毕业设计:深度学习卷积神经网络垃圾分类系统 - 深度学习 神经网络 图像识别 垃圾分类 算法 小程序
文章目录
- 0 简介
- 1 背景意义
- 2 数据集
- 3 数据探索
- 4 数据增广(数据集补充)
- 5 垃圾图像分类
-
- 5.1 迁移学习
-
- 5.1.1 什么是迁移学习?
- 5.1.2 为什么要迁移学习?
- 5.2 模型选择
- 5.3 训练环境
-
- 5.3.1 硬件配置
- 5.3.2 软件配置
- 5.4 训练过程
- 5.5 模型分类效果(PC端)
- 6 构建垃圾分类小程序
-
- 6.1 小程序功能
- 6.2 分类测试
- 6.3 垃圾分类小提示
- 6.4 答题模块
- 7 关键代码
- 8 最后
0 简介
今天学长向大家介绍一个机器视觉项目
深度学习卷积神经网络垃圾分类系统
1 背景意义
近年来,随着我国经济的快速发展,国家各项建设都蒸蒸日上,成绩显著。但与此同时,也让资源与环境受到了严重破坏。这种现象与垃圾分类投放时的不合理直接相关,而人们对于环境污染问题反映强烈却束手无策,这两者间的矛盾日益尖锐。人们日常生活中的垃圾主要包括有害垃圾、厨余垃圾、可回收垃圾以及其他垃圾这四类,对不同类别的垃圾应采取不同分类方法,如果投放不当,可能会导致各种环境污染问题。合理地进行垃圾分类是有效进行垃圾处理、减少环境污染与资源再利用中的关键举措,也是目前最合适最有效的科学管理方式,利用现有的生产水平将日常垃圾按类别处理、利用有效物质和能量、填埋无用垃圾等。这样既能够提高垃圾资源处理效率,又能缓解环境污染问题。
而对垃圾的分类首先是在图像识别的基础上的,因此本文想通过使用近几年来发展迅速的深度学习方法设计一个垃圾分类系统,从而实现对日常生活中常见垃圾进行智能识别分类,提高人们垃圾分类投放意识,同时避免人们错误投放而产生的环境污染。
2 数据集
数据集采用了中国发布的垃圾分类标准,该标准将人们日常生活中常见的垃圾分为了四大类。其中,将废弃的玻璃、织物、家具以及电器电子产品等适合回收同时可循环利用的废弃物归为可回收垃圾。将剩菜剩饭、果皮果壳、花卉绿植以及其他餐厨垃圾等容易腐烂的废弃物归为厨余垃圾。将废电池、废药品、废灯管等对人们身体健康和自然环境有害而且应当门处理的废弃物归为有害垃圾。除以上三类垃圾之外的废弃物都归为其他垃圾。
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)

3 数据探索
我们先简单的大致看看数据的情况
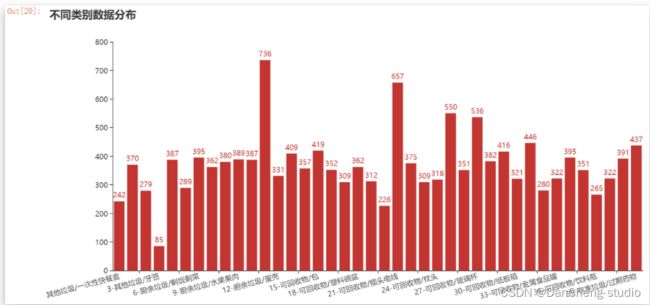
所得的垃圾图片数据集中有40个二级类别,图片数量合计 14802张。由图3-1可以看出,各个垃圾类别的图像数据量不均衡,其中图片数据量较少的类别有:类别0(一次性快餐盒)、类别3(牙签)、类别20(快递纸袋);数据量较多的类别是:类别11(菜叶根)、类别21(插头电线)、类别25(毛绒玩具)。
4 数据增广(数据集补充)
数据增广就是对基础数据集进行扩充,避免因为数据集太少导致在模型训练过程可能出现的过拟合现象,以此来提高模型泛化能力,达到更好的效果。根据扩充数据集的来源可分为两类:内部数据增广是对基础数据集进行水平翻转、垂直翻转、高斯噪声以及高斯模糊等变换操作,来产生新的特征;而外部数据增广是引入新的高质量外部数据来扩充数据集,包括数据爬取与数据筛选两个步骤。
数据爬取是通过网络爬虫技术来实现的,爬虫的流程是,首先向远程服务器端发送请求,获取目标网页的HTML文件;然后跟踪这个链接文件,获取文件数据。各种搜索引擎就是通过爬虫技术来实现网页数据更新,爬取的效率直接决定了搜索的效果。
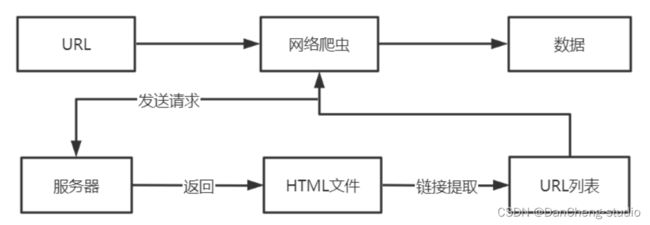
根据流程图可以看到,爬虫的流程与用户浏览网页的过程相似,首先输入目标URL地址,向服务器发送请求,接着服务器端会返回包含大量链接的HTML文件,然后提取这些链接将其组成URL列表,通过串行或并行方式从服务器端中下载数据。
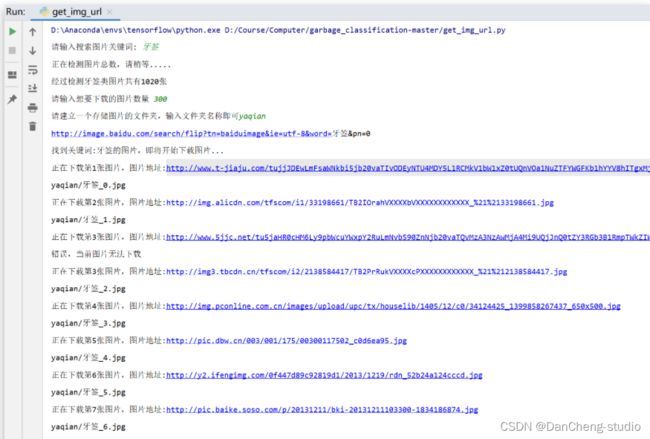
由于基础数据集中类别数量不均衡,所以本设计使用网络爬虫方式从百度图库对数量较少的类别进行数据扩充,首先输入想要爬取的图片名称关键字,然后输入想要爬取图片的数量以及存放的文件夹之后,进行图片爬取。
5 垃圾图像分类
5.1 迁移学习
5.1.1 什么是迁移学习?
