【深度学习】语义分割-综述(卷积)
这里写目录标题
- 0.笔记参考
- 1. 目的
- 2. 困难点
- 3. 数据集及评价指标
-
- 3.1数据集
- 3.2评价指标
- 4.实现架构
- 5. 模型发展
-
- 5.1基于全卷积的对称语义分割模型
-
- 5.1.1FCN(2014/11/14)
-
- 5.1.1.1具体过程
- 5.1.1.2 CNN 与 FCN
- 5.1.1.3全连接层 -> 成卷积层
- 5.1.1.4 upsampling
- 5.1.1.5局限
- 5.1.2 SegNet(2015/11/2)
-
- 5.1.2.1 结构
- 5.1.2.2 decoder变体SegNet-Basic
- 5.1.2.3 对比SegNet和FCN实现decoder
- 5.1.2.4结论及评价
- 5.1.3Unet及各种变体(2015/5/18)
-
- 结构
- 与swin结合-Swin-UNet
- 5.2基于全卷积的扩张卷积语义分割模型
-
- 5.2.1Dilated convolution(2015/11/23)
- 5.2.2DeepLab系列
-
- 5.2.2.1DeepLabV1(2014/12/22)
-
- **空洞卷积**
- 5.2.2.2 DeepLabV2(2016/6/2)
-
- 空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)
- 5.2.2.3 DeepLabV3 (2017/6/17)
- 5.2.2.4 DeepLabV3+(CVPR2018)
-
- 简述
- 网络结构
- 5.2.3 PSPNet金子塔型场景解析网络(2016/12/4 CVPR 2017)
-
- 网络架构
- 5.2.4UPerNet(ECCV2018)
-
- 结构分析
- 关于语义分割
- 特征图金字塔网络FPN(Feature Pyramid Networks)
- 应用:
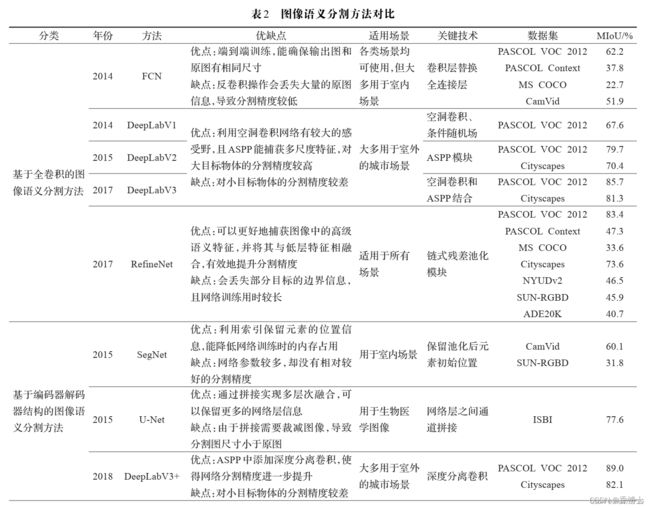
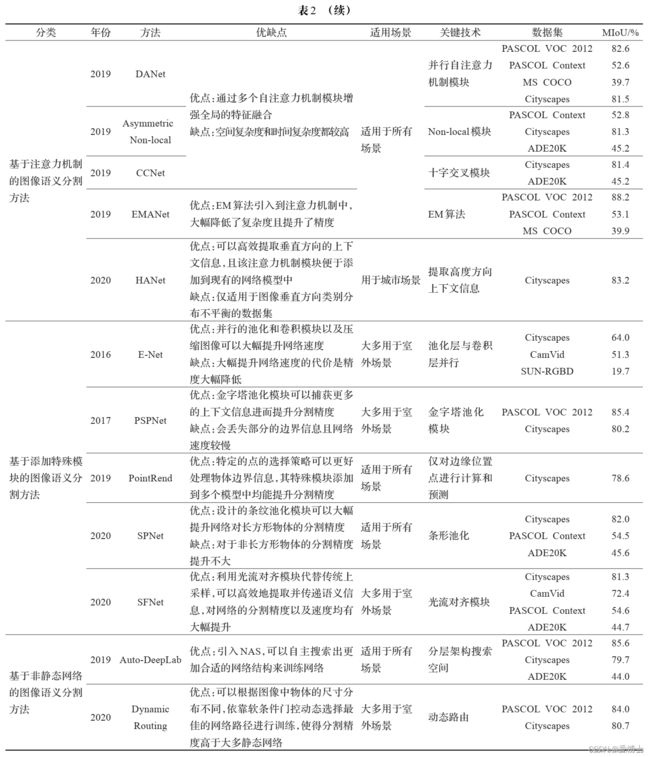
- 6汇总图
0.笔记参考
1.入门总结
2.2019-7史上最全语义分割综述(FCN,UNet,SegNet,Deeplab,ASPP…)
3.神经网络–语义分割网络回顾
4.一篇看完就懂的最新语义分割综述
5.FCN详解
6.Semantic Segmentation—SegNet:A Deep Convolutional Encoder-Decoder Architecture…(论文解读一)
7.语义分割综述
8.图像语义分割综述
9.DeepLab系列总结
10.图像语义分割方法研究进展
11.2021语义分割指南总结
12.语义分割模型架构演进与相关论文阅读----强推!!
13.图像语义分割方法研究进展
1. 目的
给定一张图像,我们要对这张图像上的每个pixel逐一进行分类,结果展示如下图:
2. 困难点
1、数据问题:分割不像检测等任务,只需要标注一个类别就可以拿来使用,分割需要精确的像素级标注,包括每一个目标的轮廓等信息,因此使得制作数据集成本过高;
2、计算资源问题:现在想要得到较高的精度的语义分割模型就需要使用类似于ResNet101等深网络。同时,分割预测了每一个像素,这就要求feature map的分辨率尽可能的高,这都说明了计算资源的问题,虽然也有一些轻量级的网络,但精度还是太低了;
3、精细分割:目前的方法中对于图像中的大体积的东西能够很好的分类,但是对于细小的类别,由于其轮廓太小,从而无法精确的定位轮廓,造成精度较低;
4、上下文信息:分割中上下文信息很重要,否则会造成一个目标被分成多个part,或者不同类别目标分类成相同类别;
3. 数据集及评价指标
3.1数据集
VOC2012:有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割
MSCOCO:是一个新的图像识别、分割和图像语义数据集,是一个大规模的图像识别、分割、标注数据集。它可以用于多种竞赛,与本领域最相关的是检测部分,因为其一部分是致力于解决分割问题的。该竞赛包含了超过80个物体类别
Cityscapes :50 个城市的城市场景语义理解数据集
Stanford Background Dataset:至少有一个前景物体的一组户外场景。
Pascal Context:有 400 多类的室内和室外场景
3.2评价指标
1、执行时间:速度或运行时间是一个非常有价值的度量,因为大多数系统需要保证推理时间可以满足硬实时的需求。然而在通常的实验中其影响是很不明显的,并且该指标非常依赖硬件设备及后台实现,致使一些比较是无用的。
2、内存占用:在运行时间相同的情况下,记录系统运行状态下内存占用的极值和均值是及其有价值的。
3、精确度:这里指的是逐像素标记的精度测量,假设共有k个类(从l0到lk其中有一个类别是属于背景的。),Pij表示本属于i类但是被预测为j类的像素个数,Pii表示为真正分对类的数量,而Pij与Pji分别被称为假正样本和假负样本。
1)Pixel Accuracy(PA,像素精度):标记正确的像素占总像素的比例.
基于像素的精度计算是评估指标中最为基本也最为简单的指标,从字面上理解就可以知道,PA是指预测正确的像素占总像素的比例.
