。left join用于确定如何从右表搜索行,左表一定都有。同理,右(外)连接时,索引创建在左表的连接字段。该连接字段在两个表中的数据类型保持一致。
此外,从上面Using where; Using join buffer (Block Nested Loop)我们也可以想到,如果有条件,那么join buffer给一个较大的容量是有助于提升性能的。
内连接INNER JOIN
我们去掉索引,然后查看执行计划。
DROP INDEX X ON `type`; EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

我们给被驱动表 book.card 添加索引
CREATE INDEX Y ON book(card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

我们再给驱动表type添加索引
CREATE INDEX X ON `type`(card); EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

可以看到这里二者均用到了索引。需要说明的是,这时type和book上下次序可能转换,也就是说 对于inner join来讲,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的 。
那如果book.card没有索引,type.card 有索引呢?
DROP INDEX Y ON book; EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

可以看到book作为了驱动表,type作为了被驱动表。即,对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现。
如果两个表数据量不一致呢?比如这里我们type为40条,book为20条。
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card = book.card;

结论: 对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表,即“小表驱动大表”。
到此这篇关于MySQL关联查询优化实现方法详解的文章就介绍到这了,更多相关MySQL关联查询优化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!