【AidLux】基于Aidlux实现人流统计(YOLOv5⼈体检测+Bytetrack多⽬标⼈体追踪+业务逻辑
基于Aidlux实现人流统计(YOLOv5⼈体检测+Bytetrack多⽬标⼈体追踪+业务逻辑)
-
-
- AidLux是什么
- 基于ARM构建,为无处不在的智能设备赋能新生
- 跨Android/鸿蒙 + Linux 融合系统,带来颠覆性的生态体验
-
- 《Aidlux智慧安防AI实战训练营》作业心得
-
- 一、训练营课程
-
- (1)课程内容
- (2)学习目的
- 二、课程大作业
-
- (1)作业题目
- (2)实现效果
- (3)代码实现
- 三、学习心得
- 四、AidLux使用心得
首先介绍一下AidLux
AidLux是什么
AidLux是一个构建在ARM硬件上,基于创新性跨Android/鸿蒙 + Linux融合系统环境的智能物联网 (AIoT) 应用开发和部署平台。
基于ARM构建,为无处不在的智能设备赋能新生
ARM硬件平台作为智能物联网世界的重要基石,在我们的生活中无处不在 - 手机、平板、机器人、家电、生产流水线…,是上百亿智能设备的心脏。
AidLux基于ARM而构建,可轻松部署于海量的智能设备之上,为其带来全新的赋能和创新体验,焕发新的生命力。
赶快找一部身边的ARM手机、平板,或基于ARM主板的设备开始体验吧!
跨Android/鸿蒙 + Linux 融合系统,带来颠覆性的生态体验
Android/鸿蒙 - 为用户带来了卓越的多媒体交互式体验以及海量的数字化生活应用生态;
Linux - 基于安全、稳定、高效等优势,构建了服务端应用部署和应用(包含AI)开发的强大生产力生态;
AidLux,通过独特的Linux内核共享技术,将Android/鸿蒙与Linux完美的融合在一起,为用户打造了一个全新的生态体验。
《Aidlux智慧安防AI实战训练营》作业心得
一、训练营课程
(1)课程内容
- 智慧城市&CV项目落地行业背景
- 基于AidLux平台沉浸式AIoT开发流程
- 人体检测模型训练及部署教程
- 检测&多目标追踪移植部署流程
- 越界识别&警告提示算法实现流程
(2)学习目的
本人是CV方向研究生,训练营的内容可以帮助开拓思维。通过真实的项目实践,进一步了解AI项目的一般开发交付流程,增加实战经验与专业能力,拓宽自己的见识和思路。
二、课程大作业
(1)作业题目
在学习了越界识别的功能后,采用人体检测+人体追踪+业务功能的方式实现 人流统计。
(2)实现效果
通过SSH连接到手机/平板端的Aidlux,并打开对应的项目文件

实现效果
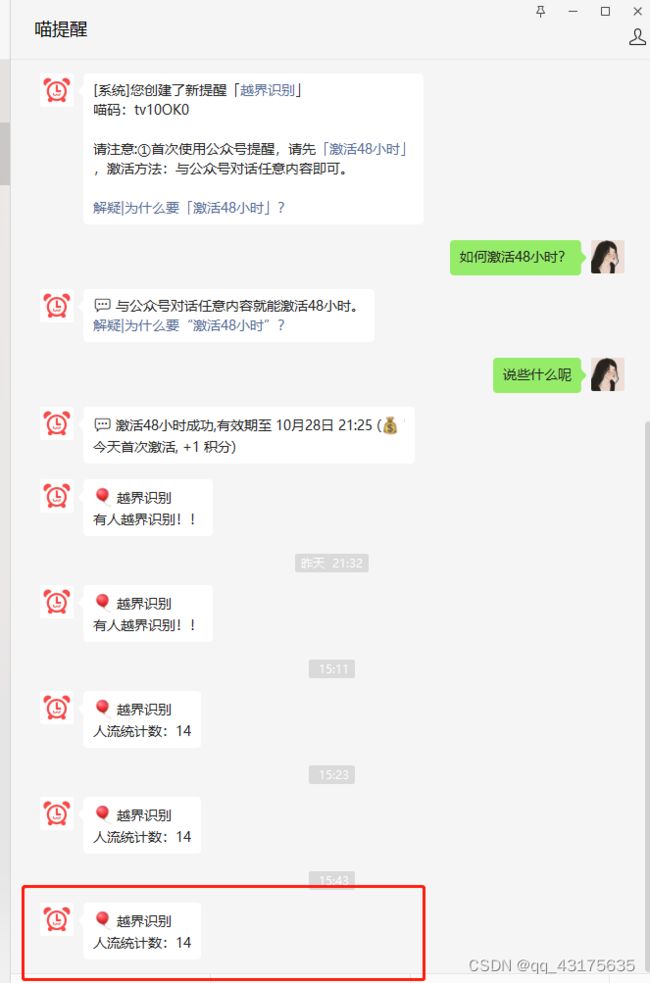
AidLux-人流计数
最后,喵提醒(公众号)会在微信上发送人流统计数。
(3)代码实现
aidlux文件夹 百度网盘提取码:x5sf
- aidlux
- pychache
- track
- cython_bbox-0.13
- tracker
- tracking_utils
- utils
- miaotixing.py
- utils.py
- video_to_image.py
- video.mp4
- yolov5_bytetrack.py
- yolov5_overstep.py
- yolov5.py
- yolov5n_best-fp16.tflite
yolov5_overstep.py
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res, scale_coords,process_points,is_in_poly,is_passing_line
import cv2
# bytetrack
from track.tracker.byte_tracker import BYTETracker
from track.utils.visualize import plot_tracking
import requests
import time