迁移学习是指在一个数据集上,重新利用之前已经训练过的卷积神经网络,并将其迁移到另外的数据集上。
5.1.2 为什么要迁移学习?
卷积神经网络前面的层提取的是图像的纹理、色彩等特征,而越靠近网络后端,提取的特征就会越高级、抽象。所以常用的微调方法是,保持网络中其他参数不变,只修改预训练网络的最后几层,最后几层的参数在新数据集上重新训练得到。其他层的参数保持不变,作为特征提取器,之后再使用较小的学习率训练整个网络。因为从零开始训练整个卷积网络是非常困难的,而且要花费大量的时间以及计算资源,所以采取迁移学习的方式是一种有效策略。
通常在非常大的数据集上对ConvNet进行预训练,然后将ConvNet用作初始化或者是固定特征提取器,以下是两个主要的迁移学习方法:
1.微调卷积网络。使用预训练的网络来初始化网络而不使用随机初始化,比较常用的方法是使用在ImageNet数据集上训练好的模型参数进行初始化,然后训练自己的数据集。
2.将卷积网络作为固定特征提取器。冻结除了全连接层外的所有其他层的权重,将最后的那个全连接层替换为具有随机权重的层,然后只对该层进行训练。
要使用深度学习方法来解决垃圾图像识别分类问题,就需要大量的垃圾图片数据集,因为当数据集太小时,一旦加深模型结构,就很可能出现过拟合的情况,训练出的模型泛化能力不足,识别准确率不高。而基于迁移学习的方法,预训练模型已经具备了提取图像基本特征基的能力,这就能在一定程度上减缓过拟合发生的可能性,将预模型迁移到垃圾图像数据集上进行微调训练,提高识别准确率。
5.2 模型选择
采用迁移学习的方式导入预训练模型,冻结特征提取层,进行微调训练,选取了SeNet154、Se_ResNet50、Se_ResNext101、ResNext101_32x16d_WSL四种模型进行对比实验,选取结果较好的模型进行调优。其中,ResNext101_32x16d_WS预训练模型是由FaceBook在2019年开源的
SeNet154结构
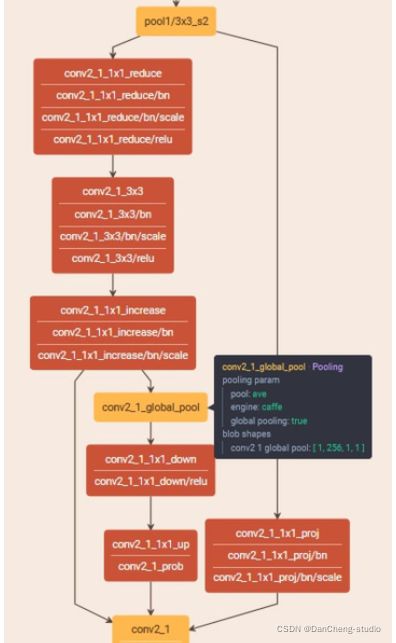
学长采用的模型结构:

采用ResNext101_32x16d_WSL网络作为基本的网络结构进行迁移学习,将CBAM注意力机制模块添加在首层卷积层,来增强图像特征表征能力,关注图像的重要特征抑制不必要的特征,固定除全连接层之外的其他层的权重。为降低过拟合,在模型全连接层添加了Dropout层,损失函数采用交叉熵损失函数(CrossEntropyLoss),优化函数对比了SGD和Adam,Adam在起始收敛速度快,但最终SGD精度高,所以采用了SGD。
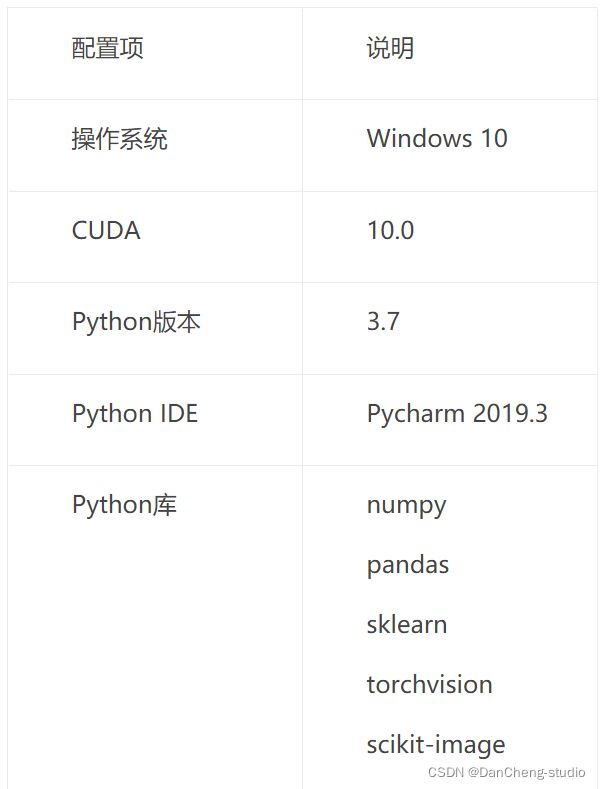
5.3 训练环境
5.3.1 硬件配置

5.3.2 软件配置
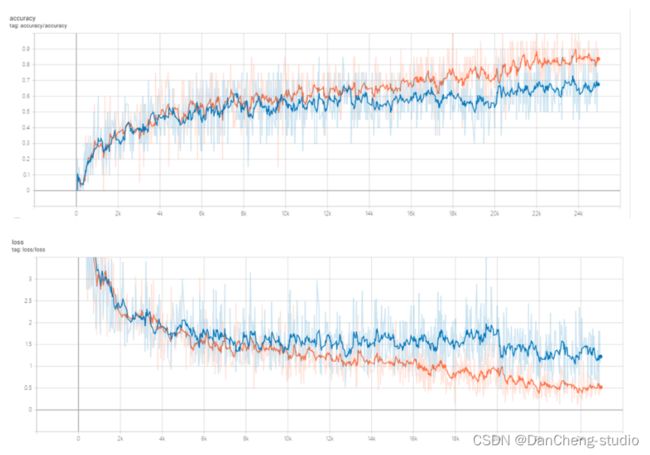
5.4 训练过程
构建好模型结构后,设置数据集加载路径,在搭建好的环境中进行模型训练,将训练过程中每轮迭代的Train Loss、Valid Loss、Train Acc、Valid Acc等数据保存到log日志文件中,然后使用matplotlib库绘制在训练集和测试集上的Accuracy跟Loss的变化曲线。
目前模型训练集准确度83.8%,测试集准确度67.5%,仍有待提高。。
5.5 模型分类效果(PC端)

6 构建垃圾分类小程序
学长设计的垃圾分类系统的核心功能是从本地相册上传照片或拍照上传照片进行识别分类,除此之外,还引入了语音识别功能、文字搜索功能、垃圾分类答题功能等满足用户的不同需求。系统的模块设计如下图所示。
·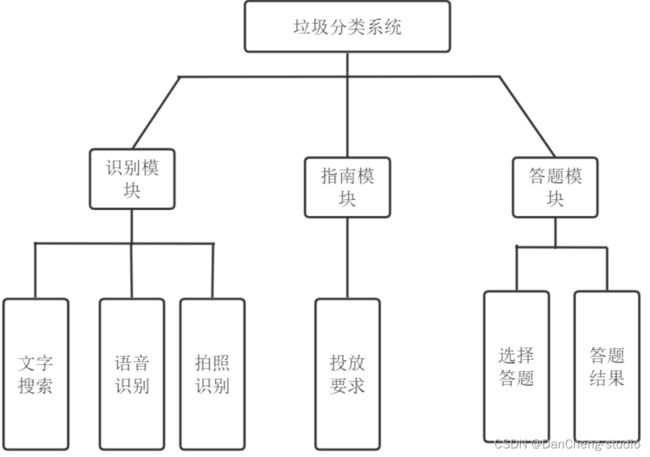
其中识别模块是用户选择识别功能,包含拍照/相册识别,语音识别、文字搜索等功能,根据所选城市的不同展示相应的垃圾类别;指南功能模块是根据所选城市的不同介绍各种垃圾的种类以及投放要求;答题模块实现垃圾种类的选择答题功能。
6.1 小程序功能
识别模块的功能包括文字搜索、语音识别、拍照识别等,该模块界面设计如图所示:

首先选择用户所在城市,然后选择使用的搜索方式,当通过三种搜索方式搜索不到相应垃圾类别时,可以通过反馈功能将未识别的垃圾名称向后台反馈信息,以便进一步完善系统。系统核心功能为拍照识别功能,拍照识别功能即调用在前面已经部署在华为云Model Arts平台上的垃圾分类识别模型,对用户从手机端提交的垃圾图片进行在线识别分类并返回识别结果,调用过程中用到了小程序的云函数功能。
6.2 分类测试
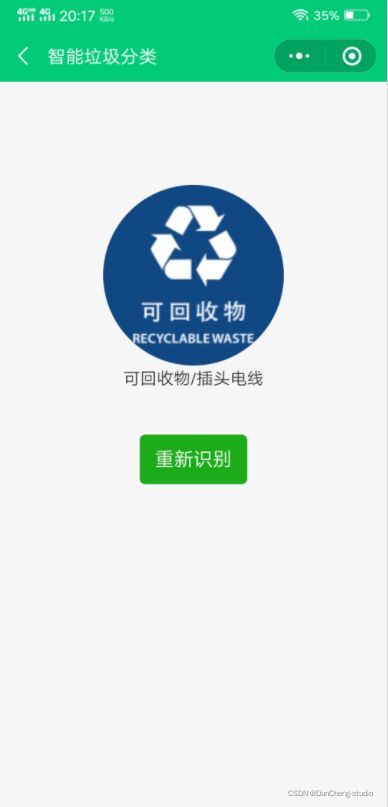
6.3 垃圾分类小提示
指南模块实现的功能是根据用户所选择的城市,将云数据库中的数据展示给用户,介绍目前不同城市发布的垃圾分类规则及投放的要求,如下图所示:



6.4 答题模块
答题模块也是根据用户所选城市的不同,测评用户对其所在城市垃圾分类规则了解的程度,以此来科普垃圾分类知识以及增强人们垃圾分类的意识,该界面如下图所示,在答完题后显示分数以及正确答案。


答题答案表
├─ 其他垃圾_PE塑料袋
├─ 其他垃圾_U型回形针
├─ 其他垃圾_一次性杯子
├─ 其他垃圾_一次性棉签
├─ 其他垃圾_串串竹签
├─ 其他垃圾_便利贴
├─ 其他垃圾_创可贴
├─ 其他垃圾_卫生纸
├─ 其他垃圾_厨房手套
├─ 其他垃圾_厨房抹布
├─ 其他垃圾_口罩
├─ 其他垃圾_唱片
├─ 其他垃圾_图钉
├─ 其他垃圾_大龙虾头