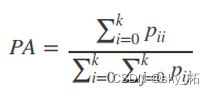
2)Mean Pixel Accuracy(MPA,平均像素精度):计算每个类内被正确分类像素数比例,之后求所有类的平均数。
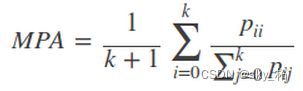
3)**Mean Intersection over Union(MIoU,均交并比):**为语义分割的标准度量,其计算两个集合的交集和并集之比,这两个集合分别为ground truth 与predicted segmentation,在每个类上计算IoU,之后将其求平均。
-----IoU即真正样本数量/(真正样本数量+假正样本数量+假负样本数量)
这样的评价指标可以判断目标的捕获程度(使预测标签与标注尽可能重合),也可以判断模型的精确程度(使并集尽可能重合)。
IoU一般都是基于类进行计算的,也有基于图片计算的。一定要看清数据集的评价标准。
基于类进行计算的IoU就是将每一类的IoU计算之后累加,再进行平均,得到的就是基于全局的评价,所以我们求的IoU其实是取了均值的IoU,也就是均交并比(mean IoU)
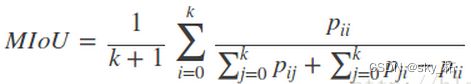
4)Frequency weighted Intersection over Union(FWIoU,频权交并):是MIoU的一种提升,这种方法根据每个类出现的频率为期设置权重。
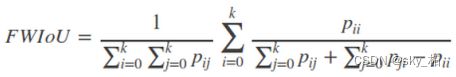
4.实现架构
(1). 编码器-解码器的构架(FCN、SegNet、U-Net)
- 编码器一般采用图像分类预训练得到的网络,采用不断的max pooling和strided convolution有利于获得长范围的语境信息从而得到更好的分类结果。
然而在此过程中特征分辨率不断降低,图像细节信息丢失,对于分割任务而言具有巨大的挑战。因此在编码器之后需要利用解码器进行图像分辨率的恢复; - 解码器的任务是将编码器学习到的识别特征(低分辨率)语义投影到像素空间(高分辨率)上,得到密集的分类。
(2). 上下文模块(Multi-scale context aggregation、DeepLab V1、V2和CRF-RNN等)
**上下文模块一般是级联在模型后面,以获得长距离的语境信息。**以DenseCRF级联在DeepLab之后理解,DenseCRF能够对于任意长距离内像素之间的关系进行建模,因此改善逐项素分类得到的分割结果;
(3). 金字塔池化方法(PSPNet、DeepLab V2、V3、V3+等)
金字塔池化的方法作用在卷积特征上,能够以任意的尺度得到对应的语境信息。一般采用平行的多尺度空洞卷积(ASPP)或者多区域池化(PSPNet)得到对应尺度语境信息的特征,最后再将其融合形成综合多个尺度语境的特征向量。
第一种方法使用图像金字塔来抽取每个尺度的特征,然后将所有尺度的图像放入CNN中得到不同尺度的分割结果,最后将不同分辨率的分割结果融合得到原始分辨率的分割结果。
第二种方法是编码器-解码器结构,从编码器结构中抽取多尺度信息,并在解码器结构中复原空间分辨率。因此可以在更深的编码器输出中抽取更长范围的信息。
第三种方法是在原有的网络结构的顶部接入额外的结构,用于捕捉长范围信息。一般会使用稠密CRF进行信息抽取。
第四种方法是空间池化金字塔,使用以多个不同大小和感受野的卷积核或池化层扫描输入图像,捕捉其中的多尺度信息

5. 模型发展
在传统的语义分割问题上,存在的三个挑战:
- 传统分类CNN中连续的池化何降采样导致空间分辨率下降。(解决:去掉最后几层的降采样和最大池化,使用上采样滤波器,得到采样率更高的特征)
- 对象对尺度检测问题,使用重新调节尺度并聚合特征图,但是计算量较大。(解决:对特征层重采样,得到多尺度的图像文本信息,使用多个并行ACNN进行多尺度采样,陈伟ASPP)
- 以物体为中心的分类,需要保证空间转换不变性。(解决:跳跃层结构,从多个网络层中抽取高层次特征进行预测;使用全连接条件随机场进行边界预测优化)
链接:https://www.jianshu.com/p/9184455a4bd3
5.1基于全卷积的对称语义分割模型
在解决图像分类问题时,往往在卷积神经网络模型末尾添加全连接层,把卷积层的输出特征图映射成一个特征向量,只能完成对整张图像进行分类。
而在解决语义分割问题时,用卷积层代替卷积神经网络模型中的全连接层得到全卷积网络,能够完成对图像中每一个像素点的分类。
5.1.1FCN(2014/11/14)
Fully Convolutional Networks for Semantic Segmentation
用 1×1 卷积替换卷积神经网络模型中全连接层,再通过 Softmax 层获得每个像素点属于各个种类的概率值,每个像素点的真实类别就是其对应的概率值最大的类别,最终得到与原图分辨率相同的分割图像。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
主要贡献
将端到端的卷积网络推广到语义分割中;
1.全卷积化(Fully Convolutional):
用于解决逐像素(pixel-wise)的预测问题。通过将基础网络(例如VGG)最后面几个全连接层换成卷积层,可实现任意大小的图像输入,并且输出图像大小与输入相对应;
2.通过deconvolutional layers进行上采样 :
上采样操作,用于恢复图片尺寸,方便后续进行逐像素预测;
3. 通过skip connection改善了上采样的粗糙度
用于融合高低层特征信息。通过跨层连接的结构,结合了网络浅层的细(fine-grain)粒度信息信息以及深层的粗糙(coarse)信息,以实现精准的分割任务。
5.1.1.1具体过程
1.首先将一幅 RGB 图像输入到卷积神经网络后,经过多次卷积及池化过程得到一系列的特征图,
2.然后利用反卷积层对最后一个卷积层得到的特征图进行上采样,使得上采样后特征图与原图像的大小一样,从而实现对特征图上的每个像素值进行预测的同时保留其在原图像中的空间位置信息,
3.最后对上采样特征图进行**逐像素分类,**逐个像素计算 softmax 分类损失。
过上采样将特征图恢复到与输入图像的尺寸一致,能够对所有像素点进行分类。
输入图像经过全卷积网络的conv1 卷积和第 1 次池化后得到 poo1 特征图,高和宽缩小为原来的 1/2;
poo1 特征图经过全卷积网络的 conv2 卷积和第 2 次池化后得到 poo2 特征图,高和宽缩小为原来的 1/4;
poo2 特征图经过全卷积网络的 conv3 卷积和第 3 次池化后得到 poo3特征图,高和宽缩小为原来的 1/8;
poo3 特征图经过全卷积网络的 conv4 次卷积和第 4 次池化后得到 poo4 特征图,高和宽缩小为原来的 1/16;
poo4 特征图经过全卷积网络的 conv5 卷积和第 5 次池化后得到 poo5 特征图,高和宽缩小为原来的 1/32。
然而,由于在池化操作中丢失部分信息,使得即使加上反卷积层的上采样操作也会产生粗糙的分割图。因此,本文还从高分辨率特性图谱中引入了跳跃连接方式。
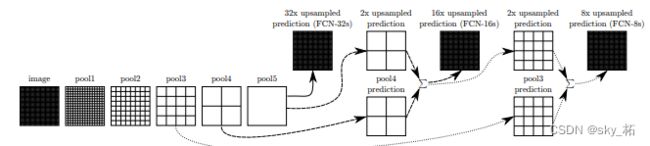
最后的语义分割结构有三种:
pool5 特征图进行 32 倍上采样得到与输入图像相同分辨率的特征图,通过 Softmax 层获得 FCN-32s 分割图;
pool5 特征图进行 2倍上采样后与 pool4 特征图进行拼接,然后进行 16 倍上采样得到与输入图像相同分辨率的特征图,通过 Softmax 层获得到 FCN-16s 分割图;
pool5 特征图进行 2 倍上采样后与 pool4 特征图进行拼接,其结果再进行 2 倍上采样后与 pool3 特征图拼接,然后进行 8 倍上采样得到与输入图像相同分辨率的特征图,通过 Softmax 层获得 FCN-8s 分割图。
由于多特征融合有利于提高语义分割的准确性,FCN-8s 比 FCN-16s 的分割效果好,FCN-16s 的分割效果又好于 FCN-32s。
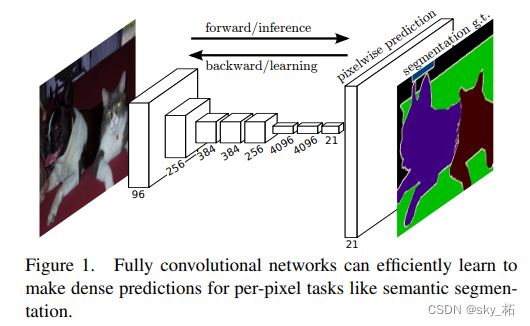
如下图所示,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络,FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。
FCN将这3层表示为卷积层,**卷积核的大小 (通道数,宽,高) 分别为 (4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
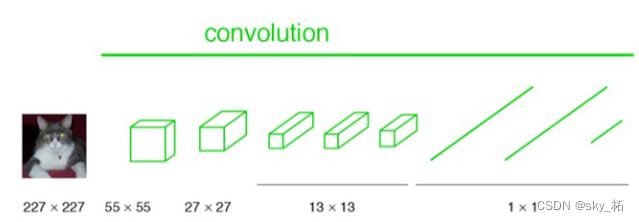
下图是一个全卷积层,与上图不一样的是图像对应的大小下标,
CNN中输入的图像大小是固定resize成 227x227 大小的图像,第一层pooling后为55x55,第二层pooling后图像大小为27x27,第五层pooling后的图像大小为1313。
**而FCN输入的图像是HW大小,第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。
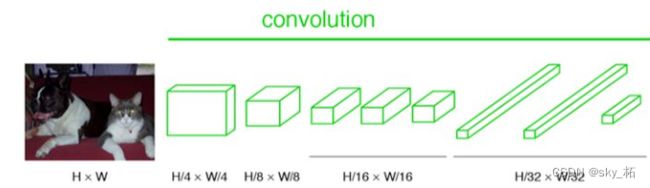
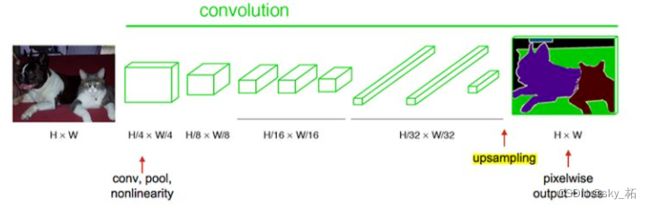
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特诊图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。

最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如下图右侧有狗狗和猫猫的图。
5.1.1.2 CNN 与 FCN
FCN与CNN的区别在于把CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。
全连接层作用:
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。
以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
栗子:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。
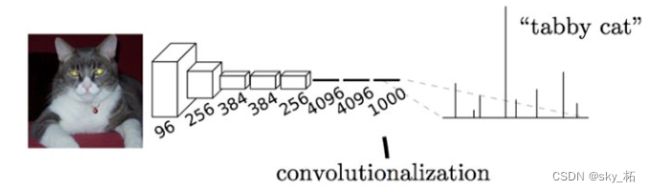
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。
与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,
FCN可以接受任意尺寸的输入图像,**采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,**从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
5.1.1.3全连接层 -> 成卷积层
全连接层和卷积层之间唯一的不同:
**卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。**然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。
因此,将此两者相互转化是可能的:
- 对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块,其余部分都是零。而在其中大部分块中,元素都是相等的。
- 相反,任何全连接层都可以被转化为卷积层。
比如,一个 K=4096 的全连接层,输入数据体的尺寸是 7∗7∗512,这个全连接层可以被等效地看做一个 F=7,P=0,S=1,K=4096 的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成 1∗1∗4096,这个结果就和使用初始的那个全连接层一样了。
全连接层转化为卷积层:
在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。
假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。
我们可以将这3个全连接层中的任意一个转化为卷积层:
针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
实际操作中,每次这样的变换都需要把全连接层的权重W重塑成卷积层的滤波器。
那么这样的转化有什么作用呢?
