人体姿态识别~HRNet论文笔记(CVPR2019)~《Deep High-Resolution Representation Learning for Human Pose Estimation》
有兴趣的朋友可以相互讨论技术

论文:https://arxiv.org/abs/1902.09212
官方代码:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Abstract
在这篇论文中,我们主要研究人的姿态问题(human pose estimation problem),着重于输出可靠的高分辨率表征(reliable highresolution representations)。现有的大多数方法都是从高分辨率到低分辨率网络(high-to-low resolution network)产生的低分辨率表征中恢复高分辨率表征。相反,我们提出的网络能在整个过程中都保持高分辨率的表征。
我们从高分辨率子网络(high-resolution subnetwork)作为第一阶段开始,逐步增加高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率子网并行连接。我们进行了多次多尺度融合(multi-scale fusions),使得每一个高分辨率到低分辨率的表征都从其他并行表示中反复接收信息,从而得到丰富的高分辨率表征。因此,预测的关键点热图可能更准确,在空间上也更精确。
通过 COCO keypoint detection 数据集和 MPII Human Pose 数据集这两个基准数据集的pose estimation results,我们证明了网络的有效性。此外,我们还展示了网络在 Pose Track 数据集上的姿态跟踪的优越性。
1、Introduction
二维人体姿态估计(2D human pose )是计算机视觉中一个基本而又具有挑战性的问题。目标是定位人体的解剖关键点(如肘部、腕部等)或部位。它有很多应用,包括人体动作识别、人机交互、动画(human action recognition, human-computer interaction, animation)等。本文着力于研究单人姿态识别(single-person pose estimation),这是其他相关问题的基础,如multiperson pose estimation,video pose estimation and tracking等。
最近的发展表明,深度卷积神经网络已经取得了最先进的性能。大多数现有的方法通过一个网络(通常由高分辨率到低分辨率的子网串联而成)传递输入,然后提高分辨率。例如,Hourglass[40]通过对称的低到高分辨率的过程(symmetric low-to-high process)恢复高分辨率。SimpleBaseline采用少量的转置卷积层(transposed convolution layers)来生成高分辨率的表示。此外,空洞卷积(dilated convolutions)还被用于放大高分辨率到低分辨率网络(high-to-low resolution network)的后几层(如VGGNet或ResNet)。
我们提出了一种新的架构,即高分辨率网络(HRNet),它能够在整个过程中维护高分辨率的表示。我们从高分辨率子网作为第一阶段始,逐步增加高分辨率到低分辨率的子网(gradually add high-to-low resolution subnetworks),形成更多的阶段,并将多分辨率子网并行连接。在整个过程中,我们通过在并行的多分辨率子网络上反复交换信息来进行多尺度的重复融合。我们通过网络输出的高分辨率表示来估计关键点。生成的网络如图所示:

与现有的广泛用于姿态估计(pose estimation)的网络相比,我们的网络有两个好处:
1、我们的方法是并行连接高分辨率到低分辨率的子网,而不是像大多数现有解决方案那样串行连接。因此,我们的方法能够保持高分辨率,而不是通过一个低到高的过程恢复分辨率,因此预测的热图可能在空间上更精确。
2、大多数现有的融合方案都将低层和高层的表示集合起来。相反,我们使用重复的多尺度融合,利用相同深度和相似级别的低分辨率表示来提高高分辨率表示,反之亦然,从而使得高分辨率表示对于姿态的估计也很充分。因此,我们预测的热图可能更准确。
我们通过实验证明了在两个基准数据集(Benchmark):COCO关键点检测数据集(keypoint detection)和MPII人体姿态数据集(Human Pose dataset)上优越的关键点检测性能。此外,我们还展示了我们的网络在PoseTrack数据集上视频姿态跟踪的优势。
2、Related Work
传统的单人体姿态估计大多采用概率图模型或图形结构模型,近年来通过深度学习对一元能量和对态能量(unary and pair-wise energies)进行更好的建模或模仿迭代推理过程,对模型进行改进。目前,深度卷积神经网络提供了主流的解决方案。主要有两种方法:
1、回归关键点位置
2、估算关键点热图(estimating keypoint heatmaps),然后选择热值最高的位置作为关键点。
大多数卷积神经网络对于关键点热图的估计包含一个类似于分类网络的主干子网络(stem subnetwork),这降低了分辨率,主体产生与输入具有相同分辨率的表示,然后由一个回归器估计热图,其中关键点位置被估计,然后以完全分辨率进行转换。主体主要采用高到低和低到高分辨率的框架,可能增加多尺度融合(multi-scale fusion)和监督( intermediate (deep) supervision)。
1、High-to-low and low-to-high.
high-to-low process的目标是生成低分辨率和高层次的表示,low-to-high process的目标是生成高分辨率的表示。这两个过程可能会重复多次,以提高性能。
具有代表性的网络设计模式包括:
1、Symmetric high-to-low and low-to-high processes。Hourglass及其后续论文将low-to-high proces设计为high-to-low process的镜子。
2、Heavy high-to-low and light low-to-high。high-to-low process是基于ImageNet分类网络,如[11,72]文献中使用的ResNet,low-to-high process是简单的几个双线性上采样或转置卷积层。
3、Combination with dilated convolutions。在[27,51,35]中,ResNet或VGGNet在最后两个阶段都采用了空洞卷积来消除空间分辨率的损失,然后采用由light low-to-high process来进一步提高分辨率,避免了仅使用空洞卷积的昂贵的计算成本。
图2描述了四种具有代表性的姿态估计网络:

2、Multi-scale fusion
最直接的方法是将多分辨率图像分别送入多个网络,并聚合输出的映射图。
1、Hourglass[40]及其扩展[77,31]通过跳过连接(上图中虚线部分),将high-to-low process中的低级别特征逐步组合为low-to-high process中的相同分辨率的高级别特性。
2、在cascaded pyramid network[11]中,globalnet将high-to-low process中的低到高级别特征(low-to-high level feature)逐步组合到low-to-high process中,refinenet(上图b中右半部分)将通过卷积处理的低到高特征进行组合。我们的方法重复多尺度融合,部分灵感来自深度融合及其扩展。
3、Intermediate supervision(中间监督)
图像分类早期开发的中间监督或深度监督[34,61],也用于帮助深度网络训练和提高热图估计质量,如[69,40,64,3,11]。Hourglass[40]和CPM[69]将中间热图作为剩余子网络的输入或输入的一部分进行处理。
4、Our approach.
我们的网络并行地连接高到低的子网。它通过在空间上精确热图估计,从而整个过程保持了高分辨率的表示。它通过重复融合高到低子网产生的各种分辨率表示来生成可靠的高分辨率表示。我们的方法不同于大多数现有的工作,它们需要一个独立的从低到高的上采样过程,并聚合low-level 和 high-level的表示。该方法在不使用中间热图监控的情况下,具有较好的关键点检测精度、计算复杂度、参数。
有很多相关的多尺度网络进行分类和分割[5,8,74,81,30,76,55,56,24,83,55,52,18]。我们的工作在一定程度上受到了其中一些问题的启发[56,24,83,55],而且存在明显的差异,使得它们不适用于我们的问题。Convolutional neural fabrics[56]和interlinked CNN[83]由于缺乏对每个子网络(depth, batch normalization)的合理设计和多尺度融合,分割结果的质量不高。grid network[18]是多个权重共享的U-Nets组合,由两个多分辨率表示的独立融合过程组成;第一阶段,信息仅从高分辨率发送到低分辨率;在第二阶段,信息只从低分辨率发送到高分辨率,因此竞争力较低。Multi-scale densenets[24]没有目标,无法生成可靠的高分辨率表示。
3、Approach
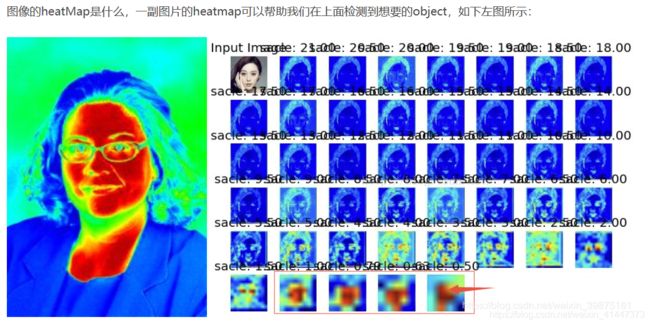
人体姿态估计(Human pose estimation),即关键点检测,旨在从一个图像(W×H×3)中检测K个部分关键点的位置(例如,手肘、手腕等)。state-of-the-art级别的方法是将这个问题转变为估计K个热图 ,其中每个热图
,其中每个热图 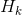 表示第 k 个关键点的位置置信度。
表示第 k 个关键点的位置置信度。
我们遵循广泛适用的pipeline:使用卷积网络预测人体关键点,它包括一个由两步卷积(降低分辨率)组成的主干(stem),一个输出与输入特征图具有相同分辨率的特征图的主体,以及一个估计热图的回归器,其中关键点位置被选择并转换为全分辨率。
我们主要关注主体的设计,并介绍我们的高分辨率网络(HRNet),如图1所示。
1、Sequential multi-resolution subnetworks.(连续的多分辨率子网络)
现有的姿态估计网络是将高分辨率到低分辨率的子网络串联起来,每个子网络形成一个阶段,由一系列卷积组成,相邻子网络之间存在一个下采样层,将分辨率减半。
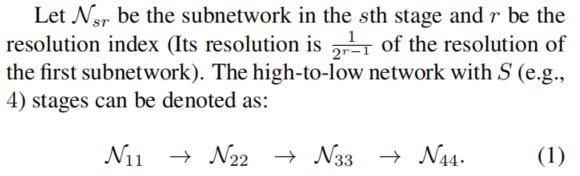
2、Parallel multi-resolution subnetworks(并行的多分辨子网络)
我们以高分辨率子网为第一阶段,逐步增加高分辨率到低分辨率的子网,形成新的阶段,并将多分辨率子网并行连接。因此,后一阶段并行子网的分辨率由前一阶段的分辨率和下一阶段的分辨率组成。一个包含4个并行子网的网络结构示例如下:

3、Repeated multi-scale fusion(反复的多尺度融合)
参考:
https://blog.csdn.net/weixin_37993251/article/details/88043650