├─ 其他垃圾_奶茶杯
├─ 其他垃圾_干燥剂
├─ 其他垃圾_彩票
├─ 其他垃圾_打泡网
├─ 其他垃圾_打火机
├─ 其他垃圾_搓澡巾
├─ 其他垃圾_果壳
├─ 其他垃圾_毛巾
├─ 其他垃圾_涂改带
├─ 其他垃圾_湿纸巾
├─ 其他垃圾_烟蒂
├─ 其他垃圾_牙刷
├─ 其他垃圾_电影票
├─ 其他垃圾_电蚊香
├─ 其他垃圾_百洁布
├─ 其他垃圾_眼镜
├─ 其他垃圾_眼镜布
├─ 其他垃圾_空调滤芯
├─ 其他垃圾_笔
├─ 其他垃圾_胶带
├─ 其他垃圾_胶水废包装
├─ 其他垃圾_苍蝇拍
├─ 其他垃圾_茶壶碎片
├─ 其他垃圾_草帽
├─ 其他垃圾_菜板
├─ 其他垃圾_车票
├─ 其他垃圾_酒精棉
├─ 其他垃圾_防霉防蛀片
├─ 其他垃圾_除湿袋
├─ 其他垃圾_餐巾纸
├─ 其他垃圾_餐盒
├─ 其他垃圾_验孕棒
├─ 其他垃圾_鸡毛掸
├─ 厨余垃圾_八宝粥
├─ 厨余垃圾_冰激凌
├─ 厨余垃圾_冰糖葫芦
├─ 厨余垃圾_咖啡
├─ 厨余垃圾_圣女果
├─ 厨余垃圾_地瓜
├─ 厨余垃圾_坚果
├─ 厨余垃圾_壳
├─ 厨余垃圾_巧克力
├─ 厨余垃圾_果冻
├─ 厨余垃圾_果皮
├─ 厨余垃圾_核桃
├─ 厨余垃圾_梨
├─ 厨余垃圾_橙子
├─ 厨余垃圾_残渣剩饭
├─ 厨余垃圾_水果
├─ 厨余垃圾_泡菜
├─ 厨余垃圾_火腿
├─ 厨余垃圾_火龙果
├─ 厨余垃圾_烤鸡
├─ 厨余垃圾_瓜子
├─ 厨余垃圾_甘蔗
├─ 厨余垃圾_番茄
├─ 厨余垃圾_秸秆杯
├─ 厨余垃圾_秸秆碗
├─ 厨余垃圾_粉条
├─ 厨余垃圾_肉类
├─ 厨余垃圾_肠
├─ 厨余垃圾_苹果
├─ 厨余垃圾_茶叶
├─ 厨余垃圾_草莓
├─ 厨余垃圾_菠萝
├─ 厨余垃圾_菠萝蜜
├─ 厨余垃圾_萝卜
├─ 厨余垃圾_蒜
├─ 厨余垃圾_蔬菜
├─ 厨余垃圾_薯条
├─ 厨余垃圾_薯片
├─ 厨余垃圾_蘑菇
├─ 厨余垃圾_蛋
├─ 厨余垃圾_蛋挞
├─ 厨余垃圾_蛋糕
├─ 厨余垃圾_豆
├─ 厨余垃圾_豆腐
├─ 厨余垃圾_辣椒
├─ 厨余垃圾_面包
├─ 厨余垃圾_饼干
├─ 厨余垃圾_鸡翅
├─ 可回收物_不锈钢制品
├─ 可回收物_乒乓球拍
├─ 可回收物_书
├─ 可回收物_体重秤
├─ 可回收物_保温杯
├─ 可回收物_保鲜膜内芯
├─ 可回收物_信封
├─ 可回收物_充电头
├─ 可回收物_充电宝
├─ 可回收物_充电牙刷
├─ 可回收物_充电线
├─ 可回收物_凳子
├─ 可回收物_刀
├─ 可回收物_包
├─ 可回收物_单车
├─ 可回收物_卡
├─ 可回收物_台灯
├─ 可回收物_吊牌
├─ 可回收物_吹风机
├─ 可回收物_呼啦圈
├─ 可回收物_地球仪
├─ 可回收物_地铁票
├─ 可回收物_垫子
├─ 可回收物_塑料制品
├─ 可回收物_太阳能热水器
├─ 可回收物_奶粉桶
├─ 可回收物_尺子
├─ 可回收物_尼龙绳
├─ 可回收物_布制品
├─ 可回收物_帽子
├─ 可回收物_手机
├─ 可回收物_手电筒
├─ 可回收物_手表
├─ 可回收物_手链
├─ 可回收物_打包绳
├─ 可回收物_打印机
├─ 可回收物_打气筒
├─ 可回收物_扫地机器人
├─ 可回收物_护肤品空瓶
├─ 可回收物_拉杆箱
├─ 可回收物_拖鞋
├─ 可回收物_插线板
├─ 可回收物_搓衣板
├─ 可回收物_收音机
├─ 可回收物_放大镜
├─ 可回收物_日历
├─ 可回收物_暖宝宝
├─ 可回收物_望远镜
├─ 可回收物_木制切菜板
├─ 可回收物_木桶
├─ 可回收物_木棍
├─ 可回收物_木质梳子
├─ 可回收物_木质锅铲
├─ 可回收物_木雕
├─ 可回收物_枕头
├─ 可回收物_果冻杯
├─ 可回收物_桌子
├─ 可回收物_棋子
├─ 可回收物_模具
├─ 可回收物_毯子
├─ 可回收物_水壶
├─ 可回收物_水杯
├─ 可回收物_沙发
├─ 可回收物_泡沫板
├─ 可回收物_灭火器
├─ 可回收物_灯罩
├─ 可回收物_烟灰缸
├─ 可回收物_热水瓶
├─ 可回收物_燃气灶
├─ 可回收物_燃气瓶
├─ 可回收物_玩具
├─ 可回收物_玻璃制品
├─ 可回收物_玻璃器皿
├─ 可回收物_玻璃壶
├─ 可回收物_玻璃球
├─ 可回收物_瑜伽球
├─ 可回收物_电动剃须刀
├─ 可回收物_电动卷发棒
├─ 可回收物_电子秤
├─ 可回收物_电熨斗
├─ 可回收物_电磁炉
├─ 可回收物_电脑屏幕
├─ 可回收物_电视机
├─ 可回收物_电话
├─ 可回收物_电路板
├─ 可回收物_电风扇
├─ 可回收物_电饭煲
├─ 可回收物_登机牌
├─ 可回收物_盒子
├─ 可回收物_盖子
├─ 可回收物_盘子
├─ 可回收物_碗
├─ 可回收物_磁铁
├─ 可回收物_空气净化器
├─ 可回收物_空气加湿器
├─ 可回收物_笼子
├─ 可回收物_箱子
├─ 可回收物_纸制品
├─ 可回收物_纸牌
├─ 可回收物_罐子
├─ 可回收物_网卡
├─ 可回收物_耳套
├─ 可回收物_耳机
├─ 可回收物_衣架
├─ 可回收物_袋子
├─ 可回收物_袜子
├─ 可回收物_裙子
├─ 可回收物_裤子
├─ 可回收物_计算器
├─ 可回收物_订书机
├─ 可回收物_话筒
├─ 可回收物_豆浆机
├─ 可回收物_路由器
├─ 可回收物_轮胎
├─ 可回收物_过滤网
├─ 可回收物_遥控器
├─ 可回收物_量杯
├─ 可回收物_金属制品
├─ 可回收物_钉子
├─ 可回收物_钥匙
├─ 可回收物_铁丝球