# 加载模型
model_path = '/home/lesson4_codes/aidlux/yolov5n_best-fp16.tflite'
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 载入模型
aidlite = aidlite_gpu.aidlite()
# 载入yolov5检测模型
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
tracker = BYTETracker(frame_rate=30)
track_id_status = {}
cap = cvs.VideoCapture("/home/lesson4_codes/aidlux/video.mp4")
frame_id = 0
count_person = 0
while True:
frame = cap.read()
key = cv2.waitKey(24)
if key == ord('q'):
break
if frame is None:
print("Camera cap over!")
break
frame_id += 1
if frame_id % 3 != 0:
continue
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# 目标追踪相关功能
det = []
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box)
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
### 人流计数识别功能实现 ###
# 1.绘制统计人流线
lines = [[186,249],[1235,366]]
cv2.line(res_img,(186,249),(1235,366),(255,255,0),3)
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]]
# 3. 人体和线段位置状态的判断(人体状态追踪判断)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
# 4. 判断是否有track_id越界,有的话保存成图片
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
count_person += 1
cv2.putText(res_img, "-1 to 1 person_count"+ str(count_person),(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,255),2)
cvs.imshow(res_img)
print("视频结束!")
# 5.越界识别+喵提醒
# 填写对应的喵码
id = '' # 填写自己的喵码
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "人流统计数:"+str(count_person)
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers)
print("发送成功!")
三、学习心得
最开始是冲着江大白老师说,课程讲解会非常详细来报的名。学下来,真的是每一步都巨详细,不论是项目背景的介绍还是关于云服务器训练yolov5,AidLux操作等都讲解细致,因为自己也有过yolov5和云服务器使用的经验,所以学习过程还是比较顺利的,就比较有成就感,也非常有继续学下去的动力。
喵提醒这个也挺好玩的,通过python程序向微信发送信息。
AidLux对我们研究生写论文或者写项目都提供了些新的思路,电脑也不用装ubuntu系统就可以实现在linux环境下的操作,非常nice~
四、AidLux使用心得
通过云服务器对模型进行训练,使用AidLux轻松将安卓设备变成边缘端设备进行AI处理,这对没有高性能设备的友友们是非常友好的,值得一试。