它在下面的情况下可以更高效:**让卷积网络在一张更大的输入图片上滑动,得到多个输出,**这样的转化可以让我们在单个向前传播的过程中完成上述的操作。
举个栗子:如果我们想让224×224尺寸的浮窗,以步长为32在384×384的图片上滑动,把每个经停的位置都带入卷积网络,最后得到6×6个位置的类别得分。
上述的把全连接层转换成卷积层的做法会更简便。
如果224×224的输入图片经过卷积层和下采样层之后得到了[7x7x512]的数组,那么,384×384的大图片直接经过同样的卷积层和下采样层之后会得到[12x12x512]的数组。然后再经过上面由3个全连接层转化得到的3个卷积层,最终得到[6x6x1000]的输出((12 – 7)/1 + 1 = 6)。这个结果正是浮窗在原图经停的6×6个位置的得分!
5.1.1.4 upsampling
相较于使用被转化前的原始卷积神经网络对所有36个位置进行迭代计算,使用转化后的卷积神经网络进行一次前向传播计算要高效得多,因为36次计算都在共享计算资源。这一技巧在实践中经常使用,一次来获得更好的结果。比如,通常将一张图像尺寸变得更大,然后使用变换后的卷积神经网络来对空间上很多不同位置进行评价得到分类评分,然后在求这些分值的平均值。
最后,如果我们想用步长小于32的浮窗怎么办?用多次的向前传播就可以解决。比如我们想用步长为16的浮窗。那么先使用原图在转化后的卷积网络执行向前传播,然后分别沿宽度,沿高度,最后同时沿宽度和高度,把原始图片分别平移16个像素,然后把这些平移之后的图分别带入卷积网络。
如下图所示,当图片在网络中经过处理后变成越小的图片,其特征也越明显,就像图像中颜色所示,当然啦,最后一层的图片不再是一个1个像素的图片,而是原图像 H/32xW/32 大小的图,这里为了简化而画成一个像素而已。

如下图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个差值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
5.1.1.5局限
1.得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
2.对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
个人评论
本文算是语义分割开天辟地之作,其全连接层的结构在最先进的分割模型中仍在使用。
5.1.2 SegNet(2015/11/2)
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
PAMI2017(IEEE Transactions on Pattern Analysis and Machine Intelligence)
encoder-decoder架构
encoder-decoder是基于FCN的架构。
encoder由于pooling逐渐减少空间维度,而decoder逐渐恢复空间维度和细节信息。通常从encoder到decoder还有shortcut connetction(捷径连接,也就是跨层连接)。
针对问题:
FCN 在语义分割时感受野固定和分割物体细节容易丢失或被平滑,最大池化和下采样会降低feature map的分辨率(即降低feature map分辨率会损失边界信息)
主要贡献:
采用了 pooling indices 来增强位置信息,降低了参数数量。
SegNet的新颖之处在于decoder阶段的上采样方式
具体来说,decoder的上采样使用了**encoder阶段下采样的最大池化的索引(indices)。**考虑到上采样是稀疏的,再配合滤波器产生最后的分割图。
5.1.2.1 结构
SegNet和FCN思路十分相似,
编码部分:
主要由VGG16网络的前 13 个卷积层和 5 个池化层组成,
作用:该部分提取输入特征,用于目标分类,这就是使用预训练的VGG原理所在,至于丢弃FC层是为了保持更高的分辨率,同时也减少了参数。
解码部分:
同样也由 13 个卷积层和 5 个上采样层组成,
每个encoder会对应一个decoder,故decoder具有13层,将低分辨率的feature map映射回和输入一样大小分类器(mask).
像素分类层(pixelwise classification layer):
decoder的输出(高维特征)会送到分类层(可训练的softmax 分类器中),最终为每个像素独立的产生类别概率

Encoder network:
Encoder network分为5个block,每个block由Conv+BN + MaxPooling组成,MaxPooling实现下采样操作,核长为2,步长为2.
因为使用的pre-train的VGG16模型的前13层,模型的参数会减少很多(FC层没了,参数少了很多)。当然这和原始的VGG16是有区别的,如上图。卷积层使用的是Conv + Batch Norm + ReLU结构。、
编码器中的每一个最大池化层的索引都被存储起来,用于之后在解码器中使用那些存储的索引来对相应的特征图进行反池化操作。
Decoder network:
模型在encoder network时使用Pooling时会记录Pooling Indices(pooling前后的对应位置),
在decoder network会用前面记录的位置还原,这也是论文的创新之处。 decoder network同样也为5个block,每个block由Upsampling + Conv + BN组成,需要注意的decoder阶段是没有加非线性激活的(即没有ReLU)。
分类层:
在decoder输出上加一个卷积层,卷积核个数为分类的通道数,即每个通道代表一类分割结果
5.1.2.2 decoder变体SegNet-Basic
SegNet的较小版本,4个encoder和4个decoder,
1.encoder阶段是LRN + (Conv+BN +ReLU + MaxPool)x4 论文给出的时卷积不使用bias
2.decoder阶段是(UpPool+Conv+ BN)x4 + Conv(分割层)
卷积核大小一直使用的时7×7,最高层的feature map接收野是原图的106×106 大小。
对于池化层和卷积层公式为:
![]()
其中Srf 是从高层feature向底层feature迭代计算,Stride 为步长,Ksize 为卷积核大小.
5.1.2.3 对比SegNet和FCN实现decoder
Upsamping就是Pooling的逆过程
A:Upsamping使得图片变大2倍。但Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原。
B:反卷积在用于填充缺失的内容,这有助于保持高频信息的完整性
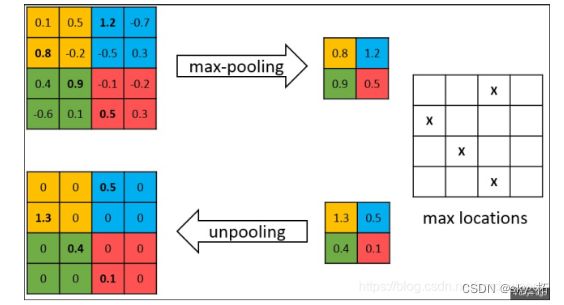
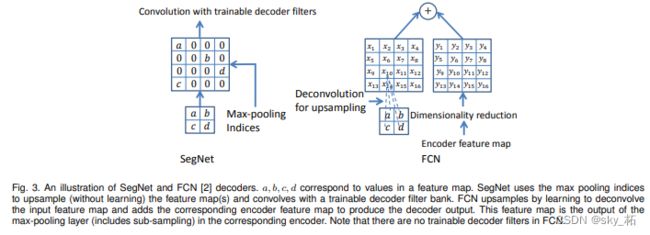
SegNet在UpPool时使用的是index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。
FCN采用transposed convolutions策略,即将feature 反卷积后得到upsampling,这一过程需要学习,同时将encoder阶段对应的feature做通道降维,使得通道维度和upsampling相同,这样就能做像素相加得到最终的decoder输出.