├─ 可回收物_铅球
├─ 可回收物_铝制用品
├─ 可回收物_锅
├─ 可回收物_锅盖
├─ 可回收物_键盘
├─ 可回收物_镊子
├─ 可回收物_闹铃
├─ 可回收物_雨伞
├─ 可回收物_鞋
├─ 可回收物_音响
├─ 可回收物_餐具
├─ 可回收物_餐垫
├─ 可回收物_饰品
├─ 可回收物_鱼缸
├─ 可回收物_鼠标
├─ 有害垃圾_指甲油
├─ 有害垃圾_杀虫剂
├─ 有害垃圾_温度计
├─ 有害垃圾_灯
├─ 有害垃圾_电池
├─ 有害垃圾_电池板
├─ 有害垃圾_纽扣电池
├─ 有害垃圾_胶水
├─ 有害垃圾_药品包装
├─ 有害垃圾_药片
├─ 有害垃圾_药瓶
├─ 有害垃圾_药膏
├─ 有害垃圾_蓄电池
└─ 有害垃圾_血压计
7 关键代码
import tensorflow as tf
import linecache
import cv2
import numpy as np
import os
from select_object import pretreatment_image
train_images_path = 'D:/WorkSpace/Python/trash_classify_dataset/dataset/'
train_labels_path = 'D:/WorkSpace/Python/trash_classify_dataset/train_label.txt'
test_images_path = 'D:/WorkSpace/Python/trash_classify_dataset/dataset/'
test_labels_path = 'D:/WorkSpace/Python/trash_classify_dataset/test_label.txt'
classify_num = 50
train_images_num = 29081
test_images_num = 3232
def load_train_dataset(index): # 从1开始
if index > train_images_num:
if index % train_images_num == 0:
index = train_images_num
else:
index %= train_images_num
line_str = linecache.getline(train_labels_path, index)
image_name, image_label = line_str.split(' ')
image = cv2.imread(train_images_path + image_name)
# cv2.imshow('pic',image)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
return image, image_label
def combine_train_dataset(count, size):
train_images_load = np.zeros(shape=(size, 224, 224, 3))
train_labels_load = np.zeros(shape=(size, classify_num))
for i in range(size):
train_images_load[i], train_labels_index = load_train_dataset(count + i + 1)
train_labels_load[i][int(train_labels_index) - 1] = 1.0
count += size
return train_images_load, train_labels_load, count
def load_test_dataset(index): # 从1开始
if index > test_images_num:
if index % test_images_num == 0:
index = test_images_num
else:
index %= test_images_num
line_str = linecache.getline(test_labels_path, index)
image_name, image_label = line_str.split(' ')
image = cv2.imread(test_images_path + image_name)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
return image, image_label
def combine_test_dataset(count, size):
test_images_load = np.zeros(shape=(size, 224, 224, 3))
test_labels_load = np.zeros(shape=(size, classify_num))
for i in range(size):
test_images_load[i], test_labels_index = load_test_dataset(count + i + 1)
test_labels_load[i][int(test_labels_index) - 1] = 1.0
count += size
return test_images_load, test_labels_load, count
# # 通过L2正则化防止过拟合
# def weight_variable_with_loss(shape, stddev, lam):
# weight = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
# if lam is not None:
# weight_loss = tf.multiply(tf.nn.l2_loss(weight), lam, name='weight_loss')
# tf.add_to_collection('losses', weight_loss)
# return weight
def weight_variable(shape, n, use_l2, lam):
weight = tf.Variable(tf.truncated_normal(shape, stddev=1 / n))
# L2正则化
if use_l2 is True:
weight_loss = tf.multiply(tf.nn.l2_loss(weight), lam, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return weight
def bias_variable(shape):
bias = tf.Variable(tf.constant(0.1, shape=shape))
return bias
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 输入层
with tf.name_scope('input_layer'):
x_input = tf.placeholder(tf.float32, [None, 224, 224, 3])
y_input = tf.placeholder(tf.float32, [None, classify_num])
keep_prob = tf.placeholder(tf.float32)
is_training = tf.placeholder(tf.bool)
is_use_l2 = tf.placeholder(tf.bool)
lam = tf.placeholder(tf.float32)
learning_rate = tf.placeholder(tf.float32)
# 数据集平均RGB值
mean = tf.constant([159.780, 139.802, 119.047], dtype=tf.float32, shape=[1, 1, 1, 3])
x_input = x_input - mean
# 第一个卷积层 size:224
# 卷积核1[3, 3, 3, 64]
# 卷积核2[3, 3, 64, 64]
with tf.name_scope('conv1_layer'):
w_conv1 = weight_variable([3, 3, 3, 64], 64, use_l2=False, lam=0)
b_conv1 = bias_variable([64])
conv_kernel1 = conv2d(x_input, w_conv1)
bn1 = tf.layers.batch_normalization(conv_kernel1, training=is_training)
conv1 = tf.nn.relu(tf.nn.bias_add(bn1, b_conv1))
w_conv2 = weight_variable([3, 3, 64, 64], 64, use_l2=False, lam=0)
b_conv2 = bias_variable([64])
conv_kernel2 = conv2d(conv1, w_conv2)
bn2 = tf.layers.batch_normalization(conv_kernel2, training=is_training)
conv2 = tf.nn.relu(tf.nn.bias_add(bn2, b_conv2))
pool1 = max_pool_2x2(conv2) # 224*224 -> 112*112
result1 = pool1
# 第二个卷积层 size:112
# 卷积核3[3, 3, 64, 128]
# 卷积核4[3, 3, 128, 128]
with tf.name_scope('conv2_layer'):
w_conv3 = weight_variable([3, 3, 64, 128], 128, use_l2=False, lam=0)
b_conv3 = bias_variable([128])
conv_kernel3 = conv2d(result1, w_conv3)
bn3 = tf.layers.batch_normalization(conv_kernel3, training=is_training)
conv3 = tf.nn.relu(tf.nn.bias_add(bn3, b_conv3))
w_conv4 = weight_variable([3, 3, 128, 128], 128, use_l2=False, lam=0)
b_conv4 = bias_variable([128])
conv_kernel4 = conv2d(conv3, w_conv4)