5.1.2.4结论及评价
模型主要在于decoder阶段的upsampling使用的时encoder阶段的pooling信息,这有效的提高了内存利用率,同时提高了模型分割率。
但是,SegNet的inference相比FCN没有显著提升,这样end-to-end的模型能力还有待提升。
尽管SegNet在评价指标不如FCN-8s效果好,但其提出的编码-解码的思想影响着后面的很多模型。
FCN和SegNet都是encoder-decoder架构。
SegNet的benchmark表现太差了,不建议用这个网络。
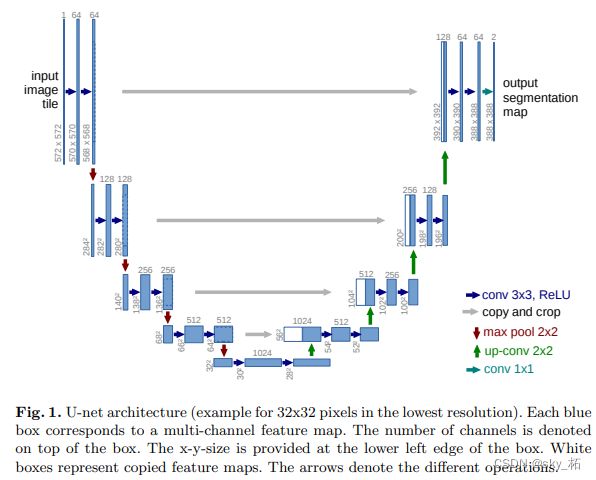
5.1.3Unet及各种变体(2015/5/18)
U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net设计的就是应用于医学图像的分割,但由于医学影像处理本身的特殊性,能够使用用于训练的数据数量还是比较少的,本篇论文提出的方法有效的提升了使用少量数据集进行训练检测的效果. 提出了处理大尺寸图像的有效方法.
- overlap-tile策略
- 随机弹性变形进行数据增强
- 使用了加权loss
结构
Unet网络非常简单,前半部分作用是特征提取,后半部分是上采样。在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
(1). U-net采用了完全不同的特征融合方式:concat拼接
A: 采用将特征在channel维度拼接在一起,形成更厚的特征。
B:在FCN中,Skip connection的联合是通过对应像素的求和,而U-Net则是对其的channel的concat过程。
(2). 上采样部分会融合特征提取部分的输出,这样做实际上是将多尺度特征融合在了一起.
A: 以最后一个上采样为例,它的特征既来自第一个卷积block的输出(同尺度特征),也来自上采样的输出。
B: 即采用跳跃 拼接 连接的架构,在每个阶段都允许解码器学习在编码器池化中丢失的相关特征
与swin结合-Swin-UNet
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
笔记:
1.Swin-Unet口语化解释
2.很好!!更详细的论文笔记
概述
和以往的transformer用在图像分割领域的方法不一样。以往的transformer都是被用在encoder部分的,就是把UNet的encoder用transformer替换一下。再怎么改也跳不出这个范围,就没见过transformer用在decoder的。
要点
要点就在于swin transformer是怎么成为decoder的,它是搞了一个patch expanding layer
贡献
1 基于Swin Transformer块,建立了具有跳跃连接的对称的编码解码结构,在编码器,实现从局部到全局的自注意力。在解码器,全局特征被上采样至输入分辨率执行相应的像素级分割预测。
2 块扩展层被开发来实现上采样,不使用卷积和插值操作实现特征维度增加。【这个可以用一下】
3 实验中表明跳跃连接对于Transformer仍然有效,因此一个基于纯transformer的具有跳跃连接的U形编码解码结构最终实现,叫Swin-Unet
摘要
CNN缺点:
卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形架构和跳跃连接的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
提出:
提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer。标记化的图像块通过跳跃连接被馈送到基于Transformer的U形En-Decoder架构中,以进行局部全局语义特征学习。
具体来说,我们使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。
并设计了具有补丁扩展层的基于对称Swin Transformer的解码器来执行上采样操作,以恢复特征图的空间分辨率。
网络结构
具体过程:
- 输入的医学图像被分割为不重叠的图像块。每一个块被当作是一个token,将其送入到基于Transformer的编码器学习深度特征表示。
- 然后,被提取上下文特征通过具有块扩展层的解码器进行上采样,通过跳跃连接融合来自编码器的多尺度特征,以便恢复特征图的空间分辨率,进一步进行分割预测。
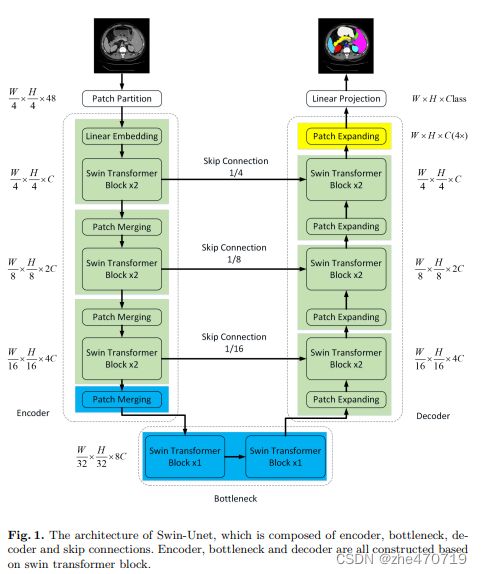
如图1所示,Swin-UNet由Encoder、Bottleneck、Decoder和跳跃连接组成。
编码器
对图像特征进行聚合,同时下采样,WH减半,channel同步增加==(由于Swin输入多少输出多少,所以下采样功能是通过torch的linear层实现的)==
输入图像先进行patch partition,每个patch大小为4x4,输入维度为H/4 x W/4 x 48,经过linear embedding和后特征图尺寸为H/4 x W/4 x C,送入两个连续的Swin Transformer block,其中特征维度和分辨率保持不变。
在patch merging进行下采样降低分辨率,将特征维度加倍。重复三次组成了编码器。
Bottleneck 用了两个连续的Swin Transformer block,这里为防止网络太深不能收敛,所以只用了两个block,在Bottleneck中,特征尺寸保持H/32 x W/32 x 8C不变。
解码器
将图像上采样要原图大小方便进行像素点分类
Swin-UNet解码器主要由patch expanding来实现上采样,作为一个完全对称的网络结构,解码器也是每次扩大2倍进行上采样,核心模块由Swin Transformer block和patch expanding组成。
跳跃连接
网络层越深得到的特征图,有着更大的感受野,浅层卷积关注纹理特征,深层网络关注本质的那种特征,通过跳连接可以使特征向量同时具有深层和表层特征(cat方法),
跳跃连接将编码器的多尺度特征与上采样特征融合。将浅层特征和深度特征连接在一起,以减少下采样造成的空间信息损失。
最后是一个线性层,所连接的特征的维数与上采样特征的维数保持相同。
Patch merging layer
输入的patch分为4个部分,拼接在一起。这种处理使得特征分辨率由H/4 x W/4降为H/8 x W/8,由于拼接操作导致特征维增加4倍,再利用线性层,将特征维度降为原来的2倍。(与swin中相同。)
Patch expanding layer
以解码器中第一个为例,在上采样之前,在输入特征(W/32×H/32×8C)上应用线性层,将特征维度增加到2×原始尺寸(W/32×H/32×16C)。然后,利用rearrange操作,将输入特征的分辨率扩展到2倍的输入分辨率,并将特征维度降小到输入维度的四分之一(W/32×H/32×16C→W/16×H/16×4C)。(Patch merging的逆操作)
Swin Transformer block
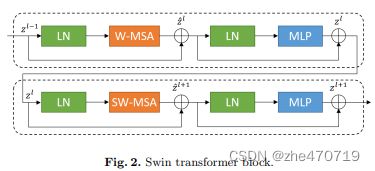
Swin Transformer 模块是基于滑动窗口构成的,如图2所示,展示了两个连续的Swin Transformer块。
- 每一个swin Transformer 是由层归一化(LN),多头自注意力模块,残差连接,带有GELU非线性的两层MLP。
- 基于窗口的多头自注意力模块(W-MSA)和基于滑动窗口的多头自注意力模块被分别用在两个连续transformer模块。
- 基于这写窗口分区机制,连续的swin transformer块可以公式化为:

总结:
Swin-Unet只是在各个特征提取模块将Unet的2D卷积换成了Swin结构,在Swin结构和Unet结构上基本没有改变,损失函数也没有做变化。再次说明了Swin模块的强大特征提取能力(感觉创新不太够啊,不过代码挺清爽的)
5.2基于全卷积的扩张卷积语义分割模型
基于全卷积对称语义分割模型得到分割结果较粗糙,忽略了像素与像素之间的空间一致性关系。于是 Google 提出了一种新的扩张卷积语义分割模型,考虑了像素与像素之间的空间一致性关系,可以在不增加参数量的情况下增加感受野。
5.2.1Dilated convolution(2015/11/23)
Multi-Scale Context Aggregation by Dilated Convolutions
创新点
- 使用空洞卷积用来进行稠密预测(dense prediction)。
- 提出上下文模块(context module),使用空洞卷积(Dilated Convolutions)来进行多尺度信息的的整合。
解决问题
(1). 常用的分割方式是对图像做卷积再pooling,降低图像分辨率的同时增大感受野。由于图像分割预测是逐像素的输出,所以要将pooling后较小的图像尺寸上采样到原始的图像尺寸进行预测。
(2). 既然网络中加入pooling层会损失信息,降低精度。那么不加pooling层会使感受野变小,学不到全局的特征。
如果去掉pooling层、扩大卷积核的话,这样纯粹的扩大卷积核势必导致计算量的增大。
关键:
pooling操作可以增大感受野,对于图像分类任务来说这有很大好处,但由于pooling操作降低了分辨率,这对语义分割来说很不利。因此作者提出一种叫做dilated convolution的操作来解决这个问题。dilated卷积(在deeplab中称为atrous卷积)。可以很好地提升感受野的同时可以保持空间分辨率。
Dilated卷积
A:空洞卷积能够整合多尺度的上下文信息,同时不丧失分辨率,也不需要分析重新放缩的图像。
B:空洞卷积没有pooling或其它下采样。空洞卷积支持感受野指数级的增长,同时还不损失分辨率
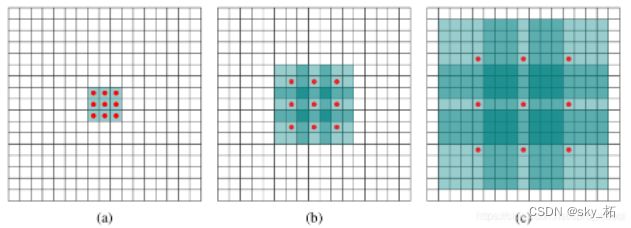
当 l = 1时,它是标准卷积。
当 l > 1时,它是扩张的卷积。
(a) 图对应3x3的扩张率为1的卷积,和普通的卷积操作一样
(b) 图对应3x3的扩张率为2的卷积,实际的卷积核还是3x3。也就是对于一个7x7的图像块,只有9个红色的点也就是3x3的卷积核发生卷积操作,其余的点略过, 即权值填写0。 虽然卷积核的大小只有3x3,但是这个卷积的感受野已经增大到了7x7。
© 图是4-dilated convolution操作, 能达到15x15的感受野.