bn4 = tf.layers.batch_normalization(conv_kernel4, training=is_training)
conv4 = tf.nn.relu(tf.nn.bias_add(bn4, b_conv4))
pool2 = max_pool_2x2(conv4) # 112*112 -> 56*56
result2 = pool2
# 第三个卷积层 size:56
# 卷积核5[3, 3, 128, 256]
# 卷积核6[3, 3, 256, 256]
# 卷积核7[3, 3, 256, 256]
with tf.name_scope('conv3_layer'):
w_conv5 = weight_variable([3, 3, 128, 256], 256, use_l2=False, lam=0)
b_conv5 = bias_variable([256])
conv_kernel5 = conv2d(result2, w_conv5)
bn5 = tf.layers.batch_normalization(conv_kernel5, training=is_training)
conv5 = tf.nn.relu(tf.nn.bias_add(bn5, b_conv5))
w_conv6 = weight_variable([3, 3, 256, 256], 256, use_l2=False, lam=0)
b_conv6 = bias_variable([256])
conv_kernel6 = conv2d(conv5, w_conv6)
bn6 = tf.layers.batch_normalization(conv_kernel6, training=is_training)
conv6 = tf.nn.relu(tf.nn.bias_add(bn6, b_conv6))
w_conv7 = weight_variable([3, 3, 256, 256], 256, use_l2=False, lam=0)
b_conv7 = bias_variable([256])
conv_kernel7 = conv2d(conv6, w_conv7)
bn7 = tf.layers.batch_normalization(conv_kernel7, training=is_training)
conv7 = tf.nn.relu(tf.nn.bias_add(bn7, b_conv7))
pool3 = max_pool_2x2(conv7) # 56*56 -> 28*28
result3 = pool3
# 第四个卷积层 size:28
# 卷积核8[3, 3, 256, 512]
# 卷积核9[3, 3, 512, 512]
# 卷积核10[3, 3, 512, 512]
with tf.name_scope('conv4_layer'):
w_conv8 = weight_variable([3, 3, 256, 512], 512, use_l2=False, lam=0)
b_conv8 = bias_variable([512])
conv_kernel8 = conv2d(result3, w_conv8)
bn8 = tf.layers.batch_normalization(conv_kernel8, training=is_training)
conv8 = tf.nn.relu(tf.nn.bias_add(bn8, b_conv8))
w_conv9 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv9 = bias_variable([512])
conv_kernel9 = conv2d(conv8, w_conv9)
bn9 = tf.layers.batch_normalization(conv_kernel9, training=is_training)
conv9 = tf.nn.relu(tf.nn.bias_add(bn9, b_conv9))
w_conv10 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv10 = bias_variable([512])
conv_kernel10 = conv2d(conv9, w_conv10)
bn10 = tf.layers.batch_normalization(conv_kernel10, training=is_training)
conv10 = tf.nn.relu(tf.nn.bias_add(bn10, b_conv10))
pool4 = max_pool_2x2(conv10) # 28*28 -> 14*14
result4 = pool4
# 第五个卷积层 size:14
# 卷积核11[3, 3, 512, 512]
# 卷积核12[3, 3, 512, 512]
# 卷积核13[3, 3, 512, 512]
with tf.name_scope('conv5_layer'):
w_conv11 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv11 = bias_variable([512])
conv_kernel11 = conv2d(result4, w_conv11)
bn11 = tf.layers.batch_normalization(conv_kernel11, training=is_training)
conv11 = tf.nn.relu(tf.nn.bias_add(bn11, b_conv11))
w_conv12 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv12 = bias_variable([512])
conv_kernel12 = conv2d(conv11, w_conv12)
bn12 = tf.layers.batch_normalization(conv_kernel12, training=is_training)
conv12 = tf.nn.relu(tf.nn.bias_add(bn12, b_conv12))
w_conv13 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv13 = bias_variable([512])
conv_kernel13 = conv2d(conv12, w_conv13)
bn13 = tf.layers.batch_normalization(conv_kernel13, training=is_training)
conv13 = tf.nn.relu(tf.nn.bias_add(bn13, b_conv13))
pool5 = max_pool_2x2(conv13) # 14*14 -> 7*7
result5 = pool5
# 第一个全连接层 size:7
# 隐藏层节点数 4096
with tf.name_scope('fc1_layer'):
w_fc14 = weight_variable([7 * 7 * 512, 4096], 4096, use_l2=is_use_l2, lam=lam)
b_fc14 = bias_variable([4096])
result5_flat = tf.reshape(result5, [-1, 7 * 7 * 512])
fc14 = tf.nn.relu(tf.nn.bias_add(tf.matmul(result5_flat, w_fc14), b_fc14))
# result6 = fc14
result6 = tf.nn.dropout(fc14, keep_prob)
# 第二个全连接层
# 隐藏层节点数 4096
with tf.name_scope('fc2_layer'):
w_fc15 = weight_variable([4096, 4096], 4096, use_l2=is_use_l2, lam=lam)
b_fc15 = bias_variable([4096])
fc15 = tf.nn.relu(tf.nn.bias_add(tf.matmul(result6, w_fc15), b_fc15))
# result7 = fc15
result7 = tf.nn.dropout(fc15, keep_prob)
# 输出层
with tf.name_scope('output_layer'):
w_fc16 = weight_variable([4096, classify_num], classify_num, use_l2=is_use_l2, lam=lam)
b_fc16 = bias_variable([classify_num])
fc16 = tf.matmul(result7, w_fc16) + b_fc16
logits = tf.nn.softmax(fc16)
# 损失函数
with tf.name_scope('loss'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=fc16, labels=y_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.add_to_collection('losses', cross_entropy_mean)
loss = tf.add_n(tf.get_collection('losses'))
tf.summary.scalar('loss', loss)
# 训练函数
with tf.name_scope('train'):
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops): # 保证train_op在update_ops执行之后再执行。
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
# 计算准确率
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y_input, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 会话初始化
# sess = tf.InteractiveSession()
# tf.global_variables_initializer().run()
saver = tf.train.Saver()
save_dir = "classify_modles"
checkpoint_name = "train.ckpt"