空洞卷积适合用于密集预测,因为它能够在不损失分别率的情况下扩大感受野。 A: 感受野跳跃不连续的问题 B: 小尺度物体检测的问题
网络架构

网络架构有两种,一种是前端网络,另外一种是前端网络+上下文模块,分别介绍如下:
-
前端网络:
将VGG网络的最后两个pooling层给拿掉了,之后的卷积层被dilated 卷积取代。并且在pool3和pool4之间空洞卷积的空洞率=2,pool4之后的空洞卷积的空洞率=4。作者将这种架构称为前端(front-end)。 -
前端网络+上下文模块:
除了前端网络之外,作者还设计了一种叫做上下文模块(context module)的架构,加在前端网络之后。上下文木块中级联了多种不同空洞率的空洞卷积,使得多尺度的上下文信息可以得到整合,从而改善前端网络预测的效果。需要注意的是前端网络和上下文木块是分开训练的,因为作者在实验中发现,如果是联合在一起进行端对端的训练并不能改善性能。
应用
扩张/膨胀卷积为卷积层引入了另一个参数,即膨胀率。它可以在在不增加计算成本的情况下扩大了感受野。膨胀卷积在实际时间段中已被广泛应用,其中一些最重要的包括DeepLab家族、多尺度Context Aggregation、密集上采样卷积和混合扩张卷积(DUC-HDC)、Densespp和ENet。
5.2.2DeepLab系列
- 语义分割是对图像做密集的分割任务,分割每个像素到指定的类别上;
- 将图像分割成几个有意义的目标;
- 给对象分配指定的类别标签。
主要贡献
使用了空洞卷积,扩大感受野,保持分辨率。
提出了在空间维度上实现 金字塔型的空洞池化 atrous spatial pyramid pooling(ASPP),整合多尺度信息。
使用了全连接条件随机场 (fully connected CRF)进行后处理,改善分割结果。
汇总
DeepLabv1
是由深度卷积网络和概率图模型级联而成的语义分割模型,
1.由于深度卷积网络在重复最大池化和下采样的过程中会丢失很多的细节信息,所以采用扩张卷积算法增加感受野以获得更多上下文信息。
2.考虑到深度卷积网络在图像标记任务中的空间不敏感性限制了它的定位精度,采用了完全连接条件随机场(Conditional Random Field,CRF)来提高模型捕获细节的能力。
DeepLabv2
语义分割模型增加了 ASPP(Atrous spatial pyramid pooling)结构,利用多个不同采样率的扩张卷积提取特征,再将特征融合以捕获不同大小的上下文信息。
DeepLabv3
语义分割模型,在 ASPP 中加入了全局平均池化,同时在平行扩张卷积(ASPP)后添加批量归一化,有效地捕获了全局语境信息。
DeepLabv3+
语义分割模型在 DeepLabv3 的基础上增加了编-解码模块和 Xception 主干网络。
增加编解码模块主要是为了恢复原始的像素信息,使得分割的细节信息能够更好的保留,同时编码丰富的上下文信息。
增加 Xception 主干网络是为了采用深度卷积进一步提高算法的精度和速度。
在inception结构中,先对输入进行11的卷积,之后将通道分组,分别使用不同的33卷积提取特征,最后将各组结果串联在一起作为输出。
5.2.2.1DeepLabV1(2014/12/22)
原文:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Backbone:VGG16
Contributions:
Atrous convolution(空洞卷积)
CRF(条件随机场)
由于语义分割是像素级别的分类,高度抽象的空间特征对low-level并不适用,因此必须要考虑feature map 的尺寸和空间不变性。
-
feature map变小是因为stride的存在,stride>1是为了增加感受野的,如果stride=1,要保证相同的感受野,则必须是卷积核大小变大,因此,论文使用hole算法来增加核大小进而达到相同的感受野,也就是空洞卷积。
-
图像输入CNN后是一个倍逐步抽象的过程,原来的位置信息会随着深度而减少甚至消失。条件随机场在传统图像处理上做一个平滑,也就是说在决定一个位置的像素值时,能够考虑周围邻居的像素值,抹茶一些噪音。
-

具体的操作:
DeeplabV1是在VGG16的基础上做了修改:
移除原网络最后两个池化层,使用rate=2的空洞卷积采样。标准的卷积只能获取原图1/4的内容,而新的带孔的卷积能够在全图上获取信息。
1.首先,去掉了最后的全连接层。做语义分割使用全卷积网络是大势所趋,
2.然后,去掉了最后两个池化层。
pooling作用:- 缩小特征层的尺寸
- 快速扩大感受野,为了利用更多的上下文信息进行分析。
去掉pooling具体原因:
语义分割是一个end-to-end的问题,需要对每个像素进行精确的分类,对像素的位置很敏感,是个精细活儿。而pooling是一个不断丢失位置信息的过程,而语义分割又需要这些信息,矛盾就产生了。没办法,只好去掉pooling喽。全去掉行不行,理论上是可行的,实际使用嘛,一来显卡没那么大的内存,二来费时间。所以只去掉了两层。
3.去了两个pooling,感受野又不够了怎么办?把atrous convolution借来用一下,这也是对VGG16的最后一个修改。atrous convolution人称空洞卷积(好像多称为dilation convolution),相比于传统卷积,可以在不增加计算量的情况下扩大感受野,厉害了
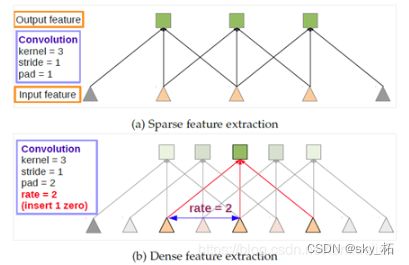
空洞卷积与传统卷积的区别在于
传统卷积是三连抽,感受野是3,空洞卷积是跳着抽,也就是使用图中的rate,感受野一下扩大到了5(rate=2),相当于两个传统卷积,而通过调整rate可以自由选择感受野。这样感受野的问题就解决了。
另外,原文指出,空洞卷积的优势在于增加了特征的密度。盯着上边这张图我想了很久这个问题,虽然你画的密,但是卷积都是一对一的输入多大输出多大,怎么空洞卷积的特征就密了呢。~~一道闪电划过后,~~我终于想明白了,这张图你不能单独看,上边的传统卷积是经过pooling以后的第一个卷积层,而下边卷积输入的浅粉色三角正是被pooling掉的像素。所以,下边的输出是上边的两倍,特征多出了一倍当然密啦。
空洞卷积
在全卷积网络中**,Feature Map上像素点的感受野取决于卷积和池化操作**。普通卷积的感受野每次只能增加两个像素,增长速度过于缓慢。传统卷积网络的感受野的增大一般采用池化操作来完成,但是池化操作在增大感受野的同时会降低图像的分辨率,从而丢失一些信息。而且对池化之后的图像在进行上采样会使很多细节信息无法还原,最终限制了分割的精度。
那么如何在不使用池化的情况下扩大感受野呢?
空洞卷积应运而生。顾名思义,空洞卷积就是往卷积操作中加入“空洞”(值为0的点)来增加感受野。
空洞卷积引入了扩张率(dilated ration)这个超参来制定空洞卷积上两个有效值之间的距离:扩张率为 r的空洞卷积,两个有效值之间有r-1个空洞,如图2所示。其中红色的点为有效值,绿色的放个为空洞。如图2.(a)所示, r = 1 r=1 r=1是空洞卷积变为普通卷积。
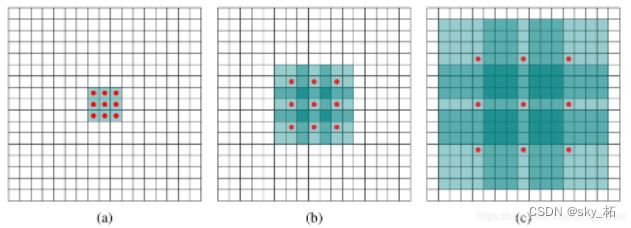
r=1 和 r=3 的空洞卷积的感受野分别是 7x7 和 15x15 ,但是它们的参数数量依旧是 9个。目前的深度学习框架对空洞卷积都支持的非常好,仅设置扩张率一个超参即可。
全连接条件随机场
使用条件随机场CRF提高分类精度。效果如下图,可以看到提升是非常明显的。具体CRF是什么原理呢?没有去研究,因为懒到了V3就舍弃了CRF。
5.2.2.2 DeepLabV2(2016/6/2)
原文:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
收录:TPAMI2017 (IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017)
Backbone:ResNet-101
Contributions:ASPP
改变:
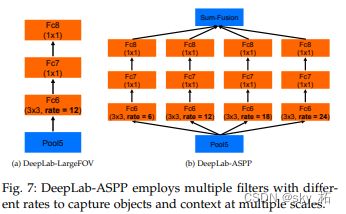
Deeplabv2是在v1上进行改进的:
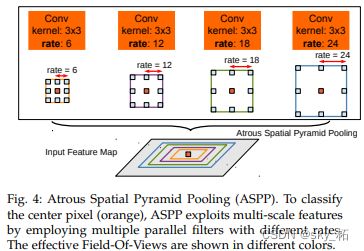
- 使用多尺度获得更好的分割效果(使用空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP))
- 基础层由VGG16转为ResNet
- 使用不同的学习策略
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)
核心思想:聚集不用尺度的感受野
作用:解决不同分割目标不同尺度的问题。
因为相同的事物在同一张图或不同图像中存在尺度上的差异。还是以这张图为例,图中的树存在多种尺寸,使用ASPP就能更好的对这些树进行分类。

ASPP如何融合到ResNet中,看图说话。将VGG16的conv6(空洞卷积),换成不同rate的空洞卷积,再跟上conv7,8,最后做个大融合(对应相加或1*1卷积)就OK了。
5.2.2.3 DeepLabV3 (2017/6/17)
原文:Rethinking Atrous Convolution for Semantic Image Segmentation
**Backbone:**ResNet-101
Contributions:
优化ASPP的结构,包括加入BN等
该模块级联了多个空洞卷积结构(Going deeper with atrous convolution)
Remove CRF(随机向量场)
具体改进:
1.舍弃了CRF,因为分类结果精度已经提高到不需要CRF了(也可能是CRF不起作用了)
另外两个贡献,一个是改进了ASPP,另一个是使用空洞卷积加深网络,这两者算是一个二选一吧,**是拓展网络的宽度,还是增加网络的深度。**一般说起DeepLab V3模型指的是前者,因为从大神给出的结果和后续发展来看,明显前者效果更好一些。
2.对于ASPP,做了两点改进。
- 一是在空洞卷积之后使用batch normalization(批量归一化操),
- 二是增加了1*1卷积分支和image pooling分支。
增加这两个分支是为了解决使用空洞卷积带来的问题:
随着rate的增大,一次空洞卷积覆盖到的有效像素(特征层本身的像素,相应的补零像素为非有效像素)会逐渐减小到1(这里没有图全靠脑补)。
因为随着扩张率的变大,会有越来越多的像素点的计算没法使用全部权重。当扩张率足够大时,只有中间的一个权重有作用,这时空洞卷积便退化成了 1x1卷积。这里丢失权重的缺点还是其次,重要的丢失了图像全局的信息。
这就与我们的初衷(获取更大范围的特征)相背离了。所以为了解决这个问题,
- 一是使用11的卷积,也就是当rate增大以后33卷积的退化形式,替代3*3卷积,减少参数个数;
- 另一点就是增加image pooling,可以叫做全局池化,来补充全局特征。具体做法是对每一个通道的像素取平均,之后再上采样到原来的分辨率。
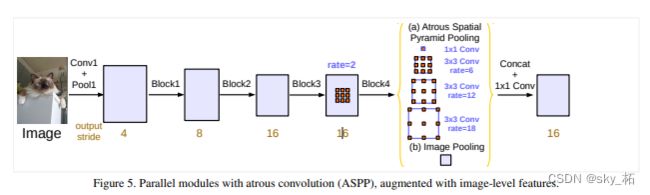
3.Going deeper with atrous convolution。为什么要加深网络呢,我理解的是为了获取更大的感受野。提到感受野自然离不开空洞卷积。还是看图说话,很显然pooling用多了特征层都快小的看不见了,所以大神给出了使用空洞卷积不断加深网络的一种思路

5.2.2.4 DeepLabV3+(CVPR2018)
原文: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
论文解读
代码:pythorch
Backbone: Xception
Contributions:
Xception
Encoder-decoder structure
动机:提升分割准确率
问题:
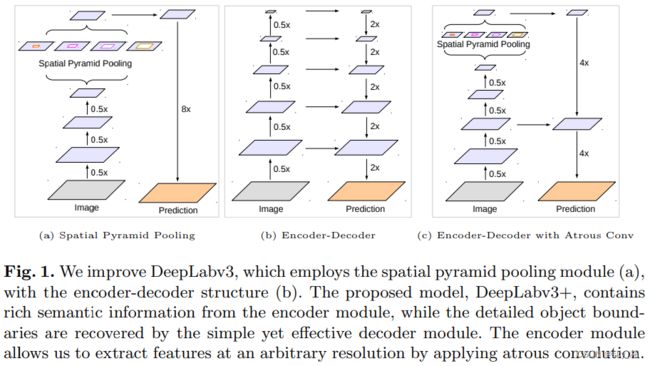
为了在多尺度上获得上下文信息,DeepLab V3使用了几个并行的不同rate的Atrous卷积(Atrous Spatial Pyramid Pooling, ASPP)。虽然在最后的特征图中包含了丰富的、多尺度的语义信息,但是由于骨干网络中存在跨步操作的池化和卷积层,这就导致特征图缺少了与对象边界有关的详细信息。
因此,如图1所示,在DeepLab V3+中,在ASPP的基础上加入了一个解码器模块
创新
- 提出了一个新型的编码器-解码器模型: 使用DeepLab v3作为高效的编码器,接入一个简单但有效的解码器模块,以精修分割结果,特别是物体的边界信息。
- 主干网络改为Xception模型,加速模型的计算,减少其计算消耗。
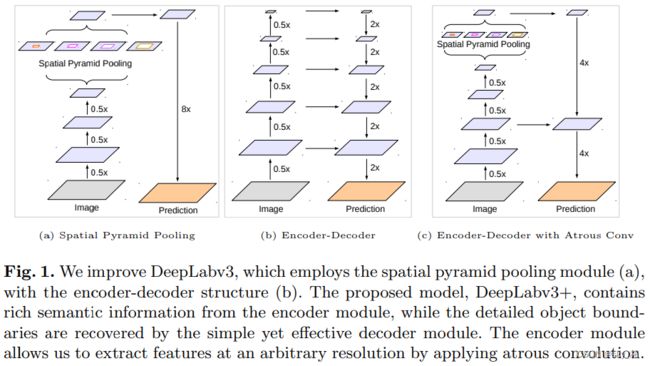
- 在ASPP和解码器模型中引入深度可分离卷积,构建更快更高效的编码器-解码器模型。
简述
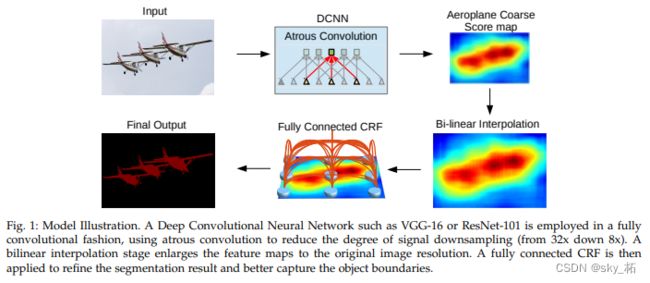
v3+ 最大的改进是将 DeepLab 的 DCNN 部分看做 Encoder,
将 DCNN 输出的特征图上采样成原图大小的部分看做 Decoder ,构成 Encoder+Decoder 体系,双线性插值上采样便是一个简单的 Decoder,而强化 Decoder 便可使模型整体在图像语义分割边缘部分取得良好的结果。
具体来说,DeepLabV3+ 在 stride = 16 的DeepLabv3 模型输出上采样 4x 后,将 DCNN 中 0.25x 的输出使用1x1的卷积降维后与之连接(concat)再使用3x3卷积处理后双线性插值上采样 4 倍后得到相对于 DeepLabv3 更精细的结果。
网络结构
空间金字塔(spatial pyramid pooling,SPP):通过在不同分辨率上以池化操作捕获丰富的上下文信息
encoder-decoder架构:逐渐的获得清晰的物体边界
1)一个编码器模块,用于逐步减小特征图,同时捕获更高级的语义信息;(
2)一个解码器模块,用于逐步恢复空间信息。
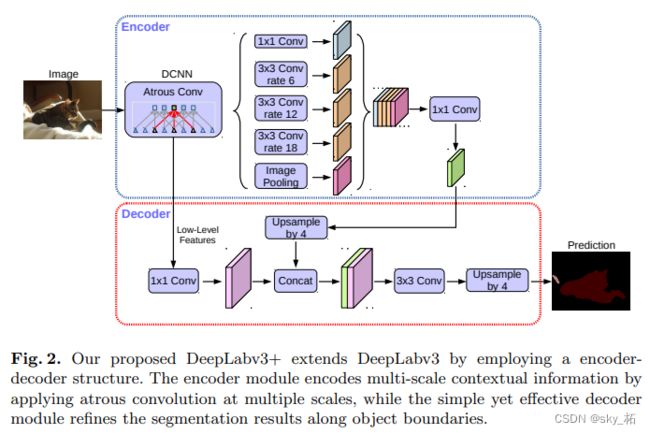
基于此,如图所示,将DeepLab V3作为编码器模块,在不同尺度应用不同rate的atrous卷积,来编码多尺度的上下文信息;同时在其后加入一个解码器模块,沿着物体边界进行优化,从而获取更锐利的分割结果。
Encoder
1、Backbone(主干网络)——将ResNet-101升级到了Xception
对应的是上面网络结构图中的DCNN(深度卷积神经网络)部分