merged = tf.summary.merge_all() # 将图形、训练过程等数据合并在一起
# writer_train = tf.summary.FileWriter('logs/train', sess.graph) # 将训练日志写入到logs文件夹下
# writer_test = tf.summary.FileWriter('logs/test', sess.graph) # 将训练日志写入到logs文件夹下
# 变量初始化
training_steps = 25000
display_step = 10
batch_size = 20
train_images_count = 0
test_images_count = 0
train_avg_accuracy = 0
test_avg_accuracy = 0
# # 训练
# print("Training start...")
#
# # # 模型恢复
# # sess = tf.InteractiveSession()
# # saver.restore(sess, os.path.join(save_dir, checkpoint_name))
# # print("Model restore success!")
#
# for step in range(training_steps):
# train_images, train_labels, train_images_count = combine_train_dataset(train_images_count, batch_size)
# test_images, test_labels, test_images_count = combine_test_dataset(test_images_count, batch_size)
#
# # 训练
# if step < 10000:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.0001, lam: 0.004})
# elif step < 20000:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.0001, lam: 0.001})
# else:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.00001, lam: 0.001})
#
# # 每训练10步,输出显示训练过程
# if step % display_step == 0:
# train_accuracy = accuracy.eval(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0, is_training: False,
# is_use_l2: False})
# train_loss = sess.run(loss, feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False})
# train_result = sess.run(tf.argmax(logits, 1),
# feed_dict={x_input: train_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# train_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: train_labels})
#
# test_accuracy = accuracy.eval(
# feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0, is_training: False,
# is_use_l2: False})
# test_result = sess.run(tf.argmax(logits, 1),
# feed_dict={x_input: test_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# test_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: test_labels})
#
# print("Training dataset:")
# print(train_result)
# print(train_label)
# print("Testing dataset:")
# print(test_result)
# print(test_label)
#
# print("step {}\n training accuracy {}\n loss {}\n testing accuracy {}\n".format(step, train_accuracy, train_loss, test_accuracy))
# train_avg_accuracy += train_accuracy
# test_avg_accuracy += test_accuracy
# result_train = sess.run(merged, feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False}) # 计算需要写入的日志数据
# writer_train.add_summary(result_train, step) # 将日志数据写入文件
#
# result_test = sess.run(merged, feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False}) # 计算需要写入的日志数据
# writer_test.add_summary(result_test, step) # 将日志数据写入文件
#
# # 每训练100步,显示输出训练平均准确度,保存模型
# if step % (display_step * 10) == 0 and step != 0:
# print("train_avg_accuracy {}".format(train_avg_accuracy / 10))
# train_avg_accuracy = 0
# print("test_avg_accuracy {}".format(test_avg_accuracy / 10))
# test_avg_accuracy = 0
#
# saver.save(sess, os.path.join(save_dir, checkpoint_name))
# print("Model save success!\n")
#
# print("Training finish...")
#
# # 模型保存
# saver.save(sess, os.path.join(save_dir, checkpoint_name))
# print("\nModel save success!")
#
# # print("\nTesting start...")
# # avg_accuracy = 0
# # for i in range(int(test_images_num / 30) + 1):
# # test_images, test_labels, test_images_count = combine_test_dataset(test_images_count, 30)
# # test_accuracy = accuracy.eval(
# # feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0, is_training: False, is_use_l2: False})
# # test_result = sess.run(tf.argmax(logits, 1),
# # feed_dict={x_input: test_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# # test_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: test_labels})
# # print(test_result)
# # print(test_label)
# # print("test accuracy {}".format(test_accuracy))
# # avg_accuracy += test_accuracy
# #
# # print("\ntest_avg_accuracy {}".format(avg_accuracy / (int(test_images_num / 30) + 1)))
#
# sess.close()
# 识别
# 模型恢复
sess = tf.InteractiveSession()
saver.restore(sess, os.path.join(save_dir, checkpoint_name))
print("Model restore success!")
def predict_img(img_path):
img = cv2.imread(img_path)
image = np.reshape(img, [1, 224, 224, 3])
classify_result = sess.run(tf.argmax(logits, 1),
feed_dict={x_input: image, keep_prob: 1.0, is_training: False, is_use_l2: False})
probability = sess.run(logits, feed_dict={x_input: image, keep_prob: 1.0, is_training: False,
is_use_l2: False}).flatten().tolist()[
classify_result[0]]
return classify_result[0], probability
def trash_classify(img_path, img_name, upload_path):
img_name = img_name.rsplit('.', 1)[0]
# print(img_name)
pretrian_img_path, selected_img_path = pretreatment_image(img_path, img_name, upload_path)
predict_result, predict_probability = predict_img(pretrian_img_path)
return predict_result, predict_probability