backbone主要是为了提取特征
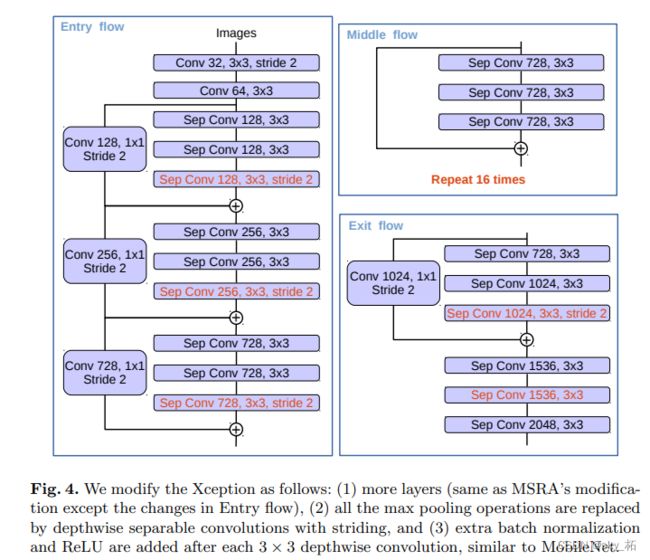
改进点:
(1)更深的Xception结构,不同的地方在于不修改entry flow network的结构,这是为了快速计算和有效使用内存
(2)将所有的卷积层和池化层用深度分离卷积Depthwise separable convolution进行替代,也就是下图中的Sep Conv
(3)每个3x3的深度卷积后都跟着BN和Relu
Xception
核心:使用了Depthwise separable convolution(深度可分离卷积)*。
Depthwise separable convolution的思想来自inception结构,是inception结构的一种极限情况。
Inception 首先给出了一种假设:
卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果。
在inception结构中,先对输入进行11的卷积,之后将通道分组,分别使用不同的33卷积提取特征,最后将各组结果串联在一起作为输出。

Depthwise separable convolution:把每一个通道作为一组。先对输入的每一个通道做33的卷积,将各个通道的结果串联后,再通过11的卷积调整到目标通道数。
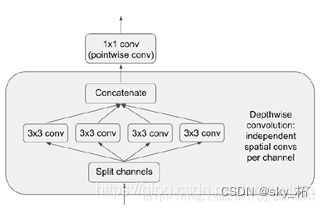
优点:
大幅缩减参数个数。幅度有多大呢?
举个简单的栗子,假设输入输出都是64通道,卷积核采用3*3,那么传统卷积的参数个数为3x3x64x64=36864
而Depthwise separable convolution为3x3x64+1x1x64x64=4672
Xception架构
引入了Entry/Middle/Exit三个flow,每个flow内部使用不同的重复模块,当然最最核心的属于中间不断分析、过滤特征的Middel flow。
Entry flow主要是用来不断下采样,减小空间维度;
中间则是不断学习关联关系,优化特征;
最终则是汇总、整理特征,用于交由FC来进行表达。
说完了backbone,再来说说V3+的整体结构。前三个版本都是backbone(ASPP)输出的结果直接双线性上采样到原始分辨率,非常简单粗暴的方法,下图中的(a)。用了三个版本,大神也觉得这样做太粗糙了,
于是吸取Encoder-Deconder的结构,下图中的(b),
增加了一个浅层到输出的skip层,下图中的c。
下面说说具体的skip方法。
- 首先,选取block2中的第二个卷积输出(看代码这个是固定的),使用1*1卷积调整通道数到48(减小通道数是为了降低其在最终结果中的比重),然后resize到指定的尺寸,也就是output stride
- 然后,**将ASPP的输出resize到output stride。**最后将两部分串联起来做两次33的卷积。最后的最后再做一次11的卷积,得到分类结果。最后的最后的最后将分类结果resize到原来的分辨率,嗯,还是熟悉的双线性采样。
2、ASPP(Atrous Spatial Pyramid Pooling)
高级特征经过ASPP的5个不同的操作得到5个不同的输出
5个操作包括1个1×1卷积,3个不同rate的空洞卷积,1个ImagePooling(全局平均池化之后再上采样到原来大小)。
卷积可以局部提取特征,ImagePooling可以全局提取特征,这样就得到了多尺度特征
特征融合在这里用concatenate的方法叠加,而不是直接相加
3、Encoder最终输出
我们看网络结构图中Decorder中的“Upsample by 4”和“Concat”可以推出backbone的两个输出:
一个是低级特征(low-level feature),这是个output=4x的输出;
另一个是高级特征,给ASPP的输入,这是个output=16x的输出
Decorder
**低级特征(来自主干网络的低层特征)**经过1x1卷积调整维度(用来减少输出的通道数。output stride=4x)(论文表明低级特征调整到48 channels时效果最好)
高级特征(编码器输出的特征)进行上采样4倍(双线性插值),让output stride从16x变为4x
然后将两个4x特征串联concatenate,后面接一些3×3卷积(细化特征.论文表明后面接2个输出channels=256的3x3卷积,输出效果较好),再上采样4倍(双线性插值)得到输出Dense Prediction
5.2.3 PSPNet金子塔型场景解析网络(2016/12/4 CVPR 2017)
PSPNet: Pyramid Scene Parsing Network
PSPNet模型学习笔记
语义分割——PSPNET
动机:
基于FCN模型的不足的改进
- 第一行中FCN算法误将船分割成车,显然一辆车在水上的概率是很小的,这种是属于错误匹配的误分割。
- 第二行中FCN算法误将摩天大厦分割成建筑物,摩天大厦和建筑物这两个类别本身是比较接近的,这种是属于类别相近的误分割。
- 第三行中FCN算法误将枕头分割成床,枕头本身区域较小,而且纹理和床较为接近,这种是属于不明显类别的误分割。
作者认为这些误分割都可以通过引入更多的上下文信息和多尺度信息进行解决,当分割层有更多全局信息和更合理的尺度信息时,出现上述几种误分割的概率就会相对低一些。
创新点:
提出了金字塔池化模块(SPP)来聚合背景信息;
简单来说就是在encoder之后得到feature map X,使用不同尺寸的kernel进行池化(avepooling)操作,之后对得到的feature map进行上采样,使得尺寸和X大小一样,然后进行级联,进而经过卷积操作得到map。和经典的FCN的区别是在encoder和decoder之间加入了PSP模块。
网络架构
在分割任务中,感受野的大小可以粗略地表明我们使用上下文信息能力。
基于这些问题,论文设计了如下图所示的模型架构,包括金字塔池化和更加有效的ResNet训练损失函数,模型架构如下图所示:
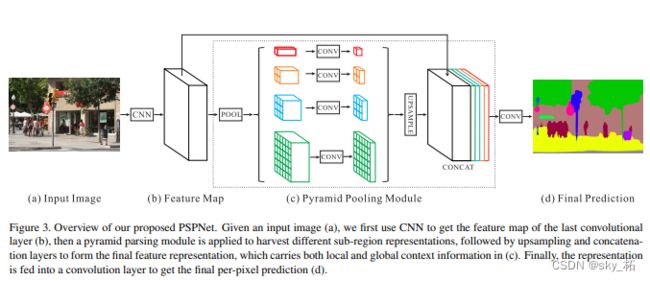
模型通过带有空洞卷积的ResNet作为主干网络提取特征图,大小是输入图像的1/8。
经过金字塔池化模块来获取语义信息,使用四种不同的层级的金字塔并上采样将其融合为原始特征图大小。经过一个卷积层得到预测的输出。
(与空间金字塔池化将不同层次的特征图平滑拼接后用于图像分类不同,以上的金字塔池化模块融合了四个比例的特征。
假设输入特征图尺寸为H×W×C。红色部分表示最粗糙的全局尺度的池化,之后按照比例将feature map分为不同子区域,形成不同区域的信息表达(如上图橘色部分为2×2,然后依次为3×3,6×6)。
池化后进行1×1卷积,调节通道数为输入通道数的1/4.然后将不同层次的特征双线性上采样至输入特征图大小。然后将所有层次的特征与原始特征图拼接,形成全局的先验表达(global prior representation)用于后续分割预测。
分析上述结构,可以看出尺度信息来自于不同层次的操作;上下文信息也通过不同尺度组合出更多的感受野区域;1×1卷积融合了通道信息。使得整个信息表达结合了局部和全局的特征表达。
)
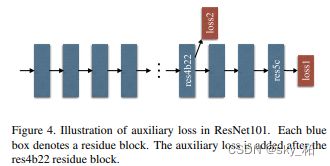
而第二点,更加有效的ResNet训练损失函数如下图所示,就是在ResNet101的基础上做了改进,除了使用后面的softmax分类做loss,额外的在第四阶段添加了一个辅助的loss,两个loss一起传播,使用不同的权重,共同优化参数。后续的实验证明这样做有利于快速收敛。
5.2.4UPerNet(ECCV2018)
原文:Unified Perceptual Parsing for Scene Understanding
笔记参考:
1.UPerNet学习笔记
解决的问题
考虑视觉识别同时处理多任务的可能性,提出新的任务(Unified Perceptual Parsing – UPP),并提出新的学习方法来解决它。
UPP任务主要存在以下问题:
1 没有单独的图像数据集包含所有级别的视觉信息标注,大量的数据集只是为了某个确定的任务种类设计,比如纹理检测、场景分析、表面识别等。
2 不同的识别任务对应不同的标注,比如分别有像素级别和图像级别的标注。
怎么解决的
1.我们提出了一个新的解析任务Unified Perceptual Parsing,它要求系统一次解析多个视觉概念
2.我们提出了一个名为UPerNet的新型网络,它具有层次结构,可以从多个图像数据集中学习异构数据。
3.该模型显示能够联合推断和发现图像下方丰富的视觉知识。
定义任务:
统一感知分析(Unified Perceptual Parsing), 该任务是指从给定的图像中尽可能多地识别不同的视觉概念。
结构分析
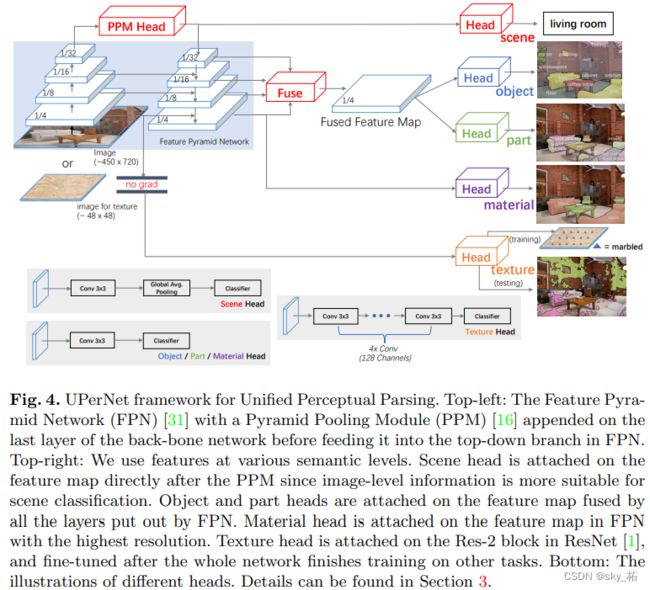
- 网络基于FPN架构(Feature Pyramid Network),注意这里区别于FCN。FPN架构之前在BiSeNet中简单提起过,使用跳线连接把高、中、低级语义特征融合起来。但FPN架构仍然存在问题,尽管理论感受野足够大,但实际上的感受野往往要远小于理论感受野。
- 在backbone网络的最后一层中引入PSPNet中的金字塔池化模块,然后再送入FPN的分支,用于克服感受野的限制。
- 网络的backbone是ResNet,将ResNet中每个stage输出的feature maps记为{C2,C3,C4,C5},FPN输出的feature maps记为{P2,P3,P4,P5},其中P5也是经过PPM后直接输出的feature map。降采样率为{4,8,16,32} 这里注意:每个stage的feature map在图中都有画出实体,并标上了对应的采样比例。
本文使用多个语义层次的特征。由于图像级信息更适合场景分类,
Scene head 直接被附加到 PPM 模块之后的特征图。
Object head 和 Part head 被附加到与来自 FPN 的所有层相融合的特征图。
Material head 被附加到 FPN 中带有最高分辨率的特征图。
Texture 被附加到 ResNet 中的 Res-2 模块,并在整个网络完成其他任务的训练之后进行优化,
这一设计背后的原因有 3 个:
纹理是最低级的感知属性,因此它纯粹基于明显的特征,无需任何高级的信息;
正确预测纹理的核心特征是在训练其他任务时被隐式学习的;
这一分支的感受野需要足够小,因此当一张正常大小的图像输入网络,它可以预测不同区域的不同标签。
各任务分类实现:
- 场景分类:场景标签(最高级语义属性)的标注是图像级别的,它的预估方式是通过对P5的feature maps进行全局均值池化,再加上线性分类器实现的
注意:P5特征图的降采样率相对较大,这样可以使特征在全局均值池化后更加集中于高等级语义信息 - 目标检测:实验发现融合FPN所有的特征图的效果,比只使用最高分辨率特征图(P2)的效果更好
- 目标分离:
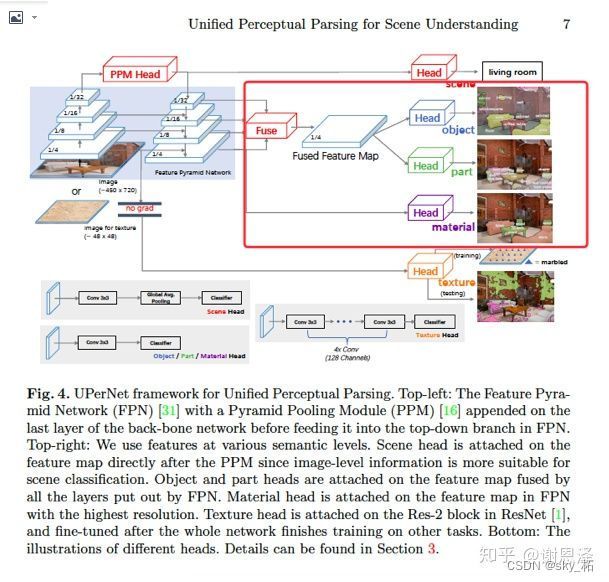
关于语义分割
网络结构如下,可以看到我红框框出的一部分是做语义分割的。上下两支是做场景分类和纹理解析的。我分析了下他的语义分割部分的代码。
一般语义分割像PSPNET,一般resnet50,做个8倍下采样,做conv5做 PPM(pyramid pooling),然后融合出结果,这样的话conv2-conv4丰富的特征并没有利用上。
而他们这个**upernet相当于是基于pspnet改进的,**在PPM融合后的特征,再分别和conv2-conv5分别做4次融合,融合方式类似于fpn, 最后融合这么多次融合出一个fused feature map, 并卷积出分割的结果。感觉特征融合非常充分,同时去掉了pspnet的辅助loss。
特征图金字塔网络FPN(Feature Pyramid Networks)
FPN网络详解
应用:
1干货 | 基于PIE-Engine AI的UperNet-SwinTransformer模型上传实践——以光伏目标提取
2.和swin的结合
3.mmsegmentation教程2:如何修改loss函数、指定训练策略、修改评价指标、指定iterators进行val指标输出
这一部分主要是针对configs/_ base _/models/upernet_swin.py
与swin
最后分割头接的是upernet,基于pspnet改进,在PPM融合后的特征,再分别和conv2-conv5分别做4次融合,融合方式类似于fpn, 最后融合这么多次融合出一个fused feature map
具体地,在4个stage中。每次stage后都会将output的feature map append进一个list
对于每个stage:
分别是:
1x128x128x128
1x256x64x64
1x512x32x32
1x1024x16x16
四组feature map喂入对应upernet的分支中做下图的特征融合,可以看到和检测的FPN非常的类似
# model settings
norm_cfg = dict(type='BN', requires_grad=True)
backbone_norm_cfg = dict(type='LN', requires_grad=True)
model = dict(
type='EncoderDecoder',
pretrained=None,
backbone=dict(
type='SwinTransformer',
pretrain_img_size=224,
embed_dims=96,
patch_size=4,
window_size=7,
mlp_ratio=4,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
strides=(4, 2, 2, 2),
out_indices=(0, 1, 2, 3),
qkv_bias=True,
qk_scale=None,
patch_norm=True,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.3,
use_abs_pos_embed=False,
act_cfg=dict(type='GELU'),
norm_cfg=backbone_norm_cfg),
decode_head=dict(
type='UPerHead',
in_channels=[96, 192, 384, 768],
in_index=[0, 1, 2, 3],
pool_scales=(1, 2, 3, 6),
channels=512,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=384,
in_index=2,
channels=256,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=19,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
进行复写,其实很好理解,upernet_swin.py只是模型的初始定义,你要是使用模型就需要修改一些东西,
比如你的分类数num_classes有可能不一样、你想换一个loss进行训练,就需要对upernet_swin.py进行复写,这里复写一定要注意格式,一定要保证复写中各个部件的层级关系一定要与upernet_swin.py的一样,
比如backbone是在model的dict之下的,decode_head是与backbone平级的。
通常情况下复写只需要对三个地方进行复写:
pretrained:是否使用预训练数据集
decode_head下面的num_classes
decode_head下面的loss_decode下面的type中的损失函数
6汇总图